The Best Data Matching Software for Every Budget and Use Case
Bad data costs the average organization $12.9M per year, according to Gartner. Scale that across the U.S. economy and you're looking at $3.1T in annual damage. Data matching software exists to fix this - finding, linking, and merging duplicate or related records across your systems so you stop making decisions on garbage.
Here's a hot take before we get into the tools: most teams shopping for record-matching software actually have a contact data problem, not an entity resolution problem. The fix is simpler and cheaper than you think.
Data matching often falls under the umbrella of Master Data Management (MDM), but this guide focuses on standalone matching tools you can deploy without buying an entire MDM platform.
Our Picks (TL;DR)
| Use Case | Tool | Why |
|---|---|---|
| B2B contact data accuracy | Prospeo | 98% verified email accuracy |
| No-code for business users | WinPure | 4.7/5 G2, drag-and-drop |
| Most transparent pricing | Match Data Pro | $27/mo, all plans public |
| SAP & enterprise MDM | Syniti | SAP-native, on AWS |
| Open-source | Dedupe / Splink | Free, production-ready |

The 7 Best Data Matching Tools in 2026
Prospeo - Best for B2B Contact Data Matching
Use this if your "data matching problem" is really a contact data problem - duplicate leads with different email addresses, phone numbers that don't connect, CRM records that are 60% complete.
Prospeo covers 300M+ professional profiles and delivers a 92% API match rate. The 7-day data refresh cycle means you're matching against current records, not stale ones - the industry average is six weeks. Upload a CSV or connect via API, and Prospeo returns 50+ enrichment data points per contact, filling the gaps that cause duplicates in the first place.
When two CRM records for the same person carry different emails, Prospeo verifies which one actually works and enriches both with current data. That eliminates the root cause of most B2B duplicates rather than just flagging them after the fact. Pricing is self-serve and transparent: the free tier gives you 75 emails per month plus 100 Chrome extension credits, and paid plans run about $0.01 per email. No contracts, no sales calls required.
WinPure - Best No-Code Matching
We watched a mid-market ops team evaluate WinPure after spending three months trying to build matching logic in Python. They had it running in under a week.
