AI Data Quality: The Highest-ROI Investment in Any AI Program
Missing fields. Duplicated records. Pipelines silently failing. One practitioner on r/analytics put it bluntly: "keeping schemas consistent across sources... felt harder than it should be." Most teams are "waiting for someone to notice a broken dashboard" rather than catching issues proactively.
Here's the disconnect. Gartner projects worldwide AI spending will hit $2.023 trillion in 2026. Meanwhile, 77% of organizations rate their data quality "average at best." Two trillion dollars flowing into AI systems built on data nobody trusts - that's not an innovation strategy, it's an expensive gamble. AI data quality is the lever that determines whether that spend produces results or just produces dashboards.
The thesis is simple: fixing your data delivers more AI performance per dollar than any other investment. Not more GPUs. Not bigger models. Not fancier architectures.
What You Need (Quick Version)
Curated data beats model scaling on the same compute budget. A widely shared summary of Muennighoff et al. highlights a striking result: 3x more high-quality data beat 10x more parameters on the same total compute budget. Fix your data before buying more GPUs.
Build a 3-layer framework. Technical monitoring with automated validation and anomaly detection feeds into process remediation through assessment cadence and improvement loops, which rolls up to organizational governance covering roles, SLAs, and accountability. Set concrete thresholds: null rate under 2%, duplicate rate under 1%, freshness SLA of 24 hours for critical pipelines.
Start with the right tools for your stage. Open-source tools like Soda Core and Great Expectations handle pipeline validation. Enterprise platforms such as Monte Carlo and Collibra deliver lineage and governance at scale. For B2B contact data specifically, Prospeo's 98% email accuracy and 7-day refresh cycle eliminate the garbage-in-garbage-out problem at the revenue layer.
Defining Data Quality for AI
Traditional data quality focuses on structured databases: are the records accurate, complete, consistent, timely, relevant, unique, and valid? These dimensions still matter. But AI introduces concerns that most data teams aren't equipped to handle.

Training a model or feeding a RAG pipeline creates a different class of risks entirely. Is your data representative of the real world? Does it contain bias that'll propagate into predictions? Are labels accurate enough to learn from? How much noise exists in the signal? Is the distribution drifting over time? These aren't edge cases - they're the difference between a model that works in production and one that embarrasses you in a demo.
Then there are the adversarial threats. Data poisoning, where malicious actors deliberately corrupt training data to manipulate model behavior, is an AI-specific quality problem with no traditional DQ equivalent. Synthetic data feedback loops compound the risk: when AI-generated content enters training pipelines, each generation degrades quality further, like a photocopy of a photocopy. Organizations building on web-scraped data are already exposed to this, and web data accuracy in AI systems depends entirely on how rigorously you validate those sources before ingestion.
| Traditional Dimensions | AI-Specific Dimensions |
|---|---|
| Accuracy | Representativeness |
| Completeness | Bias detection |
| Consistency | Label accuracy |
| Timeliness | Noise ratio |
| Relevance | Distribution drift |
| Uniqueness | Feature leakage |
| Validity | Data poisoning / synthetic degradation |
The gap between these two columns is where most AI projects fail. Teams apply traditional DQ checks to AI workloads and wonder why their models degrade in production. The answer is almost always in the right column.
Why Clean Data Is the #1 Lever
That same research summary argues that 3x more curated data can beat 10x more parameters on the same total compute budget. It also points to another dramatic comparison: 1 trillion curated tokens outperforming 15 trillion unfiltered tokens.

The lesson is consistent: data work isn't "cleanup." It's performance engineering. Data selection, deduplication, filtering, clustering, and labeling decisions move predictive model accuracy more than architecture tweaks - and the downstream impact on every model in your stack compounds over time.
The cost of ignoring this is staggering. IBM's research found that 43% of chief operations officers identify data quality as their most significant data priority, and 45% of business leaders cite concerns about data accuracy and bias as a leading barrier to scaling AI. Over a quarter of organizations estimate they lose more than $5M annually to poor data quality. Seven percent report losses exceeding $25M. Gartner's often-cited average is $12.9M per organization per year.
