What Is a B2B Identity Graph - and Why Most Explainers Get It Wrong?
Most identity graph explainers are B2C content with a B2B label slapped on top. They talk about device IDs, cookie pools, and cross-screen tracking - none of which matter when you're trying to figure out which six people at a target account actually influence the deal. A B2B identity graph solves a structurally different problem, and the distinction matters more in 2026 than it ever has.
Here's the short version: this data structure maps people to accounts and buying groups, not devices to individuals. With [54% of mobile impressions](https://www.comscore.com/ger/Insights/Blog/ID-Free-Impressions-are-the-New-Normal) and 36% of desktop impressions now lacking identifiers and 20 US states enforcing comprehensive privacy laws, first-party identity infrastructure isn't optional anymore. Most teams should buy, not build. And no identity graph matters if the contact data it resolves is stale - industry estimates put annual B2B data decay at 30-40%.
What Is a B2B Identity Graph?
An identity graph is a data structure where nodes represent identifiers - email addresses, phone numbers, company domains, user IDs - and edges represent relationships between them. It's a map connecting every signal you have about a person or organization into a single, queryable structure.
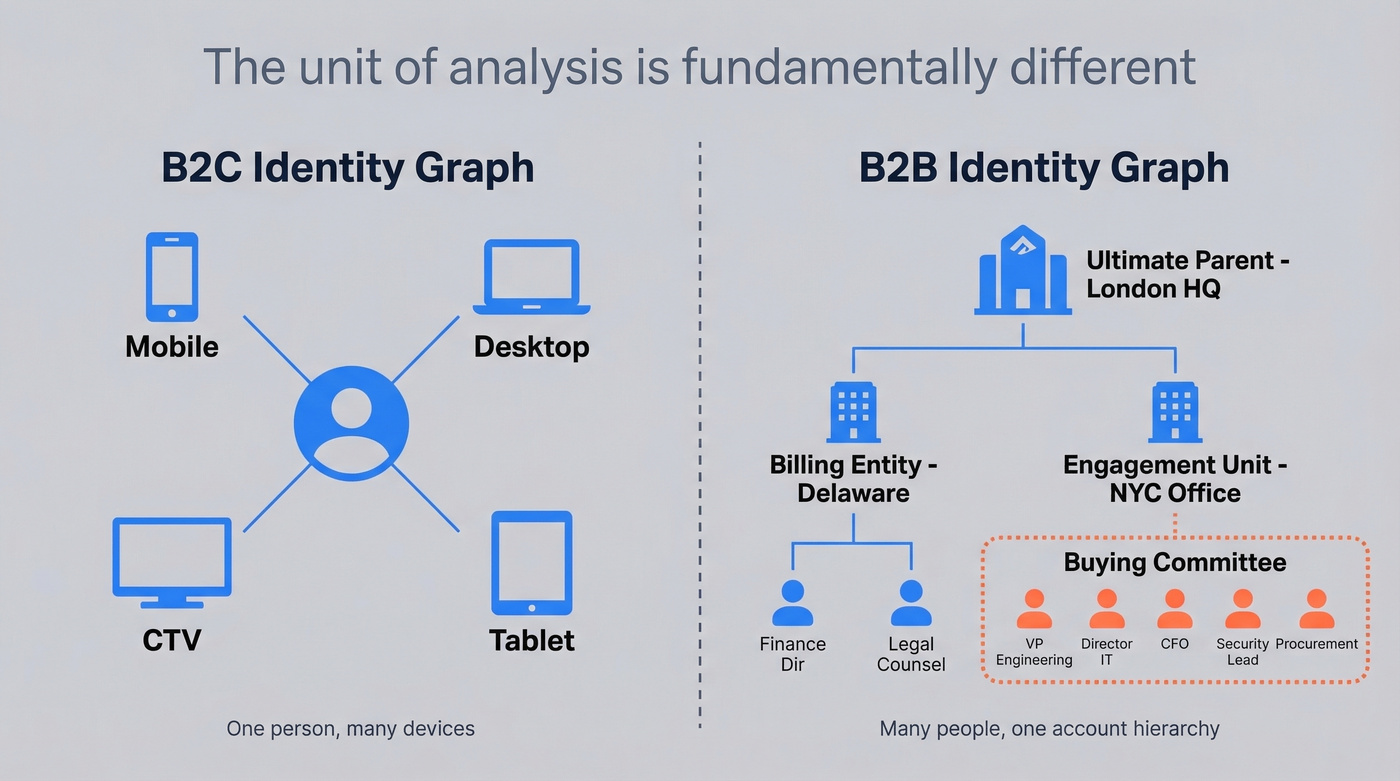
The B2B version looks fundamentally different from its B2C cousin. A B2C identity graph stitches devices to a single consumer: your phone, your laptop, your CTV, all linked to one profile. The B2B variant stitches people to accounts, buying groups, and organizational hierarchies. The unit of analysis isn't "one person across screens." It's seven people across three departments at a company with a parent entity in London and a billing entity in Delaware.
