What Is Data Matching? A Practitioner's Guide (2026)
A data engineer posted on r/dataengineering about matching PII student files. They normalized the names, trimmed the whitespace, ran a SQL JOIN on last name plus date of birth - and the output was a mess. Duplicates everywhere. The join didn't match records; it multiplied them. This is exactly what data matching solves, and it's the reason a simple WHERE a.name = b.name will never be enough for real-world data.
Quick Summary
Data matching finds records that refer to the same real-world entity across messy, fragmented datasets. It answers one question: "Are these two rows the same person, company, or address?"
Three methods dominate. Deterministic matching requires exact field equality - fast but brittle. Fuzzy matching scores similarity between strings - better, but relies on arbitrary weights. Probabilistic matching, specifically the Fellegi-Sunter model, learns from your data's actual error rates and value frequencies. It typically wins on messy data.
SQL JOINs aren't entity resolution. They're deterministic lookups that explode into duplicates the moment your data has inconsistencies. You need dedicated tools. The good news: you don't need enterprise software to start. Splink is free, open-source, and handles probabilistic matching at scale.
What Is Data Matching?
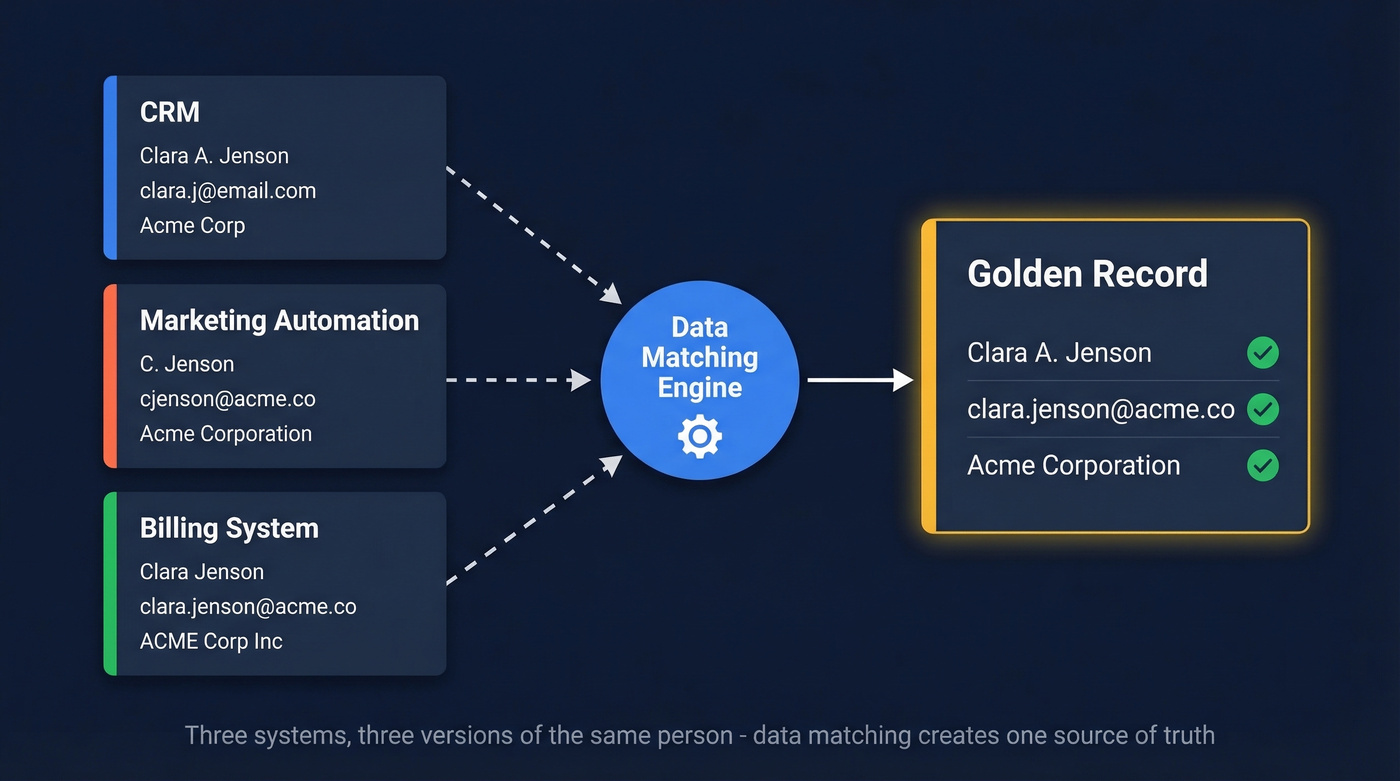
Data matching - also called entity resolution, record linkage, or deduplication - is the discipline of identifying records across one or more datasets that refer to the same real-world entity. The output is typically a "golden record)": a single, consolidated view of each entity built from the best available data across sources.