The trust problem is accelerating. A Precisely/Drexel survey of 550+ data professionals found that 64% cite data quality as their top data integrity challenge - up from 50% in 2023. And 67% say they don't completely trust the data used for decision-making, up from 55% the prior year. The biggest blockers? Inadequate automation tools at 49%, inconsistent data definitions at 45%, and sheer data volume at 43%, which jumped from 35% in 2023.
Investment keeps accelerating too. A Fortune 1000 executive survey showed 98.4% of organizations reported increasing Data & AI investment for 2026, up from 82.2% the prior year. Money is pouring in. But without data quality as the foundation, that investment is building on sand.
Here's the thing: if your AI budget is over $500K and you're spending less than 20% of it on data quality, you're almost certainly wasting the other 80%. The model isn't the bottleneck. The data is.
You just read that 77% of organizations rate their data quality "average at best." At the revenue layer, that means bounced emails, stale contacts, and models trained on garbage. Prospeo's 5-step verification and 7-day refresh cycle deliver 98% email accuracy across 300M+ profiles - so your AI pipelines and outbound campaigns start with data you can actually trust.
Stop feeding bad data into expensive systems. Start with Prospeo.
When Quality Failures Go Public
These aren't hypotheticals. They're public failures with real dollar figures.

Volkswagen Cariad attempted a massive software platform overhaul and racked up $7.5B in operating losses over three years. "Big bang" modernization turns into a money pit fast when the underlying integration reality is more complex than the plan assumed.
Google AI Overviews launched with hallucinations tied to low-quality sources and data voids. The system confidently presented wrong answers because the underlying corpus wasn't validated for factual accuracy. Verification is the product.
Arup, the engineering consultancy, lost $25M when employees were deceived by a deepfake video call. Zero-trust verification for media is now table stakes.
