
5 Best Replicate Labs Alternatives for Faster, Cheaper GPU Inference
Replicate's founder said it best on Hacker News: "our cold boots suck." When the person who built the platform admits the biggest pain point out loud, you know it's real. If your production app leaves users staring at a spinner for 15-20 seconds while your model wakes up, it's time to look elsewhere.
Three quick picks before we get into the details:
- Modal - Best overall. Sub-second container provisioning, Python-first DX, H100 at $3.95/hr. $30/mo in free credits.
- fal.ai - Cheapest GPU rates. $1.89/hr for an H100. Built for image and video generation.
- RunPod - Best budget option. Active Workers eliminate cold starts at $3.35/hr H100.
Why Developers Leave Replicate
Cold starts kill production UX. Latency can hit 15-20 seconds on some workloads. Custom model boot times stretch to 2-3 minutes if you're lucky - practitioners on HN report waits up to 30 minutes during bad stretches. For anything user-facing, that's a dealbreaker.

The math doesn't stretch. One Reddit user calculated that $60/month only buys roughly 22 GPU-hours on Replicate. At $5.49/hr for an H100, costs compound fast once you're past prototyping.
Inference-only environment. Replicate is inference-only by design. Need to iterate on models and serve them from the same platform? You're stitching together two workflows.
GPU Pricing Compared
