How to Run a Data Quality Audit That Actually Changes Something
A RevOps lead we know pulled a pipeline report for the board last quarter. It showed 847 open opportunities worth $14.2M. The problem? 312 of those were duplicates, 89 had no associated contact, and the "pipeline" was inflated by 40%. The board didn't ask about quota attainment that day. They asked why nobody caught this sooner.
That's what happens without a data quality audit. And it's far more common than anyone admits - 43% of COOs now rank data quality as their top data priority, over a quarter of organizations estimate they lose more than $5M annually to bad data, and 7% report losses exceeding $25M. With 45% of business leaders citing data quality as the leading barrier to scaling AI initiatives, audits aren't just about clean dashboards anymore. They're prerequisites for any AI strategy.
But here's the thing: most audits fail because they produce a PDF that nobody acts on. Let's fix that.
What You Need (Quick Version)
Your first audit needs exactly three deliverables:
- 10 SQL queries against your most business-critical dataset - nulls, duplicates, freshness, referential integrity, format validation
- A pass/fail spreadsheet with actual numbers and thresholds (not "some emails are missing" - write "15.3% null rate on email field, threshold is 5%, FAIL")
- A remediation plan with named owners, deadlines, and success criteria
Everything else is optimization. 56% of data teams cite data quality as their most pressing challenge, but most of them are stuck in the "we should really do something about this" phase. These three artifacts get you out of that phase in a week.
What a Data Quality Audit Actually Is
A data quality audit is a structured evaluation of a specific dataset against defined standards, with pass/fail judgments and a remediation plan attached. It's not a dashboard. It's not a vibe check. It's a repeatable process that produces evidence and assigns accountability.
People confuse three related but different things:
| Audit | Assessment | Governance | |
|---|---|---|---|
| Purpose | Test specific data, fix failures | Evaluate maturity/readiness | Ongoing policy & ownership |
| Output | Pass/fail results + remediation | Maturity score + roadmap | Standards, roles, processes |
| Cadence | Quarterly + automated daily | Annual or semi-annual | Continuous |
| Who owns it | Data/analytics engineer | Data leadership | Cross-functional |
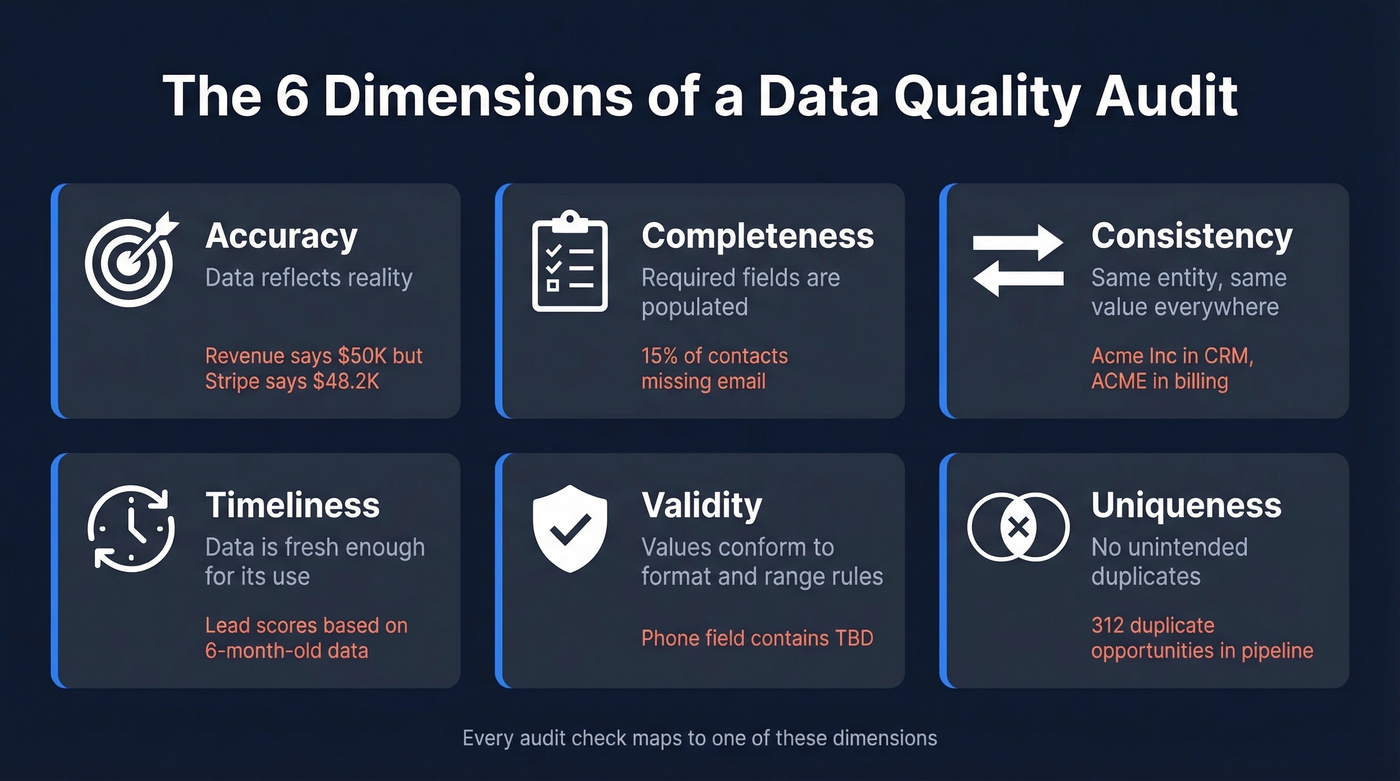
A standard audit framework measures data against six core dimensions:
| Dimension | Definition | Failure Example |
|---|---|---|
| Accuracy | Data reflects reality | Revenue field says $50K; Stripe says $48.2K |
| Completeness | Required fields are populated | 15% of contacts missing email |
| Consistency | Same entity, same value everywhere | "Acme Inc" in CRM, "ACME" in billing |
| Timeliness | Data is fresh enough for its use | Lead scores based on 6-month-old firmographics |
| Validity | Values conform to format/range rules | Phone field contains "TBD" |
