Sales Prediction Algorithms: Which One Should You Actually Use?
A VP of Sales once asked our team why the Q3 forecast was off by 40%. The model "worked" in a notebook, but the CRM was full of stale records and we were using uncalibrated stage probabilities like they were physics. That combo doesn't just add noise - it bakes fantasy into your training data, and no sales prediction algorithm can fix garbage inputs.
Most forecasting guides list eight "methods" and never name a single algorithm. Here's the fix: pick models based on the shape of your data, not vibes.
Which Algorithm to Pick
Two questions decide this: "Is it basically one time series?" and "Is it zero-heavy?"
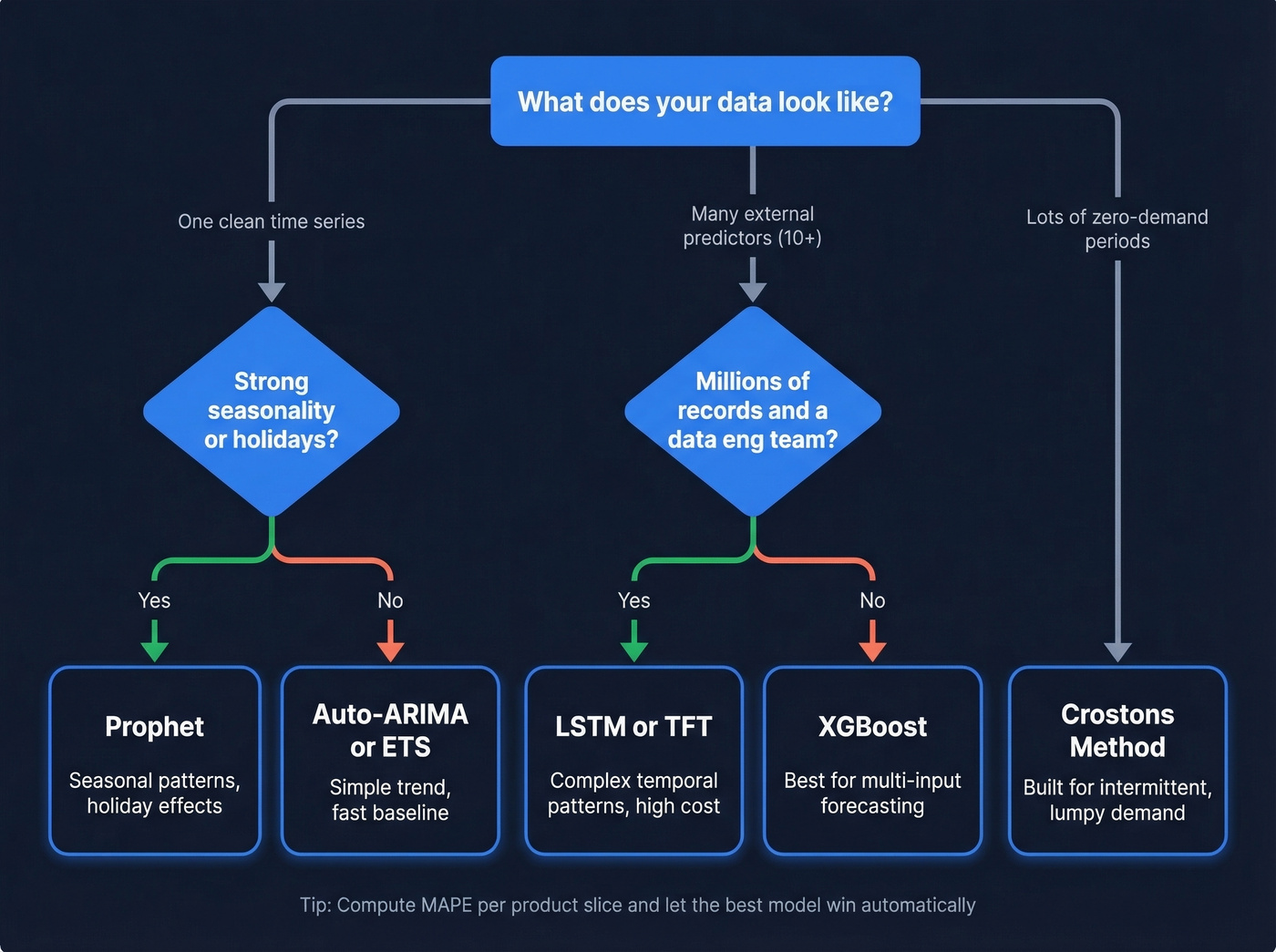
- One clean series (trend, maybe mild seasonality): ETS or Auto-ARIMA
- Lots of predictors (pricing, promos, ad spend, macro): XGBoost
- Intermittent demand (tons of zeros): Croston's method
Skip deep learning unless you've got millions of records and an actual data engineering team to keep it fed.
