Lead Scoring Best Practices That Predict Revenue - Not Curiosity
A founder on r/startup built what they thought was the perfect HubSpot scoring model. Whitepaper downloads, pricing page visits, case study clicks - all weighted, all tracked. Their biggest deal that quarter? A lead that scored 12 out of 100. Booked a demo from a cold message, never opened a single email, and closed $20K ARR in three weeks. Meanwhile, their highest scorer - 89 points - was a grad student downloading everything in sight. After scrapping the model and qualifying on problem, budget, and decision-maker alone, their close rate tripled. That's the core problem with most lead scoring best practices: they measure curiosity, not buying intent.
What You Need (Quick Version)
- Three-layer model: ICP fit as a gate, intent signals as a filter, engagement as warmth. In that order. Never let engagement override bad fit.
- Clean data first: If your records have wrong job titles or bounced emails, your scoring model is garbage-in-garbage-out. Fix the data before you build the model.
- Demo requests override everything: Someone asks to talk to sales? Route them immediately. A human conversation beats any algorithm.
A Three-Layer Scoring Framework
Most guides lump fit and engagement into a single composite score. That's how you end up routing students to your AE team. The smarter approach separates scoring into three distinct layers.
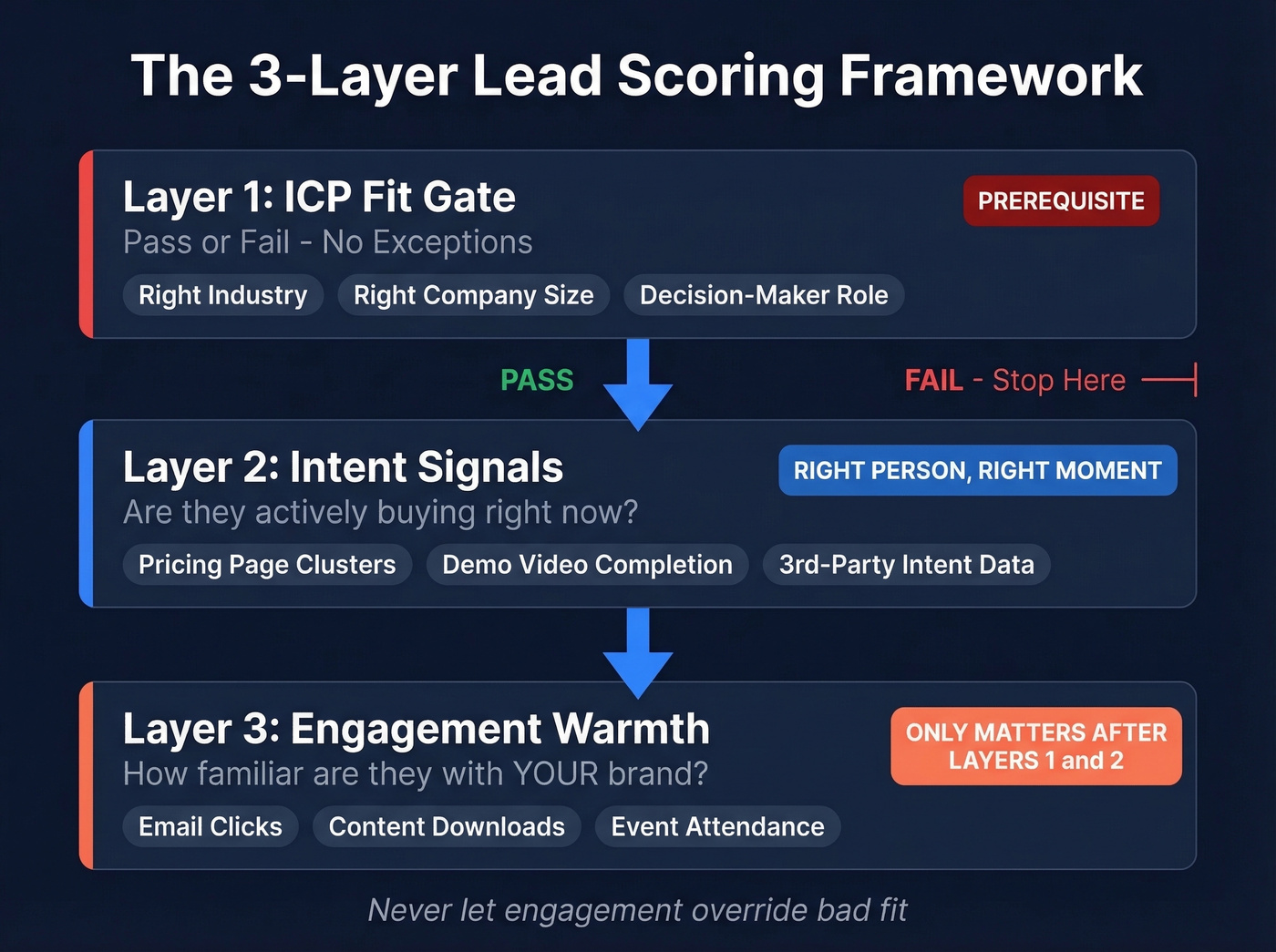
Layer 1 - ICP fit as a gate. This isn't a score booster. It's pass/fail. Wrong industry, wrong company size, wrong role? No amount of webinar attendance should push that lead to sales. Assign negative points for disqualifying attributes and treat fit as the prerequisite, not a variable.
