
Apify vs Scrapy: An Honest Comparison With Real Costs
Every Apify vs Scrapy comparison hedges with "it depends." Here's an actual answer: these tools operate at different layers of the stack, and comparing them is like comparing AWS Lambda to Flask. One's a managed cloud platform, the other's a Python framework you run yourself. The right pick comes down to your team, your targets, and whether you actually need to build scraping infrastructure at all.
30-Second Verdict
- Pick Scrapy if you have Python devs on staff, your targets are mostly static HTML, and you want infrastructure costs under $200/mo.
- Pick Apify if you're scraping JS-heavy sites, don't have DevOps capacity, or want prebuilt scrapers running in minutes.
What Each Tool Actually Is
Scrapy is an open-source Python framework built on Twisted's async engine. It's been around since 2008, has 58.9K GitHub stars, and remains the most popular web scraping framework in Python for developers who want full control over their crawling pipeline. You write spiders, configure middlewares, build pipelines - and you manage every piece of infrastructure yourself. Reddit users on r/webscraping consistently call it "super fast on static sites," and that tracks with our testing.
Apify is a cloud platform with 15,000+ prebuilt Actors (their term for serverless scraping programs), managed proxies, scheduling, and storage. It carries a 4.7/5 on G2 across 415 reviews. You can write custom code or grab a ready-made Actor and run it in minutes. Users on r/automation praise its "solid infrastructure and prebuilt actors" - though some note it felt "heavier than I needed for smaller jobs."
Head-to-Head Comparison
| Dimension | Apify | Scrapy | Edge |
|---|---|---|---|
| Type | Cloud platform | Python framework | Apify (zero infra management) |
| Languages | Python, JS, TS | Python only | Apify |
| JS rendering | Native (Playwright/Puppeteer) | Requires scrapy-playwright or selenium | Apify |
| Pricing | $0-$999/mo + usage | Free lib; $20-$3K+ infra | Scrapy (if you have the team) |
| Proxies | Built-in residential & datacenter | BYO third-party | Apify |
| Scaling | Managed, auto-scaling | Self-managed servers | Apify |
| Learning curve | Low (prebuilt); steep (custom) | Steep throughout | Apify (for prebuilt) |
| Community | 15K+ Actors, 4.7/5 G2 | 58.9K GitHub stars, massive ecosystem | Scrapy |
