How to Build a GDPR-Compliant Database From Scratch
You bought a list of 10,000 contacts, loaded them into your CRM, and launched a campaign. Three weeks later, a data subject access request lands in your inbox - and you can't explain where the data came from, why you have it, or how to delete it from every system it's touched. That's not a hypothetical. It's the most common way teams discover they didn't build a GDPR-compliant database from the start.
GDPR fines can reach EUR 20M or 4% of global annual turnover - whichever is higher. Cumulative penalties have now exceeded EUR 6.7B across 2,600+ enforcement actions. The average data breach costs $4.44M globally, and US breaches exceed $10M. Most GDPR database guides are written by lawyers who've never touched a production database, or by vendors pitching their platform. This is the practitioner's blueprint.
You need five things: a documented lawful basis for every data category, purpose-bound schema design with pseudonymization, encryption at rest and in transit, automated retention and deletion workflows, and verified data sources with DPAs. The rest of this guide shows you how to implement each one.
What GDPR Actually Requires From Your Database
Article 5 of the GDPR lays out six principles. Here's what each one means for your database in practice:

| Principle | What It Means for Your DB |
|---|---|
| Lawfulness | Every table needs a documented legal basis |
| Purpose limitation | Columns exist for a stated reason - no "just in case" fields |
| Data minimization | Collect only what you need; drop the rest |
| Accuracy | Stale data = non-compliant data; build refresh cycles |
| Storage limitation | Set TTLs; automate deletion |
| Integrity & confidentiality | Encrypt, restrict access, log everything |
These aren't abstract legal concepts. They're design constraints. Every schema decision, every query, every retention policy should trace back to one of these six principles.
Choose Your Lawful Basis
Here's the thing: consent isn't the only lawful basis, and for B2B prospecting, it's usually not the right one.
Art. 6(1)(a) gives you consent - explicit, freely given, withdrawable at any time. That's the right choice for newsletter signups and cookie tracking. But for B2B outreach, Art. 6(1)(f) legitimate interest is typically more practical and legally sound. Recital 47 explicitly references direct marketing as a potential legitimate interest.
The catch: you need to document a Legitimate Interest Assessment before you process a single record. The three-part test works like this:
- Purpose test - Is there a legitimate business interest, such as reaching potential buyers of your product?
- Necessity test - Is processing this data necessary to achieve that interest? Could you achieve it with less data?
- Balancing test - Do the individual's rights and expectations outweigh your interest?
Document each LIA with these fields: date, processing activity, data source, stated interest, necessity argument, balancing argument, safeguards like opt-out mechanisms and retention periods, and outcome. Keep these in a central repository. When a regulator asks - and they will - you need to produce this in hours, not weeks.
One jurisdiction-specific nuance worth knowing: Spain's rules are stricter for named professional emails than for generic role-based addresses like info@, so structure your outreach and opt-out handling accordingly.
Use consent if you're collecting data directly from individuals for marketing purposes, especially B2C. Renew consent at least annually. Use legitimate interest if you're building B2B prospect lists from professional data sources and can document the balancing test.
Schema Design for Compliance
Purpose-Bound Tables and Consent Logs
Separate personal data from operational data. Your users table shouldn't store marketing preferences, consent records, and billing info in the same row. Split them into purpose-specific tables with clear foreign key relationships.
Every database that processes personal data needs a consent log. At minimum, your schema should track:
user_id- who gave or withdrew consentpurpose- what they consented to, granular, not just "marketing"timestamp- when the action occurredsource- how consent was collected: web form, API, or verbalstatus- active, withdrawn, expired
This isn't optional. When someone withdraws consent for email marketing but not for product updates, you need to know which processing activities to stop - instantly.
Pseudonymization vs. Encryption
Pseudonymization isn't anonymization. If you can reverse it, GDPR still applies. The EDPB's 2025 pseudonymisation guidelines make clear that pseudonymised data remains personal data when re-identification is possible.