Here's the normalized comparison most guides skip. All rates pulled from official pricing pages as of early 2026. Billing units vary by platform. Replicate also offers per-output pricing for popular public models (FLUX dev at $0.025/image), which can be cost-effective at low volume.
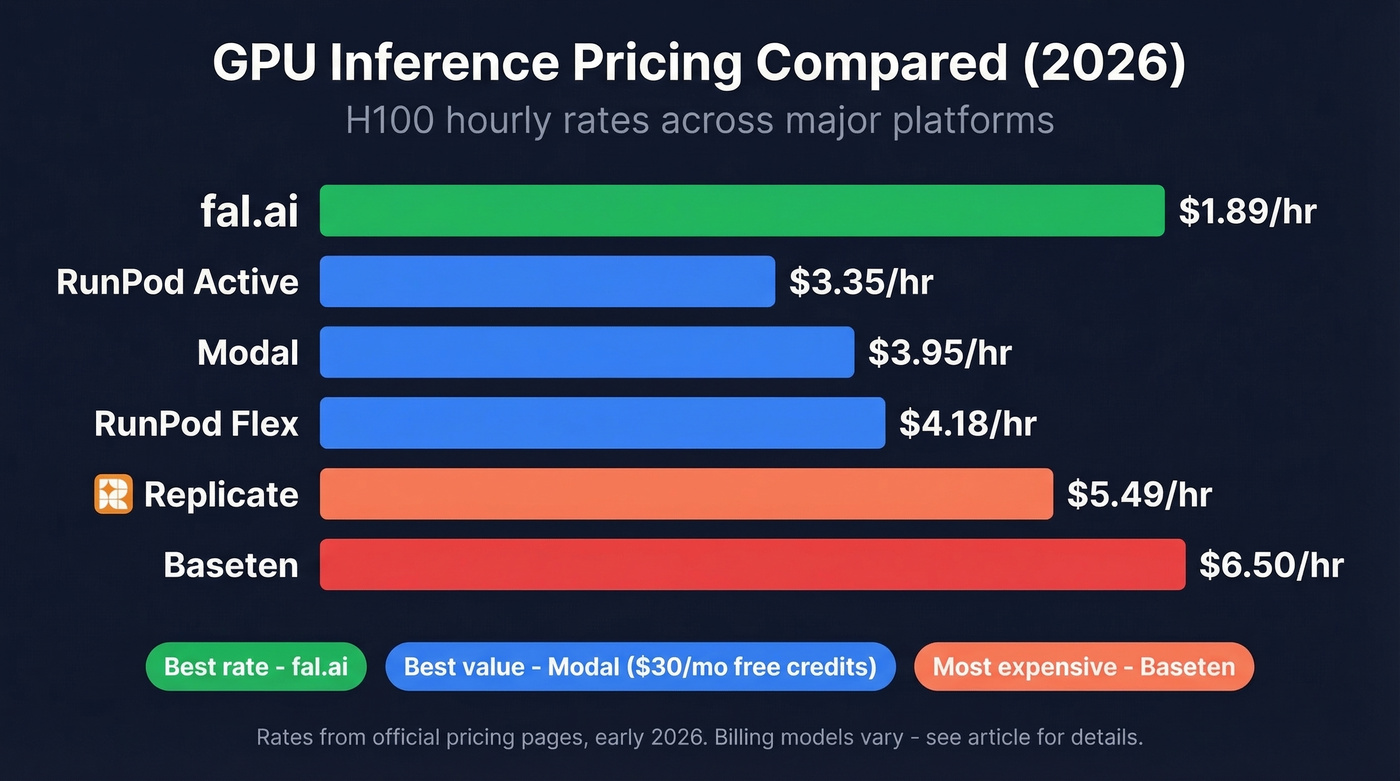
| Platform | H100/hr | A100 80GB/hr | Billing | Free Tier |
|---|---|---|---|---|
| Replicate | $5.49 | $5.04 | Per-second | None |
| Modal | $3.95 | $2.50 | Per-second, no idle | $30/mo credits |
| fal.ai | $1.89 | $0.99* | Per-second; billed across runner states | None listed |
| RunPod (Flex) | $4.18 | $2.72 | Per-hour | None listed |
| RunPod (Active) | $3.35 | $2.17 | Always-on | None listed |
| Baseten | $6.50 | $4.00 | Per-minute; no idle charges | $0/mo basic |
*fal.ai A100 rate is for the 40GB variant. T4 rates: Replicate $0.81/hr, Modal $0.59/hr.
The billing model matters as much as the hourly rate. Modal never charges for idle time. fal.ai bills across runner states - setup, idle, running, draining, and terminating - so your effective cost can run higher than the headline number for bursty workloads.
The 5 Best Alternatives to Replicate
Modal
Modal is the alternative we think most teams should evaluate first, and it's the strongest option for production workloads.
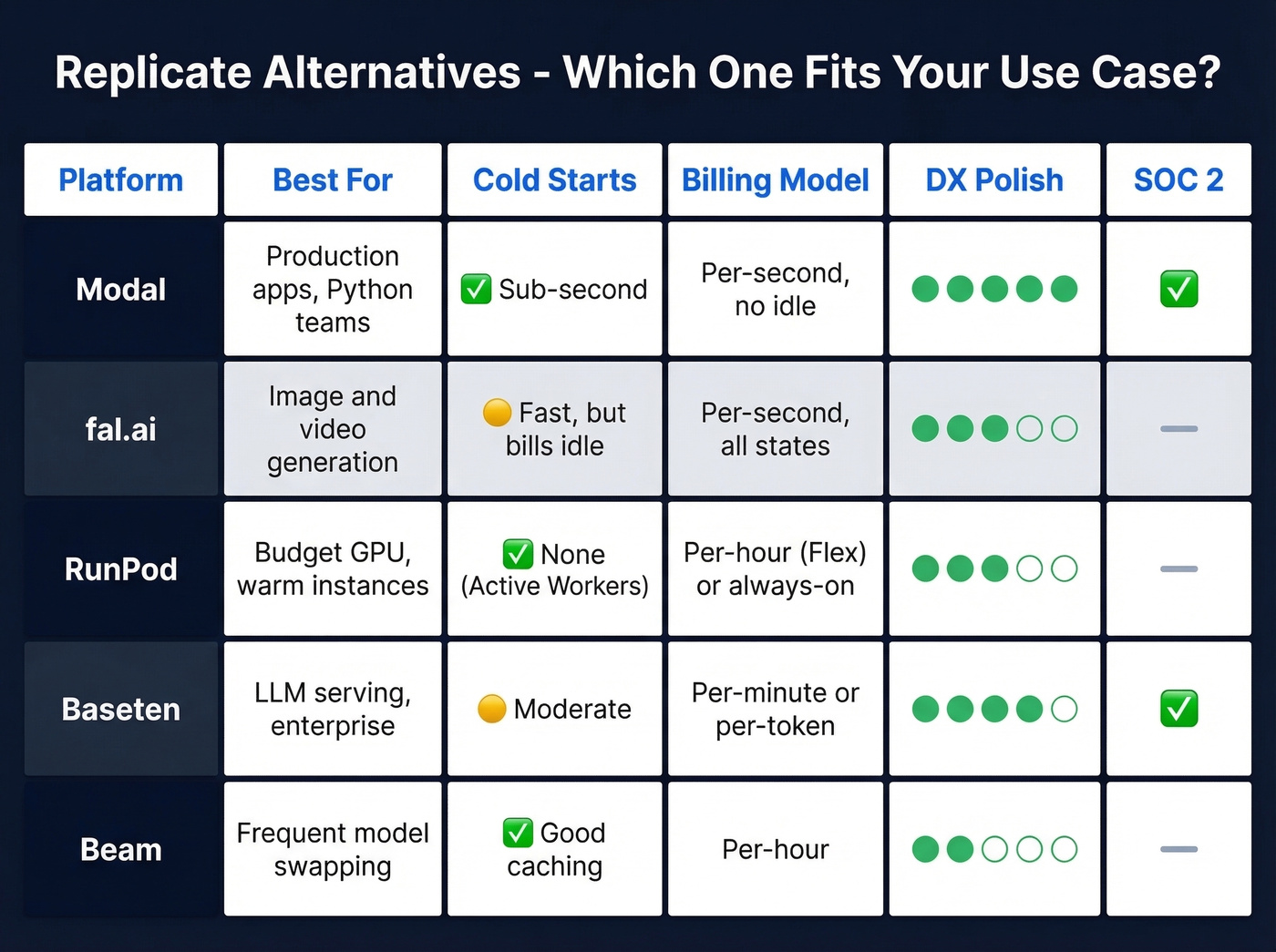