That account hierarchy - ultimate parent to billing entity to engagement unit - is what makes B2B identity resolution genuinely hard. You're not just deduplicating records. You're modeling organizational structure and grouping individuals into buying committees that shift over time.
Why It Matters in 2026
The signals B2B teams relied on are disappearing. Comscore data shows 54% of mobile impressions and 36% of desktop impressions now lack identifiers entirely, while roughly 35% of US browsers block third-party cookies by default.
Regulation is accelerating the shift. Twenty US states now enforce comprehensive privacy laws. The DOJ's Bulk Data Rule took effect in April 2025, with additional requirements rolling in later that year, and Maryland's Online Data Privacy Act prohibits selling sensitive personal data regardless of consent.
The market reflects the urgency. Estimates put it at $1.5-2.5B depending on the source, projected to hit $5.8-6.8B by the early 2030s at roughly 11-12.5% CAGR. WPP acquired InfoSum in April 2025; Publicis bought Lotame in March 2025. The infrastructure layer is consolidating because everyone realizes first-party identity is the foundation everything else sits on.
How Identity Graphs Actually Work
Two matching approaches work in tandem. Deterministic matching uses exact identifiers - an email address, a phone number, a company domain - to link records with high confidence. Probabilistic matching fills the gaps using statistical models that link records when data is messy or incomplete. Every serious identity graph uses both and assigns confidence scores to each link.