Three tiers structure the product: Essential (up to 100K records per import), Professional (250K), and Enterprise (unlimited with scheduling, automation, and audit logs). G2 gives it 4.7/5 across 74 reviews, with time to implement under one month. WinPure also maintains an 800M-name library with cross-cultural and cross-script matching - a genuine differentiator if your data spans multiple countries and writing systems.
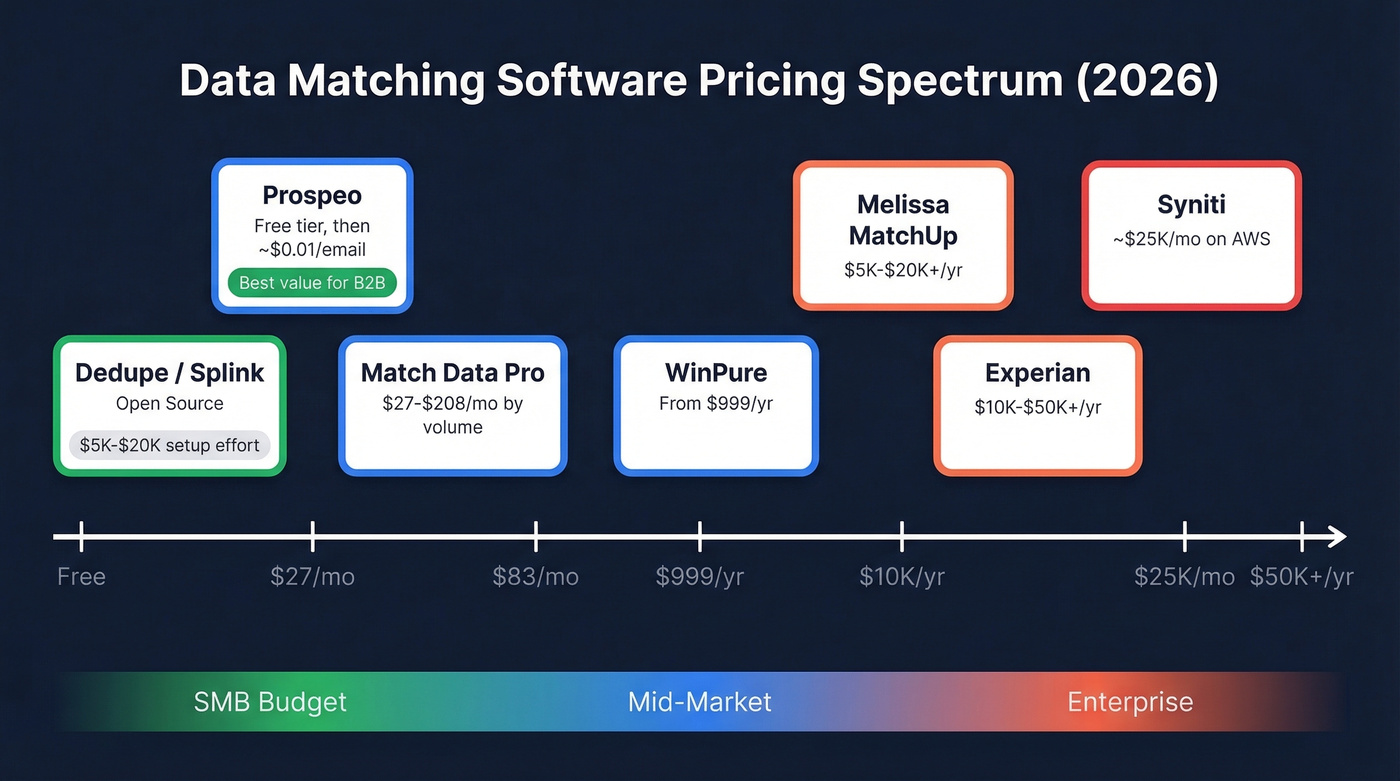
Pricing starts around $999/year. Enterprise pricing is custom. Free trial available. Skip this if you need real-time API matching at scale; WinPure is strongest as a batch tool for periodic cleansing.
Match Data Pro - Most Transparent Pricing
Here's the thing: most data matching vendors hide pricing behind "talk to sales" buttons. Match Data Pro publishes everything. At 10K records: $27/mo for Basic, $38/mo for Advanced, $54/mo for the Complete Platform. At 100K records: $104, $146, and $208/mo respectively. Need entity resolution? The Senzing ER add-on runs $54/mo. Multi-user seats cost $40.25/user/mo.
G2 rates it 5.0/5, though across just 4 reviews - run your own test before committing. One reviewer called setup "under 1 minute." Skip this if you're matching millions of records daily; it's built for SMB-to-midmarket volumes.
Data Ladder - Large-Scale Fuzzy Matching
Data Ladder supports fuzzy, phonetic, exact, and alphanumeric matching across batch scheduling and real-time API workflows. One customer reported a 24% higher match rate versus their previous vendor; another said it "saved us hundreds of person-hours each year." We've seen it handle millions of records without choking, which puts it squarely in enterprise territory.
Pricing is quote-based with a free trial. Expect $10K-$50K+/year depending on volume and modules.
Syniti - Best for SAP Migrations
If you're migrating to S/4HANA, SuccessFactors, or Ariba, Syniti is purpose-built for that workflow. A contract example on its AWS Marketplace listing runs $25,214/mo - enterprise pricing, per terabyte. GetApp rates it 4.3/5 across 24 reviews. The main complaint? Spaces in data fields cause the system problems. A frustrating edge case at this price point.
Experian Data Quality
Enterprise-grade suite covering matching, validation, and enrichment across global datasets. Expect $10K-$50K+/year depending on modules. Experian offers a 30-day free trial for validation products - worth testing if you're already in their ecosystem.
Melissa MatchUp
Strong on address verification and postal data matching, making it a natural fit for logistics, healthcare, and financial services. Pricing runs $5K-$20K+/year. If your matching problem is address-centric rather than entity-centric, Melissa deserves a serious look.
