Data Orchestration vs Data Integration: What's Actually Different?
The data integration market hit $15.24B in 2026 - yet only 28% of enterprise applications are actually connected. Meanwhile, 95% of IT leaders cite integration challenges as the primary barrier to AI adoption. That gap between spending and results is exactly why the data orchestration vs data integration distinction matters so much: teams have pipelines running but zero visibility into what's broken, what's stale, and what's silently failing.
The two terms get used interchangeably. They shouldn't.
The Short Version
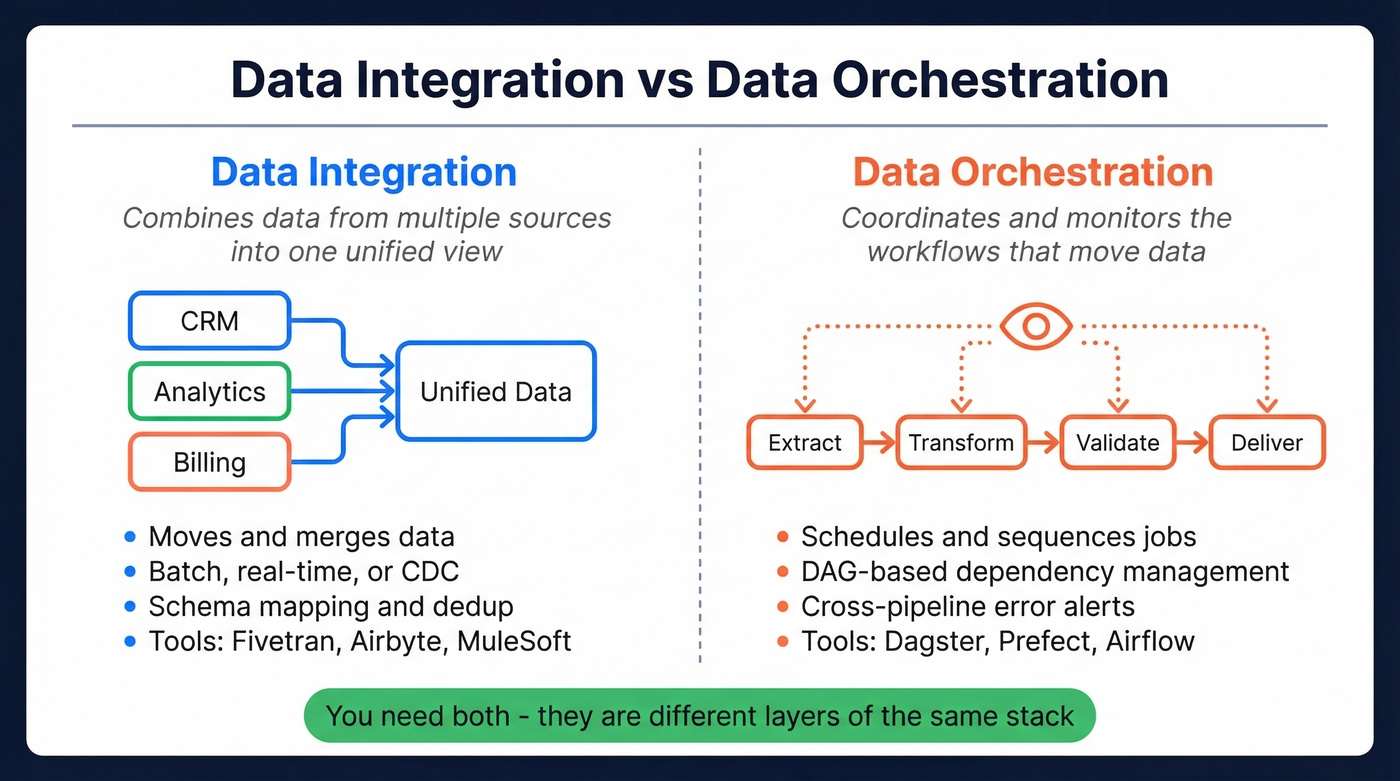
- Integration = combining data from multiple sources into one unified view. Think Fivetran, Airbyte, MuleSoft.
- Orchestration = coordinating and monitoring the workflows that move that data - scheduling, dependencies, error handling. Think Dagster, Prefect, Airflow.
- You almost certainly need both. They're different layers of the same stack, not competing approaches.
What Is Data Integration?
Data integration combines data from multiple sources into a unified, consistent view. The goal: get your CRM data, product analytics, billing system, and marketing platform talking to each other in one place. A healthcare company merging EHR records with claims data for a unified patient view is doing integration. So is a retailer consolidating POS, e-commerce, and inventory feeds into a single warehouse.
