Sales Forecasting Algorithms: What Actually Works (and What Doesn't)
Most teams think they're using sales forecasting algorithms - weighted pipeline, historical run-rate, rep intuition. Those aren't algorithms. They're spreadsheet exercises, and the confidence numbers reflect it: fewer than 50% of sales leaders trust their own forecasts.
Here's the thing: you probably don't need a fancier algorithm. You need cleaner data and a proper baseline.
Decision Framework (Start Here)
- Less than 12 months of data: Exponential smoothing or ARIMA. Don't touch ML - you'll overfit and produce garbage.
- 12+ months of clean CRM data: XGBoost is usually the best accuracy-to-complexity tradeoff in production.
- Pipeline revenue forecasting: Monte Carlo simulation over weighted pipeline. Every time.

If your data is messy, no algorithm saves you. Fix that first.
Algorithms That Actually Matter
Classical: ARIMA & Exponential Smoothing
These are your baselines, and baselines matter more than most teams realize.
Exponential smoothing works with short history and stable patterns - it weights recent observations more heavily and needs minimal tuning. ARIMA and its seasonal variant SARIMA handle trends and seasonality explicitly, which makes them strong defaults for many revenue time series. Prophet is another solid option here, especially if you want automated changepoint detection without manual tuning.
Every ML model should be benchmarked against simple baselines like seasonal naive plus a well-tuned ETS/ARIMA-style model. If your fancy model can't beat exponential smoothing, the problem isn't the algorithm - it's your features.
Machine Learning: XGBoost & Random Forest
This is where most teams should land. A peer-reviewed 2025 benchmark across five retail MSMEs found Random Forest hit a MAPE of 8.5% versus 15.2% for traditional smoothing - nearly half the error rate. Across domains, AI models deliver up to 35% better accuracy than traditional methods when the underlying data is clean.
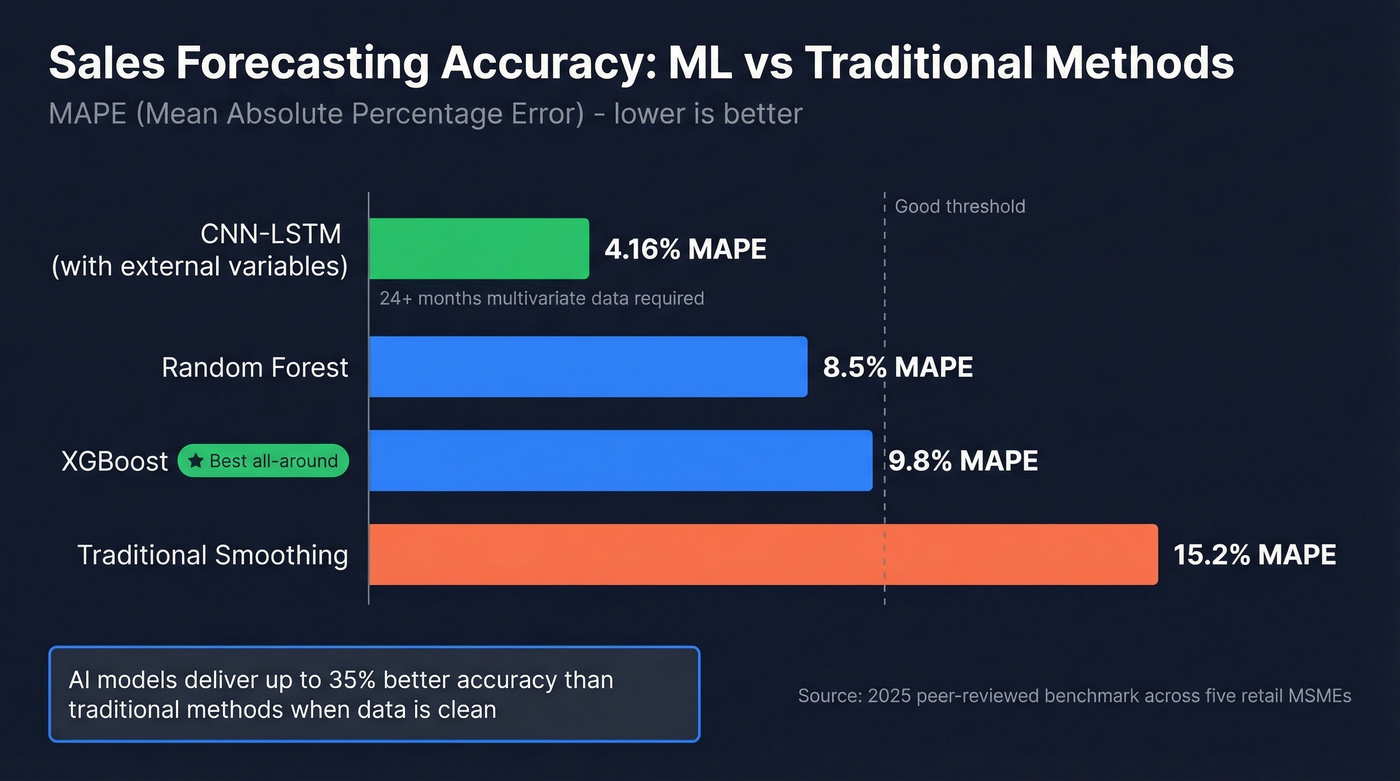
The gains come from feature engineering. Lag features, rolling averages, and exogenous variables like marketing spend matter more than which tree algorithm you pick. XGBoost edges out Random Forest in practice because it handles feature interactions more aggressively, and SHAP values let you show a VP of Sales why the model predicts a down quarter instead of just handing them a number.
