Data Validation: What It Is, Why It Breaks, and How to Fix It
You've got a "gold layer." It's documented, it's in prod, and the data team swears it's clean. Then a downstream analyst opens it up and the fields don't even match the schema. Poor data quality costs organizations an average of $12.9 million per year, according to Gartner - and that number climbs fast once you start feeding bad data into ML models and AI agents.
Most data validation guides spend 80% of their words on Excel dropdown lists. This one covers the full discipline: pipeline checks, ML pre-training verification, B2B contact verification, and the tooling that actually works in production. Whether you're a data engineer drowning in broken pipelines or a RevOps lead whose outbound sequences keep bouncing, the core problem is identical - data that wasn't checked before it moved downstream.
What You Need (Quick Version)
Here's the hot take: you don't need a "data validation strategy." You need three things - schema tests in your pipeline, anomaly alerts on volume and freshness, and verified contact data before outbound. Everything else is a vendor upsell.
- Pipeline teams: Schema tests plus volume and freshness anomaly alerts. Great Expectations or dbt tests are free to use, but you still need engineering time to implement them properly.
- ML teams: A pre-training checklist covering shape, leakage, distribution stability, and real-world feature availability. No tool replaces this discipline.
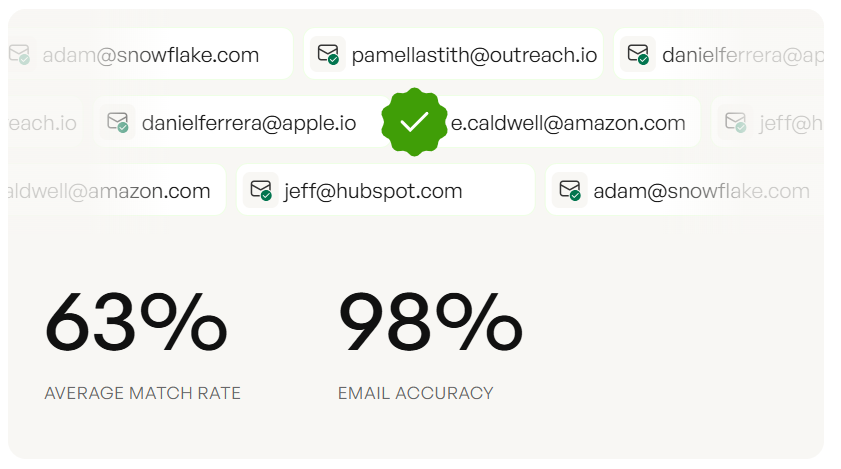
- Sales and RevOps teams: Verified contact data before outbound. A tool like Prospeo runs 5-step email verification at 98% accuracy - catch-all handling, spam-trap removal, honeypot filtering - with a free tier to get started.
Pick the lane that matches your role and jump to the relevant section.
What Is Data Validation?
Data validation is the process of checking whether data meets defined rules for format, type, range, and consistency before it's used downstream. It's the gate between "data exists" and "data is trustworthy." IBM defines it as verifying data is "clean, accurate, and ready for use" - that it falls within permitted ranges, formats, and organization-specific criteria.
The confusion starts when people conflate validation, verification, and data quality. They're related but distinct:
| Validation | Verification | Data Quality | |
|---|---|---|---|
| Scope | Individual entries | Cross-reference against source | Entire dataset lifecycle |
| When | At entry or ingestion | After the fact | Ongoing |
| Focus | Format, type, range rules | Source-of-truth matching | Profiling, cleansing, monitoring |
| Tools | GX, dbt tests, schema checks | Reconciliation queries, audits | Informatica, Monte Carlo, etc. |
| Outcome | Prevents bad data entry | Confirms existing data accuracy | End-to-end data trustworthiness |
Validation is proactive. Verification is reactive. Data quality is the umbrella that covers both - plus profiling, cleansing, and metadata management. Most teams need all three, but validation delivers the highest ROI per hour invested because it stops problems at the source.