The scope goes well beyond ETL/ELT. Integration includes synchronization, replication, virtualization, and change data capture. Flows can run bidirectionally - not just a one-way dump into a warehouse. There's also an important fork worth understanding: connecting operational systems like syncing Salesforce to billing often puts you in iPaaS territory with tools like MuleSoft or Workato, while loading data into a warehouse for analytics typically means ELT-style ingestion tools like Fivetran or Airbyte. Same umbrella, different problems. Regardless of which path you take, accuracy depends on schema mapping, deduplication logic, and how well your connectors handle edge cases at the source level.
What Is Data Orchestration?
Orchestration is the coordination layer. It automates and manages the workflows that move data through your stack - handling scheduling, dependency management, monitoring, and error recovery. If integration is about what data goes where, orchestration is about when, in what order, and what happens when something breaks.
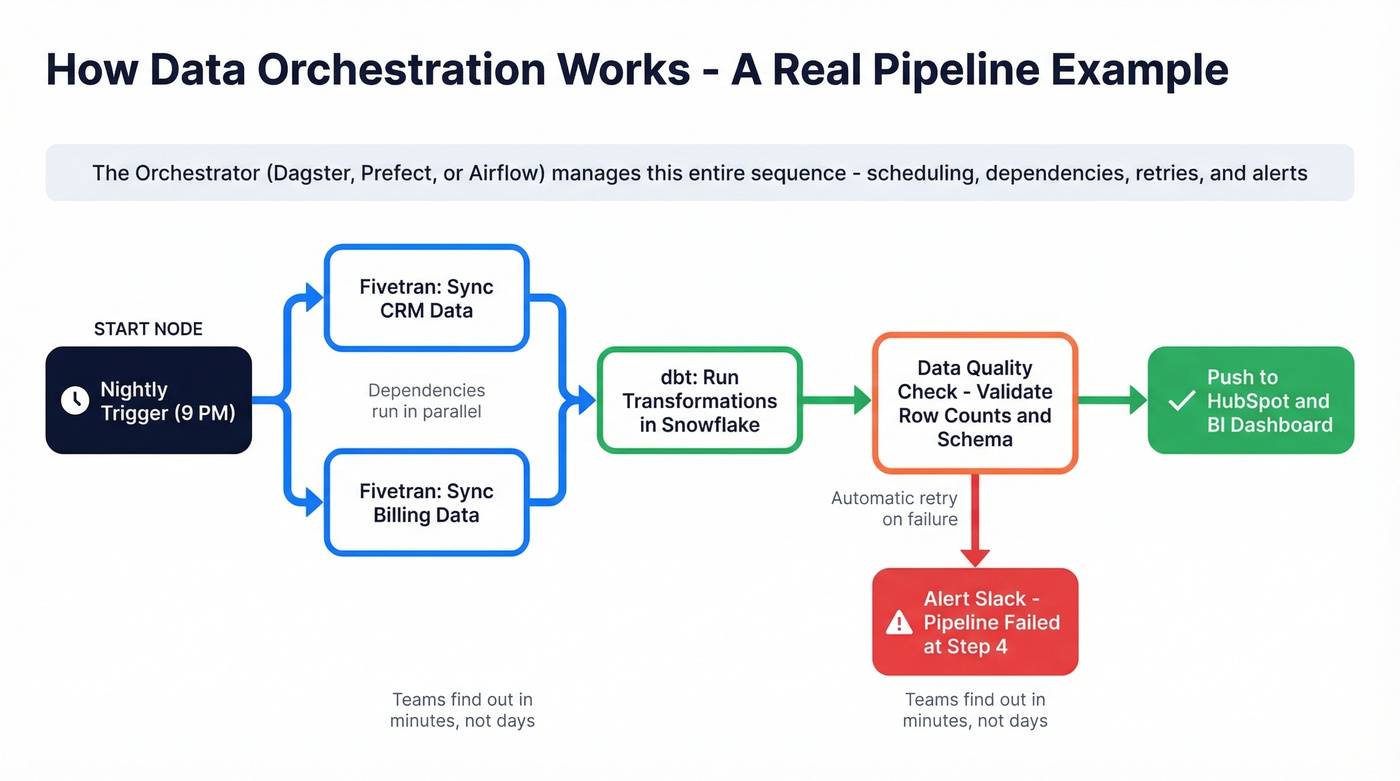
dbt Labs frames it as three phases: Organization (collect data into your warehouse), Transformation (cleanse, unify, run quality checks), and Activation (deliver to BI tools and downstream apps). Most orchestrators use DAG-based workflow management - directed acyclic graphs that map every dependency so you can see exactly what feeds what.
