Best Data Cleaning Tools in 2026: Picks by Use Case
Poor data quality costs organizations $12.9M per year on average. That's not a typo. Meanwhile, 95% of enterprise data leaders report quality issues that directly hurt business outcomes - yet 76% of data professionals still rely on spreadsheets as their primary cleaning tool. The gap between the cost of bad data and the sophistication of most teams' actual workflows is why picking the right data cleaning tool has gone from a nice-to-have to a budget line item.
We've tested and compared tools across every category - free open-source utilities, enterprise governance platforms, code-first frameworks, and B2B contact verification systems. Here's where each one actually makes sense.
Our Picks by Use Case
| Use Case | Pick | Starting Price | Best For |
|---|---|---|---|
| Free / one-off datasets | OpenRefine | Free | Messy CSVs, one-time projects |
| Self-serve analytics prep | Alteryx Designer Cloud | $250/user/mo | Cloud analytics workflows |
| B2B contact data cleaning | Prospeo | Free tier; ~$0.01/email | Contact verification + enrichment |
| Enterprise governance | Informatica | ~$2,000/mo | Regulated industries, lineage |
| Budget-friendly self-serve | Mammoth Analytics | $99/mo | Small teams, simple transforms |

Top Data Cleaning Tools Reviewed
OpenRefine
OpenRefine is one of the most popular free tools for hands-on data cleaning. It's open-source, genuinely powerful, and the clustering and faceting features handle inconsistent text data ("New York" vs "new york" vs "NY") better than most paid tools. It carries a 4.6/5 on G2 and 4/5 on Capterra, which is impressive for software that costs nothing.
Here's the thing: OpenRefine is desktop-only. No cloud version, no native pipeline integrations, no way to schedule recurring jobs. Clustering often catches inconsistencies that regex-based scripts miss, but the moment you need continuous data quality monitoring across a warehouse, you'll outgrow it fast. It's a workbench, not a production system.
Use this if you're an analyst cleaning one-off CSVs or JSON files and don't need automation.
Skip this if you need scheduled, pipeline-integrated cleaning at any real scale.
Alteryx Designer Cloud
Alteryx Designer Cloud (formerly Trifacta) is the self-serve analytics prep tool that data teams actually enjoy using. The visual interface lets analysts build cleaning workflows with drag-and-drop transformations, and the predictive suggestions are a real differentiator - it spots patterns in your data and recommends standardization steps before you even think to look for them.
Pricing: Starter edition runs $250/user/month. Legacy Trifacta licensing is commonly quoted at $4,950/user/year with a 3-user minimum. Professional and Enterprise tiers are custom-priced.
| Pros | Cons |
|---|---|
| Best-in-class visual profiling | Per-seat cost punishes small teams |
| AI-powered transformation suggestions | Enterprise tiers require sales calls |
| Cloud-native, no infrastructure to manage | Overkill for simple CSV cleanup |
The per-seat model makes the most sense at 3+ users. Solo analysts should look elsewhere.
Prospeo
Most data cleaning articles focus on formatting and deduplication. For B2B sales and marketing teams, the real data quality problem is freshness. Stale emails bounce, stale phone numbers waste rep time, and both destroy your domain reputation.