| Uniqueness | No unintended duplicates | 312 duplicate opportunities inflating pipeline |
How to Scope Your B2B Data Audit
Don't audit your entire data warehouse at once. That's how audit programs die in week two.
Start with one dataset - the one closest to revenue. Categorize your datasets into three buckets:
- Customer-facing: data that end users or customers see (dashboards, reports, product data)
- Operational: data powering real-time or near-real-time processes (lead routing, billing, scoring)
- Analytical: data feeding internal analysis and models
Customer-facing and operational datasets come first. These are where bad data causes visible damage - bounced emails, misrouted leads, wrong invoices, inflated pipeline numbers. A wrong internal chart is less urgent than a wrong invoice.
For your first audit, pick one table or one data domain. Run the full process end-to-end. Get a remediation win. Then expand scope. We've watched teams try to boil the ocean on audit one, and the result is always the same: a 47-page report that nobody reads and nothing changes.
Step-by-Step Audit Process
Define Metrics and Thresholds
Before you write a single query, decide what "good" looks like. Every check needs a metric and a threshold - otherwise you're just profiling, not auditing.
| Check | Metric | Threshold | Example |
|---|---|---|---|
| Null rate | % null per column | < 5% for required fields | Email null rate: 2.3% PASS |
| Duplicate rate | % duplicate rows | < 1% | Contact dupes: 3.7% FAIL |
| Freshness | Hours since last update | < 24 hours | Last sync: 47 hrs ago FAIL |
| Reconciliation | Source vs. target match | > 99% | 497/500 matched (99.4%) PASS |
| Format validity | % matching regex | > 98% | Phone format: 96.1% FAIL |
The key principle: document with numbers. "15.3% null rate on email field" is actionable. "Some emails are missing" is not. Every finding should be a number compared to a threshold with a pass or fail verdict.
Profile and Test Your Data
Here's where SQL does the heavy lifting. These queries cover common audit checks, adapted from patterns Dremio documents well.
NULL rate (single column):
SELECT
COUNT(*) AS total_rows,
COUNT(email) AS non_null_rows,
COUNT(*) - COUNT(email) AS null_rows,
ROUND(100.0 * (COUNT(*) - COUNT(email)) / COUNT(*), 2) AS null_pct
FROM contacts;
Duplicate detection:
SELECT email, COUNT(*) AS dupes
FROM contacts
GROUP BY email
HAVING COUNT(*) > 1
ORDER BY dupes DESC;
Foreign key integrity:
SELECT o.account_id
FROM opportunities o
WHERE o.account_id NOT IN (SELECT id FROM accounts)
AND o.account_id IS NOT NULL;
Range validation:
SELECT id, annual_revenue
FROM companies
WHERE annual_revenue < 0 OR annual_revenue > 1e12;
Regex format check (Postgres):
SELECT id, phone
FROM contacts
WHERE phone !~ '^\+?[0-9\-\(\) ]{7,20}$';
For deeper profiling - min/max/avg/stdev, distinct counts, string length distributions - Dataedo's query library is a solid reference. If you're in Python, Pandas and Polars equivalents exist for every one of these checks.
