B2B Data Infrastructure: The Complete Architecture Guide for 2026
You've got a ZoomInfo subscription, a HubSpot instance, a Stripe billing dashboard, and a product analytics tool nobody on the sales team can access - and you're calling it B2B data infrastructure. Your SDRs export CSVs from one system, paste them into another, and pray the emails are still valid. That's not infrastructure. That's a subscription and a prayer.
The average enterprise runs 371 SaaS applications. Most don't talk to each other. The people connecting them - manually exporting, reformatting, re-uploading - have become what one Reddit thread perfectly called the "human API." The global data integration market is projected to grow from $15.18B to $30.27B by 2030, and the reason is simple: disconnected systems bleed money. Misaligned operations correlate with 27% longer sales cycles, 18% higher CAC, and 23% lower revenue per employee. B2B marketing has quietly turned into systems engineering, and most teams haven't caught up.
What You Need (Quick Version)
A complete B2B data stack has seven layers. Most teams only have one - a data provider - and treat it as the whole architecture.
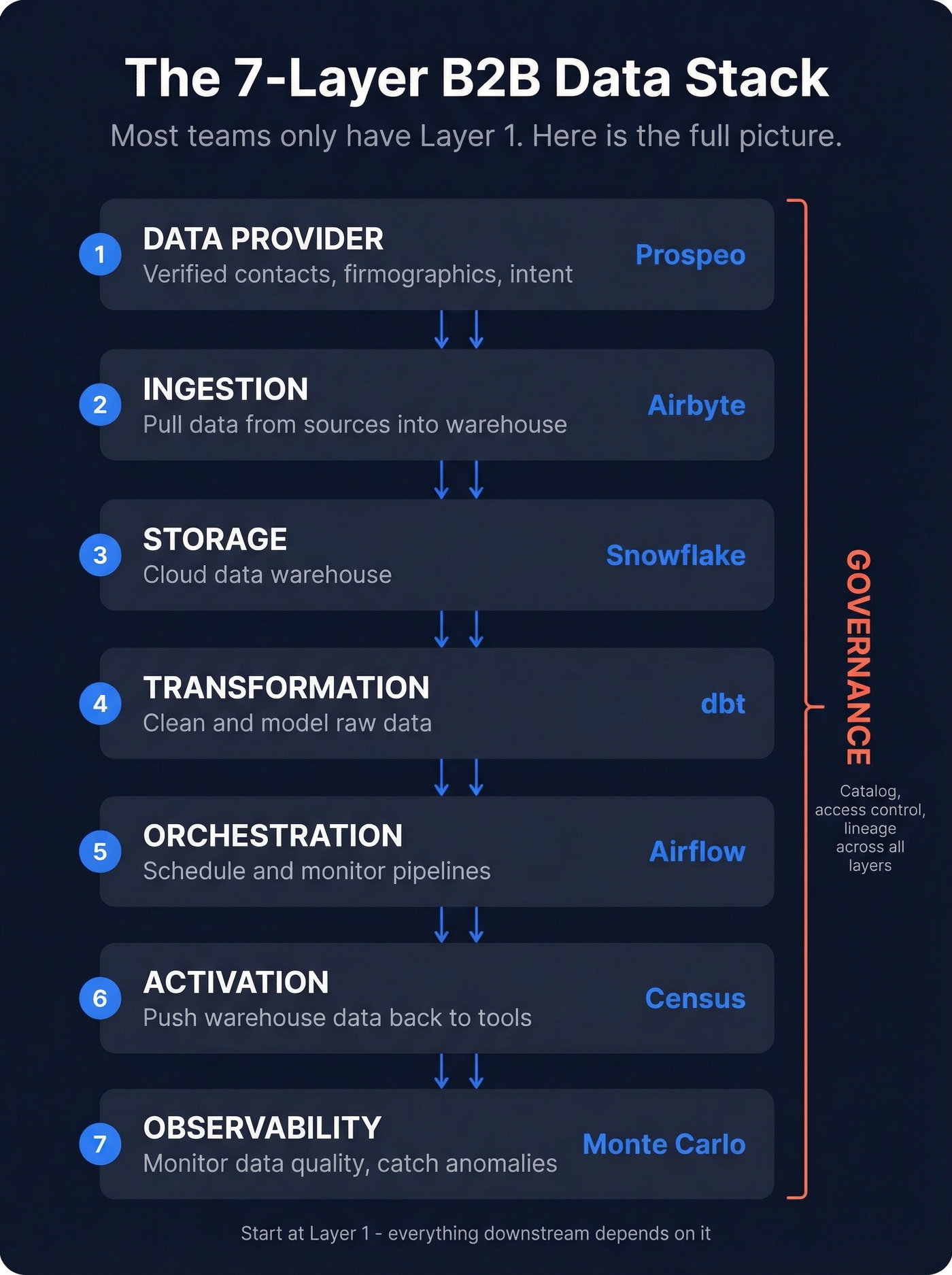
- Ingestion - Pull data from sources into your warehouse (Airbyte, open-source core, cloud from ~$100/mo)
- Storage - Cloud data warehouse (Snowflake, $500-$5,000/mo)
- Transformation - Clean and model raw data (dbt, open-source core, Cloud from ~$100/mo)
- Orchestration - Schedule and monitor pipelines (Apache Airflow, open-source)
- Activation - Push warehouse data back to operational tools (Census, free-$400+/mo)
- Governance - Catalog, access control, lineage (Atlan, typically $30K+/yr)
- Observability - Monitor data quality and catch anomalies (Monte Carlo, $2,000-$5,000+/mo)
Start with the data provider layer - everything downstream depends on it. Get verified contacts, layer in firmographics and intent signals, then connect them through a warehouse and reverse ETL. That's a functional stack you can build in weeks, not quarters.
The 7 Layers Explained
The stack went from monolithic ETL to ELT (load raw, transform later) to today's composable, cloud-native model. Each layer is a best-of-breed tool connected via APIs, with compute and storage scaling independently.
| Layer | Function | Tool | Key KPI |
|---|---|---|---|
| Ingestion | Pull from sources | Airbyte | Failed records % |
| Storage | Cloud warehouse | Snowflake | Cost per query |
| Transform | Clean + model | dbt | Schema drift events |
| Orchestration | Schedule + monitor | Airflow | Job failure rate |
| Activation | Push to SaaS tools | Census | Sync frequency |
| Governance | Catalog + access | Atlan | % assets cataloged |
| Observability | Quality monitoring | Monte Carlo | MTTD (minutes) |
