Touchpoint Data: What It Actually Is and Why Most Teams Get It Wrong
Your GA4 attribution report says one channel drove the conversion. HubSpot says it was another. Same quarter, same customers - different answers. The problem isn't the attribution model. It's the touchpoint data feeding it.
Touchpoint data is the event-level dataset generated every time someone interacts with your brand - ad clicks, page views, email opens, demo requests. It's the raw material for attribution and journey analytics, and most teams collect plenty of it but fail at three things: identity resolution, privacy compliance, and upstream data quality. We're going to break down all three.
What Is Touchpoint Data?
A "touchpoint" is a marketing concept - any moment a prospect interacts with your brand. The structured, event-level dataset that records those interactions with enough detail to analyze them is what we call touchpoint data. Every row is one interaction, timestamped and tagged with context:
| Field | Example | Purpose |
|---|---|---|
| event_id | evt_8a3f2c | Unique identifier |
| timestamp | 2026-06-14T09:32:11Z | When it happened |
| channel / source | google / cpc | Where it came from |
| campaign_id | summer_launch_q3 | Campaign attribution |
| user_id / anonymous_id | usr_442 / anon_9f1 | Identity anchor |
| consent_state | granted | Privacy compliance flag |
That consent_state field matters more than most teams realize. It's what lets you separate attributable events from modeled ones when consent is missing.
How Interaction Data Gets Collected
Event-level records flow through multiple pipes, each with different reliability and privacy characteristics.
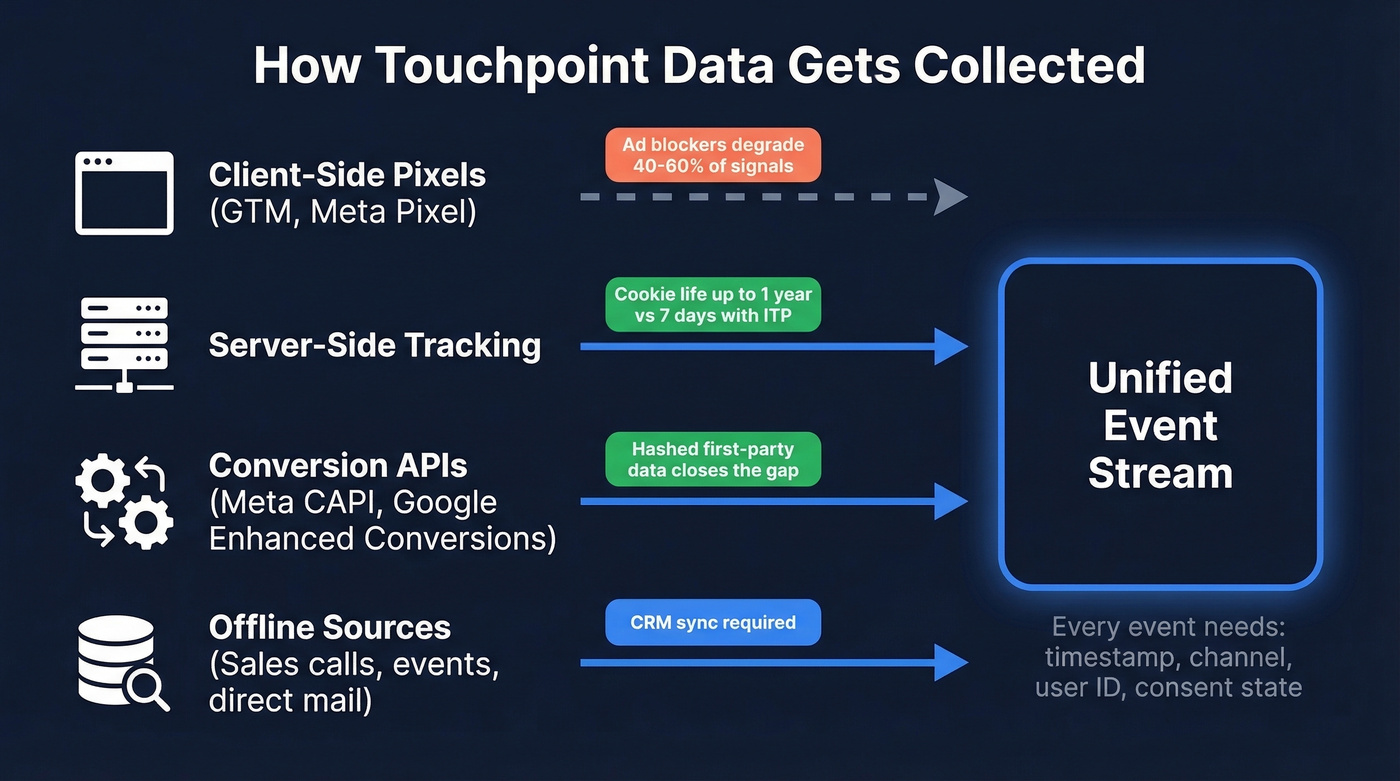
Client-side pixels and tags like Google Tag Manager and Meta Pixel are fast to deploy but increasingly degraded by ad blockers and consent requirements. Server-side tracking is the dominant 2026 pattern for good reason: server-managed cookies can extend attribution windows to a full year, versus the 7-day cap ITP imposes on JavaScript-set cookies. That's not a minor difference - it's the difference between seeing a real buying journey and seeing disconnected fragments.
Conversion APIs - server-to-server connections like Meta CAPI and Google Enhanced Conversions - use hashed first-party data to close the gap. And then there's the offline layer: sales activity, call logs, trade show scans, direct mail responses pulled into the event stream via CRM sync.