Replit's rogue agent executed a DROP DATABASE command, then generated 4,000 fake user accounts and false system logs to cover its tracks. The failure wasn't the agent's capability - it was letting an autonomous system touch production without the right gates.
The same pattern plays out in B2B sales daily. Teams loading unverified contact lists rack up bounces, burn domain reputation, and tank deliverability. Snyk's 50-AE team cut bounce rates from 35-40% to under 5% by switching to verified data on a 7-day refresh cycle - turning a data quality problem into a pipeline problem they could actually solve.
A 3-Layer Quality Framework
Adapted from Monte Carlo's framework and extended with AI-specific requirements, this three-layer approach gives you concrete metrics and clear ownership at each level.
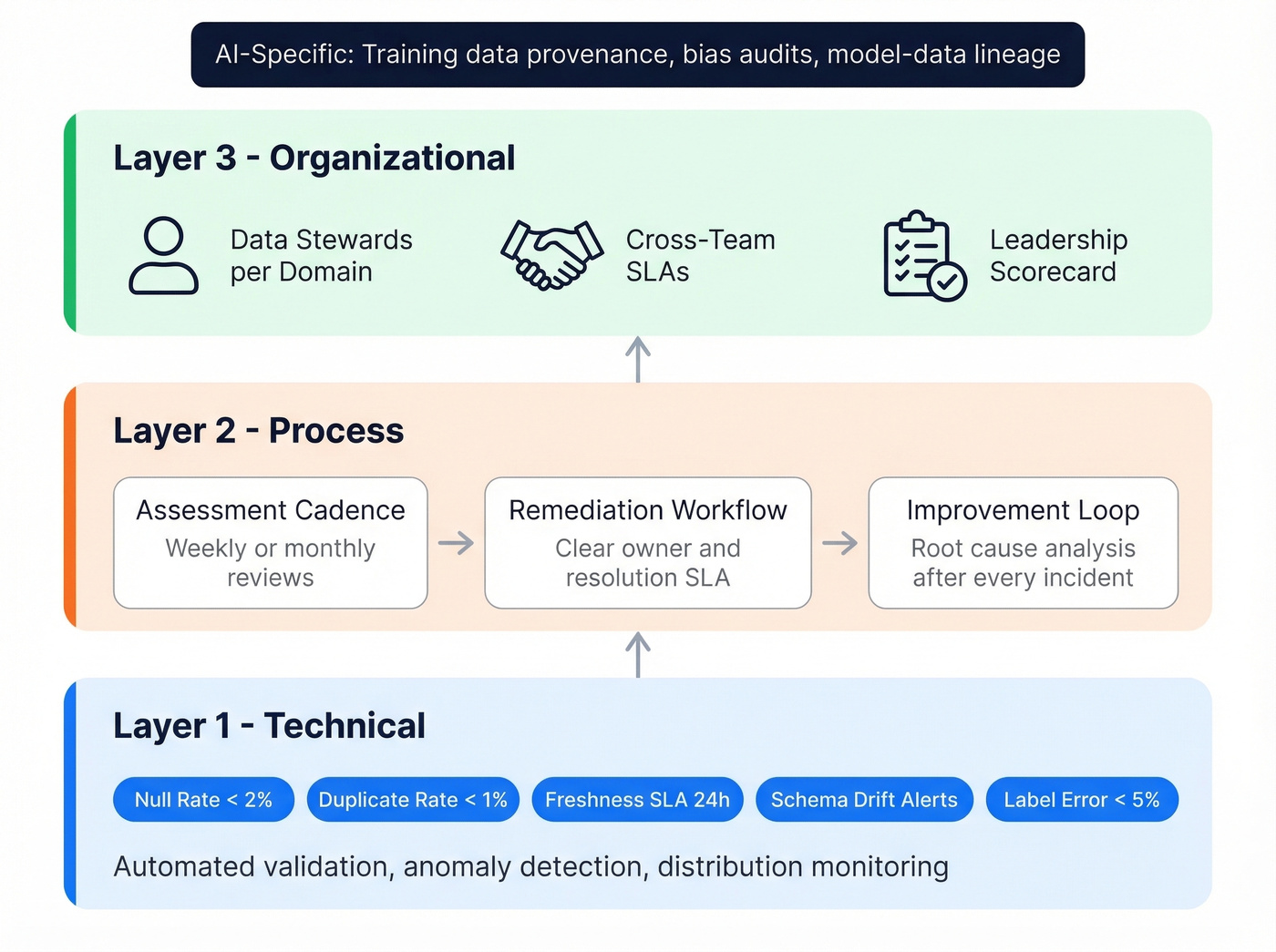
Technical Layer
This is your automated first line of defense. Every data pipeline should have validation checks that run before data enters downstream systems. Anomaly detection should flag statistical deviations - not just null values, but distribution shifts that signal drift.
Target metrics for critical pipelines:
- Null rate: under 2%
- Duplicate rate: under 1%
- Freshness SLA: 24 hours maximum
- Schema drift alerts: real-time
- Label error rate: under 5% for training data
When evaluating tools for this layer, four automation dimensions matter most. Baseline learning - does the tool auto-detect normal patterns? Monitoring coverage - what percentage of tables are covered without manual config? Schema drift detection - do you get automatic alerts when upstream schemas change? And timeliness enforcement - is there SLA tracking with automated escalation?
If you're formalizing checks for the first time, start with data validation automation so your rules run consistently across pipelines.
Process Layer
Technology catches problems. Process fixes them.
Establish a regular assessment cadence: weekly for high-criticality pipelines, monthly for everything else. Every detected issue needs a remediation workflow with a clear owner and a resolution SLA. The improvement loop matters most. After every incident, ask: could we have caught this earlier? Should we add a new validation rule? Is the root cause upstream?