Why is this so hard? Because data is fragmented by design. Organizations run an average of 991 applications, and 79% of employees work in siloed systems. Your marketing automation platform has one version of a contact. Your CRM has another. Your billing system has a third. None of them agree on the spelling of the company name, and two of them have the wrong email address. Without matching, you don't have a customer database - you have a collection of contradictory fragments.
Why It Matters
The average CRM carries a 10-30% duplicate rate, depending on how many sources feed into it and how much governance exists. That's not a minor hygiene issue. It's a structural problem that compounds across every downstream process, from outbound sequences to revenue reporting.
The compliance stakes are even sharper. GDPR and CCPA grant individuals the right to access, correct, and delete their data. If your records for a single person are scattered across five systems under three name variations, fulfilling a Data Subject Access Request becomes a record linkage problem. Fail at it, and you're exposed. Meta Ireland was fined €1.2B under GDPR. Oracle settled for $115M. National Public Data suffered a breach exposing nearly 3 million records and filed for bankruptcy.
For outbound teams, bad data has a more immediate cost. Sending sequences to unverified, duplicated contacts tanks your bounce rate, damages domain reputation, and burns through your sequencing budget. Every duplicate is a wasted touch.
Use Cases by Method
Deterministic Matching
Use this if your data has a reliable unique identifier - a Social Security number, a tax ID, a consistent email address across systems. Deterministic matching requires exact field equality.
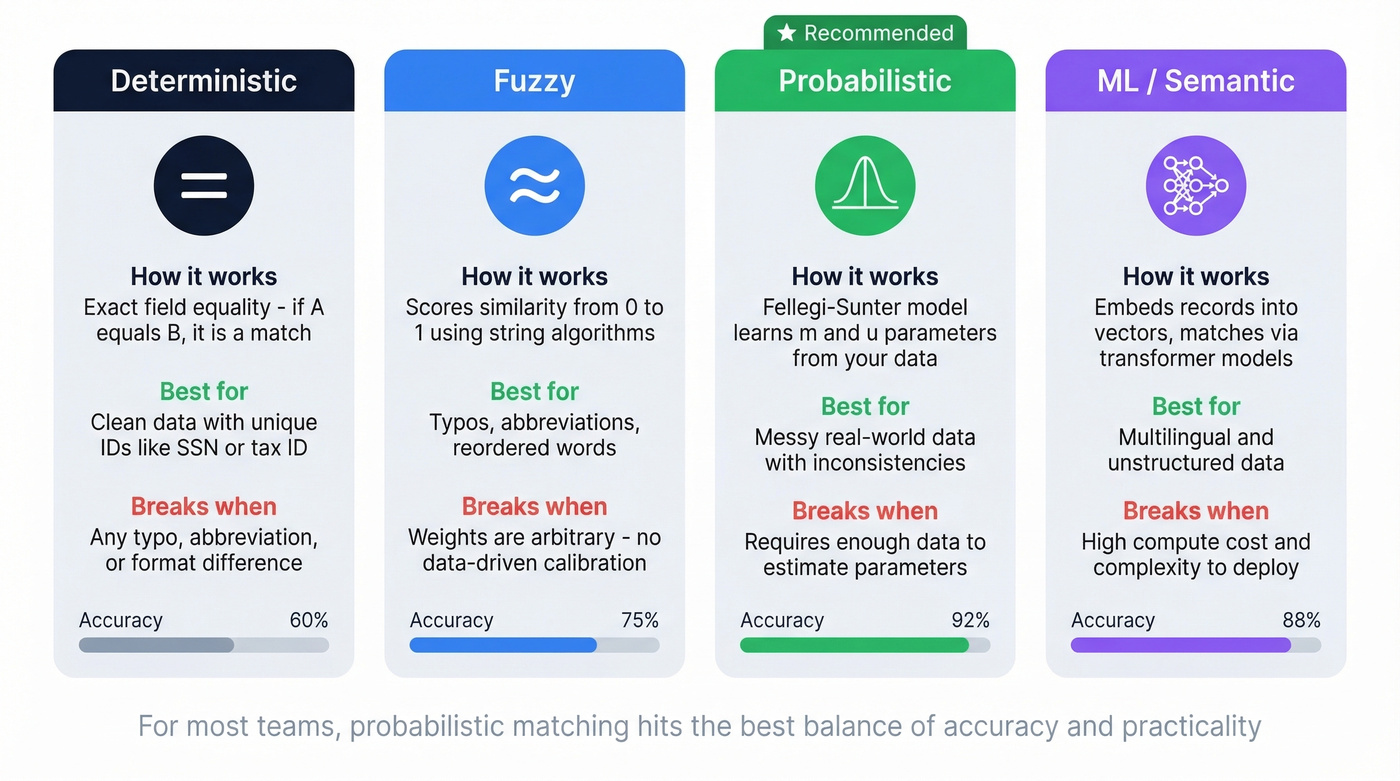
Skip this if your data has any inconsistency in the fields you're joining on. One typo, one missing middle initial, one "St." vs "Street" - and the match fails silently or creates duplicates.