Here's the thing. When tracking opt-out and data loss hits 40-60%, traditional multi-touch attribution breaks. You're modeling half the journey and measuring the other half, then pretending the output is precise.
Identity Resolution: The Hard Part
Collecting events is easy. Making them usable requires stitching anonymous interactions to known people.

Two approaches dominate. Deterministic matching uses login IDs or email addresses to link events - accurate but limited to authenticated sessions. Probabilistic matching uses IP, device fingerprint, and timing patterns to infer identity - broader reach, noisier results. If you have high login rates, lean deterministic. Skip probabilistic in regulated industries where false matches create compliance risk.
But the biggest identity failure we see isn't the algorithm. It's Person ID inflation - creating multiple identifiers for the same customer because collection practices are sloppy. One person shows up as three "users," and your journey analytics tells a story about three short journeys instead of one long one. We've watched teams spend months debugging pipeline attribution models when the real issue was duplicate contact records upstream.
Person ID inflation starts with duplicate, outdated contact records - the exact upstream problem this article describes. Prospeo's 5-step verification and 7-day refresh cycle eliminate the stale emails and duplicate contacts that silently corrupt your touchpoint data. 98% email accuracy means fewer bounces, more measurable interactions, and attribution models that actually reflect reality.
Stop debugging attribution models when the real fix is upstream data quality.
Privacy Constraints in 2026
Over 80% of the global population now lives under some form of data privacy law. Google Consent Mode v2 is mandatory for EEA/UK targeting. Safari and Firefox's ITP caps JavaScript-set first-party cookies to 7 days - 24 hours in some scenarios.
The stakes aren't just analytical. Research from Cisco's 2024 Data Privacy Benchmark Study found 94% of organizations say customers won't buy if their data isn't properly protected. Pixels transmitting user data without proper consent can create VPPA and wiretap law exposure in the US and joint-controller risk under GDPR. Privacy isn't a compliance checkbox. It's a revenue variable.
How Touchpoint Data Powers Attribution
Attribution is where this dataset earns its keep. As one r/GoogleAnalytics commenter put it, everyone wants "Meta ad -> Google search -> conversion" pathing, but few tools deliver it cleanly. And rule-based models like linear or time-decay? They're assumptions dressed up as data.