Document Findings
Every audit needs a findings table. Here's what a filled example looks like:
| Check | Metric | Threshold | Result | Status |
|---|---|---|---|---|
| Email null rate | % null | < 5% | 2.3% | PASS |
| Contact duplicates | % duplicate | < 1% | 3.7% | FAIL |
| Revenue reconciliation | Source match % | > 99% | 99.4% | PASS |
| Revenue accuracy | Variance vs Stripe | < 0.1% | 0.02% | PASS |
| Data freshness | Hours since sync | < 24 hrs | 47 hrs | FAIL |
| Phone format | % valid format | > 98% | 96.1% | FAIL |
Track three operational KPIs over time to measure whether your audit program is actually improving things: number of incidents (N), time to detection (TTD), and time to resolution (TTR). If N goes down and TTD shrinks quarter over quarter, your audits are working.
Your audit just flagged a 15% email null rate and 3.7% duplicates. Now what? Prospeo's 300M+ profiles with 98% verified email accuracy and 7-day refresh cycles mean fewer nulls, fewer bounces, and fewer audit failures. Enrich your CRM in bulk - 83% of leads come back with verified contact data and 50+ data points.
Pass your next data quality audit before you even run it.
How to Audit CRM and GTM Data
CRM and go-to-market data has its own failure modes that generic frameworks miss entirely.

Bounce rates are the canary in the coal mine. If your SDRs are running sequences with a 12% email bounce rate, you're not just losing replies - you're burning domain reputation. Every bounced email tells ESPs your list is dirty, and once your domain gets flagged, even your good emails stop landing.
Stale contacts rot faster than most teams realize. If your CRM hasn't been enriched recently, a meaningful chunk of your contact data points to the wrong company, wrong title, or a deactivated inbox. The consensus on r/sales is that B2B contact data decays at roughly 30% per year, and in our experience that's conservative for fast-moving industries like tech.
Duplicate opportunities inflating pipeline is the 847-duplicate scenario from the intro. Merge rules that don't catch company name variants ("Acme Inc" vs "Acme, Inc." vs "ACME") create phantom pipeline that misleads the entire organization.
Misrouted leads and broken attribution follow from stale territory fields and wrong industry codes. Leads route to the wrong rep, marketing can't measure what's working, and everyone blames each other.
When the audit reveals stale emails and dead phone numbers - and it will - the fix is re-verification and enrichment. Prospeo handles this at scale with 98% email accuracy, a 7-day data refresh cycle versus the 6-week industry average, and CRM enrichment that returns 50+ data points per contact. That's the difference between knowing your data is bad and actually fixing it.
Build Your Remediation Plan
An audit without a remediation plan is just audit theater. A PDF that makes everyone feel productive while nothing changes.

Your remediation plan needs these fields for every failing check:
| Field | Example |
|---|---|
| Issue | Contact duplicate rate 3.7% (threshold: <1%) |
| Root cause | No dedup rule on web form imports |
| Downstream impact | Inflated pipeline by ~$2.1M |
| Action | Implement fuzzy match dedup on import |
| Owner | Sarah Chen, RevOps |
| Deadline | 2026-03-15 |
| Success criteria | Duplicate rate < 1% for 30 days |
| Verification | Re-run duplicate query on Apr 15 |
The structure matters: executive summary, scope and sources, dimensions with metrics and thresholds, findings with root causes, and recommendations with an action plan that has named owners and deadlines. Skip any of those elements and the report collects dust.