Here's the thing: the real driver behind orchestration adoption isn't scheduling. It's visibility. A recurring theme on Reddit's r/dataengineering is teams running dozens of pipelines as ad-hoc scripts with no central view of what's running or what failed. They only discover something broke when an end user complains about a dashboard three days later. That's the gap orchestration fills.
You can orchestrate flawless pipelines and integrate every source - but if the contact data flowing through them is stale, your outbound still fails. Prospeo refreshes 300M+ profiles every 7 days (not the 6-week industry average) with 98% email accuracy and 5-step verification. That's the data quality layer most stacks are missing.
Stop orchestrating bad data. Start with contacts you can trust.
Key Differences at a Glance
| Dimension | Integration | Orchestration |
|---|---|---|
| Purpose | Unify data sources | Coordinate workflows |
| Scope | Data movement and merging | Pipeline management |
| Processing | Batch, real-time, CDC | DAG-based scheduling |
| Error handling | Retry/log at source | Cross-pipeline alerts |
| Example tools | Fivetran, Airbyte, Informatica | Airflow, Dagster, Prefect |
| Use when | Sources are disconnected | Pipelines lack visibility |
The distinction is architectural. Integration tools get data from point A to point B in the right format. Orchestration tools make sure the entire chain - extraction, transformation, loading, validation, delivery - runs reliably and observably.
The Biggest Mistake Teams Make
Teams overextend their integration tool as an orchestration plane. Azure Data Factory is the classic example - excellent at moving data between Azure services, often maddening as a general-purpose orchestrator at scale.
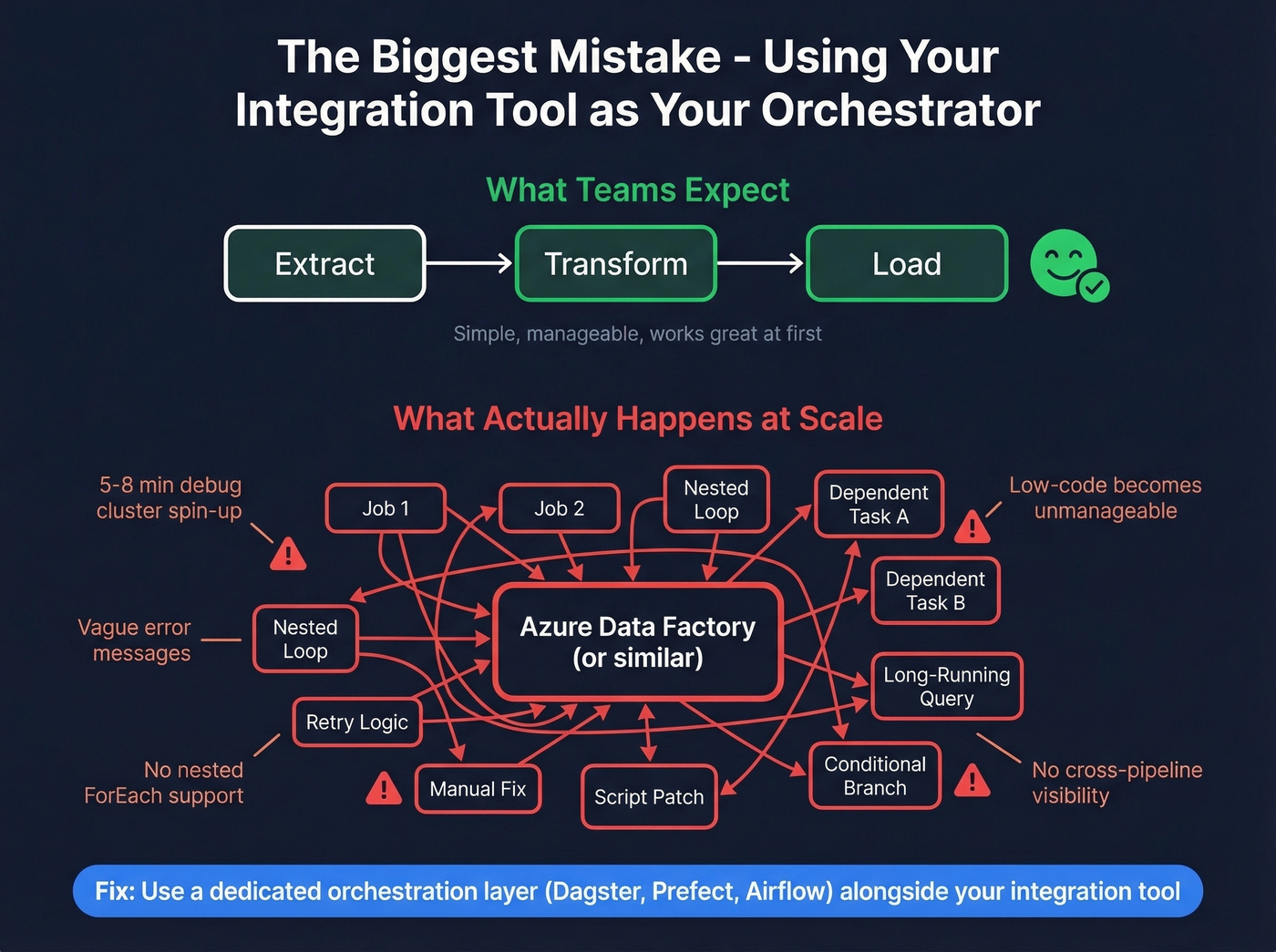
The gotchas pile up fast. Debug clusters take 5-8 minutes to spin up. Error messages are vague. There's no support for nested ForEach loops. Low-code pipelines become unmanageable once you're past a handful of jobs. We've watched teams spend months building increasingly fragile ADF pipelines before finally admitting they need a dedicated orchestration layer. If your integration tool is also your orchestrator, you'll outgrow it - the only question is when.