Why Bad Data Costs More Than You Think
Bad data doesn't announce itself. It compounds silently until someone notices the dashboard numbers don't add up, or a model starts drifting, or your outbound sequences bounce 23% on the first send.

The numbers are staggering. According to IBM's analysis of IBV research, 43% of chief operations officers identify data quality as their most significant data priority. Over a quarter of organizations estimate they lose more than $5 million annually to poor data quality. Seven percent report losses exceeding $25 million - and those are just the ones willing to put a number on it.
It's getting worse, not better. Gartner forecasts AI spending will surpass $2 trillion in 2026 at 37% year-over-year growth. The stakes of feeding bad data into models have never been higher. And 45% of business leaders cite data accuracy or bias as the leading barrier to scaling AI initiatives. You can't build trustworthy AI on unvalidated data.
The practitioner reality is even grimmer. A recurring pattern on r/dataengineering: users report "numbers don't look right," and engineers end up manually eyeballing data in SQL to find pipeline issues. Sampling the data lake against the source, checking time of last ingestion, comparing volume against historical averages - and issues still slip through. One poster captured the frustration perfectly: "Outside of paying seven figures for an enterprise data quality tool, what do you do?"
The answer is you validate early, validate automatically, and validate at the right layer. Automation alone can reduce manual validation effort by up to 70% - teams report cutting validation time from 5 hours to 25 minutes. But you need to know what to check first.
12 Types of Validation Checks
Every validation rule falls into one of these categories. Some are table stakes; others are where mature teams separate themselves.

| Check Type | What It Does | Example |
|---|---|---|
| Type | Confirms data matches expected dtype | Age field contains integers, not strings |
| Range | Values fall within min/max bounds | Revenue between $0 and $10B |
| Format | Matches expected pattern | Email follows user@domain.tld |
| Presence | Required fields aren't null or empty | Every record has a company name |
| Uniqueness | No duplicate values where uniqueness is expected | One row per customer ID |
| Consistency | Related fields don't contradict each other | Ship date isn't before order date |
| Cross-field | Derived or dependent fields are logically valid | State matches zip code prefix |
| Pattern matching | Regex or pattern-based validation | Phone numbers match country format |
| Code/reference | Values exist in a valid reference set | Country code is in ISO 3166 list |
| Length | String length within acceptable bounds | US zip codes are 5 or 9 characters |
| Schema | Column names, order, and types match contract | No surprise columns or renamed fields |
| Statistical | Distribution, variance, and outliers within norms | Mean order value hasn't shifted 3 sigma overnight |
The first ten are deterministic - they either pass or fail. Statistical checks are probabilistic, which makes them both more powerful and harder to get right. We've seen teams set statistical thresholds too tight and drown in alert fatigue within a week. Start with the deterministic checks. Add statistical validation once you've got the basics running cleanly.
Here's the thing: most pipeline failures trace back to missing presence checks and schema drift. In our experience, those two alone catch 60-70% of issues in a typical data stack.
You just read about 12 validation check types. Prospeo runs five of them automatically on every email - catch-all handling, spam-trap removal, honeypot filtering, format checks, and source verification - at 98% accuracy across 143M+ verified addresses. All refreshed every 7 days, not 6 weeks.
Stop validating contact data manually. Let the infrastructure do it.
Validation in Excel
Excel's Data Validation feature is a cell-level input restriction tool. It's not enterprise-grade checking, and conflating the two is how teams end up with false confidence.
What it does well: dropdown lists for controlled input, number ranges, text length limits, custom formulas for conditional rules (e.g., =AND(LEN(A1)>=3, LEN(A1)<=50) to enforce name length), and input/error messages that guide users. For a 50-row spreadsheet tracking event RSVPs, it's perfectly adequate.
Where it breaks: copying from cells without validation and pasting into validated cells can remove or override validation rules. There's no audit trail, no automated alerting, no version control, and no way to validate relationships across sheets or files at scale.
