
ParseHub vs Scrapy: Honest 2026 Comparison
ParseHub's own comparison page still lists their Standard plan at $99/month - pricing from 2019. Scrapy maintainers are discussing removing Splash from the docs in the 2.13 milestone. Most of what you'll read about ParseHub vs Scrapy online is stale.
These aren't even the same category of tool. One is a point-and-click desktop app, the other is a Python framework. The "versus" framing only makes sense if you know which camp you fall into. Let's sort that out.
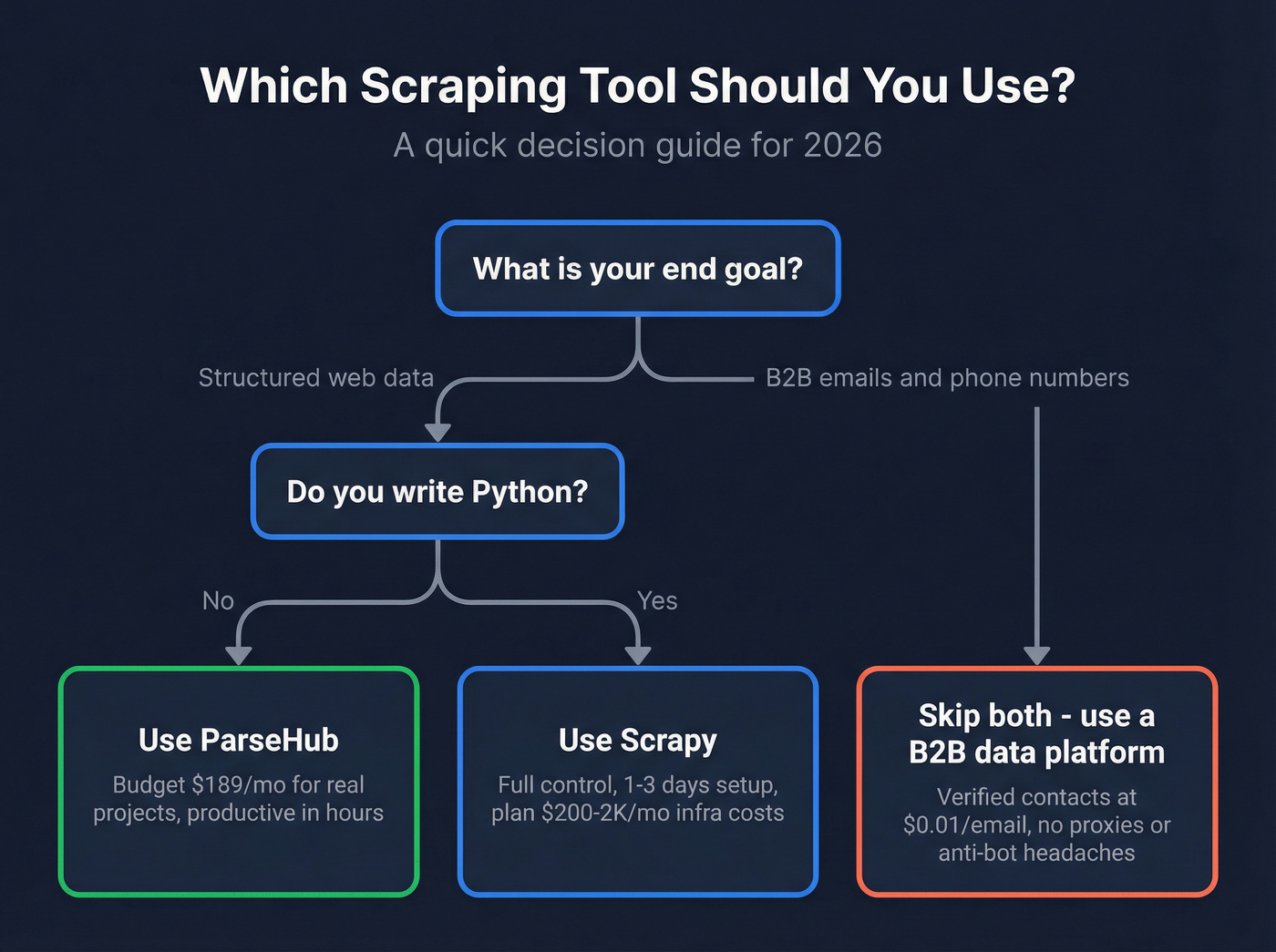
30-Second Verdict
| Scenario | Pick |
|---|---|
| Non-technical, under 10K pages/mo | ParseHub |
| Python dev who needs scale + control | Scrapy |
| You're scraping for B2B contact data | Skip both - use Prospeo |
ParseHub is the fastest path to structured data if you don't write code. Scrapy is the most flexible open-source scraping framework if you do. And if your end goal is business emails and phone numbers, neither tool is the right answer - you're solving a data problem with an infrastructure tool.
Feature Comparison at a Glance
| ParseHub | Scrapy | |
|---|---|---|
| Audience | Non-technical users | Python developers |
| 2026 pricing | $0 / $189 / $599/mo | Free framework; $200-$2K+/mo TCO |
| JS rendering | Built-in | Via scrapy-playwright |
| Learning curve | 1-3 hours | 1-3 days |
| Deployment | Desktop app + cloud runs | Self-hosted or Scrapy Cloud |
| Export formats | CSV, JSON | CSV, JSON, XML, custom |