The activation layer is where most teams have a gap. Reverse ETL tools like Census push enriched, modeled data from your warehouse back into Salesforce, HubSpot, Outreach - wherever your reps actually live. Without it, your warehouse is a reporting tool. With it, it's an operational engine.
One emerging concept worth tracking: chronographic data, which treats time-based events as a distinct signal layer. It isn't a standard stack component yet, but teams using event-based triggers for outreach timing are seeing measurably better results. The trajectory is clear - ETL gave way to ELT, batch is giving way to real-time, and the next wave is AI-first. Focus on the layers that close the gaps your team hits every week: the missing enrichment, the broken routing, the stale records.
The Data Provider Layer
This is where most teams start. It's also where most teams stop - buying a ZoomInfo license and calling it "infrastructure." The data provider layer feeds every downstream system, so getting it right matters more than any other decision you'll make.
Four criteria matter most when evaluating providers: data freshness, schema quality, API and bulk delivery options, and native CRM piping. The market splits into platform-first tools built for humans clicking a UI, and API-first tools built for programmatic access.
Platform-First Tools
ZoomInfo is the incumbent. 600M+ professional profiles and 135M+ verified phone numbers, with one of the deepest US-focused databases on the market. A Professional plan starts around $15,000/year, Advanced runs ~$25,000, and Elite pushes past $40,000 - with renewal uplifts of 30-50% that catch teams off guard. EMEA and APAC coverage has real gaps, and the platform's complexity often requires dedicated ops support.
Apollo is the mid-market alternative: 275M+ contacts, free tier with 1,200 credits/year, paid tiers starting around $49/user/month up to ~$79/user/month. It bundles sequencing and a dialer, which is convenient. The tradeoff is data quality - we've seen higher bounce rates from Apollo lists compared to dedicated data providers, and that's a problem if your domain reputation matters to you.
API-First Providers
Here's the thing: if you're building real data infrastructure - not just giving reps a search bar - API-first providers are the better foundation.
Prospeo delivers 300M+ profiles with 98% email accuracy and a 92% API match rate. The biggest differentiator is the 7-day refresh cycle; most providers refresh around every 6 weeks. At roughly $0.01 per email with a free tier, it's the most cost-efficient way to get verified contact data into your pipeline. Snyk's 50-person AE team cut bounce rates from 35-40% to under 5% and generated 200+ new opportunities per month after switching their contact data layer.