Fuzzy Matching
Fuzzy matching scores the similarity between two values on a scale of 0 to 1 rather than demanding exact equality. "Clara A. Jenson" compared to "Clara Jenson" might score 0.92 - close enough to flag as a likely match, different enough to catch.
| Category | Examples | Best For |
|---|---|---|
| Character-based | Levenshtein, Jaro-Winkler | Typos, abbreviations |
| Token-based | Jaccard, cosine similarity | Reordered words |
| Phonetic | Soundex, Metaphone | Names that sound alike |
| Semantic | TF-IDF, embeddings | Meaning-level similarity |
The limitation: fuzzy matching alone relies on arbitrary, user-chosen weights. How important is a name match vs. a date-of-birth match? Those decisions are judgment calls, and they leave accuracy on the table.
Probabilistic Matching (Fellegi-Sunter)
This is where matching gets principled. The Fellegi-Sunter model uses three parameters to compute match probability: lambda (prior probability that any two records match), m (probability of observing a given similarity if the records truly match), and u (probability of observing that similarity by coincidence).
Here's the intuition that makes this powerful. An exact match on the surname "Joss" is much stronger evidence than an exact match on "John" - because the collision probability for a rare name is far lower. Fuzzy-only approaches treat both matches the same. Fellegi-Sunter doesn't.
Consider "hammond" vs. "hamond" - a Jaro-Winkler similarity of 0.97. A fuzzy matcher sees a near-match. A probabilistic model also factors in how common "hammond" is in the dataset and the baseline collision rate. The result is a calibrated probability, not an arbitrary score.
If you're doing anything beyond trivial deduplication, probabilistic matching is the method to learn.
ML and Semantic Matching
The frontier is embedding-based entity resolution. Ditto (Li et al., 2020) used BERT embeddings for blocking and matching, beating previous benchmarks by as much as 29%. The pipeline embeds records into vector space, clusters via cosine similarity for blocking, matches with a transformer model, then merges. We haven't battle-tested these approaches enough in production to recommend them over Fellegi-Sunter for most teams, but they're clearly where the field is heading.
| Approach | How It Works | Best For | Limitation |
|---|---|---|---|
| Deterministic | Exact field equality | Clean data, unique IDs | Fails on any inconsistency |
| Fuzzy | Similarity scoring (0-1) | Typos, abbreviations | Arbitrary weights |
| Probabilistic | Bayesian m/u parameters | Messy, real-world data | Requires parameter estimation |
| ML/Semantic | Embedding + transformer | Multilingual, unstructured | Compute cost, complexity |
The Matching Process Step by Step
Regardless of which algorithm you choose, the workflow follows seven steps.