Our take: In most B2B forecasting setups, XGBoost with a small set of well-chosen features will outperform whatever deep learning model you throw at the problem. We've benchmarked this repeatedly - complexity doesn't pay until your data justifies it.
Deep Learning: LSTM & CNN-LSTM
Deep learning wins with long histories, rich covariates, and enough data to justify the complexity. A hybrid CNN-LSTM model incorporating external variables - holidays, weather, salary days - achieved a MAPE of 4.16% on retail sales data. That's impressive.
But context matters. In a separate 2025 benchmark on e-commerce data, LSTM posted an R-squared of 0.561 while SARIMA and XGBoost both went negative at -1.41 and -2.33 respectively, meaning they performed worse than simply predicting the average. Algorithm superiority is always dataset-dependent. Always.
Skip LSTM unless you have 24+ months of multivariate data and a data science team that can maintain the pipeline. For everyone else, it's overkill.
Monte Carlo for Pipeline
Your VP of Sales has a whale deal at 70% probability. That's $500K x 0.70 = $350K in "expected revenue." Except that deal is either $500K or $0 - there's no universe where you close $350K of it.
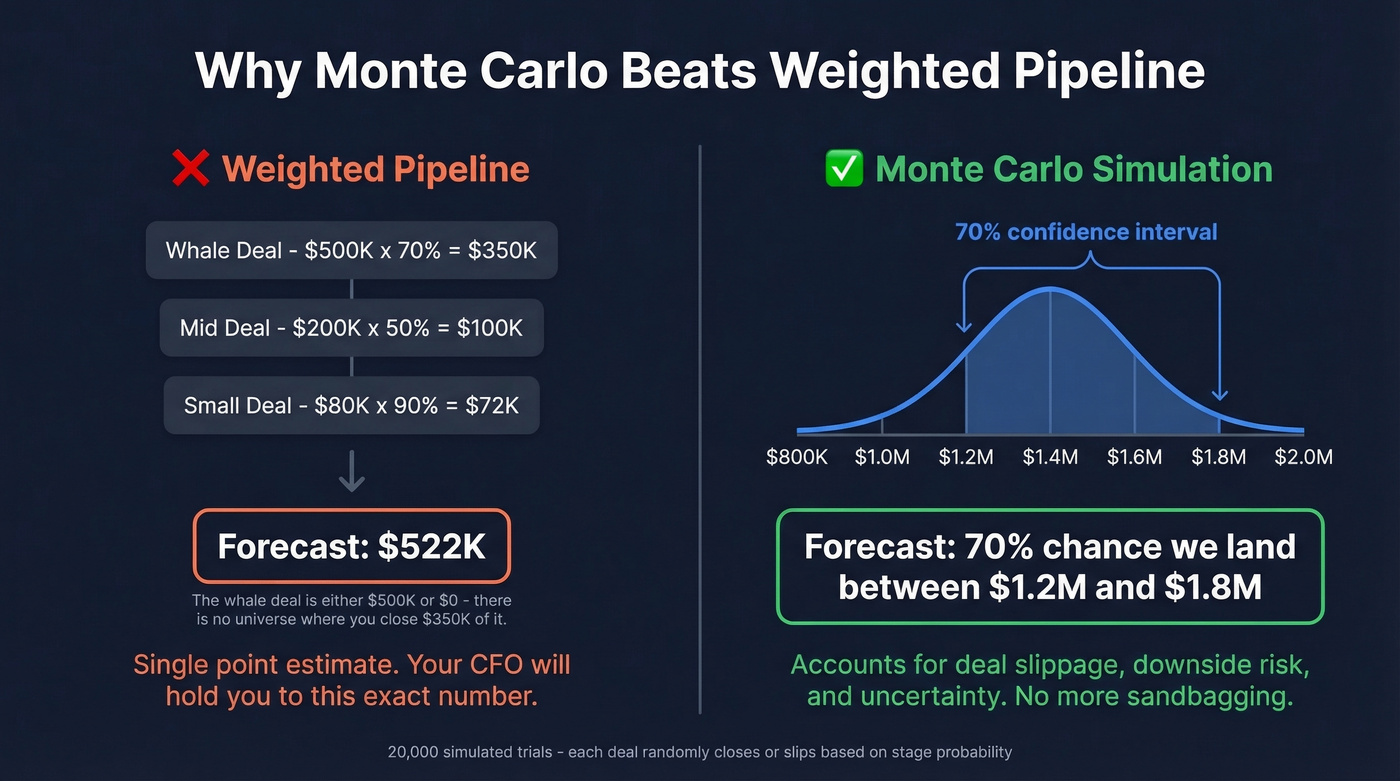
Monte Carlo simulation runs 20,000 trials where each deal randomly closes or doesn't based on stage probability, modeling slippage by shifting 15% of pipeline up to 30 days later. The output is a distribution - "70% chance we land between $1.2M and $1.8M" - which is infinitely more useful than a point estimate your CFO will hold you to. We've seen teams adopt Monte Carlo and immediately stop sandbagging their forecasts because the range already accounts for downside risk.