Coresignal positions itself as a pure data layer: 75M+ company records plus 839M employee records and 425M job records, with API and bulk dataset delivery starting at $49/month. People Data Labs goes deeper on the developer side - 3B+ person records, standardized schemas, monthly refresh, with a Pro plan starting around $98/month plus custom enterprise pricing. Both require you to build your own enrichment logic on top, which is exactly the point if you're treating data as composable infrastructure.
Your warehouse, orchestration, and activation layers are useless if the data feeding them is stale. Prospeo refreshes 300M+ profiles every 7 days - not 6 weeks - with a 92% API match rate built for programmatic infrastructure, not manual CSV exports.
Stop being the human API. Plug in data that actually stays fresh.
Waterfall Enrichment
Relying on a single data source typically leaves 40-60% of qualified prospects unreachable. Contact data decays 25-30% annually. No single provider can keep up.
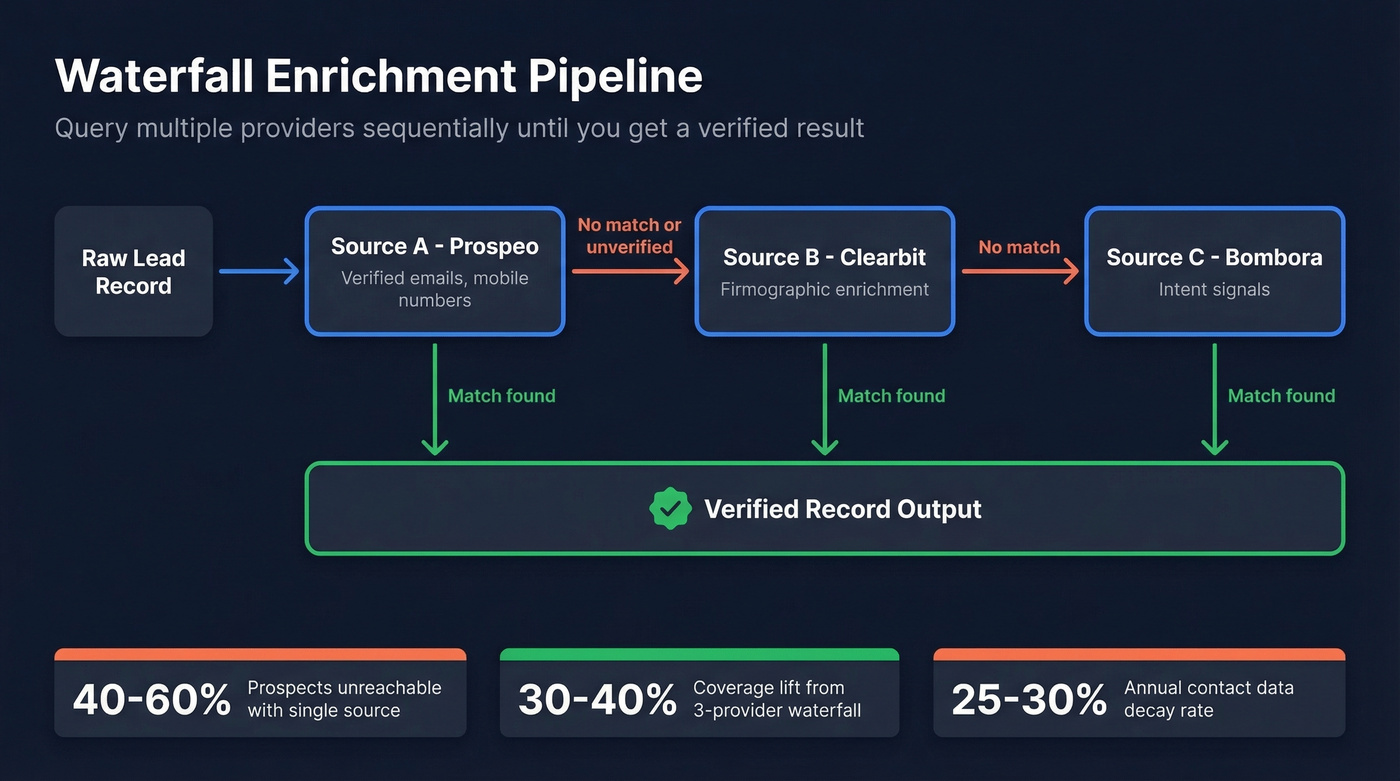
Waterfall enrichment solves this by querying multiple providers sequentially until you get a verified result. Your pipeline checks Source A first. If it returns nothing or an unverified result, it falls through to Source B, then Source C. The output is a single verified record, regardless of which provider delivered it.