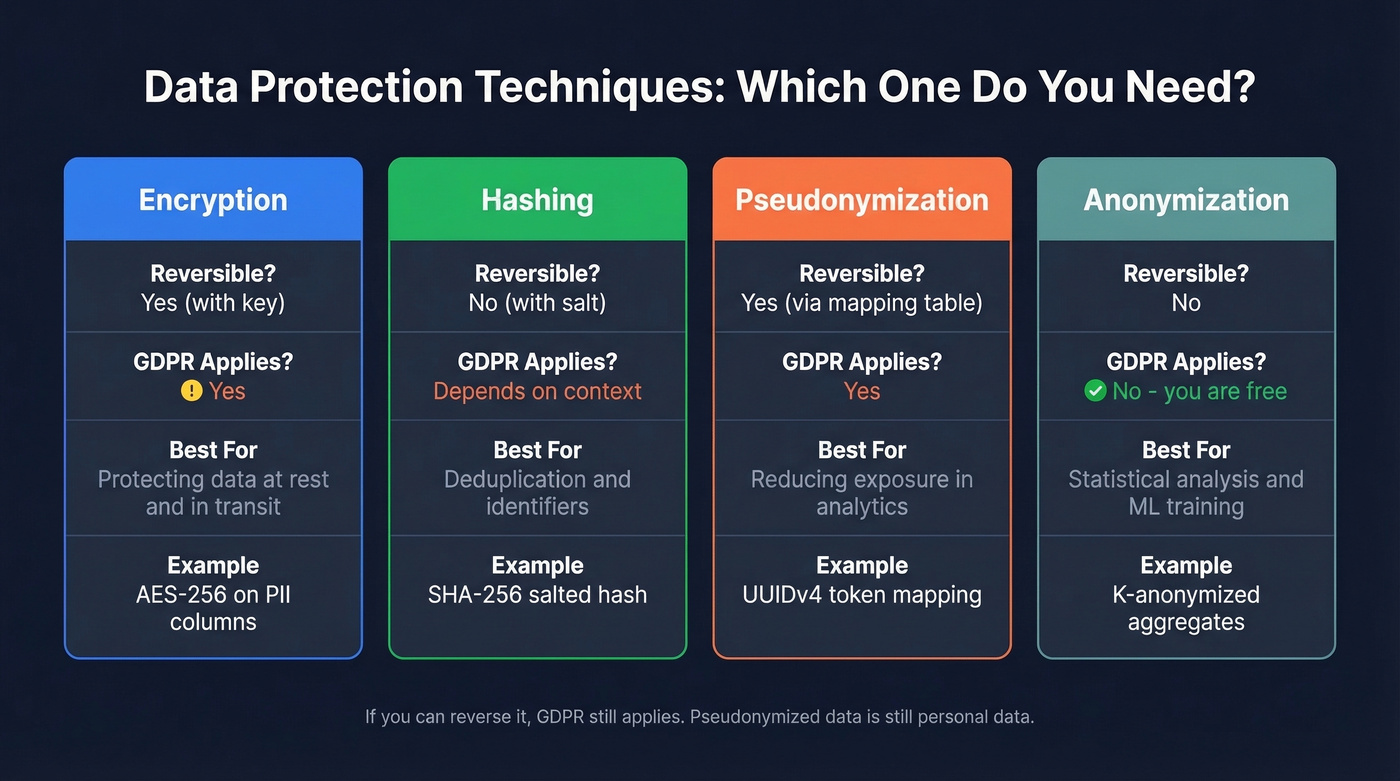
| Technique | Reversible? | GDPR Applies? | Use Case | Example |
|---|---|---|---|---|
| Encryption | Yes (with key) | Yes | Protecting data at rest/transit | AES-256 on PII |
| Hashing | No (with salt) | Depends | Deduplication, identifiers | SHA-256 salted hash |
| Pseudonymization | Yes (via map) | Yes | Reducing exposure in analytics | UUIDv4 token mapping |
| Anonymization | No | No | Statistical analysis, ML training | K-anonymized aggregates |
The practical pattern: replace identifiers with UUIDv4 tokens and store the mapping in a separate, access-controlled table. Your analytics team queries the pseudonymized dataset; only authorized personnel can access the mapping table to re-identify when legally required.