Tools Worth Knowing in 2026
Integration Tools
Fivetran dominates analytical integration with usage-based pricing based on MAR (monthly active rows) - clean and easy to budget. Airbyte is the open-source alternative for connector flexibility without vendor lock-in; Airbyte Cloud uses credit-based pricing for managed connectors. For operational integration, MuleSoft and Workato are the enterprise standards, though expect $50K+/year contracts. Skip MuleSoft if you're a small team without dedicated integration engineers - the learning curve isn't worth it below a certain scale.
Orchestration Tools
Starting from scratch? Evaluate Dagster or Prefect first. Dagster takes an asset-first approach with strong lineage and observability - the best fit for teams building new stacks. Prefect is Python-native and event-driven, ideal for dynamic workflows. Airflow remains battle-tested with the largest community but carries heavier ops overhead. Managed options like Astronomer, Prefect Cloud, and Dagster Cloud typically start in the low hundreds per month for small teams, scaling into the thousands for larger orgs.
Data Quality: The Layer Everyone Forgets
Let's be honest: most teams agonize over orchestration tooling while ignoring the data quality layer entirely. A perfectly orchestrated pipeline feeding stale contacts into your CRM is just automated failure. If you're evaluating vendors, start with a verified contact database and compare options across the best B2B database lists.
How to Decide What You Need
Choose integration when your data lives in disconnected silos and you don't have a unified view - the problem is fragmentation, not workflow management.
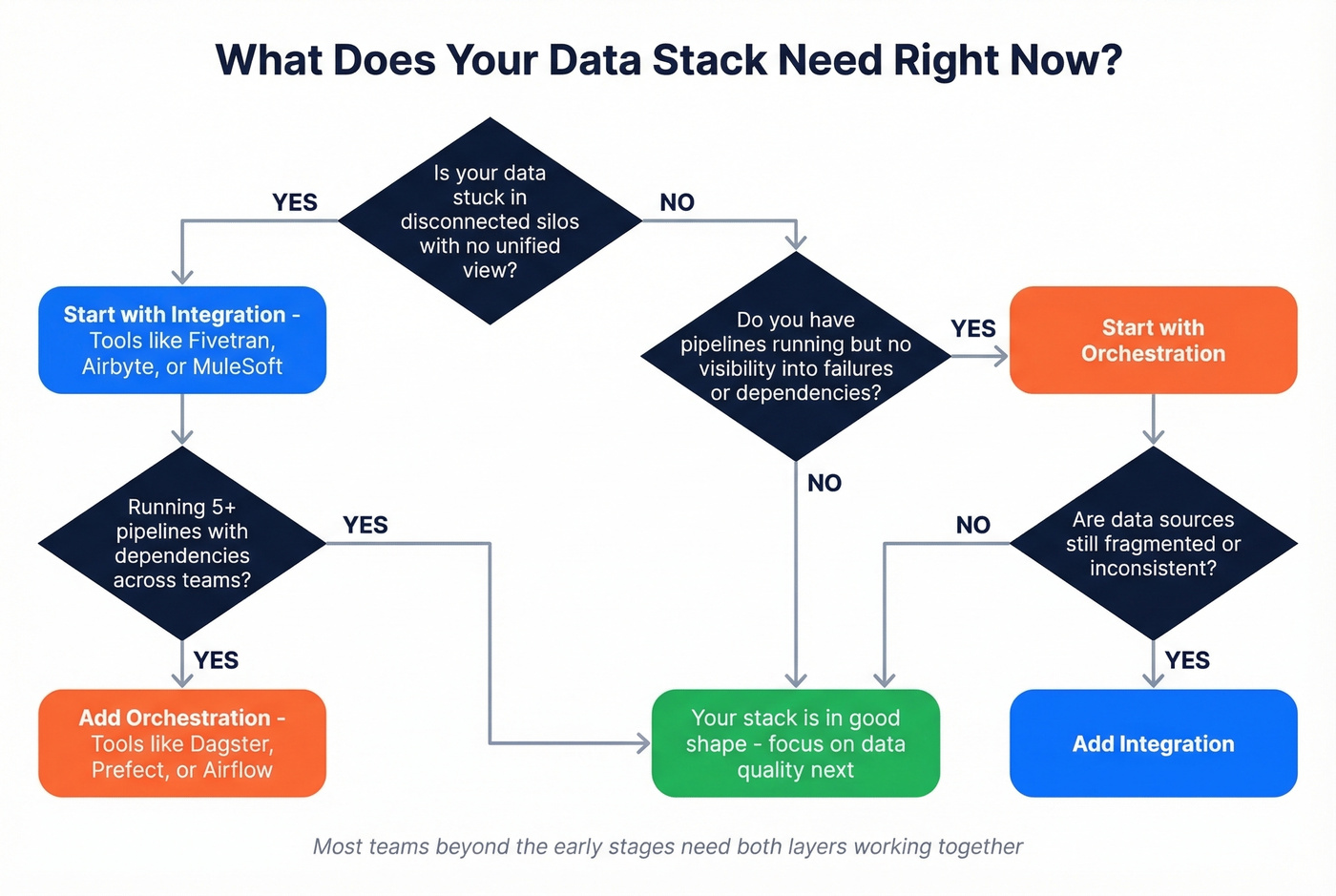
Choose orchestration when your pipelines exist but you've got no visibility into failures, complex dependencies between jobs, or multiple teams stepping on each other's workflows. One scenario we see constantly: a team has Fivetran syncing five sources into Snowflake, dbt running transformations, and a reverse ETL tool pushing segments back to HubSpot - but nobody knows which step failed when the marketing team's audience list goes stale on a Monday morning. That's an orchestration problem, not an integration one.