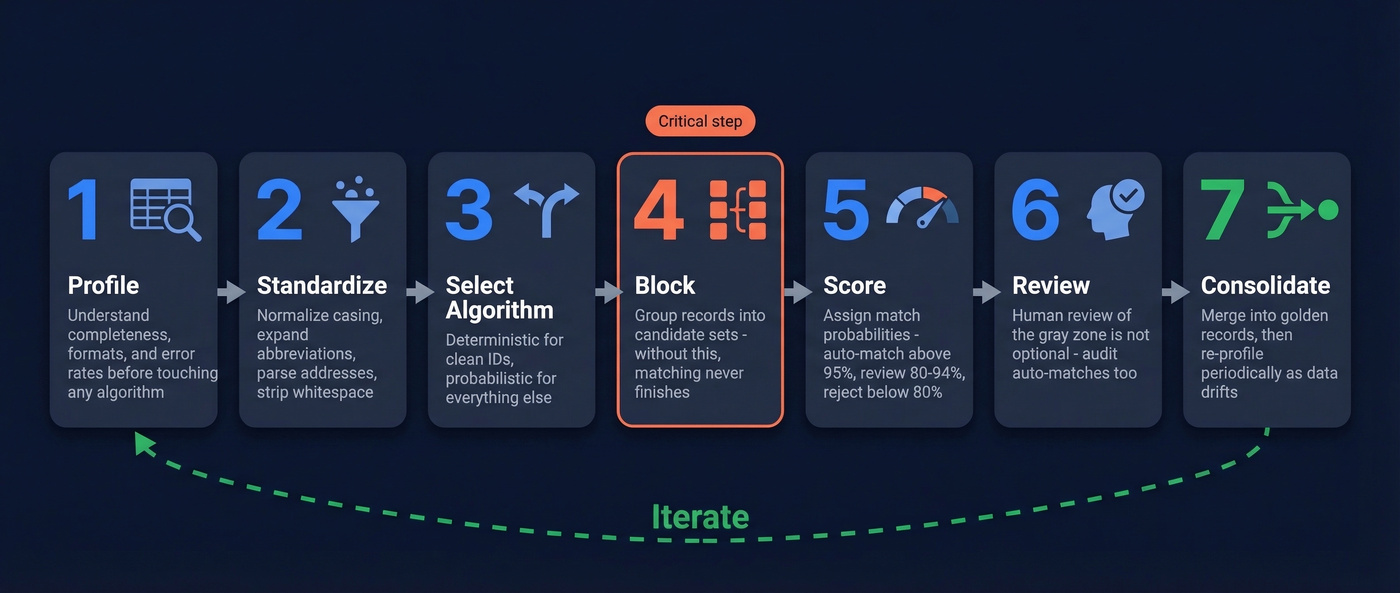
1. Profile. Understand completeness, format variation, and error rates before you touch an algorithm. What percentage of records have a date of birth? How many name formats exist? In our experience, teams that skip profiling spend twice as long debugging their match results.
2. Standardize. Normalize casing, expand abbreviations like "St." to "Street," parse addresses into components, strip whitespace. You're reducing surface-level variation so the algorithm can focus on real ambiguity.
3. Select your algorithm. Deterministic for clean identifiers, probabilistic for everything else.
4. Block. This is the step most people skip - and it determines whether your matching job finishes in minutes or never finishes at all. Pairwise comparison scales at O(n^2). A dataset of 400 million rows means 80 quadrillion comparisons without blocking. Blocking groups records into candidate sets - same first two letters of surname, same zip code - so you only compare plausible pairs. One r/dataengineering practitioner described trying to match roughly 400 million address records and needing candidate retrieval plus a 0-1 score for the top matches. Without blocking, that job simply doesn't complete.
5. Score. Run your algorithm and assign match probabilities. Set threshold bands: 95%+ for auto-match, 80-94% for human review, below 80% for non-match.
6. Review. Human review of the gray zone isn't optional. Audit a sample of auto-matches too - false positives are expensive.
7. Consolidate and iterate. Merge matched records into golden records. Then re-profile periodically. Data drifts. New sources get added. Matching isn't a one-time project.
Your CRM's 10-30% duplicate rate isn't just a hygiene issue - it's wrecking your outbound. Prospeo's 300M+ profiles are deduplicated, verified through a 5-step process, and refreshed every 7 days. 98% email accuracy. No duplicates. No guesswork.
Skip the matching headache - start with data that's already clean.
Measuring Match Quality
Precision measures how many of your model's predicted matches are actually correct. High precision means few false positives - you aren't merging records that shouldn't be merged. Recall measures how many true matches your model found out of all that exist. High recall means few missed duplicates. F1 score is the harmonic mean of both.

Typical results for a well-tuned probabilistic workflow: precision around 0.96, recall around 0.89. Strong, but notice that recall is usually the harder number to push up.
Beyond these, track operational KPIs: duplicate rate over time, manual review volume (is it shrinking?), and time-to-golden-record. Maintain audit trails for every merge decision, and re-profile your data periodically to catch drift before it degrades quality.
Common Mistakes
Believing perfect matching exists. "St. Mary's Hospital" could refer to institutions in dozens of cities across multiple countries, with abbreviations like Saint/St./St and non-Latin scripts like "聖マリア病院." If someone promises 100% match accuracy, they're either working with trivial data or lying.

Using arbitrary weights when data-driven parameters are available. Manually deciding that "name is worth 40% and DOB is worth 30%" feels intuitive but leaves accuracy on the table. Fellegi-Sunter estimates these weights from your actual data. Let it.
Skipping data preparation. Here's the thing - the biggest problem isn't your algorithm. It's your data. Teams jump straight to algorithm selection and wonder why results are poor. Profile first. Standardize second. Match third.
