Probabilistic Matching: What It Is, How It Works, and How to Do It Right
A RevOps lead spent three weeks building deterministic matching rules for a patient registry merge. Exact match on name, date of birth, and postal code. The rules looked clean - until they missed 8% of true duplicates because one system stored "Robert" and the other stored "Bob." That's not an edge case. That's the norm.
Probabilistic matching exists because real-world data is messy, and rigid rules can't handle the mess.
The Short Version
This approach uses weighted evidence from multiple fields to estimate whether two records refer to the same entity. It outperforms deterministic rules in virtually every setting when properly configured - a peer-reviewed analysis found no settings where deterministic quality can't be equalled or exceeded by well-designed probabilistic linkage.
If you want to implement it today:
- Splink - Python, open-source, Fellegi-Sunter native, actively maintained
- Dedupe - Python, active learning workflow
- fastLink - R, EM algorithm built in
- Zingg - Spark-based, built for large-scale workloads
What Is Probabilistic Matching?
Probabilistic matching is an evidence-based approach to deciding whether two records refer to the same real-world entity. Instead of requiring exact agreement on specific fields (deterministic matching) or just measuring how similar two strings look (fuzzy matching), it weighs evidence from multiple fields simultaneously and outputs a match probability.
The core idea comes from a 1969 paper by Ivan Fellegi and Alan Sunter. Each field comparison contributes evidence for or against a match. A rare surname agreeing is stronger evidence than a common first name agreeing. A date-of-birth mismatch is more damning than a missing postal code. The model combines all of this into a single score.
Think of it like a courtroom. Instead of a checklist where every box must be ticked, the model weighs the evidence from each field and renders a verdict based on the totality.
Why Deterministic Rules Fall Short
Here's a concrete example from the Splink documentation. Two records: "Bob Smith, 1990-01-01, London" and "Robert Smith, 1990-01-01, [missing postcode]." A human glances at these and says "probably the same person." A deterministic rule requiring exact match on first name AND postcode returns zero matches. The pair is discarded entirely.