Layer 2 - Intent signals. First-party intent like pricing page clusters and demo video completion, plus third-party intent from platforms like Bombora and 6sense that track in-market research across thousands of topics, tell you whether someone is actively evaluating solutions. This is the layer ZoomInfo's own framework calls the difference between "right prospect, wrong time" and genuine buying readiness. It's the "right person, right moment" filter.
Layer 3 - Engagement warmth. Brand-specific actions: your emails, your content, your events. This layer only matters after a lead passes the first two. It tells you how familiar they are with you specifically, not whether they're in-market. Advanced teams extend this layer post-sale to flag expansion and upsell signals from existing customers.
Six Practices With Real Numbers
Here's the thing - most guides give you nine "best practices" without a single actual point value. We've watched teams spend weeks debating abstract frameworks when what they needed was a starting spreadsheet. These are the numbers that separate strong scoring models from the ones that waste your SDRs' time.
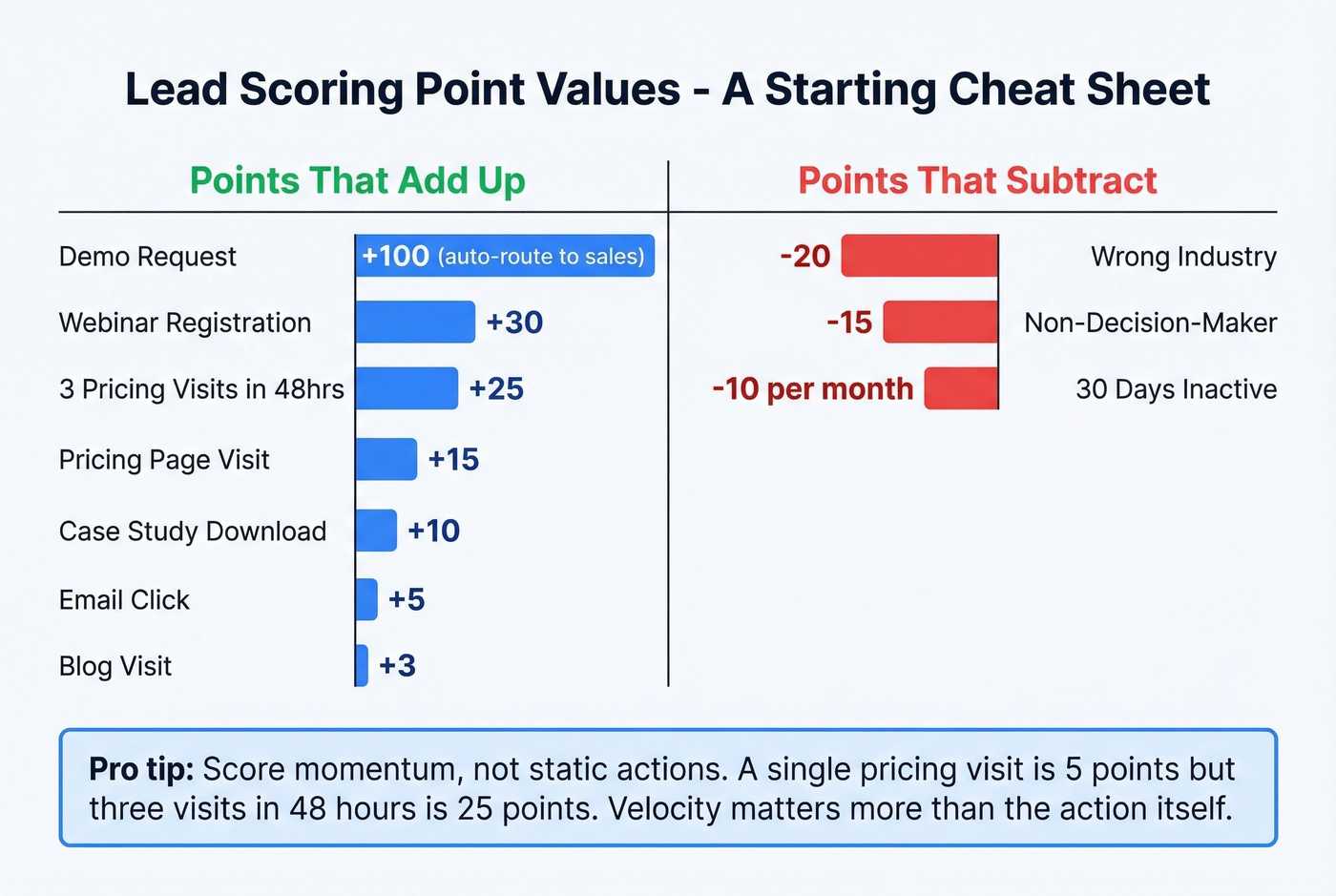
1. Start with fit as a gate. If a lead doesn't match your ICP, no engagement score should push them to sales. Assign -20 for wrong industry, -15 for non-decision-maker roles, -10 for outside your target territory. One team lowered their activity threshold but tightened title and seniority filters - they saw a 13% jump in MQL-to-meeting rate. These negative points ensure high-activity, low-fit leads never clog your pipeline.
2. Score momentum, not static actions. A single pricing page visit is worth maybe 5 points. Three pricing visits in 48 hours? That's 25 points. The velocity matters more than the action itself. Someone who watches 80% of your demo video, hits pricing, and downloads a case study in one session gets 40 points. In HubSpot, use score group limits and overall score caps to keep awareness actions like blog visits from inflating numbers while letting conversion events contribute more.