Treating SQL JOINs as a matching strategy. We've seen this pattern repeatedly: a data engineer writes a multi-condition JOIN, gets a result set full of duplicates, and spends weeks writing exception logic. Use a dedicated matching tool. That's what they're for.
Tools Worth Knowing
Splink
You don't need enterprise software to start. Splink is open-source, implements Fellegi-Sunter natively, and runs on Spark or DuckDB. It was built by the UK Ministry of Justice for large-scale probabilistic deduplication. The documentation is excellent, the community is active, and the price is right - free. If you're doing serious record linkage, start here before signing a six-figure contract.
Let's be honest: for most teams under 50 million records, Splink paired with DuckDB handles everything you need. We've recommended it to multiple teams who were evaluating enterprise tools and found it covered 90% of their requirements.
Zingg
Zingg takes a different approach: active learning. You label a sample of record pairs as match/no-match, and the model learns your matching patterns. It's ideal for teams that want a custom matching model without writing rules from scratch. Open-source and free.
OpenRefine
OpenRefine is the Swiss Army knife for exploratory data cleaning. Its clustering features use fingerprinting and n-gram approaches to group similar strings interactively. Best for small-to-mid-scale matching where you want to see and approve clusters manually. Free.
Enterprise Options
Data Ladder ($10K-50K+/yr) and Informatica ($50K-500K+/yr) serve the enterprise MDM market - full-featured platforms for organizations with dedicated data governance teams and budgets to match. For teams without that budget, skip these.
Keeping Clean Data After Matching
After matching identifies your duplicates and builds golden records, the next challenge is keeping those records accurate. Stale emails, outdated job titles, and missing phone numbers creep back in fast. Tools like Prospeo help here - with a 7-day data refresh cycle and automatic duplicate removal across searches, it prevents the re-accumulation of the exact problems you just solved. The 92% API match rate means enrichment workflows actually return usable data, not empty fields.
Every duplicate in your CRM is a wasted sequence, a bounced email, and domain reputation damage. Prospeo's enrichment API returns 50+ verified data points per contact at a 92% match rate - so you're building golden records, not fragmenting them further.
Enrich your CRM with verified contacts at $0.01 per email.
Compliance Implications
GDPR's Right to Access, Right to Rectification, and Right to be Forgotten all require the same underlying capability: finding every record associated with a given person across every system. That's an entity resolution problem.
Without reliable matching across your data estate, you can't confidently respond to Data Subject Access Requests. Meta's €1.2B fine, Oracle's $115M settlement, and National Public Data's bankruptcy demonstrate that regulators aren't treating this as theoretical. If your compliance team can't find all records for a given individual, you have a matching problem masquerading as a legal risk.
Impact on Business Intelligence
Clean, deduplicated records aren't just an ops win - they're the foundation of trustworthy analytics. When duplicate contacts inflate your pipeline counts or skew conversion rates, every dashboard built on that data tells a misleading story.
Resolving entities before building BI layers means your reporting reflects actual customers, not fragmented echoes of the same person across systems. Teams that invest in matching before building dashboards avoid the painful cycle of "the numbers don't add up" that derails quarterly reviews. I've watched a VP of Sales lose 20 minutes of a board meeting explaining why pipeline numbers didn't reconcile - and the root cause was 14,000 duplicate contacts nobody had cleaned up.
FAQ
What's the difference between data matching and deduplication?
Data matching identifies records referring to the same entity across one or more datasets, including cross-system linkage and entity resolution. Deduplication removes duplicates within a single dataset. Deduplication is one specific application of the broader matching discipline.
Deterministic vs. probabilistic - which should I use?
Use deterministic matching when your data has reliable unique identifiers like tax IDs or consistent email addresses. For messy names, inconsistent formatting, or missing fields, probabilistic matching wins. Most real-world datasets fall into the second category.
Can I do data matching in SQL?
Basic deterministic lookups, yes. But SQL JOINs on inconsistent data create duplicate explosions rather than clean matches. For fuzzy or probabilistic record linkage, use Splink or Zingg - SQL is a query language, not a matching engine.
How accurate is data matching?
Typical fuzzy/probabilistic workflows achieve precision of 0.96+ and recall of 0.89+. Perfect accuracy isn't possible with real-world data - ambiguity, missing fields, and non-Latin scripts guarantee some irreducible error rate. Aim for F1 above 0.90.
What tools clean B2B contact data after matching?
Prospeo enriches and verifies contact records with 98% email accuracy and 125M+ verified mobile numbers on a 7-day refresh cycle. After deduplication, it fills data gaps and prevents stale records from piling back up. Free-tier options like OpenRefine handle the matching step itself.