| Best for | JS-heavy sites, no-code/small teams | Static sites, Python teams | - |
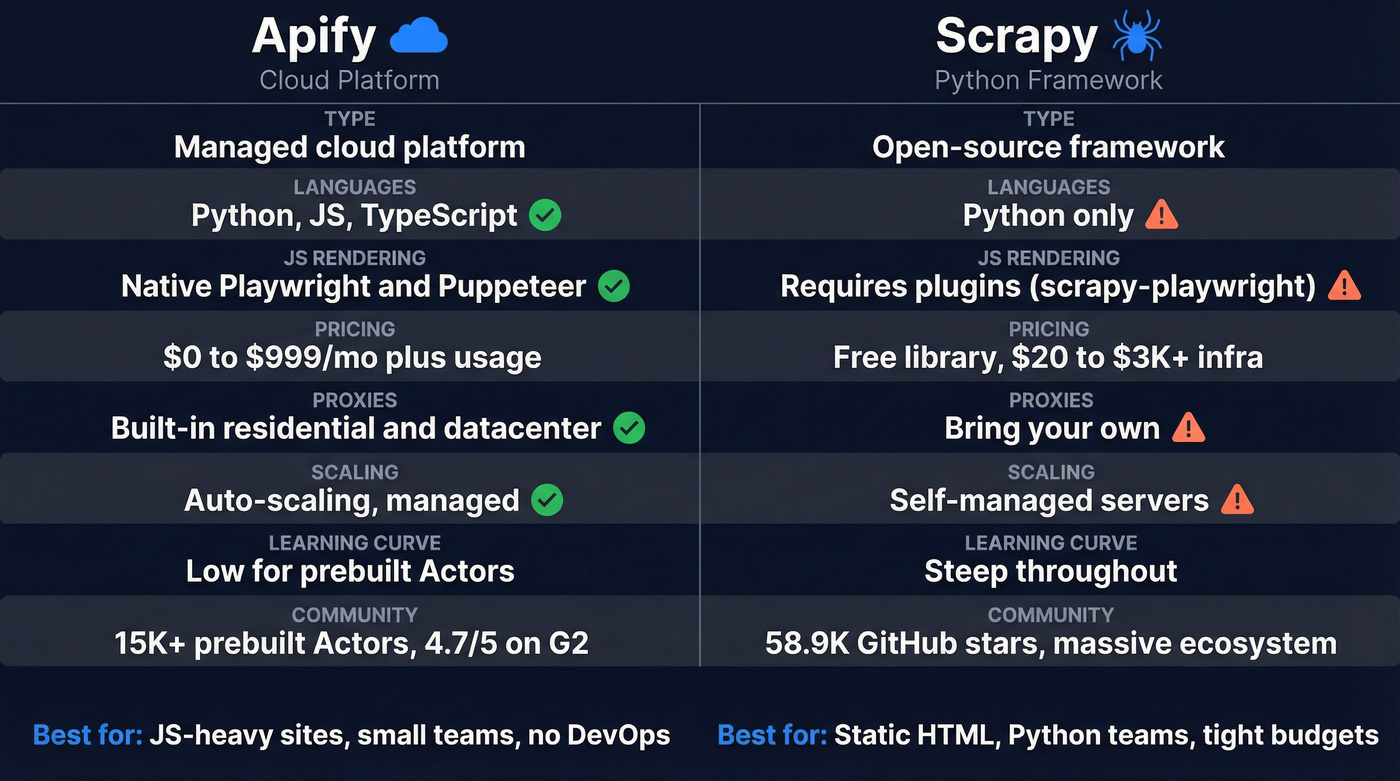
The table tells most of the story, but here's the nuance it misses: Scrapy gives you unlimited architectural freedom at the cost of operational burden. Apify trades some of that freedom for infrastructure you never have to think about.
Let's be honest - most teams choosing between these two would be better served by Apify's prebuilt Actors than by a custom Scrapy project. The "build it yourself" instinct is strong in engineering teams, but we've seen it play out dozens of times: teams underestimate Scrapy's operational overhead by 3-5x. Unless scraping is a core competency and not a side project feeding a sales pipeline, managed infrastructure wins.
What You'll Actually Pay
Apify runs on compute units (CUs), where 1 CU equals 1 GB of RAM for 1 hour. CU rates drop as you scale: $0.30/CU on Starter, $0.25/CU on Scale, $0.20/CU on Business. Some real math: a 1 GB job running 5 minutes costs about $0.025. A 4 GB Playwright job running an hour costs $1.20 at Starter rates.

The tiers: Free ($0 with $5 in credits), Starter ($29/mo), Scale ($199/mo), Business ($999/mo). Each tier includes prepaid credits equal to the subscription price. Unused credits expire monthly and don't roll over - browser-heavy jobs burn CUs fast, so a "cheap" plan can surprise you. Residential proxies add $7-$8/GB depending on tier. Datacenter proxies are included: 30 IPs on Starter, 200 on Scale. Extra concurrent runs cost $5/run, and additional RAM runs $2/GB.
Scrapy is free to download. Running it in production is not.
A Reddit user documented scraping 10K-30K news articles/day on self-hosted infrastructure for ~$150/mo - versus $3K-$4.5K/mo through paid APIs. That's the Scrapy value proposition in one data point. But it required PostgreSQL, GCP buckets, Scrapyd, Redash dashboards, and Slack alerting. Plus the engineering time to build and maintain all of it.
Scrapy's "free" label is misleading. Rough TCO by scale: hobby projects run $20-$50/mo on a single VPS, mid-scale operations hit $200-$500/mo once you add proxies and monitoring, and production crawling with rotating proxies, anti-detection, and alerting lands at $500-$3K+/mo. None of that includes developer hours.