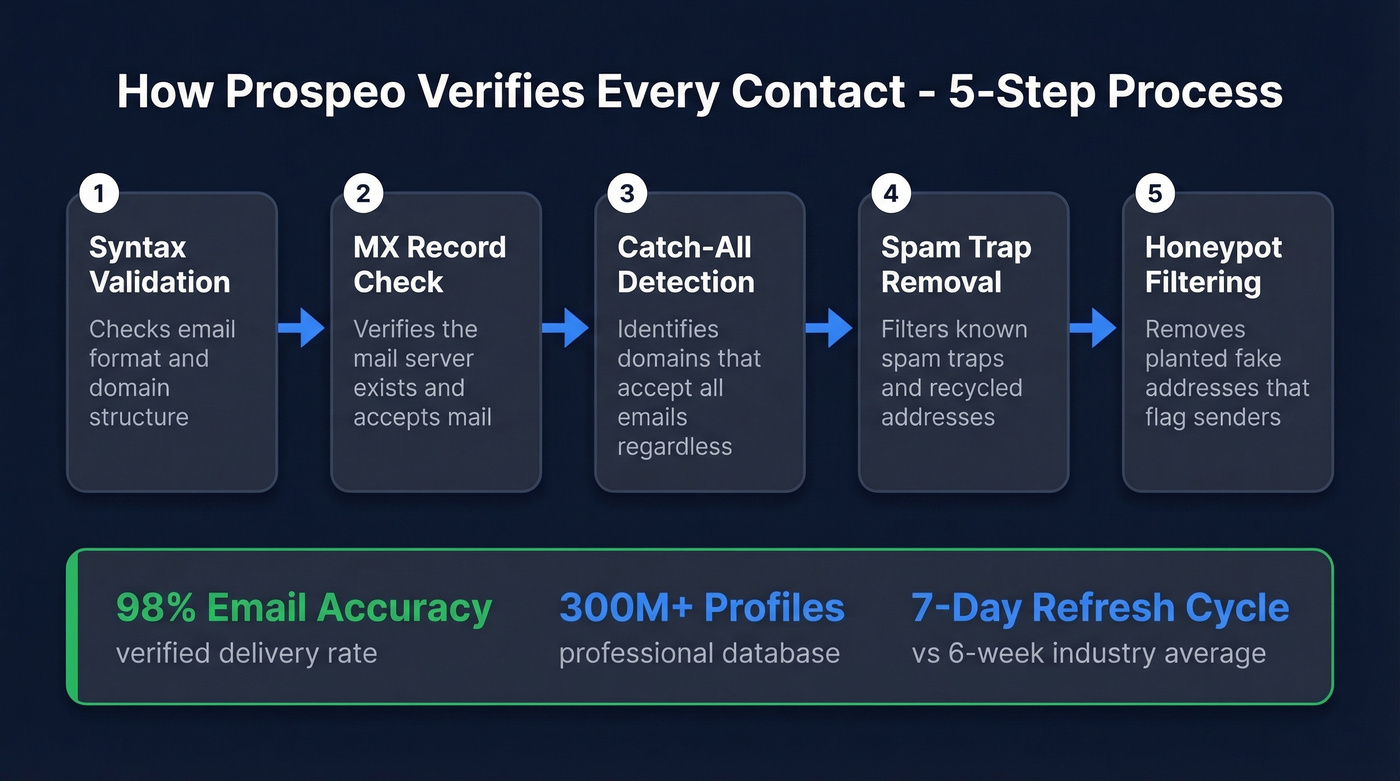
Every record runs through a 5-step verification process with catch-all handling, spam-trap removal, and honeypot filtering - delivering 98% email accuracy across 300M+ professional profiles. The 7-day data refresh cycle is the key differentiator; the industry average is six weeks, which means most "verified" databases are already decaying by the time you export a list. CRM enrichment returns 50+ data points per contact at a 92% match rate, and you can upload a CSV, push contacts through the API, or enrich directly inside HubSpot or Salesforce. Pricing is credit-based and transparent: the free tier gives you 75 emails per month, and at scale you're paying roughly $0.01 per email. No contracts, no sales calls required.
Use this if your data quality problem is bounced emails, disconnected phones, or stale CRM records.
Skip this if you're cleaning analytics datasets or warehouse tables - this is purpose-built for B2B contact data.
Informatica Cloud Data Quality
Informatica is the enterprise standard, and for regulated industries, it's the right call. It covers data profiling, standardization, matching, deduplication, and lineage tracking in a single governed platform, handling rule-based transformations at scale while maintaining full audit trails. If you need ISO 8000 compliance or audit trails for every transformation, this is where serious teams land.
Gartner Peer Insights gives it a 4.3/5 across 184 ratings. Pricing starts around $2,000/month, and enterprise deployments climb quickly. The tradeoff is implementation time - expect months, not days.
Talend (Qlik Talend Cloud)
Talend's open-source heritage makes it a familiar choice for data engineering teams building governed ETL pipelines. Now part of Qlik, Talend Cloud handles data quality rules, profiling, and cleansing within broader integration workflows. It scores a 4.4/5 on Gartner Peer Insights with 108 ratings, and pricing starts at $1,170/user/year - often more accessible than Informatica for mid-market teams that need governance without the enterprise-grade invoice.