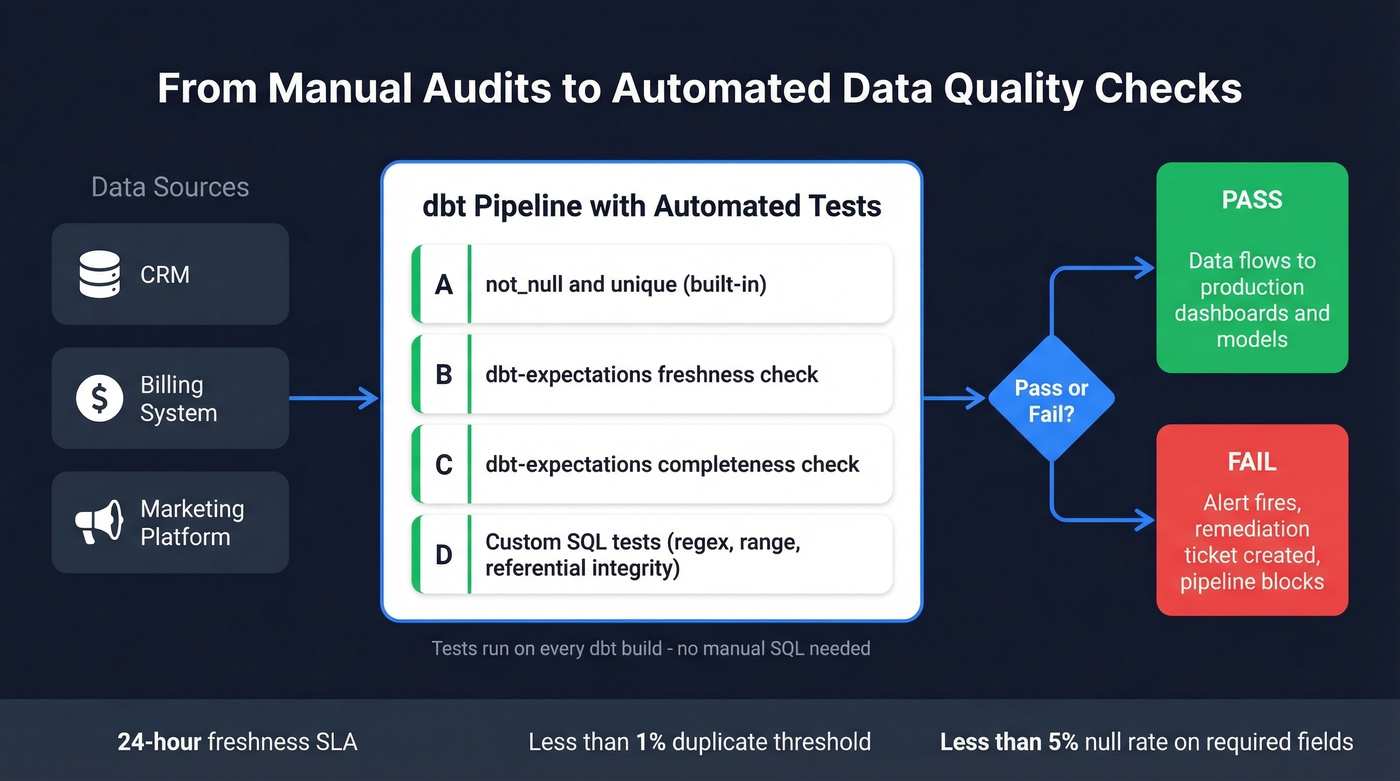
Automating Audits in Your Pipeline
Manual audits are necessary for the first pass. But if you're still running SQL queries by hand every quarter, you're leaving gaps between audits where data rots undetected.
dbt-expectations
dbt's native tests cover the basics - unique, not_null, accepted_values, relationships. That's four checks. You need more.
dbt-expectations is a free, open-source package that extends dbt with Great Expectations-style assertions you define in YAML. Thousands of teams use it in production.
Freshness check:
- dbt_expectations.expect_grouped_row_values_to_have_recent_data:
group_by: [source_system]
timestamp_column: updated_at
datepart: hour
interval: 24
Completeness across time buckets:
- dbt_expectations.expect_row_values_to_have_data_for_every_n_datepart:
date_col: created_date
date_part: day
interval: 1
test_start_date: "2026-01-01"
test_end_date: "2026-03-01"
These run on every dbt build, which means your audit checks execute every time your pipeline runs. Issues surface in hours, not quarters.
Great Expectations + Airflow
For teams not on dbt, Great Expectations is the standard alternative. Install with pip install great_expectations, initialize with gx.get_context(mode="file") to create your project structure, then define expectation suites as JSON - each suite is a collection of checks against a specific dataset. Integrate with Airflow via airflow-provider-great-expectations (requires Python 3.10+, GX 1.7.0+, Airflow 2.1+). Suites run as Airflow tasks, failing the DAG when checks fail.
This is the right path for teams running Spark, Airflow, or custom Python pipelines where dbt isn't in the stack.
Audit Tools Compared
Let's be honest: most teams don't need a dedicated data quality tool. Start with SQL and dbt tests. Prove the process manually. Then decide if you need software.