This happens every day in healthcare systems, government registries, and CRM databases. Deterministic matching is computationally cheap and often high-precision, but it's prone to catastrophically low recall.
The consequences are real. England's Hospital Episode Statistics Identifier (HESID) system had a missed match rate of 8.6% in 1998. Adding a probabilistic step brought that down to 0.4% by 2015 - an order-of-magnitude reduction in linkage errors across millions of patient records. The HESID case also shows what most production systems end up doing: a deterministic first pass for easy matches, then a probabilistic second pass to catch everything the rules missed.
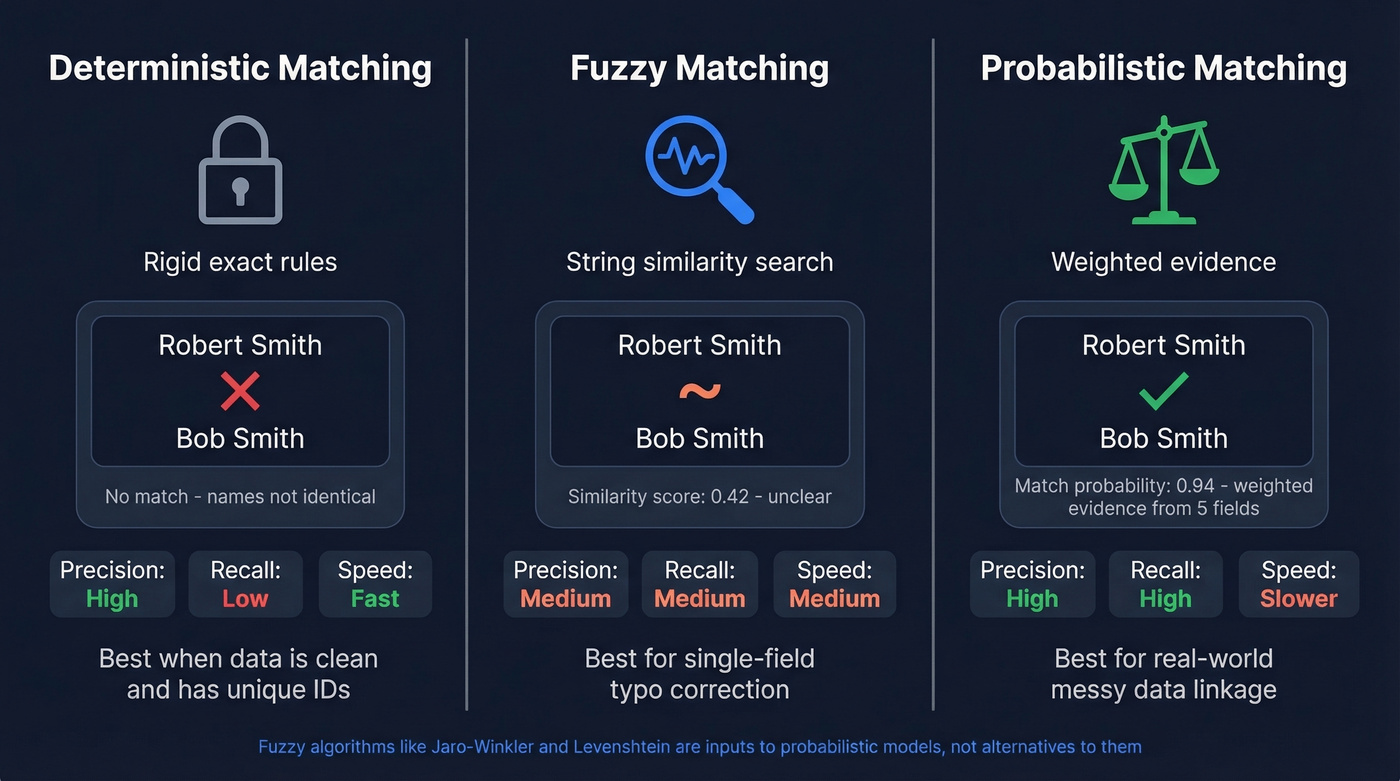
Probabilistic vs. Fuzzy vs. Deterministic
These three terms get thrown around interchangeably, and it causes real confusion. Let's clear it up.
| Approach | How It Works | Strengths | Weaknesses | Best For |
|---|---|---|---|---|
| Deterministic | Exact match on rules | Fast, high precision | Low recall, brittle | Clean data with UIDs |
| Fuzzy | String similarity scores | Catches typos | No field weighting | Single-field cleanup |
| Probabilistic | Weighted evidence across fields | Best recall on incomplete records | Requires configuration | Real-world linkage |
The critical distinction: fuzzy matching algorithms - Levenshtein distance, Jaro-Winkler, Soundex, Metaphone, N-grams, Hamming distance, Jaccard similarity - are components that a probabilistic model can incorporate. They aren't alternatives to it. The model uses string similarity as one input among many, then weighs each field's evidence into an overall match probability.
A common trap is over-relying on TF-IDF approaches for structured records. TF-IDF can overemphasize common terms like "John" while missing the structural context that makes weighted evidence-based linkage effective, as DataGroomr's analysis points out. Fuzzy matching also struggles with naming convention variation - "J. Smith" vs. "Johnathan Smith" isn't a typo, and edit-distance metrics handle it poorly.
How the Fellegi-Sunter Model Works
The Fellegi-Sunter model has three core parameters. Once you understand them, the rest clicks into place.