Security Controls
Encryption (Art. 32 & 34)
GDPR doesn't prescribe specific encryption algorithms, but the industry standard is clear: AES-256 at rest, TLS 1.2+ in transit. Art. 32 frames encryption as an "appropriate" technical measure based on risk. Recital 83 reinforces this with an emphasis on confidentiality.
Here's the practical upside most teams miss: Art. 34 says that if breached data is encrypted and unintelligible to unauthorized parties, you don't need to notify affected individuals. That's a massive reduction in breach response cost and reputational damage. Encryption isn't just a compliance checkbox - it's your insurance policy.
Access Control and Audit Logging
The ICO's security guide frames security around the CIA triad - confidentiality, integrity, availability - plus the ability to restore access after incidents and regularly test your measures.
In practice, that means role-based access control with least privilege, MFA on every account that touches personal data, and regular access reviews. Your marketing team doesn't need read access to the full contacts table. Your analytics team doesn't need the pseudonymization mapping table. Lock it down.
If you can't prove who accessed what data and why, you can't demonstrate compliance. Your audit logs should capture the user ID, IP address, and session identifier; the action type such as read, write, delete, or export; the timestamp with timezone; the purpose or justification for access; and the data category accessed. Encrypt logs at rest with AES-256, restrict access via RBAC and MFA, and treat them as immutable records. A log that someone can edit isn't an audit trail - it's a liability.