If your "data validation strategy" lives in Excel, you don't have a strategy. You have a suggestion box. Use Excel validation for what it is - a lightweight input control for small, manual datasets - and move to proper tooling for anything that feeds a pipeline, model, or outbound campaign.
How to Validate Data in Pipelines
Pipeline validation is where the discipline actually matters at scale. The core principle is simple: validate at source, not at consumption. Every hour you delay checking, the blast radius of bad data grows.
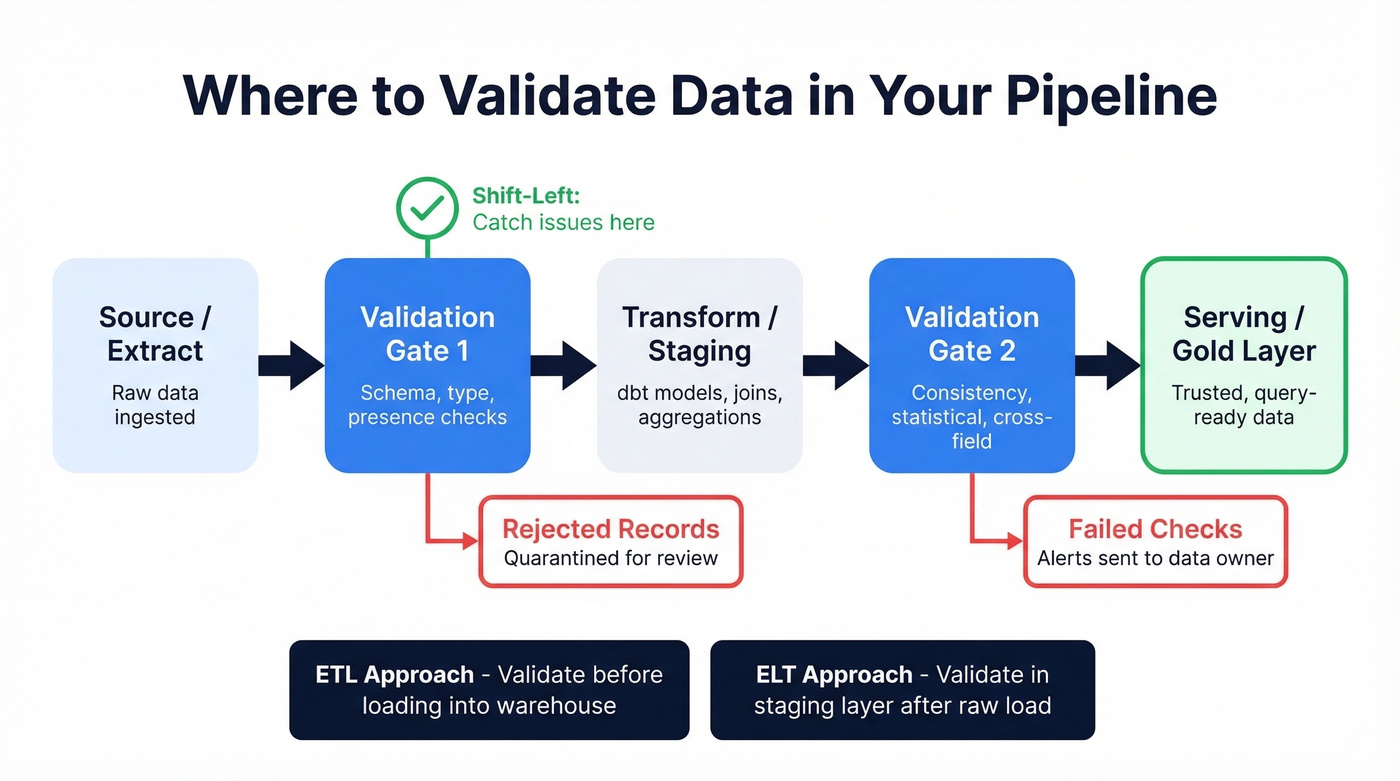
This is the "shift-left" strategy borrowed from software engineering. Instead of catching issues when a dashboard breaks or a stakeholder complains, you catch them at ingestion - before transformation, before serving, before anyone builds a decision on top of bad numbers.