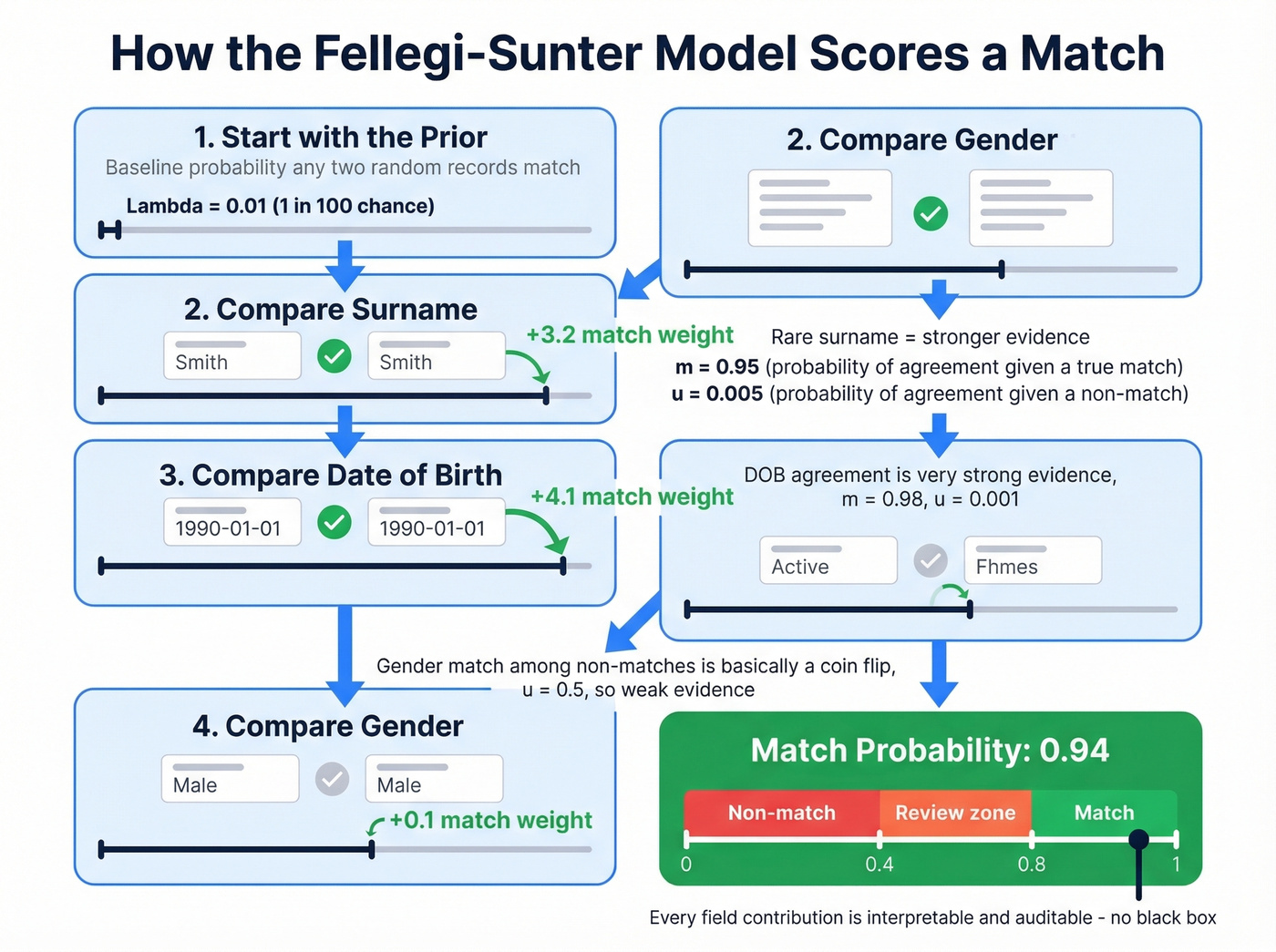
Lambda is the prior match probability - the baseline chance that any two randomly selected records are a true match. Two overlapping patient registries might have lambda = 0.01. Two independent databases with minimal overlap might have lambda = 0.0001.
m-probabilities represent the chance of observing a particular comparison outcome given that the records truly match. If two records genuinely belong to the same person, the probability their dates of birth match exactly might be around 0.98, allowing for occasional data entry errors. Higher m-probabilities correspond to fields that are more reliable for true matches.
u-probabilities represent the chance of observing that same outcome given that the records don't match. A surname match among non-matches might have u around 0.005 - rare enough to be strong evidence. A gender match among non-matches might have u around 0.5 - basically a coin flip, carrying almost no evidential weight.
The step-by-step process, adapted from Robin Linacre's interactive walkthrough:
- Start with the prior. Before comparing any fields, you have a baseline probability that two records match.
- Compare the first field. If surnames agree, the match weight shifts upward - more for rare surnames, less for common ones. Disagreement shifts it down.
- Compare the next field. Date of birth agrees? Strong upward shift. Gender agrees? Barely moves the needle.