You just read why stale data violates GDPR's accuracy principle. Prospeo refreshes every record on a 7-day cycle - not the 6-week industry average - so your database stays compliant without manual cleanup. Every email passes 5-step verification with spam-trap and honeypot removal, DPAs are available on request, and global opt-outs are enforced automatically.
Start with data that's accurate, fresh, and GDPR-ready out of the box.
EU Data Residency Architecture
GDPR doesn't mandate EU-only storage. But in practice, many teams provision EU databases to simplify compliance and avoid the headache of Standard Contractual Clauses for every data transfer.
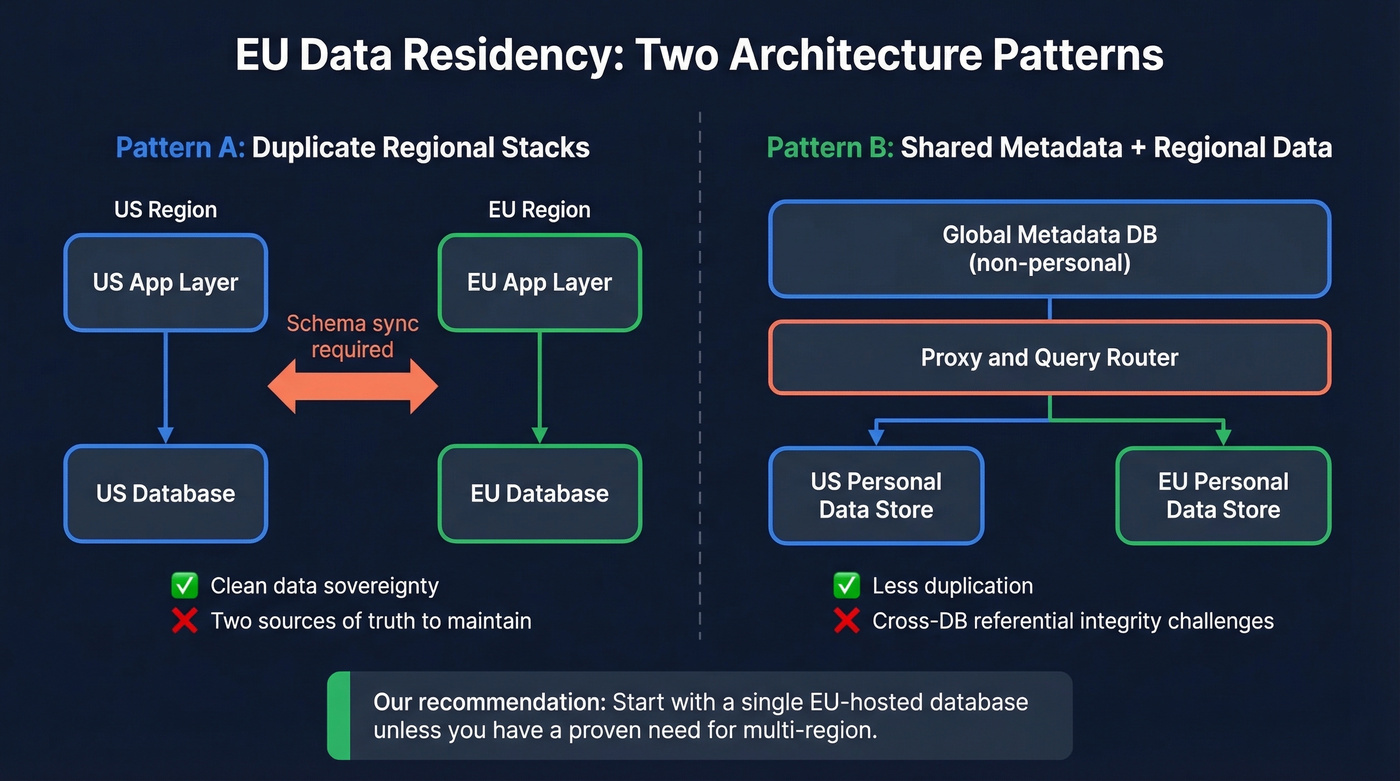
Two patterns dominate.
Pattern A: Duplicate regional stacks. Separate US and EU databases, each with its own application layer. Clean data sovereignty, but you're maintaining two sources of truth and deploying schema changes consistently across both.
Pattern B: Shared metadata + regional data stores. One global operational database for non-personal metadata, with regional databases for personal data. A proxy layer routes queries. Less duplication, but you're dealing with cross-DB referential integrity challenges.
A startup on r/softwarearchitecture reported 3-7x latency increases when splitting a single PostgreSQL database across US app servers and an EU data store, largely due to N+1 query patterns and cross-region roundtrips. Our recommendation: start with a single EU-hosted database unless you have a proven need for multi-region. The complexity of dual stacks isn't worth it for most teams under 100 employees.
Retention and Automated Cleanup