You don't need 17 providers. You need three and a pipeline connecting them. Prospeo for verified emails and mobile numbers, Clearbit for firmographic enrichment, Bombora for intent signals. Wire them through Clay or a custom workflow in your warehouse, and you've got coverage no single vendor matches alone. We've tested this exact configuration across multiple client engagements, and the coverage lift from single-provider to three-provider waterfall is consistently in the 30-40% range.
Snyk's 50 AEs cut bounce rates from 35-40% to under 5% and generated 200+ opportunities per month - because they fixed the data provider layer first. At $0.01 per email with 98% accuracy, Prospeo is the most cost-efficient foundation for any B2B data stack.
Every layer downstream depends on this one. Get it right for $0.01 per lead.
Build vs Buy Your Data Stack
A survey of 102 data professionals gives us real numbers. 61% take a buy-first, build-selectively approach. 71% cite faster time-to-value for buying; 64% cite control and customization as the reason to build. And 42% cite compliance requirements as a reason to build - a number that'll only grow as state privacy laws multiply.
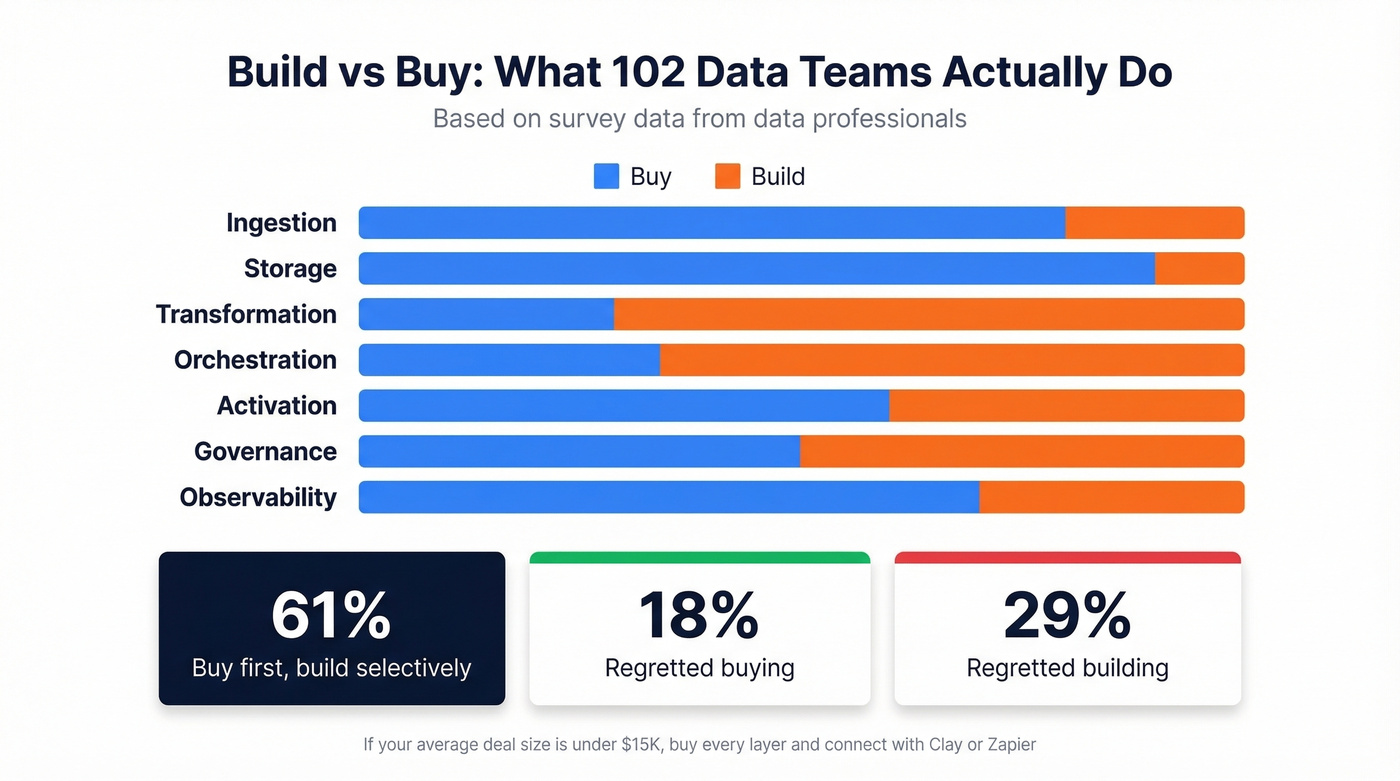
Teams are most likely to build in the transformation and orchestration layers, where custom business logic lives. They buy storage and ingestion, where commodity infrastructure does the job. Your dbt models encode how your business thinks about accounts and contacts. Snowflake just stores bytes.