- Sum the partial match weights. Each field comparison adds or subtracts from the running total.
- Convert to a final match probability between 0 and 1.
That's it. The math is more transparent than most ML approaches - every field's contribution to the match score is interpretable and auditable, which is a genuine advantage in regulated industries.
You're reading about probabilistic matching because your data has duplicates, conflicts, and gaps. Prospeo eliminates that problem upstream - 300M+ profiles run through a 5-step verification pipeline with catch-all handling, spam-trap removal, and honeypot filtering. Every record refreshed every 7 days, not 6 weeks. 98% email accuracy means you spend zero time reconciling "Bob" vs. "Robert."
Start with clean data and skip the matching entirely.
Blocking, Thresholds, and Scale
Why Blocking Is Mandatory
Without blocking, comparing every record to every other record requires (n squared - n)/2 operations. For 1 million records, that's roughly 500 billion comparisons. No amount of hardware makes that practical.
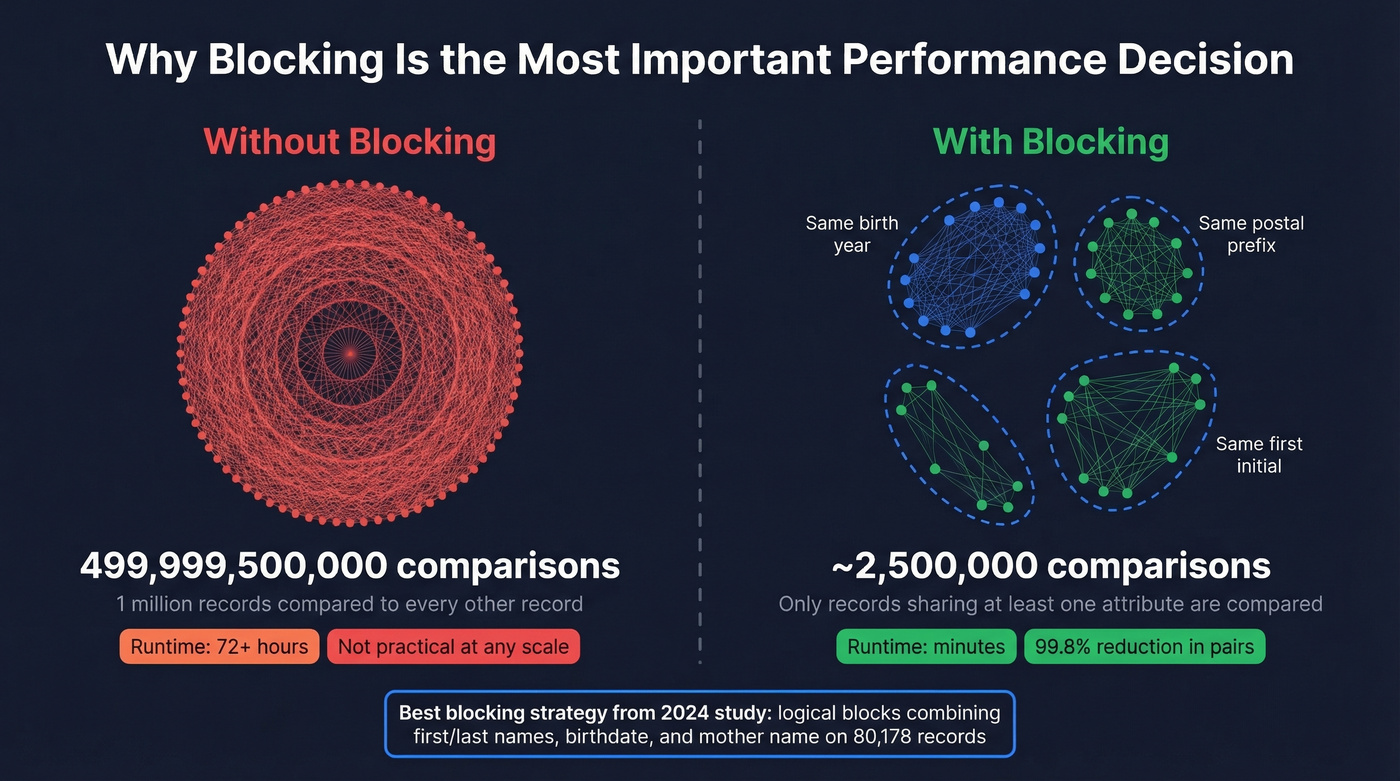
Blocking restricts comparisons to candidate pairs that share at least one attribute - same first initial, same birth year, same postal code prefix. A 2024 study on 80,178 records found the best blocking strategy used logical blocks combining first/last names, birthdate, and mother's name. We've seen teams treat blocking as an afterthought and then wonder why their pipeline takes 72 hours to run. It's the single most impactful performance decision you'll make.