Default to the shortest defensible retention period. If you can't articulate why you're keeping data, delete it.
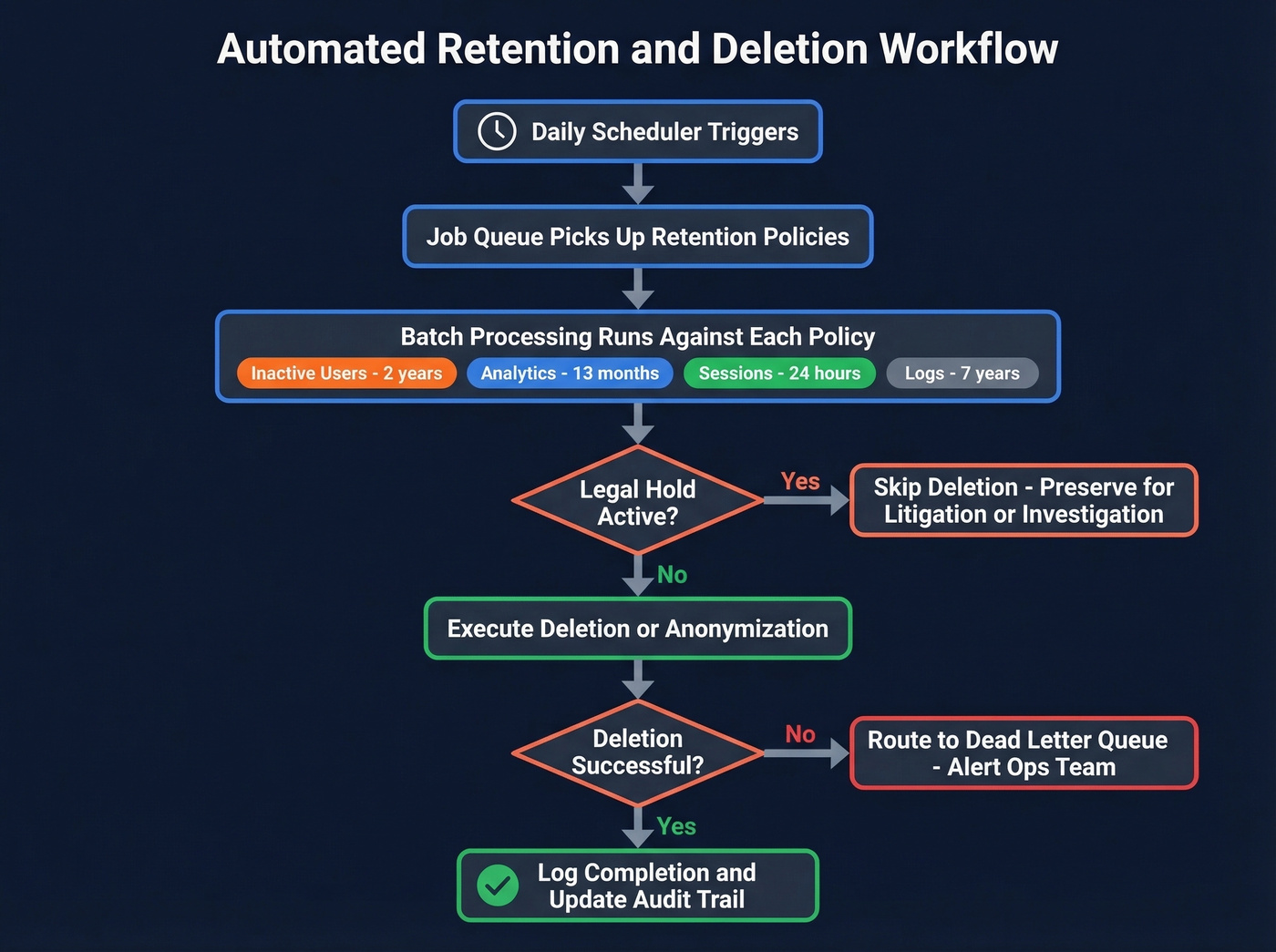
Getting data retention policies that sales teams actually follow requires automating as much as possible - manual policies get ignored the moment pipeline pressure ramps up. We've learned this the hard way watching teams build beautiful retention documentation that nobody enforces.
| Data Type | Retention | Action After Expiry | Basis |
|---|---|---|---|
| Inactive users | 2 years | Soft delete, then hard delete after 90 days | Purpose limitation |
| Analytics events | 13 months | Anonymize | Storage limitation |
| Session data | 24 hours | Auto-delete | Data minimization |
| Audit logs | 7 years | Archive (immutable) | Legal obligation |
| Financial records | 7 years | Archive | Legal obligation |
The implementation architecture that works: a daily scheduler triggers a job queue that runs batch processing against each retention policy. Before any deletion, the job checks for legal holds from litigation or regulatory investigation. Failed deletions route to a dead-letter queue with monitoring alerts. You can build this in a week with a simple cron job and a few database procedures - it doesn't need to be complex to be effective.
Data Subject Rights Workflows
Right to Erasure (Art. 17)
Here's the scenario that burns teams: a customer emails requesting deletion. You remove them from the CRM. But your marketing automation pulls from a backup two days later and re-adds them to a campaign. They file an ICO complaint. You're now explaining why your "deletion" didn't actually delete anything.