For teams beyond the earliest stages, you'll need both. When weighing data orchestration vs data integration for your stack, the real question isn't "which one?" It's where your current architecture breaks down first. Fix that layer, then build the other around it - especially if you're also thinking about customer data orchestration across channels.
A perfectly coordinated pipeline feeding outdated contacts into your CRM is just automated failure - you said it yourself. Prospeo's enrichment API returns 50+ data points per contact at a 92% match rate, plugging directly into Salesforce, HubSpot, Clay, and Zapier. No stale records. No silent breakdowns downstream.
Make your data stack worth orchestrating - start with verified contacts.
FAQ
Is data orchestration the same as data integration?
No. Integration combines data from multiple sources into a unified view. Orchestration coordinates and monitors the workflows that move data through your stack - scheduling, dependencies, error handling. They're complementary layers, and most production data stacks need both running in tandem.
What's a concrete example of data orchestration?
A Dagster pipeline that runs nightly: it triggers Fivetran to extract CRM data, waits for completion, kicks off dbt transformations in Snowflake, validates output quality, and alerts Slack if any step fails. That coordination - the sequencing, monitoring, and error handling across tools that don't natively talk to each other - is orchestration.
Do I need both integration and orchestration tools?
For a single pipeline, your integration tool's built-in scheduler will likely be enough. Once you're running 5+ pipelines with dependencies and multiple teams, a dedicated orchestrator pays for itself in visibility alone. The observability gap is what pushes most teams to add orchestration.
How do I keep B2B contact data clean across pipelines?
Use a verification layer before data enters your warehouse. Prospeo's API enriches and verifies contacts with a 92% match rate and 98% email accuracy, refreshing records every 7 days. Plugging it into your integration or orchestration workflow via Zapier, Make, or direct API prevents stale data from propagating downstream.