The regret data is telling: 29% of teams regretted a build decision within a year, versus only 18% who regretted buying. We've seen this pattern repeatedly - a team spends three months building a custom enrichment pipeline and ends up with something slower and less accurate than a $149/month Clay subscription.
Let's be honest: if your average deal size is under $15K, you almost certainly don't need to build any custom data pipelines. Buy every layer, connect them with Clay or Zapier, and spend your engineering hours on product. The "build it ourselves" instinct has a 29% regret rate for a reason.
What It Actually Costs
A mid-market B2B data stack runs $3,000-$8,000/month in tooling, plus 1-2 dedicated FTEs.
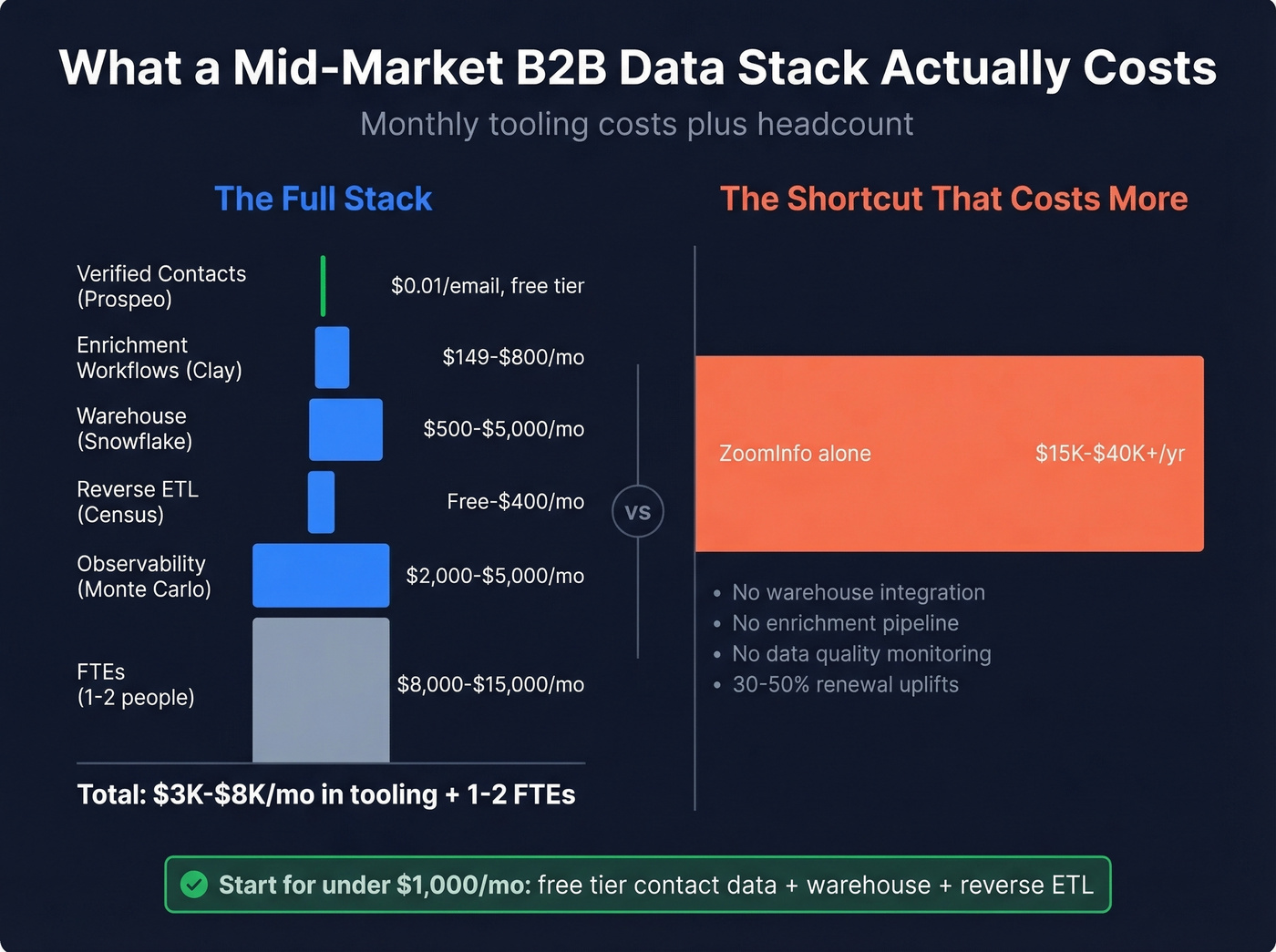
| Component | Example | Cost |
|---|---|---|
| Contacts (verified) | Prospeo | ~$0.01/email, free tier |
| Contacts (enterprise) | ZoomInfo | $15K-$40K+/yr |
| Contacts (mid-market) | Apollo | Free-$79/user/mo |
| Enrichment workflows | Clay | $149-$800/mo |
| Warehouse | Snowflake | $500-$5,000/mo |
| Reverse ETL | Census | Free-$400+/mo |
| Observability | Monte Carlo | $2,000-$5,000+/mo |
| Total (mid-market) | $3K-$8K/mo + 1-2 FTEs |
Compare that to "just buying ZoomInfo" at $15K-$40K/year. The infrastructure investment is larger upfront, but the ROI compounds - bad routing, duplicate records, bounced emails, and missed signals bleed revenue every quarter. A proper stack gives you data you can trust, routed to the right system, at the right time.
The cost-efficient path: start with a verified contact data provider on the free tier, add a warehouse, and connect them with reverse ETL. You can have a functional stack for under $1,000/month before you need enterprise-grade observability or governance. Skip observability tools entirely until your pipeline handles 50K+ records monthly - before that threshold, manual spot-checks and dbt tests catch most issues.
Data Management and Compliance
Privacy isn't a checkbox. It's an infrastructure layer that touches every other layer in the stack.
CCPA applies if you hit $25M in revenue, process data on 100,000+ California consumers, or derive 50% of revenue from selling/sharing personal information. Getting B2B data management right means baking compliance into every pipeline from the start, not bolting it on after a regulator comes knocking.