Most CRM duplicates exist because contact data was incomplete from day one - not because your matching logic failed. Prospeo enriches every record with 50+ data points at a 92% API match rate, refreshed every 7 days. Stop deduplicating symptoms. Fix the root cause.
Verify 75 emails free and see how many duplicates were just bad data.
Enterprise data matching tools start at $10K/year and still leave you with stale records refreshed every 6 weeks. Prospeo delivers 98% email accuracy on a 7-day refresh cycle for roughly $0.01 per email - no contracts, no sales calls.
Get enterprise-grade data matching accuracy at 90% less cost.
Pricing Comparison
| Tool | Starting Price | Pricing Model | Free Trial/Tier |
|---|---|---|---|
| Prospeo | Free (75 emails/mo) | Per-email (~$0.01) | Yes - free tier |
| WinPure | ~$999/yr | Annual subscription | Yes |
| Match Data Pro | $27/mo | Monthly by volume | Yes |
| Data Ladder | ~$10K-$50K+/yr | Quote-based | Yes |
| Syniti | ~$25K/mo (AWS) | Contract / per-TB | Contact sales |
| Experian | ~$10K-$50K+/yr | Enterprise contract | 30-day trial |
| Melissa | ~$5K-$20K+/yr | Enterprise contract | Demo available |
Notable omissions: Informatica, IBM InfoSphere, and Profisee all offer data matching as part of broader MDM platforms. They're excluded here because independent pricing and review data is thin - but if you're already evaluating MDM suites, they belong on your shortlist.
Open-Source Alternatives
If you've got engineering resources and want to avoid vendor lock-in, four open-source tools are worth evaluating.

Dedupe (Python) uses an active learning approach that improves with your feedback - best for teams comfortable writing Python who want fine-grained control. Splink (Python/DuckDB) handles large-scale probabilistic linking across millions of records with strong documentation. Zingg (Spark-based) offers ML-powered matching that scales horizontally, a good fit if you're already running Spark. The Python Record Linkage Toolkit is more academic library than product, but solid for standard algorithms.
Avoid FEBRL and FRIL - both are no longer maintained. And let's be honest: "free" software still costs engineering time. Budget $5K-$20K in setup effort for any serious open-source deployment.
How to Evaluate Match Accuracy
Every vendor claims 96%+ accuracy. Those numbers are meaningless without context.