Real-Time vs Batch
Most teams run batch validation - checks execute after a scheduled pipeline run completes. This works well for daily or hourly loads where a few minutes of latency is acceptable. Real-time validation (checking each record as it streams in) matters when you're processing event data, financial transactions, or anything where a bad record can trigger an immediate downstream action.
The tradeoff is straightforward: batch is simpler to implement and debug; real-time catches issues faster but adds infrastructure complexity.
ETL vs ELT Placement
In traditional ETL, validation gates sit between extract and transform - you reject bad records before they enter the warehouse. In ELT architectures (which dominate modern stacks), raw data lands first and validation runs as part of the transformation layer, typically via dbt tests or Great Expectations checkpoints. ELT gives you more flexibility to define rules in SQL, but it also means bad data temporarily exists in your warehouse. The fix is staging layers with validation gates that prevent bad data from reaching serving tables.
Data Contracts and Schema Enforcement
Data contracts are the most underused tool in modern data engineering. A data contract defines ownership, locks the schema, and prevents silent breaking changes before data moves between teams. Think of it as an API contract, but for datasets.
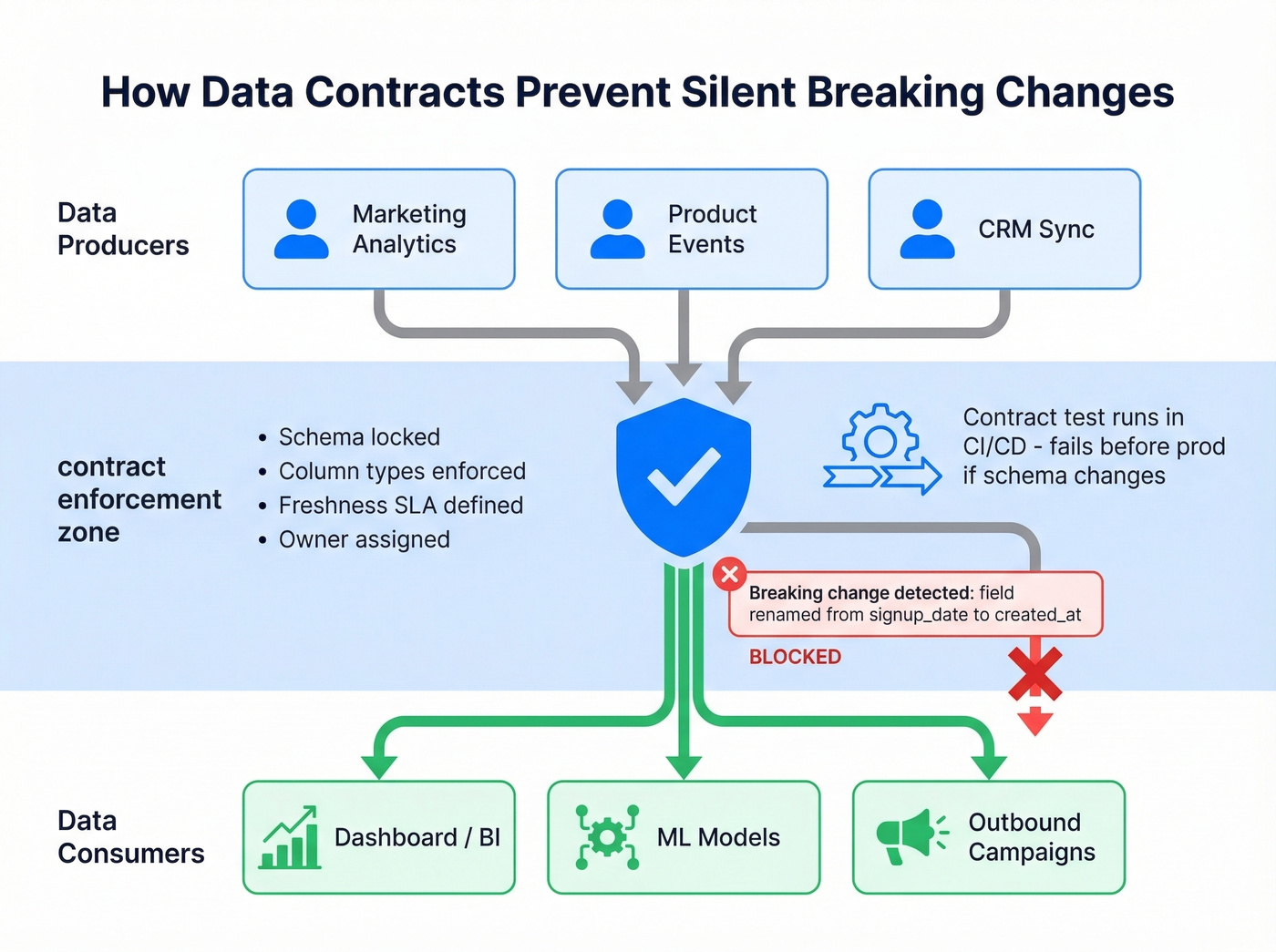
The contract specifies column names, types, allowed values, freshness SLAs, and who owns the data. When a producer changes a field name or adds a column, the contract test fails in CI/CD before the change hits production. No more "gold layer" data arriving with mismatched fields and nobody knowing who to call. A minimal contract might look like this in YAML:
contract:
owner: marketing-analytics
freshness_sla: 6h
schema:
- name: customer_id
type: string
not_null: true
unique: true
- name: signup_date
type: date
range: [2020-01-01, today]
- name: plan_tier
type: string
accepted_values: [free, pro, enterprise]
The r/dataengineering consensus is clear: the root cause of most validation failures is lack of domain ownership. Producers claim data is "deployed and in prod," but only high-level checks reveal it's completely broken. Data contracts force accountability.