You're comparing scraping tools to build a contact list - but Prospeo already has 300M+ profiles with 98% verified emails. No spiders, no proxies, no CU overages. Just $0.01/email with 7-day data refresh.
Ditch the scraping pipeline. Get verified B2B data in seconds.
The JavaScript Rendering Problem
Scrapy doesn't execute JavaScript. If your target renders content client-side, your selectors return nothing. This is the single biggest limitation and the reason many teams end up on Apify instead.
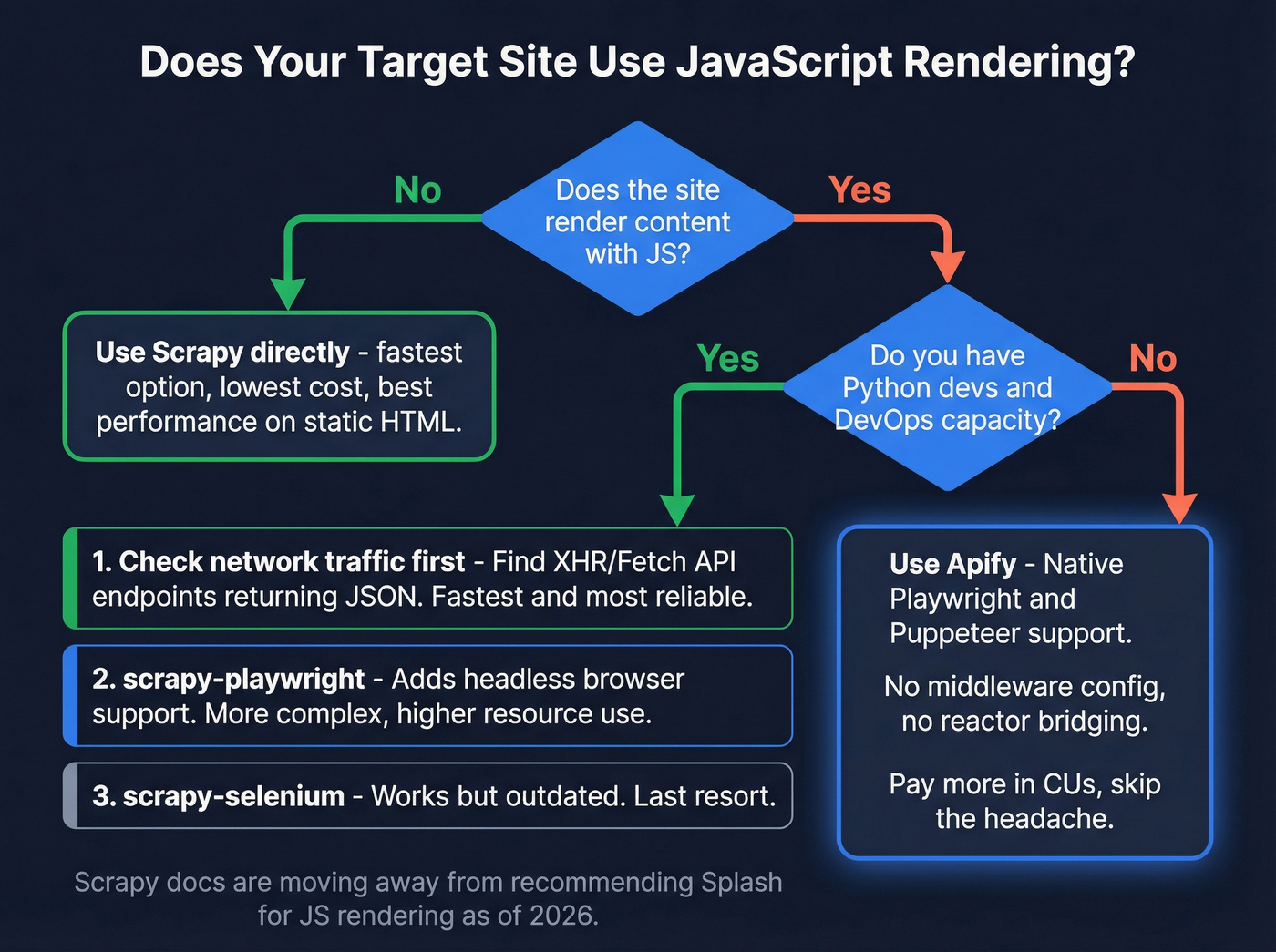
Three workarounds exist, ranked by effectiveness:
- Inspect network traffic and find the underlying XHR/Fetch API endpoints returning JSON - faster and more reliable than rendering anything.
