How to Automate Data Validation Without Drowning in Rules
A swapped API endpoint at 2 AM. By morning, 14 dashboards are wrong and your analyst is doing row-by-row comparisons in a spreadsheet. That's not a hypothetical - it's what happens when data validation automation doesn't exist. Roughly 60% of business data is inaccurate, and the teams that skip automation spend their weeks cleaning up messes instead of shipping insights.
Here's the thing: most data teams don't need more validation rules. They need fewer, better ones - tuned to the datasets that actually drive decisions. Chase 100% test coverage and you'll drown in alert noise while real issues slip through unnoticed.
Three quick picks if you want to get moving today:
- Soda - warehouse-native, transparent pricing ($0 free / $750/mo Team), fast to deploy
- Great Expectations - expectations-as-code for engineering-heavy teams, free OSS plus a free GX Cloud Developer option
- Monte Carlo - enterprise-scale data observability with lineage, typically ~$100K+/year
Where Automated Validation Fits in Your Pipeline
Validation isn't a single gate. It's checkpoints across three stages:
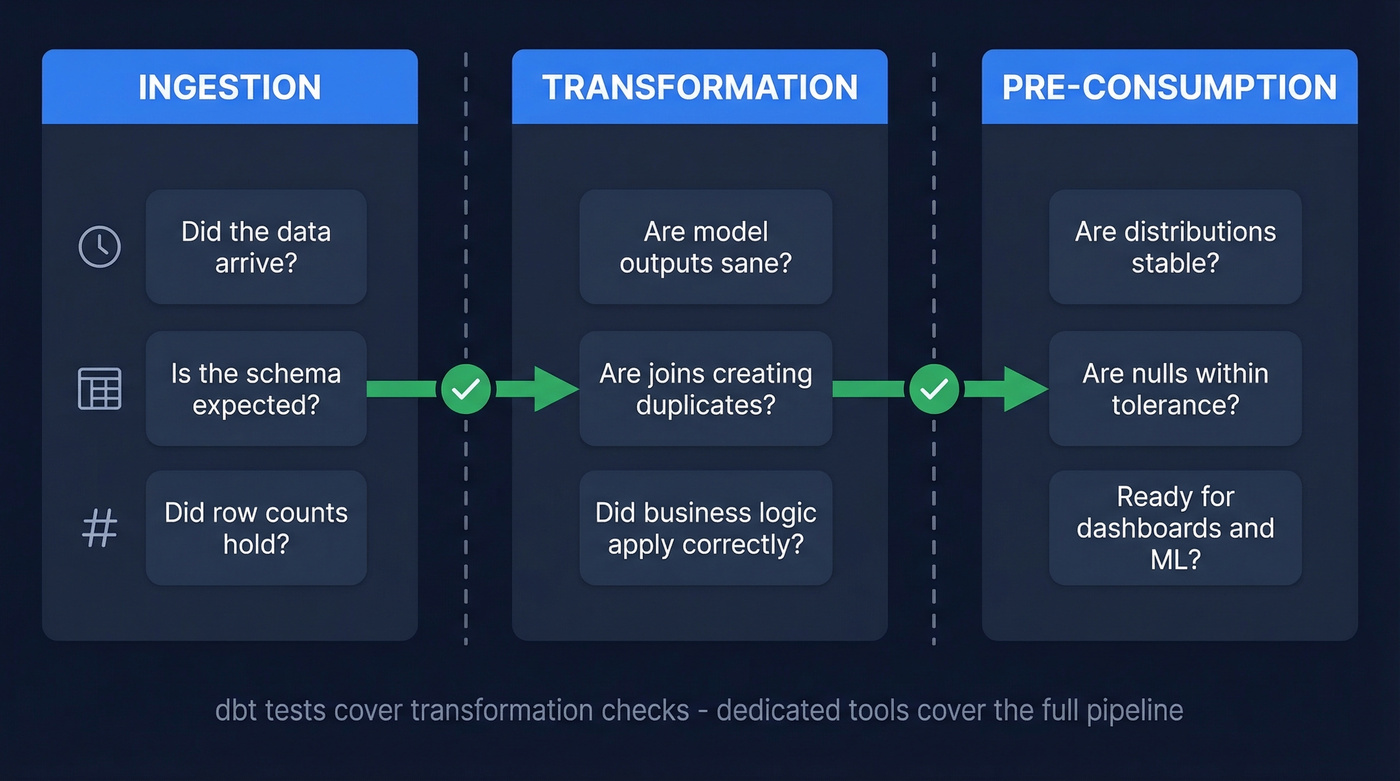
- Ingestion: Did the data arrive? Is the schema what you expected? Did row counts hold?
- Transformation: Did your models produce sane outputs? Are joins creating duplicates?