Observability vs Monitoring
These three concepts get conflated constantly, but they're distinct:
- Monitoring tells you something broke. A freshness check fires because a table hasn't updated in 6 hours.
- Observability helps you understand why. You trace the failure back to a source API timeout that caused a partial load.
- Validation prevents breakage in the first place. Schema tests, range checks, and volume anomaly alerts catch issues before they propagate.
Track freshness, volume, distribution, and schema drift. Alert on anomalies. But don't confuse observability tooling (Monte Carlo, Soda) with validation frameworks (Great Expectations, dbt tests). You need both layers - one to prevent, one to diagnose.
Validation for AI and ML
With 79% of organizations adopting AI agents in some form, training data validation isn't optional - it's a compliance requirement. The EU Artificial Intelligence Act mandates that high-risk AI systems meet rigorous data governance standards, including validating training data for accuracy, completeness, and bias.
Beyond compliance, invalid training data creates real technical risk. Data poisoning - where corrupted inputs degrade model performance - is one of the hardest problems to diagnose after the fact. Validate before training, not after deployment.
The Pre-Training Checklist
- Shape and dtypes: Validate column count, names, and data types match expectations. Catch schema drift before it becomes model drift.
- Range realism: Flag impossible values - negative ages, $0 enterprise deals, timestamps from the future.
- Category consistency: Check for typos, casing mismatches, rare categories, and placeholder values like "N/A" or "test."
- Duplicate detection: Find exact and near-duplicate records. Duplicates inflate training signal and bias predictions.
- Cross-column relationships: Verify derived fields are consistent. If
total = quantity x price, check that the math holds. - Target leakage: Look for suspiciously high correlations between features and the target variable. Features created after the outcome are the classic culprit.