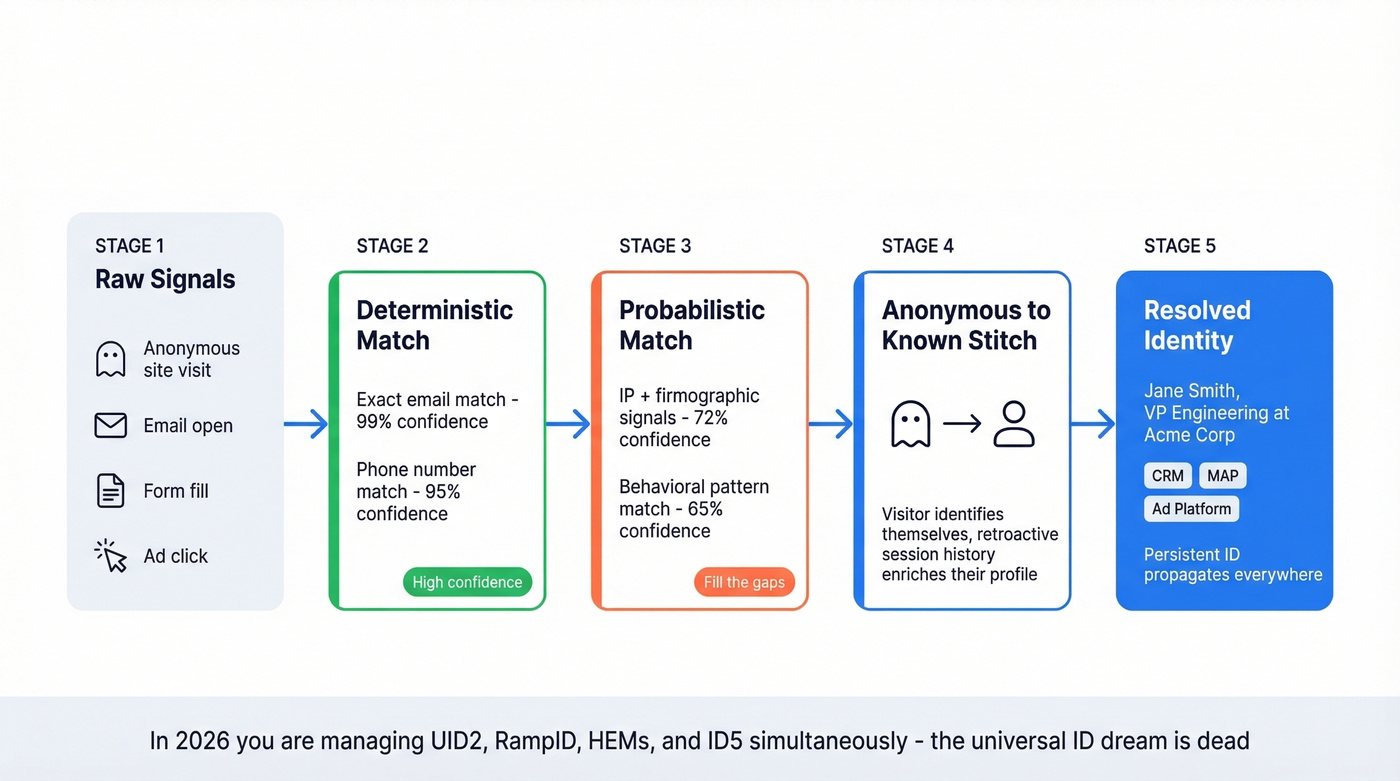
Anonymous-to-known stitching is where the graph earns its keep. It connects an anonymous website visit to a known contact once they eventually identify themselves, and that anonymous session retroactively enriches the contact's engagement history. Persistent IDs then propagate across your CRM, MAP, and ad platforms so the full picture follows the person everywhere.
Here's the part most explainers skip: the "universal ID" dream is dead. In 2026, you're managing UID2, RampID, HEMs, and ID5 simultaneously with limited interoperability between them. Plan accordingly.
An identity graph built on decaying records is just an expensive org chart full of dead emails. Prospeo's 7-day refresh cycle and 98% email accuracy ensure the contact layer of your graph stays current - not 30-40% stale like the industry average.
Stop resolving identities to bounced emails. Start with data that's actually verified.
People Graph vs. Account Graph
Understanding the relationship between these two layers is essential. The people graph maps individual professionals - their job titles, email addresses, phone numbers, and engagement signals. The account graph maps organizational entities, subsidiaries, and firmographic attributes.