The 7 Core Forecasting Models
Auto-ARIMA
Auto-ARIMA is the "good enough, fast" baseline when your series is close to stationary without strong seasonality. Enterprise demand planning systems position it exactly this way, and it matches how it behaves in production. It wins when you need something stable with minimal tuning. Read Microsoft's Dynamics 365 algorithm guidance once - you'll see why so many teams start here.

ETS (Exponential Smoothing)
ETS is underrated because it looks "simple." Simple models embarrass fancy ones on small datasets all the time. ETS handles linear or exponential trends and naturally weights recent observations more heavily - exactly what you want when the business changes quarter to quarter. It fails when you need to explain sales with external drivers; it's not built for that.
Prophet
Does your data have clear seasonality and holiday effects? Prophet is built for that kind of real-world patterning and gives you a model your stakeholders can actually reason about.
Where it breaks: sparse B2B pipeline series with long stretches of "nothing happened." Prophet's structure can overfit narratives onto noise. We've seen teams adopt it as a default for lumpy opportunity creation data and get worse results than a naive seasonal average. It's great for seasonal demand, not magic for sparse B2B pipelines.
XGBoost
Here's the thing about XGBoost: the failure mode matters more than the success stories. On sparse, zero-heavy series, naive regression spits out absurdly high forecasts for items that barely sell. One practitioner shared results across thousands of MSKUs with roughly 50% zeros - the predictions were nonsensical.
That's not "XGBoost is bad." It's "you picked the wrong objective and data representation." When used correctly - with engineered lag features, rolling windows, promo flags, pricing, and macro indicators - XGBoost is the workhorse for multi-input forecasting. It learns feature interactions that statistical models can't touch, and in our experience it's the single most forgiving ML model for teams that are still building out their feature pipelines.
Random Forest
Random Forest is the calmer cousin of gradient boosting. In our bake-offs, it sometimes loses a bit of accuracy to XGBoost but wins on "not doing anything insane" when the data's messy. If your feature engineering isn't stable yet, Random Forest is a safer first benchmark. It still struggles with intermittent demand unless you model the zeros explicitly.
LSTM / Deep Learning
A 2026 AIP conference paper used millions of records (2013 through mid-2017 daily sales) to compare deep learning methods, evaluated with MAE and MSE (AIP Conf. Proc., 2026). That scale requirement is the point.
Temporal Fusion Transformers are a popular deep learning option for multi-horizon forecasting with mixed inputs, but they carry the same data-volume and engineering requirements. Among modern AI forecasting techniques, TFTs represent the highest ceiling - and the highest cost to get right. If you've got 24-60 monthly points per product, deep learning is mostly a way to burn time and compute.
Croston's Method
Most forecasting guides skip Croston's entirely. That's a gap if you sell anything with lumpy demand. When many periods are zero, "normal" regression and even many classical models get weird fast because the underlying data generating process is fundamentally different. Enterprise platforms now include Croston's specifically for intermittent demand - a refreshingly honest admission that sparse series need specialized handling.
If your data looks like "zero, zero, zero, 12, zero, zero, 4," start here.
Algorithm Selection Guide
The "ARIMAX vs Prophet vs XGBoost with 50 predictors" question comes up constantly on Reddit (example thread). Once you're truly in dozens of exogenous variables, you're in tabular ML territory, and XGBoost is usually the most forgiving first bet.
The pragmatic approach: compute MAPE per product or dimension slice, then pick the best-fit model automatically from a menu. That "selector" logic is closer to how real forecasting systems should behave than picking one model for everything.
| Data Shape | Best Algorithm | Why |
|---|---|---|
| Simple trend, no seasonality | Auto-ARIMA / ETS | Low complexity, fast |
| Strong seasonality + holidays | Prophet | Seasonality + holiday effects |
| 10+ external features | XGBoost | Learns interactions |
| Many zero-demand periods | Croston's | Built for intermittent demand |
| Millions of records, complex patterns | LSTM / TFT | Learns complex temporal patterns |
| Low data, few features | ETS or Naive | Simple wins small |
Every algorithm in this guide fails the same way: garbage inputs produce garbage forecasts. Stale contacts, bounced emails, and outdated job titles poison your training data before a single model runs. Prospeo's 7-day data refresh cycle and 98% email accuracy mean your CRM reflects reality - not last quarter's org chart.
Fix the data layer and your forecasts fix themselves.
Evaluating Your Forecast Model
MAPE is the most popular metric and also the most misleading one. It's fine when volumes are healthy and non-zero, but it breaks down hard on low-demand items because tiny absolute errors explode into huge percentages (MAPE limitations).