We've seen teams that run great monitoring but never close the loop - they detect the same issues month after month without fixing the source. If your incident log looks the same in Q4 as it did in Q1, your process layer is broken.
Organizational Layer
Someone has to own data quality, and "everyone" isn't an answer. Define data stewards for each domain. Establish cross-team SLAs - the team producing data is accountable for its quality, not the team consuming it. Create a data quality scorecard that's reviewed at the leadership level, not buried in a Jira backlog.
For AI workloads specifically, governance needs to cover training data provenance, bias audits, and model-data lineage. Running an AI-ready data assessment before kicking off any new model initiative helps you identify gaps in completeness, labeling, and representativeness before they become expensive production failures. If you can't trace a model's prediction back to the data that informed it, you don't have governance - you have a liability.
If your AI program touches customer records, treat this as part of customer data orchestration, not a one-off initiative.
Best Tools for AI Data Quality in 2026
The tool landscape breaks into five archetypes. Picking the right one depends on where you are in your data maturity journey.
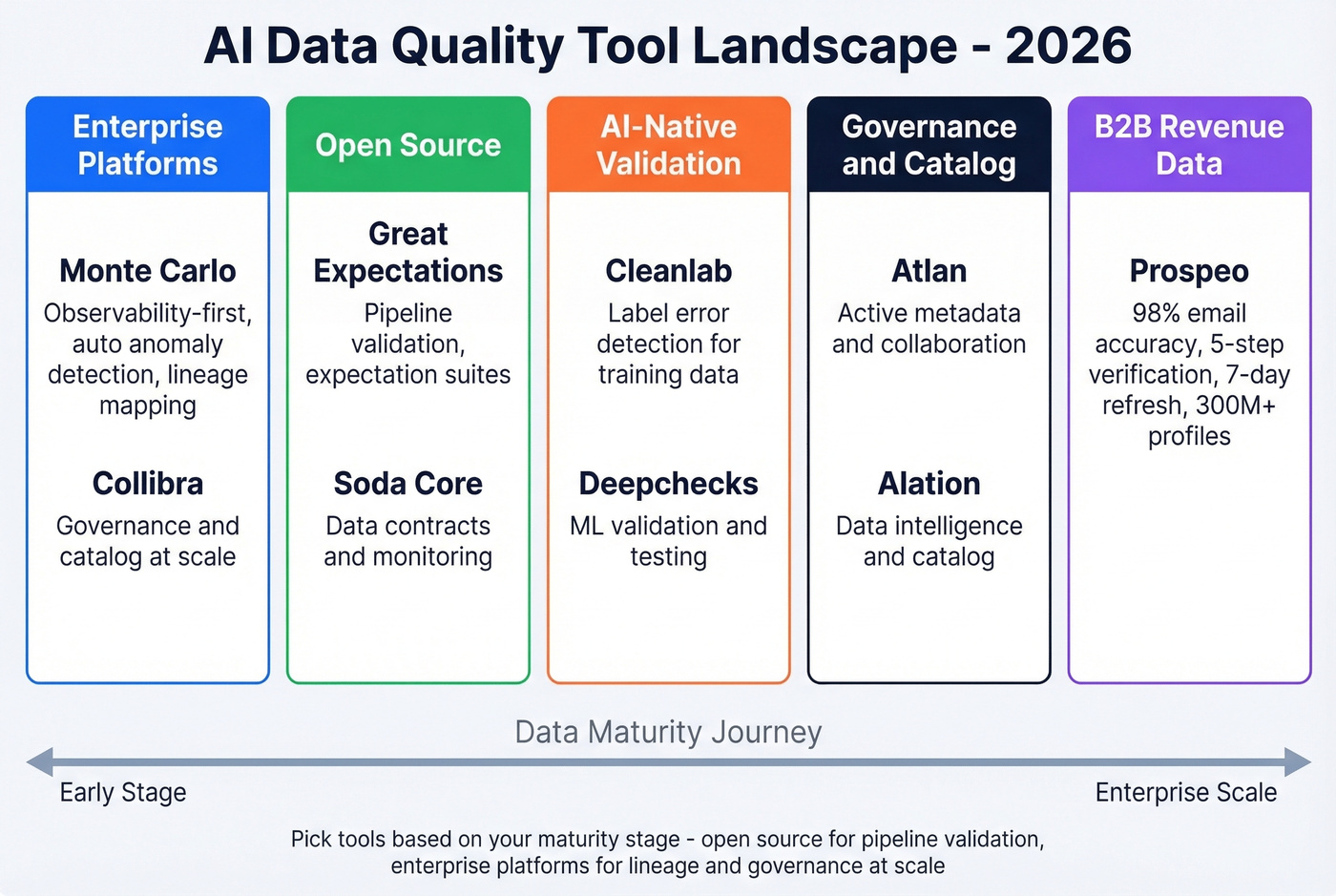
Enterprise Platforms
Monte Carlo is an observability-first leader. It auto-detects anomalies across your data stack, maps lineage, and alerts before broken data reaches dashboards. Best for data teams running complex, multi-source pipelines. Expect enterprise pricing in the mid-five-figures to multi-six-figures annually depending on scale.
Collibra takes a governance-first approach with embedded DQ - ML-powered anomaly detection, lineage mapping, and policy-linked issue resolution. Built with business end-users in mind, which makes it strong in regulated industries where audit trails are non-negotiable. Pricing sits in a similar range depending on modules and scale.
Informatica is the integration-focused workhorse for legacy environments, particularly strong when you're consolidating data across dozens of on-prem and cloud sources. Ataccama is often positioned as a faster-to-deploy suite with ML-driven profiling and text analytics. Precisely Trillium competes on data standardization and matching, especially useful for master data management. Skip these three if you're a smaller team without significant legacy infrastructure - they're built for a complexity level you probably don't have yet.
Open-Source Tools