Mammoth, Insycle, and Code-Based Options
Mammoth Analytics starts at $99/month and targets small teams that need simple, visual data cleaning without the complexity of Alteryx. Solid for budget-conscious teams doing basic transforms.
Insycle earns a 4.7/5 on G2 across 192 reviews, largely because it's deeply integrated with HubSpot. If your CRM is HubSpot and your main problem is duplicates and formatting inconsistencies, Insycle is purpose-built for that workflow. Pricing runs around $200-$600/month depending on contact volume and feature tier.
dbt Cloud + Great Expectations is the code-first path. dbt Cloud starts at $100/developer/month for transformation logic; Great Expectations starts at $499/month for data validation and testing. Together, they're powerful for engineering teams that want cleaning rules defined as code. Not for non-technical users.
Other tools you'll see in this category include Melissa, WinPure, Data Ladder, and Domo - but many teams skip them in early-stage buying because pricing is harder to pin down quickly.
Let's be honest: if your deal sizes are modest and you're not in a regulated industry, you don't need Informatica-level tooling. A combination of OpenRefine for analytics cleanup and a purpose-built verification tool for contact data will get you 90% of the way there at 10% of the cost. We've seen this play out with dozens of teams who started with enterprise evaluations and ended up with something far simpler.
Most data cleaning tools fix formatting. Prospeo fixes the problem that actually kills revenue: stale contact data. Every record is verified through a 5-step process and refreshed every 7 days - not the 6-week industry average.
Stop cleaning data that's already decayed. Start with records that are accurate today.
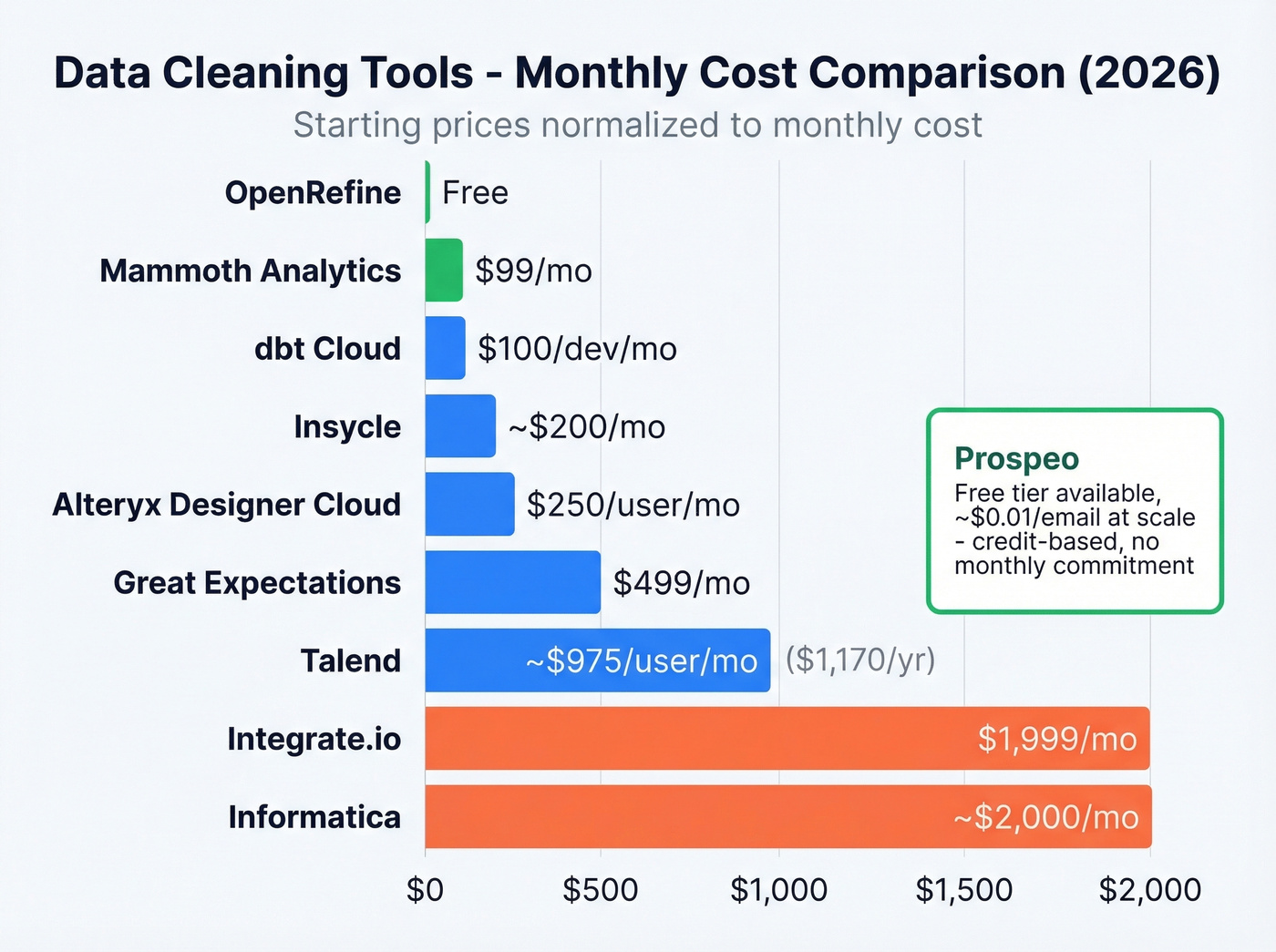
Pricing Comparison
| Tool | Starting Price | Type |
|---|---|---|
| OpenRefine | Free | Desktop, open-source |
| Mammoth Analytics | $99/mo | Self-serve, visual |
| dbt Cloud | $100/dev/mo | Code-based transforms |
| Insycle | ~$200/mo | CRM-native (HubSpot) |
| Alteryx Designer Cloud | $250/user/mo | Self-serve analytics prep |
| Great Expectations | $499/mo | Data validation/testing |
| Talend | $1,170/user/yr | Enterprise ETL + quality |
| Integrate.io | $1,999/mo | Integration + cleansing |
| Informatica | ~$2,000/mo | Enterprise governance |
Data Cleaning Mistakes to Avoid
These five mistakes break more analyses than bad tooling:

Removing outliers blindly. That "anomalous" data point might be your most important observation. We've seen teams throw out legitimate signals because a value looked weird in a histogram - only to realize months later it was a real pattern.