Choosing the Right Algorithm
| Algorithm | Best For | Min Data | Complexity |
|---|---|---|---|
| Exp. Smoothing | Short history, baselines | 6 months | Low |
| ARIMA/SARIMA | Trend + seasonality baselines | 12+ months | Low-Med |
| Random Forest | Tabular data, many features | 12+ months | Medium |
| XGBoost | Best all-around ML | 12+ months | Medium |
| LSTM | Long sequences, rich data | 24+ months | High |
| CNN-LSTM | Multivariate, external vars | 24+ months | Very High |
| Monte Carlo | Pipeline probability | Active pipeline | Low-Med |
No forecasting algorithm survives dirty CRM data. If 30% of your pipeline contacts are stale, your model is predicting against phantom deals. Prospeo's 98% email accuracy and 7-day data refresh keep your pipeline grounded in reality - so your forecasts actually hold.
Stop feeding garbage data into sophisticated models.
When Forecasting Models Fail
Only 7% of organizations achieve 90%+ forecast accuracy. The algorithm usually isn't the problem.

A data scientist on r/datascience shared a telling case: they built an XGBoost model with 15 engineered features across thousands of SKUs. The result? Absurdly high predictions for near-zero-selling items. Sparse, zero-inflated data broke the model completely, and no amount of hyperparameter tuning fixed it. The consensus in that thread was blunt - garbage data in, garbage forecasts out, regardless of model sophistication.
We've seen the same pattern in pipeline forecasting. If 30% of your pipeline contacts bounce when reps actually email them, your stage probabilities are built on phantom opportunities. The forecast is already broken before any model runs. Tools like Prospeo, with 98% email accuracy and a 7-day refresh cycle, fix this upstream - your CRM reflects real, reachable contacts instead of stale data from six weeks ago.
The top failure modes:
- Dirty CRM data - stale contacts, optimism bias in stage assignments, inconsistent definitions across teams
- No baseline model - you can't know if XGBoost is better if you haven't tried seasonal naive first
- Sparse or zero-inflated data - tree models produce nonsense on segments with mostly zeros
- Ignoring seasonality - a model trained on Q4 data will hallucinate revenue in Q1
- Overfitting - 95% accuracy on training data, 40% on next quarter's actuals
Putting It Into Production
Getting a model into a Jupyter notebook is 20% of the work. Let's be honest - most forecasting projects die in the gap between "it works on my laptop" and "it runs every Monday at 6am." A production-grade stack looks like this:

- Data processing and validation
- Model training (XGBoost or Random Forest)
- Experiment tracking (MLflow)
- Orchestration (Prefect)
- Deployment (Flask + Docker)
- Monitoring (Evidently AI + Grafana)
The monitoring layer is non-negotiable. You're watching for data drift, concept drift, and prediction drift. Any of these should trigger retraining - not on a fixed schedule, but when drift thresholds are breached. Most teams skip monitoring entirely and wonder why their model degrades after two quarters. Set up alerts from day one. If you don't, you'll discover the model broke three months ago when your CFO asks why Q3 actuals missed the forecast by 40%.
Monte Carlo simulations and XGBoost models need real stage probabilities - not ones inflated by unreachable contacts. Prospeo enriches your CRM with 50+ verified data points per contact at $0.01/email, so every deal in your pipeline represents a real, reachable buyer.
Better forecasts start with contacts that actually pick up the phone.
FAQ
What's the best algorithm for small datasets?
Exponential smoothing or ARIMA. ML models need at least 12 months of clean, consistent data to outperform simple baselines. Start with a seasonal naive forecast - if your model can't beat "same month last year," it's not ready for production.
How do you measure forecast accuracy?
MAPE is the most common metric - it expresses error as a percentage of actual values, making it intuitive across scales. Track RMSE for sensitivity to large errors and R-squared for overall fit. In the peer-reviewed benchmark linked above, Random Forest achieved 8.5% MAPE versus 15.2% for traditional smoothing.
Why do accurate models still produce bad forecasts?
Dirty pipeline data is the most common culprit. If 30%+ of your contacts are stale or unreachable, stage probabilities are fiction. No algorithm compensates for garbage in - the fix is upstream data quality, not a better model.
Which sales forecasting algorithms are most accurate?
It depends on your data. With 24+ months of multivariate history, CNN-LSTM models have achieved MAPE as low as 4.16%. For most B2B teams with 12-18 months of CRM data, XGBoost delivers the best accuracy-to-effort ratio. The real accuracy killer isn't algorithm choice - it's data quality and feature engineering.