- Pre-consumption: Before a dashboard or ML model consumes data, are distributions stable? Are nulls within tolerance?
dbt tests validate that transformations ran correctly. They don't give you end-to-end data quality automation. They won't monitor ingestion quality, detect distribution drift, or alert you when an upstream schema changes. In practice, dbt tests and dedicated validation tools are complementary layers: use dbt tests for transform-level assertions, and use a dedicated tool to monitor pipeline health and data behavior over time.
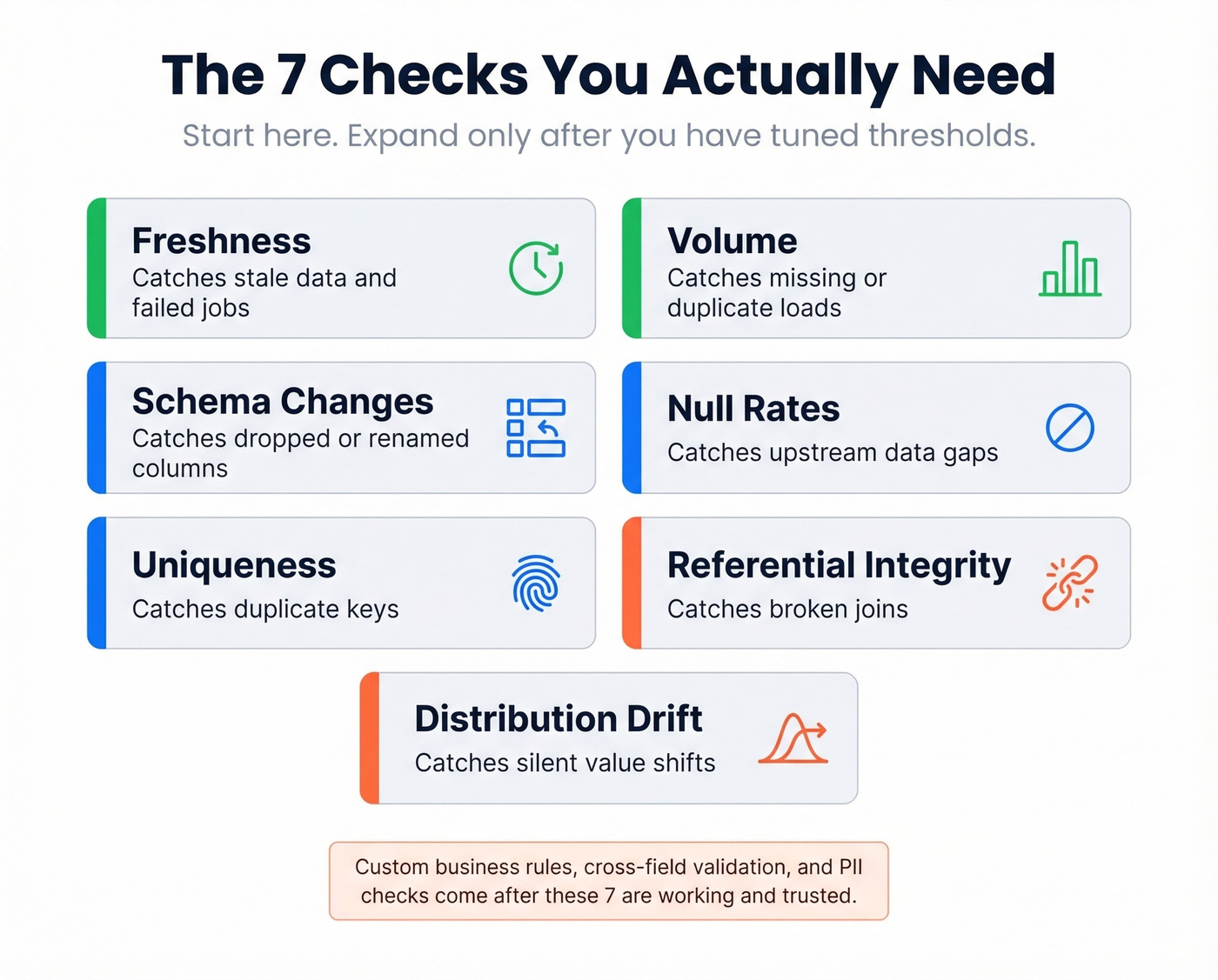
The Minimum Viable Check Set
If you try to automate validation by writing hundreds of brittle rules, you will lose. We've watched teams do this. Start with these seven checks and expand only after you've tuned thresholds:
| Check | What It Catches |
|---|---|
| Freshness | Stale data, failed jobs |
| Volume | Missing/duplicate loads |
| Schema changes | Dropped/renamed columns |
| Null rates | Upstream data gaps |
| Uniqueness | Duplicate keys |
| Referential integrity | Broken joins |
| Distribution drift | Silent value shifts |
These seven cover most common data incidents. Custom business rules, cross-field validation, and PII policy checks come after you've proven the system works and your team trusts the alerts.