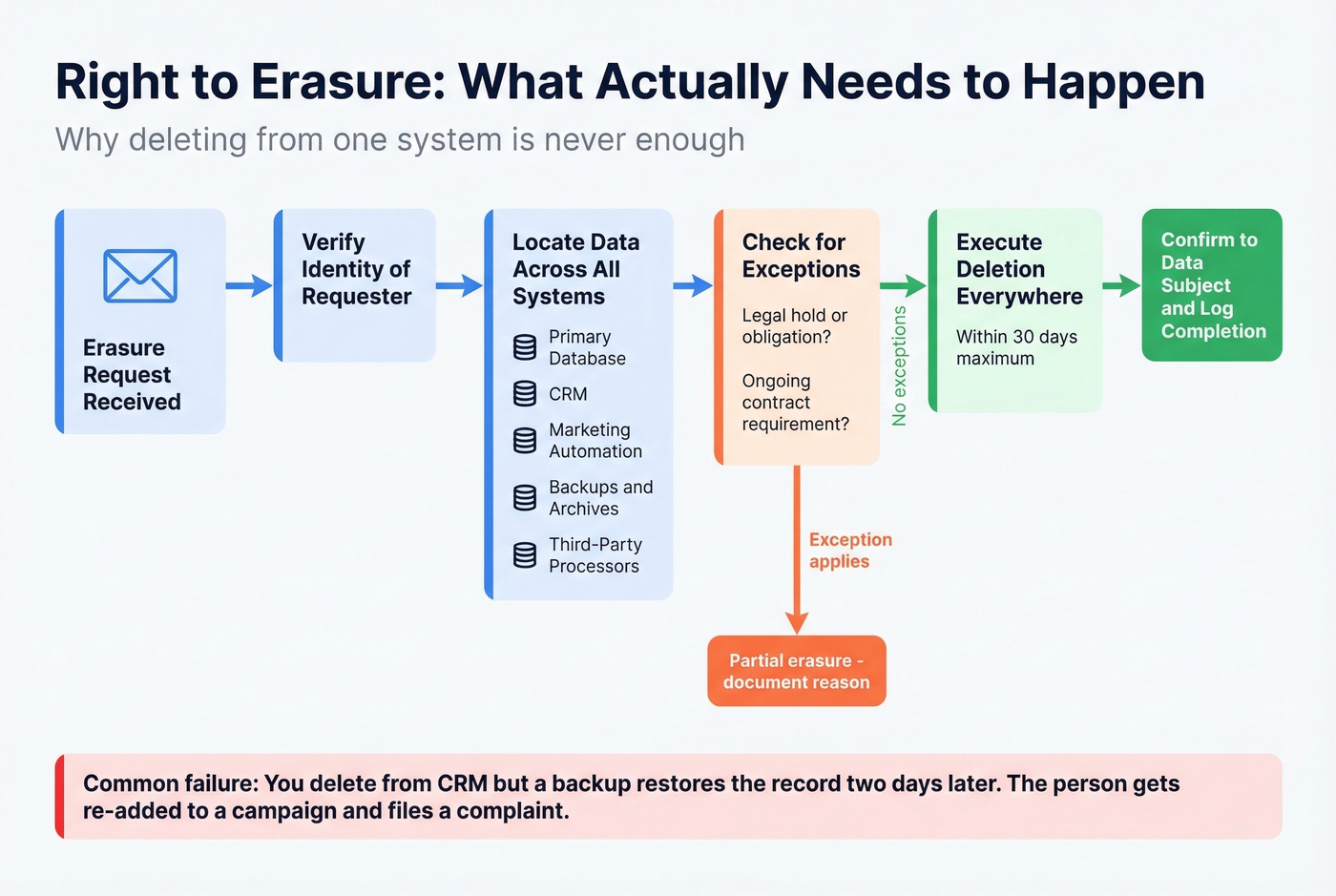
Art. 17 requires erasure "without undue delay" when grounds apply - data no longer necessary, consent withdrawn, objection upheld, unlawful processing, legal obligation, or children's data. The ICO's practical guidance gives you one month to respond. For backups where immediate deletion isn't feasible, the ICO accepts putting data "beyond use" - meaning you don't process it for any purpose and delete it when the backup cycle naturally overwrites. But you need to tell the individual what's happening.
Build a soft-delete to hard-delete pipeline. Soft-delete immediately removes data from all live systems and active processing. Hard-delete purges it from backups on the next cycle. Log every step.