- Distribution stability: Compare distributions across train/test splits and across time periods. Class imbalance and distribution shift both degrade performance.
- Real-world availability: Every feature in your training set must be available at prediction time. If a feature only exists after the event you're predicting, it's leakage disguised as signal.
Steps 6 and 8 are the ones teams skip most often, and they're the ones that cause the most expensive failures. We watched a team spend three months building a model that performed beautifully in backtesting - only to discover the top feature was a timestamp that didn't exist until after the conversion event. Three months, gone.
Best Tools and Services
Tools fall into four categories: open-source frameworks, B2B contact verification, enterprise platforms, and observability tools. The right choice depends on your stack, team size, and whether you need pipeline checks, contact verification, or both.
| Tool | Category | Best For | Cost |
|---|---|---|---|
| Great Expectations | OSS Framework | Python pipeline validation | Free (1-4 wk setup) |
| dbt tests | OSS (built-in) | SQL-native teams on dbt | Free / ~$100+/mo Cloud |
| Apache Deequ | OSS Framework | Spark batch validation | Free |
| Soda | Hybrid | OSS-to-enterprise bridge | Free tier / ~$300+/mo |
| Prospeo | B2B Contact Verification | Email & contact validation | Free tier / ~$0.01/email |
| Informatica | Enterprise | Full data quality suite | $50K-$250K/yr |
| Monte Carlo | Enterprise | Data observability | $50K-$150K/yr |
| Ataccama | Enterprise | AI-powered data profiling | $30K-$100K/yr |
Open-Source Frameworks
Great Expectations is the most mature open-source validation framework and the one we recommend for most Python-based pipeline teams. You define "expectations" (individual rules), group them into suites, run them via checkpoints, and get human-readable Data Docs as output. It integrates with Pandas, Spark, SQL via SQLAlchemy, and orchestrators like Airflow. Warehouse support covers Snowflake, BigQuery, and Redshift.
Getting started takes about 15 minutes:
pip install great_expectations
great_expectations init
From there, add a datasource, define expectations (e.g., expect_column_values_to_not_be_null, expect_column_values_to_be_between), build a checkpoint, and run it. The official docs and community tutorials walk through the full setup. Budget 1-4 weeks for a production-grade implementation and 0.1-0.5 FTE for ongoing maintenance, depending on pipeline count.
dbt tests are the zero-new-tooling option if you're already running dbt. Built-in schema tests cover not-null, unique, accepted values, and relationships. Custom data tests let you write any SQL assertion. Free with dbt Core; dbt Cloud plans typically start around $100+/month.
Apache Deequ is Spark-native and purpose-built for large-scale batch validation. If your data lives in Spark and you need checks at terabyte scale, Deequ is the right pick.
When to skip frameworks entirely: If you have fewer than 10 tables and a single pipeline, a handful of custom SQL assertions or Python scripts will serve you fine. Frameworks pay for themselves when you're managing dozens of data sources and need standardized reporting, shared expectation libraries, and CI/CD integration. Don't adopt Great Expectations for a three-table Postgres database.
B2B Contact Verification
Let's be honest about a validation problem most data quality guides completely ignore: your prospect list. Sending outbound to unverified email addresses isn't just a marketing problem - it's a verification failure with real consequences. Bounced emails burn domain reputation, waste rep time, and tank deliverability for your entire organization.
Prospeo maintains a database of 143M+ verified emails refreshed every 7 days - compared to the 6-week industry average. That freshness gap matters because email addresses decay quickly as people change jobs. The verification process covers catch-all domains, spam traps, and honeypots, delivering 98% email accuracy so your sequences actually land.
The free tier gives you 75 email verifications per month. Paid plans run about $0.01 per email with no contracts. For teams running outbound at scale, that's a fraction of the cost of a single bounced campaign.
Enterprise Platforms
Informatica is the most complete enterprise data quality suite on the market. It covers profiling, cleansing, matching, monitoring, and validation across structured and unstructured data. Expect to pay $50K-$250K/year depending on modules and scale, plus a steep learning curve.