Dropping all missing values. Non-random missingness introduces bias you won't catch later. If 40% of your "company size" field is blank and those blanks skew toward startups, your entire analysis tilts toward enterprise without you noticing.
Mixing formats and units. Revenue in dollars and euros in the same column produces silently wrong calculations. This one's embarrassingly common.
Wrong categorical encoding. Assigning numbers to categories implies ordering that doesn't exist. "Small = 1, Medium = 2, Large = 3" tells your model that Large is three times Small, which is nonsense.
Cleaning without documenting steps. If you can't reproduce it, nobody can trust it. The consensus on r/dataengineering is that undocumented cleaning is worse than no cleaning at all, because at least raw data is honest about its messiness.
You don't need a $2,000/month platform to solve a bounced-email problem. Prospeo delivers 98% email accuracy across 300M+ profiles at ~$0.01/email - with CRM enrichment returning 50+ data points at a 92% match rate.
Get 90% of the data quality at 10% of the enterprise price tag.
FAQ
What's the difference between data cleaning and data preparation?
Data cleaning corrects errors, removes duplicates, and enforces standards for long-term reliability. Data preparation shapes clean data for a specific analysis - filtering, joining, aggregating. Conflating them leads to persistent quality issues that compound downstream.
Can AI fully automate data cleaning?
AI handles pattern detection and anomaly flagging far better than manual rules, and 61% of organizations saw measurable quality improvements after adding intelligent automation. But edge cases - ambiguous duplicates, domain-specific formatting - still need human review to avoid silent errors.
How do I choose the right tool?
Start with the problem you're solving. For one-off analytics projects, OpenRefine handles it for free. When the issue is stale B2B contacts bouncing your outbound campaigns, a verification-first tool like Prospeo is the better fit at ~$0.01/email. Enterprise teams with compliance requirements should evaluate Informatica or Talend for governed, end-to-end pipelines.
What's the best free data cleaning tool?
For analytics datasets, OpenRefine offers powerful clustering and transformation at zero cost. For B2B contact data, Prospeo's free tier verifies 75 emails per month at 98% accuracy - enough to test deliverability improvements before committing budget.