What you need built in: DSAR workflows with intake, verification, and routing across systems. Global Privacy Control signal handling - Oregon now requires it. Vendor contract taxonomy distinguishing service providers from third parties. Retention schedules mapping data category to system to owner to deletion method.
Data ownership is one of the thorniest issues teams face when multiple vendors touch the same records. Your contracts should explicitly define who owns enriched data, who can retain it after termination, and what happens to derived datasets. Without clear ownership clauses, you risk vendor lock-in and compliance exposure simultaneously.
Three new comprehensive state privacy laws took effect January 1, 2026: Indiana, Kentucky, and Rhode Island. The compliance surface expands every year. When evaluating data providers, look for GDPR compliance, opt-out enforcement, and available DPAs - that's the baseline for any provider feeding your infrastructure. For a deeper breakdown of frameworks, fines, and implementation, see our guide to B2B compliance.
FAQ
What is B2B data infrastructure?
It's the complete system - ingestion, storage, transformation, orchestration, activation, governance, and observability - that feeds your sales and marketing tools with accurate, fresh, compliant data. Think of it as the pipeline connecting raw data sources to the operational systems where your team works, with quality monitoring built in.
How much does a B2B data stack cost?
A mid-market stack runs $3,000-$8,000/month in tooling plus 1-2 dedicated FTEs. You can start smaller: a verified data provider on a free tier, a warehouse, and a reverse ETL tool gets you a functional foundation for under $1,000/month.
Should I build or buy my data infrastructure?
Buy first, build selectively - 61% of data teams take this approach. Buy commodity layers like storage and ingestion. Build transformation and orchestration where custom business logic lives. 29% of teams regret building within a year versus 18% who regret buying.
How does waterfall enrichment improve data coverage?
Waterfall enrichment queries multiple providers sequentially - if Source A returns nothing verified, the request falls to Source B, then Source C. This typically lifts reachable prospect coverage from 40-60% to 85%+ without manual effort. Three providers wired through Clay or a warehouse workflow is the sweet spot.