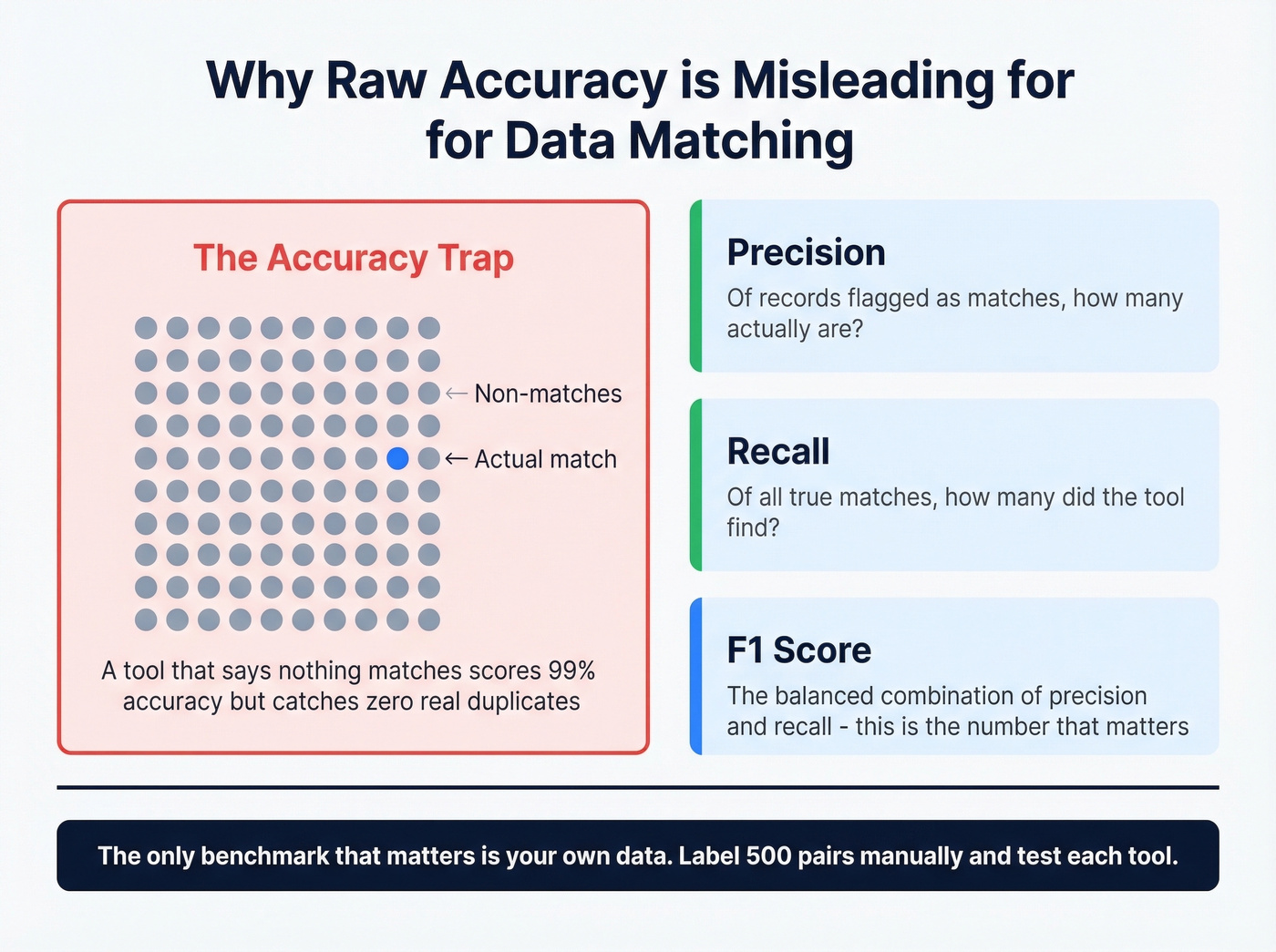
Record-matching datasets are massively imbalanced - 99% of record pairs are non-matches. A tool that labels everything "not a match" scores 99% accuracy while being completely useless. You need precision, recall, and F1 score, not raw accuracy percentages.
The OpenSanctions Pairs benchmark - 755,540 labeled pairs across 293 sources and 31 countries - shows a production rule-based matcher hitting 91.33% F1 while GPT-4o reached 98.95% F1. Rule-based systems tend to over-match (false positives); LLMs struggle with cross-script transliteration. Neither is perfect.
The only benchmark that matters is your own data. In our experience, the bake-off approach consistently reveals which tool handles your specific messiness best. Take your worst 10,000 records, manually label 500 pairs as match/non-match, and test each tool against that ground truth. It's tedious. It's also the only way to know what you're actually buying.
FAQ
What is data matching software?
Tools that find duplicate or related records across datasets using fuzzy, phonetic, and probabilistic algorithms, then merge them into a single golden record. Common use cases include CRM deduplication, patient record linkage in healthcare, and customer identity resolution across marketing platforms.
Deterministic vs. probabilistic matching?
Deterministic matching requires exact field matches - identical SSN, same email address. Probabilistic matching uses weighted similarity scores to find likely matches despite typos, abbreviations, or missing data. Most modern tools combine both approaches for the best balance of precision and recall.
How much does data matching software cost?
Free for open-source tools like Dedupe and Splink. SMB-focused platforms start at $27/month with Match Data Pro. Enterprise solutions run $10K-$25K+/month. For B2B contact deduplication specifically, Prospeo's free tier covers 75 verifications monthly, with paid plans at roughly $0.01 per email.
Can I use a B2B data tool instead of traditional record linkage?
Yes - if your duplicates stem from incomplete contact data rather than true entity resolution challenges. Enriching records with verified emails and 50+ data points eliminates the root cause of most CRM duplicates. Traditional matching tools are better when you need to link records across unrelated databases with no shared identifiers.