Use it if you want Python-first infrastructure with no YAML, sub-second container provisioning, and zero idle billing. The H100 runs at $3.95/hr - 28% cheaper than Replicate. The Starter plan includes $30/mo in free credits, enough to prototype without pulling out a credit card. SOC 2 compliant. The developer experience is genuinely good: you define GPU requirements with Python decorators, push code, and Modal handles the rest. No Dockerfiles unless you want them. For teams coming from Replicate's Cog-based workflow, the reduction in boilerplate is dramatic - we've seen engineers get a custom model deployed in under an hour on their first try.
Skip it if you just need a pre-built model API and don't want to write infrastructure code. Replicate's model library is still unmatched for quick experimentation.
fal.ai
Use it if you're building image or video generation pipelines and GPU cost is your primary constraint. At $1.89/hr for an H100, fal.ai is the cheapest option here by a wide margin. Flux Kontext Pro runs $0.04/image. 5xx errors aren't billed - a detail that matters at scale.
Skip it if you have bursty, unpredictable traffic. Here's the thing: fal bills for every runner state including setup and idle time. We've run the numbers, and for spiky workloads, Modal's no-idle billing can actually cost less despite the higher hourly rate. Model your own traffic pattern before committing.
RunPod
RunPod's killer feature is the Flex vs Active Worker split. Flex Workers scale to zero at $4.18/hr for an H100. Active Workers stay warm at $3.35/hr, eliminating cold starts entirely.