Use a two-layer approach. Pick a primary error metric that matches your output type, then benchmark against a naive baseline and compute Forecast Value Added (FVA). RMSSE is especially useful for comparing across many series - it's the standard from the M5 competition (RMSSE + FVA best practice).
And don't random-split time series. Walk-forward validation only: train on the first chunk, predict the next period, roll forward, repeat (why random splits leak future info).
| Metric | Best For | Watch Out |
|---|---|---|
| MAE | General accuracy | Doesn't punish spikes |
| RMSE | Mean forecasts | Spike-sensitive |
| MAPE | Easy % reading | Breaks on zeros |
| WMAPE | Portfolio accuracy | Favors big items |
| RMSSE | Cross-series compare | Needs naive baseline |
| FVA | Vs baseline impact | Baseline must exist |
Pitfalls That Tank Forecasts
Data leakage from random splits. Time series isn't i.i.d. Random train/test splits leak the future into training and inflate offline accuracy. Walk-forward or sliding windows only.
Sparse demand + wrong model = nonsense. The Reddit MSKU example is painfully common: XGBoost on 36 monthly points with roughly 50% zeros produced "absurdly high" predictions. Switch to Croston's, two-stage models, or zero-inflated framing.
Objective mismatch. You train to match historical sales with MSE/MAE, but the business goal is profit, waste reduction, or service level. If your labels are biased by past constraints, your "accurate" model can be strategically wrong (discussion).
Static stage probabilities. Treating every deal at "Proposal" as 45% hides risk concentration. Refresh probabilities quarterly by deal size and segment - or your model inherits the same fantasy. If you're still relying on a weighted pipeline, this is the first place to tighten the math.
CRM data quality creates phantom pipeline. Your forecast trains on pipeline data. If 20% of contacts have bounced emails or changed jobs, you're modeling deals that aren't real. Tools like Prospeo that refresh contact data on a 7-day cycle with 98% email accuracy handle exactly this kind of upstream hygiene - the kind that decides whether your model learns reality or hallucinates. This is the core of CRM hygiene and it’s usually the highest-leverage fix.
Let's be honest: every vendor claims "AI improves accuracy by 30%" without defining accuracy or showing the baseline. That's not forecasting. That's marketing.
Hot take: If your deal sizes are under $10k and your sales cycle wraps up in a month, you probably don't need a sophisticated prediction model at all. You need a clean pipeline and a spreadsheet. The algorithm obsession is a distraction from the data quality problem sitting right underneath it.
Forecasting Tools and Pricing
Approximate ranges as of early 2026. Enterprise contracts vary - the biggest swing factor is seat count plus add-on modules.
| Tool | Category | Approx. Price |
|---|---|---|
| Prospeo | Data quality layer | Free tier; ~$0.01/email |
| Zoho CRM (Zia) | CRM + AI forecasting | $14-40/user/mo |
| HubSpot Sales Hub | CRM + forecasting | $45-150/user/mo |
| Salesforce Einstein | AI modules | $50-220/user/mo |
| Clari | Revenue intelligence | $100-120/user/mo |
| Gong Forecast | Revenue intelligence + forecasting | ~$250/user/mo |
Notice the mismatch: forecasting tools are priced per user, while data hygiene is priced per record. Paying about $0.01/email to keep contacts verified is often a cheaper accuracy win than buying another forecasting seat license - especially if you’re evaluating predictive sales software or broader AI forecasting software.
XGBoost and Prophet can model feature interactions all day, but they can't compensate for a pipeline built on unverified contacts. Prospeo enriches your CRM with 50+ data points per contact at a 92% match rate - giving your prediction models the signal density they actually need to perform.
Feed your forecasting models verified data starting at $0.01 per email.
FAQ
What's the best sales prediction algorithm for small datasets?
ETS or Auto-ARIMA. Statistical models generalize better with limited history - fewer than roughly 50 data points and complex ML models tend to overfit, while ETS and ARIMA give stable baselines you can beat later as data accumulates.
Can I use XGBoost for time series sales forecasting?
Yes, but only with proper feature engineering: lag features, rolling averages, and calendar signals validated via walk-forward splits. Random train/test splits on time series leak future information and inflate accuracy metrics by 15-30% versus real-world performance.
How does CRM data quality affect forecast accuracy?
Stale contacts and bounced emails create phantom pipeline that inflates predictions and misleads training data. Teams running a 7-day data refresh cycle see cleaner labels and more reliable model outputs than teams refreshing quarterly - it's one of the simplest accuracy wins available before you touch a single hyperparameter.
Do AI forecasting techniques outperform traditional statistical models?
For most sales teams with under 100k records, traditional models like ARIMA and ETS match or beat deep learning approaches. ML and neural networks shine above roughly 500k rows with 10+ external features, but they require significantly more engineering effort to deploy and maintain reliably.