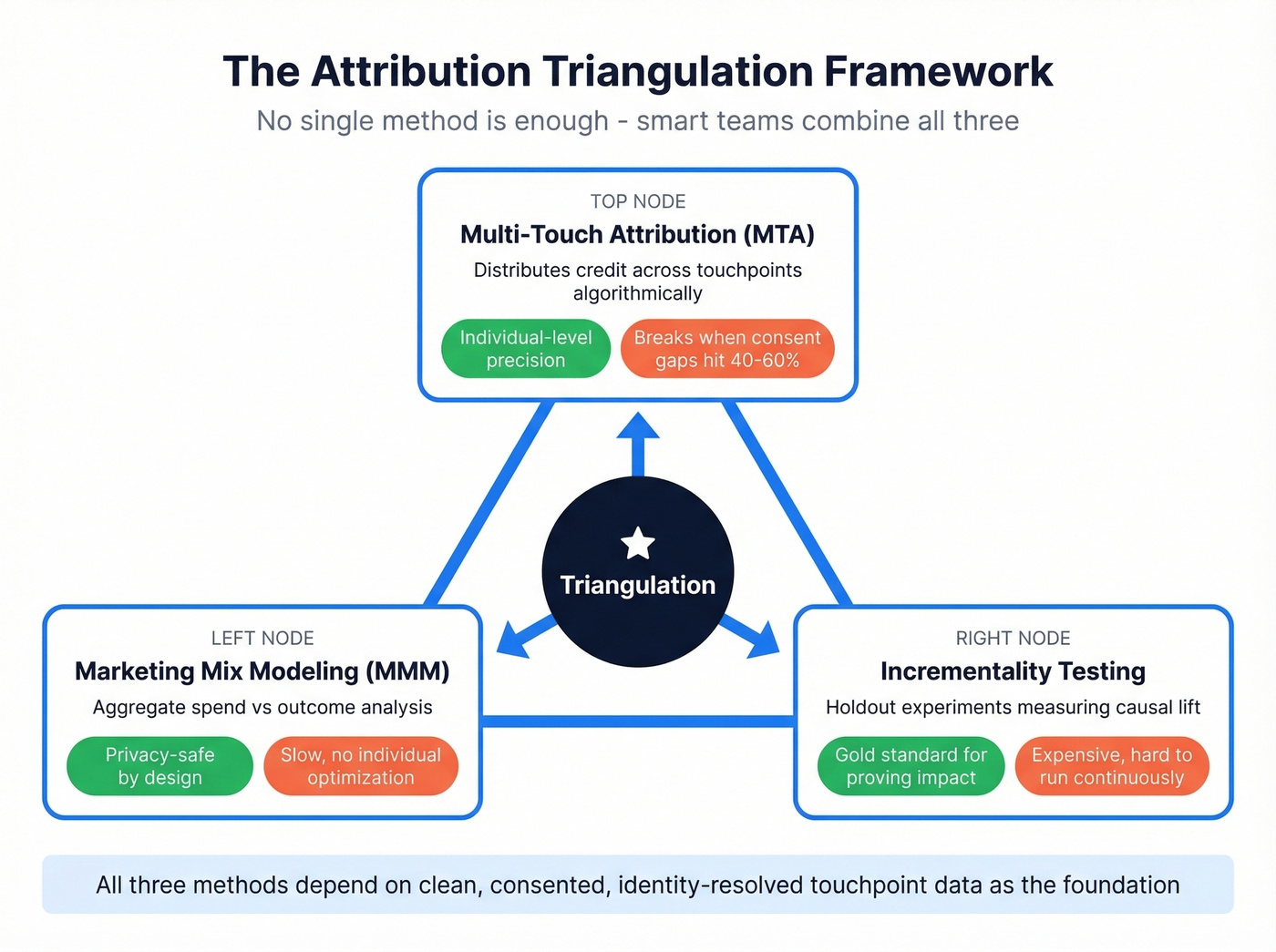
| Approach | How It Works | Tradeoff |
|---|---|---|
| Multi-touch attribution (MTA) | Distributes credit across touchpoints algorithmically | Requires clean, consented, identity-resolved data - breaks when privacy gaps erode the foundation |
| Marketing mix modeling (MMM) | Aggregate-level analysis using spend and outcome data | Privacy-safe by design, but slow and unable to optimize individual journeys |
| Incrementality testing | Measures causal lift through holdout experiments | Gold standard for proving impact, but expensive and hard to run continuously |
The smart play is triangulation. Adobe's Mix Modeler explicitly combines aggregate data, event-level interaction records, and exogenous variables into a unified framework. That convergence of MTA and MMM is where the industry is heading, and it demands clean touchpoint data as the foundation.