HN practitioners mention RunPod positively for no-frills serverless GPU compute, and the pricing is transparent enough that you won't get invoice surprises. It's the pragmatic choice for teams that want warm GPUs without enterprise sales calls. The tradeoff? Less developer tooling polish than Modal. You're closer to the metal, which is either a feature or a bug depending on your team.
Baseten
Baseten targets a different buyer. Their per-token LLM pricing - DeepSeek V3.1 at $0.50/$1.50 per 1M tokens - makes sense if you're serving language models and want costs tied to usage rather than GPU-hours. Dedicated H100s run $6.50/hr, the most expensive here, but there are no idle charges. SOC 2 compliant, with Enterprise options for VPC and hybrid deployments.
The pick for teams that want a more "platform" feel than raw serverless GPUs.
Beam
One HN practitioner called Beam "so much better" than Replicate for cold starts, praising its caching and volumes for fast model/LoRA switching. Pricing runs roughly $0.50-2.00/hr depending on GPU tier. Worth evaluating if you swap models frequently, though it's the smallest platform on this list and documentation can be thin in spots.
You're optimizing GPU costs down to the penny - don't feed your AI models stale contact data. Prospeo's enrichment API returns 50+ data points per contact at a 92% match rate, with every record refreshed on a 7-day cycle. At ~$0.01/email, your data layer costs less than a single minute of H100 compute.
Clean input data, clean output. Start enriching for free.
How to Choose
Let's be honest: most teams shopping for Replicate competitors don't actually need the most powerful GPU tier. If your p95 latency requirement is under 500ms, you need warm instances - not faster hardware.
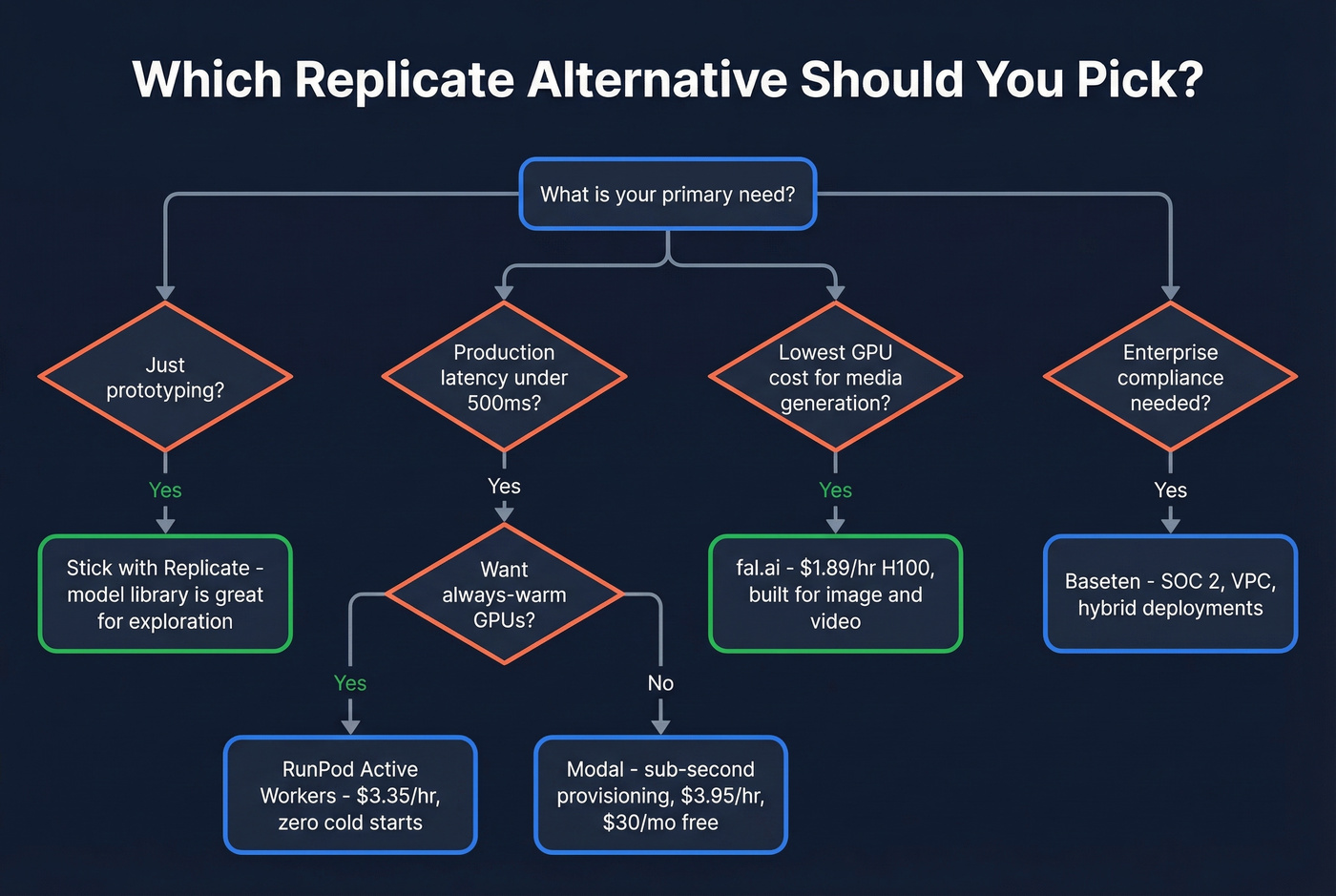
Prototyping? Replicate is still fine. The model library and web UI are excellent for exploration.
Production latency? Modal for sub-second provisioning, or RunPod Active Workers if you want always-warm GPUs.
Budget GPU or media generation? fal.ai for the lowest per-image rates, RunPod Flex for general compute.
Enterprise MLOps with compliance needs? Baseten for SOC 2 and VPC/hybrid options. Need BYOC? Look at Northflank.