Watch for buying committee activation separately: multiple contacts from the same company engaging in a short window is one of the strongest signals you'll find.
3. Apply negative scoring and decay. Deduct 10 points for every 30 days of inactivity. A lead that was hot in January and silent through March shouldn't still sit in your SDR queue. Negative points for incomplete data - missing phone number, missing title - also help. If you can't reach them, the score is academic.
4. Set thresholds by sales capacity. Start with 0-30 cold, 31-70 warm, 71-100 hot as defaults. Then adjust based on how many leads your SDRs can actually work. If they're drowning, raise the MQL threshold. If they're idle, lower it. Threshold-setting is operational, not theoretical - test your model by running scored leads against a control group for 45 days and comparing conversion rates.
5. Demo requests override scoring. Someone fills out a "talk to sales" form? Route them immediately regardless of score. Send to sales, let a human qualify. No algorithm is smarter than a real conversation with a motivated buyer.
6. Ignore email opens. Bots, image preloading, and security scanners inflate open rates to the point of meaninglessness - a large share of email "opens" are machine-generated. Scoring opens is how you end up with a model that rewards spam filters. Only count opens when they're paired with clicks and high-intent page views.
You just read it: garbage data in, garbage scores out. Wrong job titles and bounced emails destroy even the best scoring model. Prospeo's 5-step verification delivers 98% email accuracy, and every record refreshes every 7 days - not the 6-week industry average.
Stop scoring leads you can't even reach. Start with clean data.