You validate freshness, volume, and schema in your warehouse. But what about the contact data flowing into your CRM? Prospeo's 5-step verification catches stale emails, spam traps, and honeypots before they hit your pipeline - delivering 98% email accuracy on 143M+ verified addresses, refreshed every 7 days.
Stop validating warehouse data while letting bad contacts wreck your outbound.
30-60-90 Day Rollout Plan
Days 1-30: Foundation. Deploy freshness and volume checks on your top 3-5 datasets. Wire alerts to Slack or PagerDuty. The goal isn't wall-to-wall coverage - it's proving the system catches real issues without drowning you in noise. In our experience, the biggest mistake teams make here is monitoring too many datasets at once and ignoring every alert within a week.
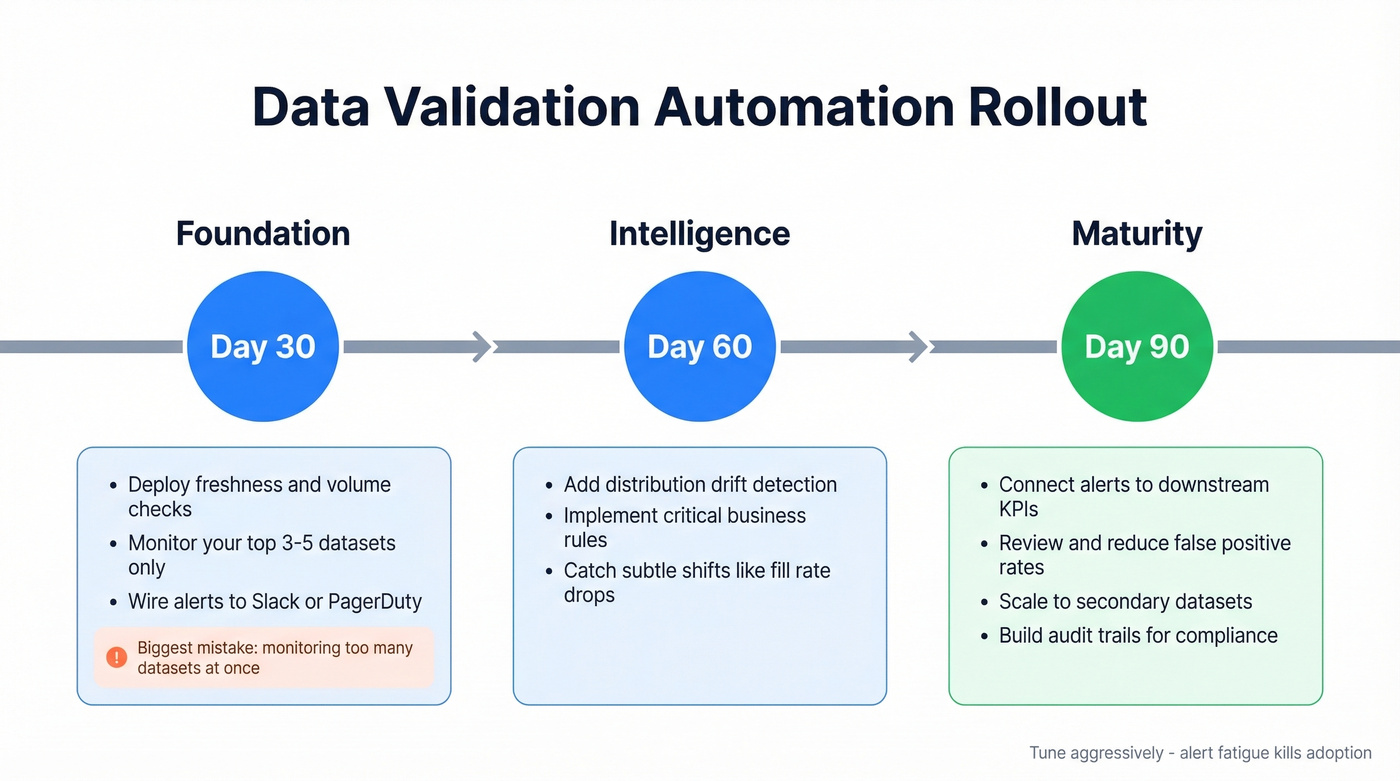
Days 31-60: Intelligence. Add distribution drift detection and your most critical business rules. This is where you start catching the subtle problems - a field that's technically valid but shifted from 80% fill rate to 40%. One team we worked with discovered a vendor had silently changed their date format from ISO 8601 to US-style MM/DD/YYYY, which passed every null and type check but broke downstream cohort analysis for two weeks before anyone noticed.
Days 61-90: Maturity. Connect alert outcomes to downstream KPIs. Review false positive rates. Scale coverage to secondary datasets and connect validation results to audit trails for compliance documentation. A validation system that pages you for every blip isn't automation - it's a new source of toil. Tune aggressively.