Access and Rectification
Art. 15 gives individuals the right to a copy of their data. Art. 16 gives them the right to correct inaccuracies. For most teams, the practical answer is an automated DSAR response system that can pull all records associated with an identifier, package them in a machine-readable format, and deliver them within the one-month SLA. Teams on r/dataengineering consistently flag backup deletion as the hardest part of DSAR compliance - and in our experience, they're right. Manual DSAR processing doesn't scale past a few dozen requests per month.
Building a Compliant B2B Prospect Database
Everything above applies to your prospect database too - but there's an additional compliance dimension most teams overlook. Art. 5(1)(d) requires that personal data be accurate and kept up to date. Stale prospect data isn't just a deliverability problem. It's processing inaccurate personal data, which is a GDPR violation in its own right.
Let's be honest: if your prospect data is more than 30 days old, you're probably already failing the accuracy principle. The industry average data refresh cycle is six weeks. That's not good enough.
Your data source is a compliance decision. A provider with stale data makes you non-compliant by default. You need a provider that refreshes data frequently, enforces opt-outs globally, and offers a Data Processing Agreement. Prospeo refreshes its 300M+ professional profiles every 7 days with 98% email accuracy and global opt-out enforcement, with DPAs available on request. When you're building prospect lists with 30+ search filters, the data minimization principle is baked in - you're pulling only the contacts that match your ICP, not dumping an entire industry into your CRM.
Pair your data source with documented legitimate interest assessments as covered in the lawful basis section, clear opt-out mechanisms in every outreach, and retention policies that automatically purge prospects who don't engage within a defined window.
Documented data sources. That's what regulators ask for first. Prospeo's Zero-Trust data partner policy means every record comes from vetted sources, verified through proprietary infrastructure - no third-party email providers in the chain. 143M+ verified emails at 98% accuracy, GDPR compliant, with full DPAs so your Legitimate Interest Assessment actually holds up.
Stop scrambling to explain where your data came from.
Ongoing Compliance
Building a compliant database is the first step. Keeping it compliant is where most teams fall apart.
Regular audits - Review processing activities, access controls, and retention policies quarterly at minimum. DPIA triggers - Conduct a Data Protection Impact Assessment before large-scale processing, systematic monitoring, or deploying new technology that touches personal data. Breach response - Art. 33 requires notification to your supervisory authority within 72 hours of becoming aware of a breach. Have a response plan documented and tested before you need it. Records of processing - Art. 30 requires maintaining records of all processing activities. Update it every time you add a new data flow or change a purpose.
A GDPR-compliant architecture also gives you a head start on CPRA, LGPD, and other emerging privacy frameworks - the structural patterns are nearly identical.
Look, compliance isn't a project with a finish line. It's a maintenance commitment. The teams that get fined aren't usually the ones who never tried - they're the ones who built something compliant three years ago and never updated it. If you're going to build a GDPR-compliant database, commit to the ongoing work or it'll unravel the moment regulations shift.
FAQ
Does GDPR require storing data in the EU?
No. GDPR permits storage anywhere, but transfers outside the EU require safeguards like Standard Contractual Clauses or adequacy decisions. Many teams provision EU-hosted databases to simplify compliance and avoid documenting every cross-border transfer.
Is pseudonymized data still personal data under GDPR?
Yes. The EDPB's 2025 guidelines confirm pseudonymized data remains subject to GDPR because re-identification is possible via the mapping table. Only truly anonymized data - where re-identification is impossible - falls outside GDPR scope entirely.
How long do I have to respond to a deletion request?
One month from receipt, per ICO guidance. Complex requests can be extended by two additional months, but you must inform the individual within the first month explaining why the extension is necessary.
What's the best lawful basis for B2B prospecting?
Legitimate interest under Art. 6(1)(f) is more practical than consent for B2B outreach. Document a Legitimate Interest Assessment covering purpose, necessity, and balancing before processing any records. Recital 47 explicitly supports direct marketing as a legitimate interest.
How do I keep prospect data GDPR-compliant over time?
Use a data source that refreshes weekly and enforces opt-outs globally - stale data violates Art. 5(1)(d)'s accuracy requirement. Pair that with automated retention policies and quarterly processing audits.