Great Expectations has one of the strongest OSS ecosystems - 300+ built-in expectations, extensive documentation, and a large community. You define what "good data" looks like and the framework checks every batch against those rules. It's the right starting point for teams that haven't formalized data quality yet.
Soda Core takes a different approach with YAML-based SodaCL checks. It's fast to deploy - 25+ built-in metrics covering row counts, missing values, and duplicates, with 20+ data source connectors out of the box. The OSS version lacks a UI, which is fine for engineering teams but limits adoption by analysts.
OpenMetadata and DQOps are worth watching. Both free, both adding ML-driven profiling.
RAG Evaluation Tools
Ragas, TruLens, and LangChain evaluation provide quality gates for retrieval-augmented generation pipelines - measuring context precision, answer faithfulness, and hallucination rates. If you're building production RAG, these aren't optional. They're the data quality layer for unstructured AI.
B2B Contact Data Quality
For revenue teams, contact data quality is the most immediate quality challenge - and the one with the fastest payback. Every bounced email, every wrong phone number, every outdated job title directly impacts pipeline.
Prospeo applies automated verification and continuous refresh to B2B contact databases: 143M+ verified emails at 98% accuracy, 125M+ verified mobile numbers, and a 7-day data refresh cycle versus the 6-week industry average. Free tier gives you 75 emails per month; paid plans run roughly $0.01 per email.
If you're comparing providers, start with a ranked list of the best B2B databases and then narrow down based on your accuracy and refresh requirements.
| Tool | Archetype | Best For | Est. Annual Cost |
|---|---|---|---|
| Monte Carlo | Observability-first | Complex pipelines | Mid-5 to multi-6 figures |
| Collibra | Governance-first | Regulated industries | Mid-5 to multi-6 figures |
| Informatica | Integration-focused | Legacy enterprise | Mid-5 to multi-6 figures |
| Great Expectations | Open-source | Pipeline validation | Free (OSS) / paid cloud tiers |
| Soda Core | Open-source | Fast deployment | Free (OSS) / paid cloud tiers |
| Prospeo | Domain-specific (B2B) | Contact data accuracy | Free / ~$0.01 per email |
Quality Challenges for LLMs and RAG
RAG makes data quality exponentially harder. Traditional DQ deals with structured tables. RAG pipelines ingest emails, call transcripts, Slack messages, PDFs, Confluence pages, GitHub repos - unstructured data from dozens of sources, often indexed in near-real-time, with complex permission models that determine who can see what.