Building AI-Powered B2B Apps?
If you're building AI-powered prospecting or lead-scoring tools, your inference stack is only half the equation. The data feeding your models matters just as much. Prospeo's enrichment API covers 300M+ professional profiles with a 92% match rate and 98% email accuracy, refreshed on a 7-day cycle. For developers wiring up AI pipelines that touch business contacts, it's the cleanest input data we've found.
If you're also evaluating data enrichment services or building a repeatable lead enrichment workflow, it helps to benchmark match rate, refresh cadence, and coverage before you lock in your inference stack.
Building AI-powered lead scoring or prospecting tools on Modal, fal.ai, or RunPod? Your model is only as good as the data pipeline behind it. Prospeo gives you 300M+ verified profiles with 98% email accuracy and 125M+ mobile numbers - all accessible via a single API call with a 92% match rate.
Ship faster with data your models can actually trust.
Replicate Labs - A Disambiguation
Replicate Labs (replicatelabs.com) is a separate AI sales coaching platform - not the ML inference service covered here. If you're looking for alternatives to the sales coaching platform, that CB Insights page covers it. This article covers Replicate (replicate.com), the GPU inference platform.
FAQ
Is Replicate good for production apps?
Replicate's DX is excellent for prototyping, but cold starts of 15-20 seconds - and custom model boots that can stretch to minutes - make it risky for user-facing workloads. Modal or RunPod Active Workers are safer bets when latency matters.
Which Replicate alternative has the cheapest GPU rates?
fal.ai at $1.89/hr for an H100 is the lowest headline rate. But fal bills for all runner states including idle, so for bursty workloads Modal at $3.95/hr with zero idle billing can cost less in practice.
Can I run custom models on these platforms?
Yes. Modal, RunPod, Baseten, and Beam all support custom model deployments. Modal uses Python decorators so you typically don't need Dockerfiles. Replicate supports custom models via Cog, but boot times for custom containers are the main pain point driving teams to these alternatives.