- Use scrapy-playwright, which adds headless browser support but increases complexity and resource consumption significantly.
- scrapy-selenium, the older middleware approach that works but feels clunky and is increasingly outdated.
Scrapy's docs are moving away from recommending Splash (their previous go-to for JS rendering), which signals the ecosystem is still figuring out its dynamic-content story. Apify handles this natively. Playwright and Puppeteer Actors render JS out of the box - no middleware configuration, no Twisted-asyncio reactor bridging. You pay more in CUs, but you skip the integration headache entirely.
Running Scrapy on Apify
Here's what most comparison posts miss: you can run your existing Scrapy spiders on Apify's infrastructure. The Apify SDK wraps Scrapy projects as Actors, and run_scrapy_actor installs the asyncio-compatible reactor automatically. You keep your spiders, and Apify provides scheduling, proxy rotation, monitoring, and storage.
Key components: ApifyScheduler uses Apify's request queue, ActorDatasetPushPipeline pushes items to Apify datasets, and ApifyHttpProxyMiddleware integrates Apify's proxy pool. This path makes sense when you've already invested in Scrapy spiders but need cloud infrastructure without rebuilding everything.
Starting fresh? Crawlee - Apify's open-source crawling library - is worth a look. It's built on asyncio, fully type-hinted, and offers a unified interface for both HTTP and browser-based scraping. Think of it as what Scrapy might look like if it were designed today.
When to Choose Which
Imperva's 2024 threat research found roughly 50% of internet traffic is now non-human, and bot-detection services nearly doubled from 36 to 60 between 2022 and 2024. Scraping is getting harder regardless of your tool choice. Here's how we'd break it down:

Static sites + Python devs + tight budget - go with Scrapy. You'll get the best performance-per-dollar ratio, and the Scrapy documentation is excellent.
JS-heavy sites + small team + no DevOps - Apify. The prebuilt Actors and managed infra save weeks of setup. Check the Apify Store before writing a single line of code.
Existing Scrapy spiders + need cloud infra - run Scrapy on Apify. Best of both worlds.
Scraping for B2B contact data - stop scraping entirely.
That last scenario is more common than people admit.
Scraping for Leads? Skip the Infrastructure
Look, we've talked to dozens of teams who spent weeks building spiders to collect emails, phone numbers, and company info from websites. They were solving the wrong problem. That data is already available, verified, and structured.
If your real goal is web scraping lead generation, it’s worth pressure-testing whether you should be scraping at all.
Between Scrapy's infra costs and Apify's CU burn, you're spending $200-$3K/mo just to collect data that still needs verification. Prospeo delivers 143M+ verified emails and 125M+ mobile numbers - ready to use, no scraping required.
Why scrape, clean, and verify when the data already exists?
FAQ
Can I use Scrapy and Apify together?
Yes. The Apify SDK converts Scrapy projects into Actors on Apify's cloud. You keep your spider code while Apify handles scheduling, proxies, and storage - it's the cleanest migration path if you already have working spiders and need managed infrastructure without a rewrite.
Is Scrapy really free?
The library is open-source and always will be. Production use requires servers, proxies, and monitoring - expect $150-$3K+/month in infrastructure costs depending on crawl volume, plus ongoing developer hours for maintenance and anti-detection updates.
What if I just need B2B contact data?
Skip scraping entirely. Prospeo delivers 300M+ verified profiles with 98% email accuracy starting at $0/month (75 free credits). At roughly $0.01/email, it's cheaper and faster than any spider-and-proxy setup for contact enrichment.