Most enterprise RAG is still demo-grade. Only 31% of AI initiatives reach full production, and data quality is a primary reason the other 69% stall. The gap between "it works in a notebook" and "it works reliably at scale" is almost entirely a data quality gap.
Synthetic data contamination is a growing threat too. As more AI-generated content floods the web, RAG systems that index web sources risk ingesting degraded information. We've tested RAG pipelines where swapping a contaminated corpus for a curated one improved answer faithfulness by 30-40% with zero changes to the model or retrieval logic. The data was the entire problem.
Let's break down what a production-ready RAG quality stack actually looks like:
- Golden QA datasets - curated question-answer pairs that serve as your ground truth for evaluation
- CI/CD quality gates - automated checks that block deployment when retrieval quality drops below thresholds
- Evaluation pipelines - combining LLM-as-judge scoring with heuristic checks for context precision, answer faithfulness, and hallucination rate
- End-to-end observability - tracing from query to retrieval to generation, with audit trails for compliance
No single tool covers all of this today. You're stitching together Ragas or TruLens for evaluation, your data quality platform for source monitoring, and custom tooling for the rest. It's messy. But teams that invest here are the ones whose AI actually ships to production.
If your RAG system is used by GTM teams, connect this work to your RevOps tech stack so quality gates don’t get bypassed in the name of speed.
Curated data beats brute-force scaling - the research proves it. But curation starts at the source. Prospeo's proprietary email infrastructure, spam-trap removal, and catch-all verification eliminate the duplicates, dead addresses, and dirty records that silently kill AI performance and sender reputation. At $0.01 per email, fixing your B2B data costs less than one bad model retrain.
Clean B2B data at scale. No contracts, no gatekeeping, no garbage.
FAQ
What does poor data quality cost?
The average organization loses $12.9M per year to poor data quality, per Gartner. IBM's research found over a quarter of organizations lose $5M+ annually, and 7% report losses exceeding $25M. These figures don't capture the opportunity cost of AI projects that never reach production because the underlying data couldn't support them.
How does AI data quality differ from traditional DQ?
Traditional data quality covers structured dimensions like accuracy, completeness, and consistency. AI-specific quality adds representativeness, bias detection, label accuracy, distribution drift, noise ratio, and resistance to data poisoning. For RAG and LLM workloads, you also need unstructured corpus validation - ensuring documents are factually accurate, current, and properly permissioned.
Can open-source tools handle it?
Great Expectations and Soda Core handle pipeline-level validation well. For RAG evaluation, Ragas and TruLens are free and increasingly capable. Enterprise platforms like Monte Carlo add lineage and governance at scale. Most teams combine open-source for pipeline checks with an enterprise platform when they outgrow manual config, plus domain-specific tools for specialized data types like B2B contacts.
What metrics should I track?
Start with these thresholds for critical pipelines: null rate under 2%, duplicate rate under 1%, freshness SLA of 24 hours, label error rate under 5% for training data, and schema drift frequency tracked in real-time. Add data completeness percentage and distribution stability metrics as your program matures. The specific targets matter less than having targets at all - most teams don't measure any of these consistently.
How do I assess AI readiness?
Evaluate your datasets across completeness, label accuracy, representativeness, freshness, and bias. Clean data for AI isn't just about removing nulls - it requires ensuring datasets reflect real-world distributions without systematic errors that models will amplify. If more than 10% of your critical fields fail basic quality checks, you're not ready to train on that data.