Setting Match Thresholds
Once you have match scores, you need a cutoff. The same Brazil study found that a cutoff score of 17.9 or higher identified 98.46% of true pairs while filtering out 90.04% of false pairs. Strong result, but the right threshold depends entirely on your use case.
For research - where missing a true match means biased results - lower the threshold to favor recall. For service delivery - where a false match means the wrong patient gets the wrong treatment - raise it to favor precision. There's no universal "correct" cutoff. Start with your tool's default, then tune against a labeled sample.
What Breaks at Scale
Dedupe, one of the most popular open-source tools, failed to scale beyond 2 million records due to memory constraints in benchmark testing. That's fine for most use cases, but large-scale projects need different tools. MERAI processed 15.7 million records in the same benchmark. Zingg, built on Apache Spark, is designed for large-scale deduplication and linkage workloads.
If you're working with tens of millions of records, plan your tool choice around this constraint from day one. Skip Dedupe entirely and go straight to Zingg or a commercial MDM platform.
Real-World Benchmarks
Healthcare Accuracy Numbers
The best published benchmarks come from healthcare, where this approach has decades of operational history. The 2024 Brazil public health study achieved AUC 0.979, accuracy 93.26%, sensitivity 98.46%, and specificity 90.04% on 80,178 records. A 2026 Indiana evaluation using a modified Fellegi-Sunter algorithm reported F1 above 0.82 across all age strata, with sensitivity ranging from 0.70 to 0.97 depending on the demographic group.
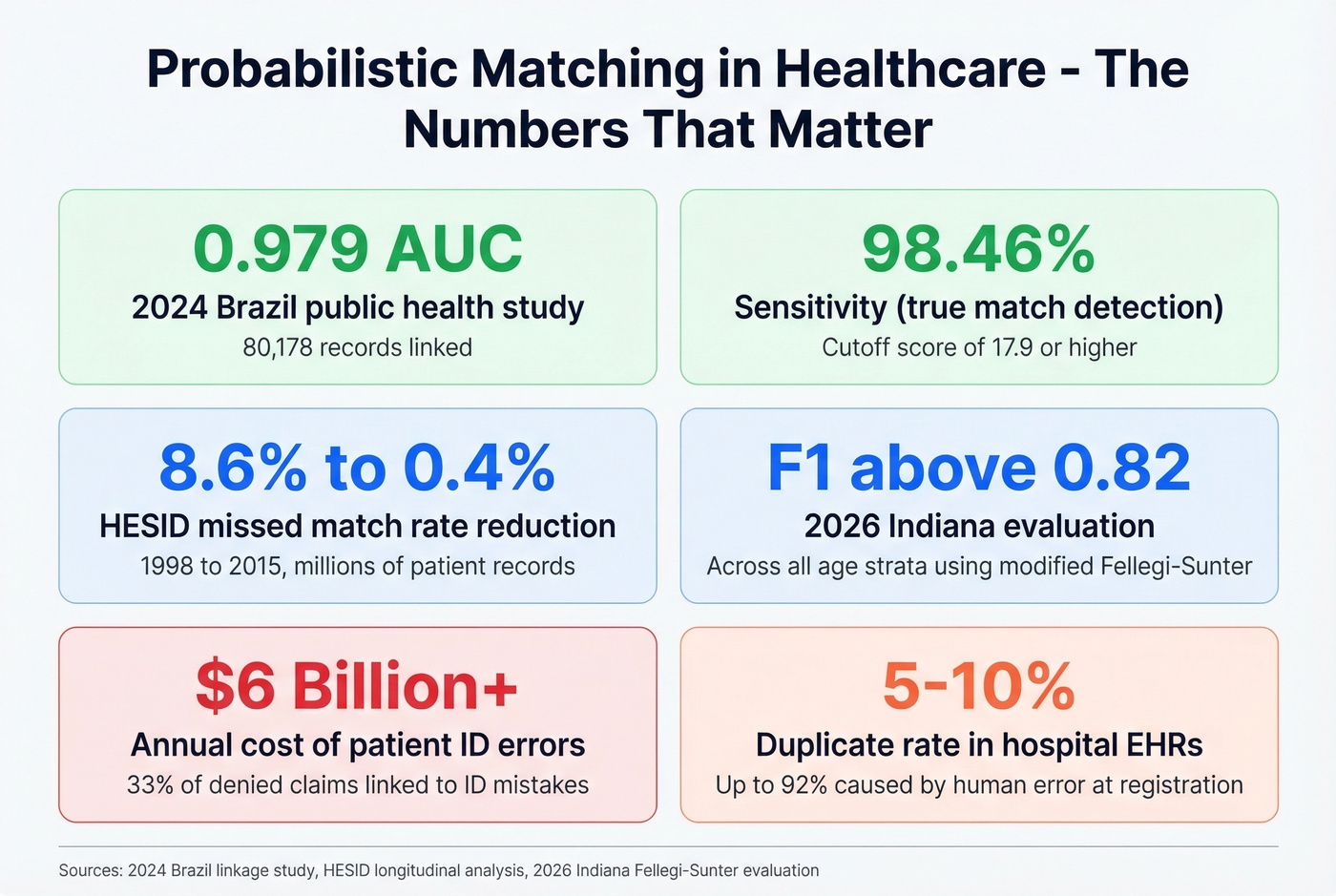
For context: duplicate records occur in 5-10% of hospital EHRs, with up to 92% resulting from human error during registration. Patient ID errors are linked to 33% of denied claims and over $6 billion in annual costs. These aren't abstract numbers - they're the reason probabilistic matching became standard practice in healthcare before most other industries even knew the term.
Bias and Fairness
Here's the thing most record linkage guides won't tell you: your model's accuracy isn't uniform across populations. The HESID study found that missed matches disproportionately affected ethnic minorities, foreign patients, and people in high-deprivation areas. The 2026 Indiana study confirmed this pattern - lower performance correlated directly with missingness and discordance in race/ethnicity fields.