ParseHub caps you at 200 pages free. Scrapy costs $200-$2K/month in infrastructure. Meanwhile, Prospeo delivers 143M+ verified emails and 125M+ mobile numbers at $0.01/email - no proxies, no anti-bot headaches, no Playwright configs.
Get verified B2B contacts in seconds, not sprint cycles.
ParseHub in 2026

Use ParseHub if you're a marketer, analyst, or ops person who needs to pull structured data from a few hundred pages without touching a terminal. The point-and-click interface handles straightforward sites - AJAX, infinite scroll, login-gated pages. We've seen first projects go from zero to working scrape in about two hours.
Skip ParseHub if you need volume or speed. The free plan caps you at 200 pages per run, 5 public projects, and 14-day data retention - barely enough to test. The Standard plan at $189/month gets you 10,000 pages per run, 20 private projects, IP rotation, and scheduled runs from minute to monthly cadence. Professional hits $599/month for unlimited pages, 120 private projects, 30-day retention, and priority support.
Here's a detail that trips people up: each worker scrapes roughly 5 pages per minute, and "pages" count every dynamic action - scrolls, clicks, new content loads. That adds up faster than you'd expect, especially on sites with infinite scroll or heavy pagination. On G2, ParseHub holds a 4.3/5 with users praising the support team while flagging the UI as occasionally unintuitive. Reddit threads also regularly point out that once sites start blocking you, you'll end up paying for proxies on top of your subscription.
Scrapy in 2026
Scrapy is free, open-source, and backed by 58.9K GitHub stars. But "free" is misleading. The framework costs nothing. Running it in production costs real money.

A small workload - a few spiders, basic proxy rotation, modest infrastructure - runs $200-$2,000/month between VMs, proxy services, and engineering time. At scale with residential proxies and headless browsers, we've seen costs balloon past $5K/month. Scrapy Cloud offers managed hosting at $9/month per unit, but most teams outgrow it quickly. Zyte API, the modern paid path for anti-bot and JS rendering, charges $1.01-$16.08 per 1,000 browser requests depending on site complexity.
And then there's the JavaScript problem. 94% of modern websites use client-side rendering. Scrapy alone can't handle that. Splash, the old answer, is deprecated. The modern path is scrapy-playwright - install Playwright, configure an async Twisted reactor, and manage Chromium instances alongside your spiders. It works, but it's a meaningful jump in complexity and resource consumption compared to static HTML scraping.
Look, Scrapy is still the best scraping framework available. But most people weighing these two options aren't building a scraping pipeline - they're trying to get data. If you don't already write Python, Scrapy's power is irrelevant to you.
When to Use Which
You're non-technical and scraping simple sites. ParseHub. Budget $189/month for anything beyond toy projects. You'll be productive in hours, not days.
You're a Python developer who needs scale and customization. Scrapy. You'll invest 1-3 days getting productive, plus ongoing infrastructure management. The tradeoff is total control over every request, pipeline, and retry policy - and that control matters when you're scraping millions of pages or dealing with aggressive anti-bot measures.
Your goal is B2B emails and phone numbers. Skip both. Scraping company websites for contact data is the slow, expensive, legally murky path. Prospeo has 143M+ verified emails and 125M+ verified mobile numbers at 98% email accuracy on a 7-day refresh cycle - roughly $0.01 per email with a free tier to test. If you’re evaluating options for web scraping lead generation, it’s worth separating “data acquisition” from “data quality.”
Building scrapers to find business emails means fighting anti-bot systems, managing proxies, and cleaning bad data. Prospeo's 300M+ profiles are refreshed every 7 days with 98% email accuracy - purpose-built for the data you actually need.
Skip the scraping pipeline. Start with verified data.
FAQ
Can Scrapy handle JavaScript-heavy websites?
Yes, but the old approach (Splash) is deprecated. The current method is scrapy-playwright, which requires Playwright and an async Twisted reactor. Expect an extra day of setup and roughly 3-5x higher memory usage per spider compared to static HTML scraping.
Is ParseHub really free?
The free plan caps you at 5 public projects, 200 pages per run, and 14-day retention. In our testing, real projects hit those limits within the first week. Budget $189/month minimum for production use.
What's a good alternative if I just need business contact data?
Scraping websites for emails and phone numbers is the slow, fragile path. A purpose-built B2B data platform gives you verified contact info without any scraping infrastructure - no proxies, no anti-bot workarounds, no maintenance. Free tiers typically let you test before committing.