Monte Carlo takes an observability-first approach - it monitors your data estate for freshness, volume, schema, and distribution anomalies, then helps you trace root causes. It's more diagnostic than preventive, which makes it complementary to validation frameworks rather than a replacement. Pricing runs $50K-$150K/year.
Ataccama differentiates with AI-powered data profiling that auto-suggests rules based on your data patterns. Precisely Trillium focuses on address and identity validation for regulated industries. Talend bundles validation into a broader data integration platform. All three sit in the $30K-$250K+ per year range and are worth evaluating for large organizations with complex governance requirements.
Observability Tools
Soda bridges the gap between open-source and enterprise. It offers a free tier for basic checks and Soda Cloud starting around $300/mo for teams that need dashboards, alerting, and collaboration features without the six-figure commitment.
Common Mistakes to Avoid
Five anti-patterns we see repeatedly:
Silent failures. Validation runs, something fails, and nobody notices because there's no alerting. Every check needs a failure path - an alert, a blocked pipeline, a logged error. A check that fails silently is worse than no check at all, because it creates false confidence.
Validating too late. If you're catching issues at the dashboard layer, you've already lost. By the time a stakeholder says "these numbers don't look right," the bad data has propagated through transformations, models, and reports. Shift left. Check at ingestion.
No ownership. The most common root cause isn't technical - it's organizational. Nobody owns the data. Producers say they "don't know the data." Consumers inherit broken schemas and spend days reconciling naming conventions. Data contracts fix this, but only if someone enforces them.
No automation. If your process involves a human opening a SQL editor and eyeballing row counts, you don't have validation. You have a hope-based strategy. Automate the checks, automate the alerts, and reserve human judgment for the anomalies that automated checks surface.
Trusting labels without checks. Just because a table lives in the "gold" layer or a dataset is labeled "production-ready" doesn't mean it's valid. Labels are assertions. Validation is proof. Run checks on every layer, including the ones someone already told you were clean.
Bad data costs $12.9M per year on average. For outbound teams, that starts with bounced emails and burned domains. Prospeo's proprietary verification catches invalid addresses at $0.01 each - 90% cheaper than ZoomInfo - so your pipeline stays clean before data ever moves downstream.
Validate your contact data at the source for a penny per email.
FAQ
What's the difference between data validation and data verification?
Validation checks whether data meets defined rules - format, range, type - at the point of entry. Verification confirms data matches a trusted external source after the fact. Validation prevents bad data from entering your system; verification audits what's already there. Most teams need both, but validation delivers higher ROI because it stops problems at the source.
Can Excel handle enterprise data validation?
No. Excel's Data Validation feature handles cell-level input restrictions: dropdown lists, number ranges, and text length limits - useful for datasets under 100 rows. Paste operations can silently override rules, there's no audit trail, and it doesn't scale beyond a single file. For anything feeding a pipeline or outbound campaign, use Great Expectations, dbt tests, or a dedicated verification service.
What's the best free tool for pipeline checks?
Great Expectations is the most mature open-source framework, integrating with Pandas, Spark, SQL, Airflow, and major warehouses like Snowflake and BigQuery. For SQL-native teams already on dbt, built-in dbt tests require zero additional tooling.
How do I validate email addresses before outbound?
Run addresses through a multi-step verification process that checks deliverability, catches catch-all domains, and removes spam traps - before you send, not after your bounce rate spikes. A good service handles catch-all domains, honeypots, and spam traps in a single pass, returning a confidence score you can filter on before loading addresses into your sequences.
Does the EU AI Act require data validation?
Yes. The EU Artificial Intelligence Act mandates that high-risk AI systems meet rigorous data governance standards, including validating training data for accuracy, completeness, and bias. Organizations deploying high-risk AI without proper checks face significant penalties, making validation a legal requirement in 2026, not just a best practice.