Shannon entropy and distinct value ratio were strongly associated with performance variation. When a demographic group has more missing data or more inconsistent data entry, the model performs worse for that group. You can report "99.6% overall accuracy" while hiding a 3x higher miss rate for minority populations.
Always stratify your evaluation metrics by demographic group. If you don't, you aren't measuring what you think you're measuring.
If your probabilistic matching pipeline doesn't include a fairness audit stratified by demographic group, you don't have a production-ready pipeline. You have a prototype.
Identity Resolution Beyond the Binary
The biggest misconception is that "deterministic vs. probabilistic" is a meaningful binary choice. A peer-reviewed analysis in the Journal of the American Medical Informatics Association argues convincingly that most commonly stated distinctions between deterministic and probabilistic identity resolution are misleading. The real differences come from implementation choices - blocking strategy, threshold selection, variable weighting, data preprocessing - not from some intrinsic superiority of one paradigm.
A recurring question in data engineering communities is whether weighted evidence-based linkage is "worth the complexity." The answer is almost always yes. The reluctance some teams have toward these methods usually stems from misconceptions about the math, not from actual performance shortcomings.
Tools for Probabilistic Matching
| Tool | Language | Capabilities | Learning | Maintained |
|---|---|---|---|---|
| Splink | Python | Link + Dedup | Unsupervised | Yes |
| Dedupe | Python | Link + Dedup | Active | Yes |
| fastLink | R | Link only | Unsupervised (EM) | Yes |
| Python Record Linkage Toolkit | Python | Link + Dedup | Multiple | Yes |
| Zingg | Spark/Java | Link + Dedup | Active | Yes |
| JedAI | Java | Link + Dedup | Multiple | Yes |
Splink is our default recommendation. Fellegi-Sunter native, excellent documentation, maintained by the UK Ministry of Justice's analytical services team. We've used it on multiple internal projects and it's the fastest path from "I want to try probabilistic matching" to "I have match scores."