Choosing the Right Tool
| Tool | Approach | Best For | Pricing |
|---|---|---|---|
| Soda | YAML-first, SQL to warehouse | Fast deployment teams | $0 free / $750/mo Team |
| Great Expectations | Python-first, expectations as code | Engineering-heavy orgs | Free OSS + free GX Cloud |
| Monte Carlo | Full data observability + lineage | 30+ person data teams | ~$100K+/yr |
| Anomalo | Unsupervised ML detection | Mature enterprises | Enterprise pricing |
| dbt tests | SQL assertions in transforms | dbt-native workflows | Free (OSS) / dbt Cloud |

Soda - Warehouse-Native
Soda's SodaCL language lets you define checks in YAML and pushes SQL directly to your warehouse - no data egress, no Python runtime to manage. Pricing is refreshingly transparent: free for up to 3 production datasets, $750/month (billed annually) for the Team plan with 20 datasets included, and $8/month per additional dataset. Enterprise pricing adds RBAC, audit logs, SSO, private deployment, and premium support.
The CLI returns pass/fail exit codes, making CI/CD integration trivial. We've seen teams go from zero to production checks in under a day. If you're looking for the fastest path to automated data validation without a heavy engineering lift, Soda's the one.
Great Expectations - Code-First
GE is Python-first, which makes it powerful for teams already living in notebooks and Airflow DAGs. The open-source core is free, and GX Cloud offers a free Developer option with Team and Enterprise upgrades. It holds a 4.5/5 on G2 from 11 reviews - users praise the documentation but flag setup friction.
Let's be honest: the number of configuration steps before you write your first expectation is genuinely cumbersome. GE also often runs validation in Python contexts with Pandas or Spark, which can require pulling data into a Python runtime. That's a meaningful difference from Soda's warehouse-native approach, where SQL gets pushed to the warehouse by default.
Monte Carlo - Enterprise Observability
Use this if you're running a 30+ person data team and need lineage, anomaly detection, and multi-workspace support. Skip this if you're a 5-person analytics team - it's overkill and the price tag reflects that.
Monte Carlo is commonly packaged across three tiers: Start (up to 10 users, up to 1,000 monitors, 50+ native connectors), Scale (unlimited users, 50,000 API calls/day, pay-per-monitor billing), and Enterprise (AI-powered anomaly detection, end-to-end lineage mapping, multi-workspace support). The consensus on r/dataengineering is that Monte Carlo is excellent once you hit scale, but the onboarding and contract process can be slow for smaller orgs.
Anomalo - ML Anomaly Detection
Anomalo uses unsupervised ML to detect anomalies without predefined rules - it learns your data's patterns and flags deviations. Its ML routines resolve 80% of anomalies without human intervention. Best for mature enterprises on Snowflake, BigQuery, or Databricks. Not built for streaming. Pricing isn't public but falls in the same enterprise range as Monte Carlo.
Validate Contact Data Pipelines Too
Automated data validation isn't only for warehouses. If your RevOps team ingests prospect and contact data into a CRM or sequencer, that data degrades fast - people change jobs, emails go stale, phone numbers rotate.
For contact data specifically, Prospeo runs a 5-step verification process with catch-all handling, spam-trap removal, and honeypot filtering. That delivers 98% email accuracy and a 92% API match rate, with records refreshing every 7 days compared to the 6-week industry average. If you're piping prospect data into Salesforce or HubSpot, its enrichment API returns 50+ data points per contact, keeping your pipeline clean without manual list scrubbing. If you're evaluating vendors, compare data enrichment services and how they handle refresh cycles.
Your data validation stack catches schema changes and distribution drift. But contact decay is the silent pipeline killer - people change jobs, emails bounce, phones disconnect. Prospeo refreshes 300M+ profiles every 7 days (not the 6-week industry average) so your CRM enrichment stays clean without manual checks.
Automate contact validation at $0.01 per email with 98% accuracy.
FAQ
How many checks should I start with?
Start with 5-7 checks on your most critical dataset: freshness, volume, schema, nulls, and uniqueness. Expand only after you've tuned alert thresholds and assigned clear ownership. More checks doesn't mean better coverage - it usually means more noise.
Can dbt tests replace a dedicated validation tool?
No. dbt tests validate that transformations ran correctly - they don't monitor ingestion quality, detect distribution drift, or alert on upstream schema changes. Use dbt tests alongside a dedicated observability tool as complementary layers. The dbt documentation is clear about this scope.
How do I validate contact data in outbound pipelines?
Use a verification tool that checks emails and phone numbers before they enter your CRM or sequences. Stale data is the number one cause of deliverability drops in outbound - automate the check or pay for it later in bounced sends and damaged sender reputation.