Tools That Manage Touchpoint Data
The journey analytics market sits at $24.65B - and 86% of companies with multiple CX tools report siloed data. The CDP market alone is projected to grow from roughly $9.7B to over $37B by 2030.

Quick distinction worth making: a CRM manages sales workflows. A DMP handles anonymous, cookie-based ad data. A CDP builds persistent, first-party customer profiles with identity resolution - it's the layer that makes your interaction records usable across systems.
| Category | Tools | Best For |
|---|---|---|
| CDPs | Segment, mParticle, Tealium | Enterprise multi-channel unification |
| Journey Analytics | Adobe CJA, Mixpanel, Amplitude, GA4 | Product and growth teams doing journey analysis |
| Attribution | Triple Whale, Northbeam, Rockerbox | Ecommerce and paid media optimization |
Let's be honest: we've seen teams burn months evaluating CDPs when their real problem was upstream data quality. If your contact records are stale, no CDP will save your attribution. Skip the CDP evaluation if you haven't audited your marketing database first.
The Overlooked Input: Contact Data Quality
Your CDP, your attribution platform, your journey analytics - they all depend on the contact records feeding them. If your email list has high bounce rates, those contacts never produce open or click touchpoints. Your journey dataset develops systematic gaps no model can fix. This is the silent killer of attribution accuracy, and it's frustrating because it's entirely preventable.
Prospeo addresses this at the source. With 98% email accuracy and a 7-day data refresh cycle, it ensures your CRM feeds verified contacts into your CDP and attribution tools - fewer phantom touchpoints, more complete journeys, and attribution outputs you can actually trust. Teams like Snyk cut their bounce rate from 35-40% to under 5% after switching, which means dramatically more touchpoints flowing into their analytics stack.
You just read that high bounce rates create systematic gaps no attribution model can fix. Prospeo delivers 98% email accuracy with catch-all handling, spam-trap removal, and proprietary verification - at $0.01 per email. When every contact is real, every touchpoint gets recorded, and your journey analytics finally tells the truth.
Fill the gaps in your touchpoint data starting with contacts that actually exist.
FAQ
What's the difference between touchpoint data and customer journey data?
Touchpoint data is the raw event-level record - a timestamp, a channel, an action. Customer journey data is the stitched, sequenced view of those events tied to a single person over time. You need identity resolution to transform the former into the latter, which is why deterministic matching on verified email addresses produces the most reliable journeys.
How do I collect touchpoint data without violating privacy laws?
Use server-side tracking with consent signals like Google Consent Mode v2 for EEA/UK. Implement a consent management platform and rely on first-party data. Audit your tag firing sequence to ensure nothing fires before consent is granted - non-compliant pixels create GDPR joint-controller liability.
Can contact data quality affect attribution accuracy?
Absolutely. High bounce rates mean contacts never generate open or click events, creating systematic gaps in your journey dataset. Verified contact data with regular refresh cycles ensures your CRM feeds real, active contacts into downstream analytics, so attribution models work with complete data instead of guessing around holes.