Dedupe is the right choice for active learning - you label a small sample of pairs and the model learns your matching criteria. Watch the 2M-record ceiling.
fastLink is the go-to for R users, implementing Fellegi-Sunter with an EM algorithm and graceful missing-data handling.
For enterprise scale, Zingg runs on Apache Spark and handles datasets that would crash Dedupe. Commercial MDM platforms solve the same problem at $50K-$200K+/year - worth it for regulated industries that need vendor support, overkill for everyone else.
The LLM Era
The frontier is moving beyond classical Fellegi-Sunter. EnsembleLink represents a new approach: zero-label entity resolution using pretrained language models for semantic similarity. No training labels required.
The pipeline works like this: dense + sparse retrieval feeds into cross-encoder reranking, then selects the top candidate. It runs locally on open-source models - Qwen3-Embedding-0.6B for embeddings, Jina Reranker v2 for reranking. A typical query with 50 candidates takes about 0.5 seconds on a consumer GPU.
This doesn't replace Fellegi-Sunter for structured data with well-defined fields. But for messy, semi-structured records where traditional blocking strategies struggle, LLM-based approaches are increasingly competitive. We're evaluating EnsembleLink for production workloads in 2026 and expect this category to mature fast.
Applying Probabilistic Thinking to B2B Data
The same evidence-based principles that power probabilistic record linkage also drive modern B2B data platforms. When you're building prospect lists, data accuracy depends on verification pipelines that go beyond simple deduplication - you need multiple signals, weighted evidence, and continuous re-verification. Stale data is just another form of linkage error.
Prospeo applies this multi-signal approach to B2B contact data. Its 5-step verification process checks every email through catch-all handling, spam-trap removal, and honeypot filtering, achieving 98% email accuracy across 300M+ professional profiles. Where most platforms refresh data every six weeks, Prospeo runs a 7-day refresh cycle - and if you're building outbound lists and care about deliverability, that refresh cadence matters more than database size.
Probabilistic matching fixes bad data after the fact. But the best linkage strategy is never needing it. Prospeo's proprietary email infrastructure verifies every contact before it reaches your CRM - 92% API match rate, 83% enrichment rate, 50+ data points per record. Teams using Prospeo cut bounce rates from 35%+ to under 4%.
Stop deduplicating downstream - get it right at the source for $0.01 per email.
FAQ
What's the difference between probabilistic and fuzzy matching?
Fuzzy matching measures string similarity between individual fields using algorithms like Levenshtein or Jaro-Winkler. Probabilistic matching uses string similarity as one input among many, weighting each field's evidence and combining them into an overall match probability via the Fellegi-Sunter model. Fuzzy matching is a component; probabilistic matching is the framework.
When should I use deterministic instead of probabilistic matching?
Use deterministic matching when you have a reliable unique identifier - like SSN or national ID - present in both datasets with minimal errors. In most real-world scenarios with messy, incomplete data, probabilistic linkage delivers equal or better results with far fewer missed matches.
How do I choose a match threshold?
Start with your tool's default, then tune against a labeled sample of known matches and non-matches. Research use cases typically favor higher recall (lower threshold), while service delivery favors higher precision (higher threshold). The 2024 Brazil study found a cutoff of 17.9 or higher achieved 98.46% sensitivity and 90.04% specificity - a useful baseline.
Can this approach handle millions of records?
Yes, with proper blocking. Without blocking, pairwise comparisons grow quadratically - 1M records means roughly 500 billion comparisons. Tools like Splink and Zingg implement blocking natively. Dedupe struggles beyond 2M records due to memory constraints, so plan your tool choice around your data volume.
How does data quality affect match accuracy?
Verification pipelines that check multiple signals outperform single-rule validation. In healthcare, multi-field probabilistic linkage catches matches that single-field rules miss entirely. In B2B prospecting, multi-step email verification - including catch-all handling and spam-trap removal - catches invalid addresses that simple syntax checks miss. More evidence, better decisions.