That said, here's the field when you outgrow the basics:
| Tool | Type | AI/ML | Best For | Est. Pricing |
|---|---|---|---|---|
| Great Expectations | OSS / Code | No | Python/Airflow teams | Free; Cloud ~$1-5K/mo |
| dbt-expectations | OSS / Code | No | dbt shops | Free; dbt Cloud $100+/mo |
| Prospeo | Proprietary / No-Code | No | B2B contact verification & enrichment | Free tier; ~$0.01/email |
| Soda Core | OSS / Partial No-Code | No | YAML-first checks | Free; Cloud ~$500/mo |
| Deequ | OSS / Code | No | Spark-based pipelines | Free (AWS/Spark) |
| Datafold | Proprietary / Partial | No | Diff testing in CI | ~$500/mo+ |
| Monte Carlo | Proprietary / No-Code | Yes | Enterprise (100+ tables) | ~$50-150K+/yr |
| Anomalo | Proprietary / No-Code | Yes | Auto-detect anomalies at scale | ~$30-100K+/yr |
| Bigeye | Proprietary / No-Code | Yes | Mid-market monitoring | ~$30-80K+/yr |
| Collibra | Proprietary / No-Code | Yes | Governance + quality combined | ~$50-200K+/yr |
General observability tools like Monte Carlo and Anomalo are excellent at catching schema changes, volume anomalies, and distribution drift across your warehouse. But when your audit reveals that contact data is the problem - stale emails, invalid phone numbers, missing firmographics - those tools can't fix it. That's a different kind of quality issue, and it needs a different kind of tool.
Skip the enterprise platforms if your average deal size is under $50K and your warehouse has fewer than 50 tables. SQL plus dbt-expectations will cover you until you genuinely outgrow them.
Bad data costs organizations $5M+ per year. Every failed freshness check traces back to stale records from providers refreshing every 6 weeks. Prospeo refreshes all 300M+ profiles every 7 days with 5-step verification, catch-all handling, and spam-trap removal - so your pipeline numbers reflect reality, not ghosts.
Replace your biggest audit failure with data that stays accurate weekly.
Pitfalls That Kill Audit Programs
We've seen five patterns destroy audit programs before they produce a single remediation win.
Scope creep is the most common killer. Auditing everything at once means finishing nothing. One dataset, end-to-end, with a remediation win - then expand.
No ownership turns findings into suggestions. And suggestions get ignored. Every failing check needs a person and a deadline in the remediation plan. No exceptions.
Alert fatigue happens when teams set thresholds too tight, get 200 alerts a week, and start ignoring all of them. Set thresholds at levels that represent actual business risk, not theoretical perfection. If your null rate threshold is 0.1% on a non-critical field, you're going to drown in noise.
Audit theater is the quarterly report that gets produced, presented, filed, and forgotten. If your audit doesn't change a process, a pipeline, or a dataset within 30 days of completion, it's theater. Once your process is repeatable, formalize maturity levels - Initial, Repeatable, Optimized - so leadership can track progression and hold teams accountable.
Tool over-investment is buying a $100K observability platform before you've run your first SQL-based audit. That's like buying a race car before you have a driver's license. Start with SQL. Graduate to dbt tests. Buy tooling when you've outgrown the basics.
FAQ
How often should you run a data quality audit?
Run a full manual audit quarterly on your most critical datasets. Between audits, automate daily checks for nulls, duplicates, and freshness using dbt-expectations or Great Expectations. The manual audit catches structural issues and new failure modes; the automated checks catch day-to-day drift.
What's the difference between an audit and data profiling?
Data profiling is the discovery step - understanding column distributions, null rates, and value ranges. An audit includes profiling but adds thresholds, pass/fail judgments, root cause analysis, and a remediation plan with named owners. Profiling tells you what your data looks like. An audit tells you whether it's good enough and what to fix.
How do you audit B2B contact data in a CRM?
Check email bounce rates, phone number validity, duplicate contact records, and freshness - when was each record last verified? Also examine firmographic accuracy and job title currency, since those fields drive lead scoring and routing. For records that fail, re-verify through a platform with a short refresh cycle so you're replacing stale data with genuinely current records, not slightly-less-stale ones.
What tools do I need for my first audit?
A SQL client and a spreadsheet. Run profiling and validation queries against your database, document pass/fail results with thresholds, and build a remediation plan with owners and deadlines. Add dbt-expectations or Great Expectations when you're ready to automate. Don't buy enterprise tooling until you've proven the process works manually.
Who should own the audit framework in a GTM org?
RevOps is the natural owner for go-to-market data audits because they sit at the intersection of sales, marketing, and customer success systems. They have the cross-functional visibility to define thresholds that reflect actual business impact and the authority to enforce remediation deadlines across teams.