Scoring Template
Use this as a starting point, then calibrate against your closed-won data after 60-90 days.
| Action | Points | Rationale |
|---|---|---|
| Demo request | 100 (auto-route) | Strongest intent signal |
| Webinar registration | 30 | Active research |
| Pricing page visit | 15 | Evaluating cost |
| 3 pricing visits in 48 hrs | 25 | Momentum signal |
| Case study download | 10 | Solution validation |
| Email click | 5 | Engaged with content |
| Blog visit | 3 | Awareness only |
| Wrong industry | -20 | Fit disqualifier |
| 30 days inactive | -10/month | Score decay |
Manual vs Predictive Scoring
| Dimension | Manual (Rule-Based) | Predictive (ML) |
|---|---|---|
| Setup effort | Low - you write the rules | High - needs data pipeline |
| Data requirement | None | ~1K contacts + 100 deals |
| Transparency | Full - you see every rule | Low - black box |
| Scalability | Breaks at volume | Handles thousands |
| Bias risk | Your assumptions baked in | Training data baked in |

Predictive scoring sounds great until you learn about its failure modes. CRMs like HubSpot and Salesforce store latest-state values, not point-in-time snapshots, so your model trains on data that didn't exist when the scoring decision was actually made - a problem called information leakage. Models look accurate in testing but undervalue early-stage leads in production.
Our recommendation: start manual. Graduate to predictive when you have the data volume to support it, and even then, keep rules-based overrides for demo requests and fit gates. Predictive scoring works best as a prioritization aid, not an autonomous decision engine.
Clean Data - The Prerequisite Everyone Skips
Let's be honest: none of this matters if your underlying data is wrong. If your contact records have outdated emails or incorrect job titles, your fit layer is broken from day one. Wrong titles mean your ICP gate misfires. Bounced emails mean engagement signals never reach the prospect, so your behavioral layer goes dark too. We've seen teams build gorgeous scoring models on top of CRM data that hadn't been cleaned in over a year - and then wonder why their MQL-to-SQL rate was stuck at 8%.
This is where most teams underinvest. Prospeo refreshes contact records every 7 days, returns 50+ data points per enrichment, and verifies emails at 98% accuracy with a 92% API match rate. Your fit scores reflect current job titles and org structures, not last quarter's chart. At roughly $0.01 per email, cleaning your CRM costs a fraction of the scoring platform sitting on top of it.
Deducting points for missing phone numbers and titles? Prospeo enriches contacts with 50+ data points at a 92% match rate - job title, seniority, company size, industry - so your fit gate actually works. At $0.01 per email, fixing your scoring foundation costs less than one bad MQL.
Enrich your CRM so every lead scores against real data, not gaps.
What Scoring Tools Cost
Here's a hot take: you can spend $3,600/month on HubSpot Enterprise for predictive scoring, but if the underlying contact data is stale, you're just predicting faster with bad inputs. For deals averaging under $20K, you probably don't need a six-figure intent platform either. The enrichment layer is the cheapest line item on this list and the one that matters most.

| Tool | Tier | Cost | Notes |
|---|---|---|---|
| Prospeo | Data enrichment | Free tier, ~$0.01/email | Data quality layer |
| HubSpot | Professional | $890/mo, 3 seats | Manual scoring |
| HubSpot | Enterprise | $3,600/mo, 10 seats | Predictive scoring |
| Salesforce Einstein | Sales Cloud + Einstein | ~$215/user/mo | $165 base + $50 add-on |
| 6sense | Enterprise | $60K-$300K/yr | Intent + account scoring |
Skip 6sense if you're under 50 reps or your average deal size is below $30K. The ROI math just doesn't work at that scale.
FAQ
What's a good MQL-to-SQL conversion rate?
A solid starting benchmark is 30% - roughly 400 MQLs producing 120 SQLs. If you're significantly below that, your scoring model is passing unqualified leads. Tighten fit criteria before adjusting engagement weights.
How often should I update my scoring model?
Review weekly for the first month after launch, then shift to quarterly. Adjust thresholds whenever sales capacity changes or your MQL-to-SQL rate drifts more than 5 points in either direction.
What's the difference between lead scoring and lead grading?
Lead scoring measures behavior - what a prospect does. Lead grading measures fit - who a prospect is. In the three-layer framework above, grading is Layer 1 and scoring covers Layers 2 and 3. You need both, but grading should always come first.
How do I keep scoring data accurate over time?
Use an enrichment tool that refreshes records automatically. Stale data is the top reason scoring models degrade within 90 days of launch - job titles change, people switch companies, emails bounce. Budget roughly $0.01 per record for ongoing verification and build a quarterly audit into your RevOps calendar.