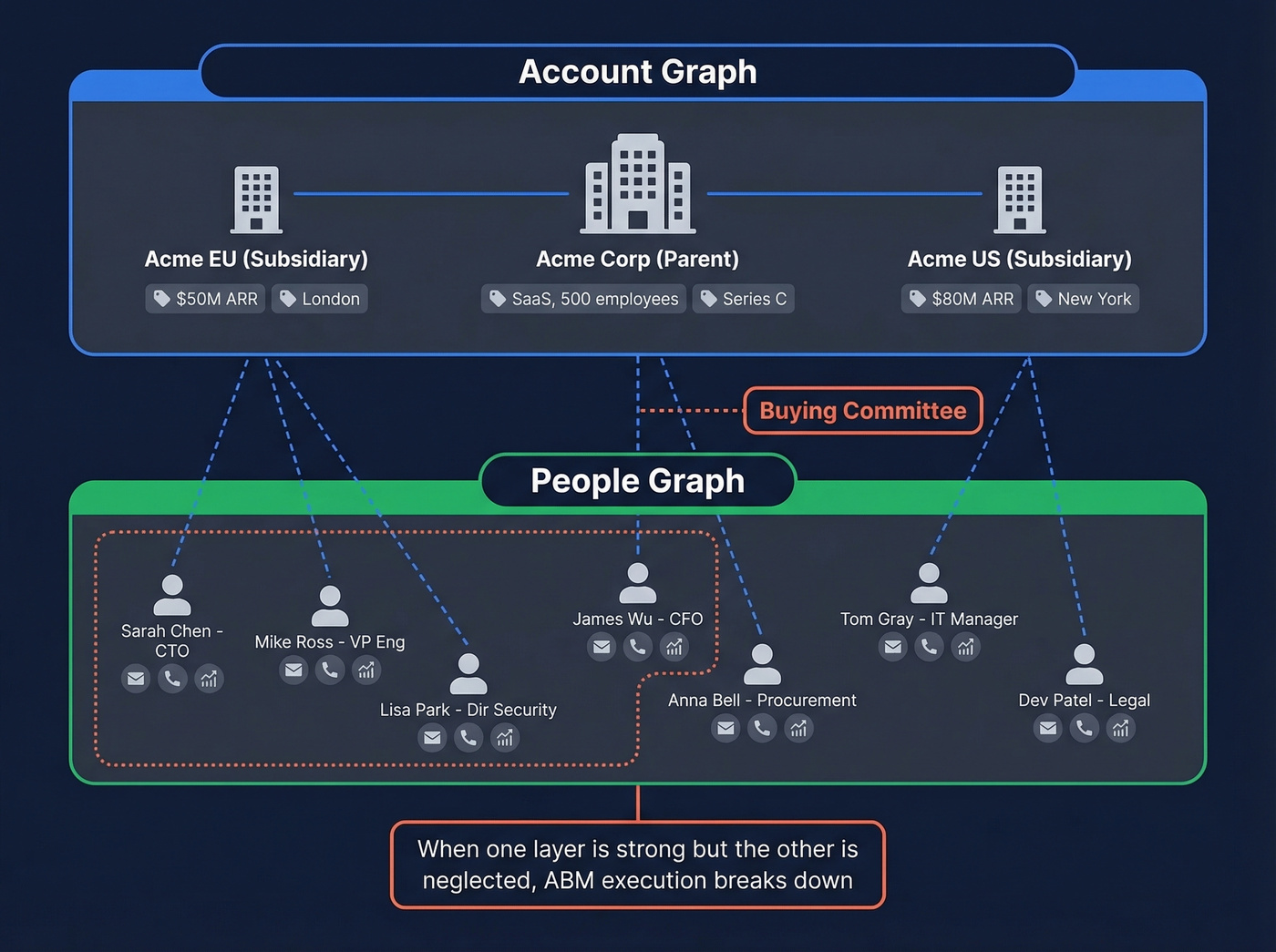
A complete B2B identity graph weaves both layers together, linking the right people to the right accounts so your sales team targets actual buying committees rather than disconnected contact lists. When we've seen teams struggle with ABM execution, it's almost always because one layer is strong and the other is neglected. You can have the best account targeting in the world, but if you can't identify the five people who actually sign off on the purchase, you're sending emails into the void.
Build vs. Buy
Building in-house gives you full control and no vendor lock-in. The reality is painful. Snowpark, in real-world implementations, has had gaps versus Spark-style stacks: no GraphX/GraphFrames equivalent for graph processing, and ML workflows often require workarounds like converting Snowpark DataFrames to Pandas for training, persisting classifiers into tables, and wiring Python stored procedures together. It feels like duct tape - because it is. Budget $150K+ in engineering time over 2-4 months, minimum.
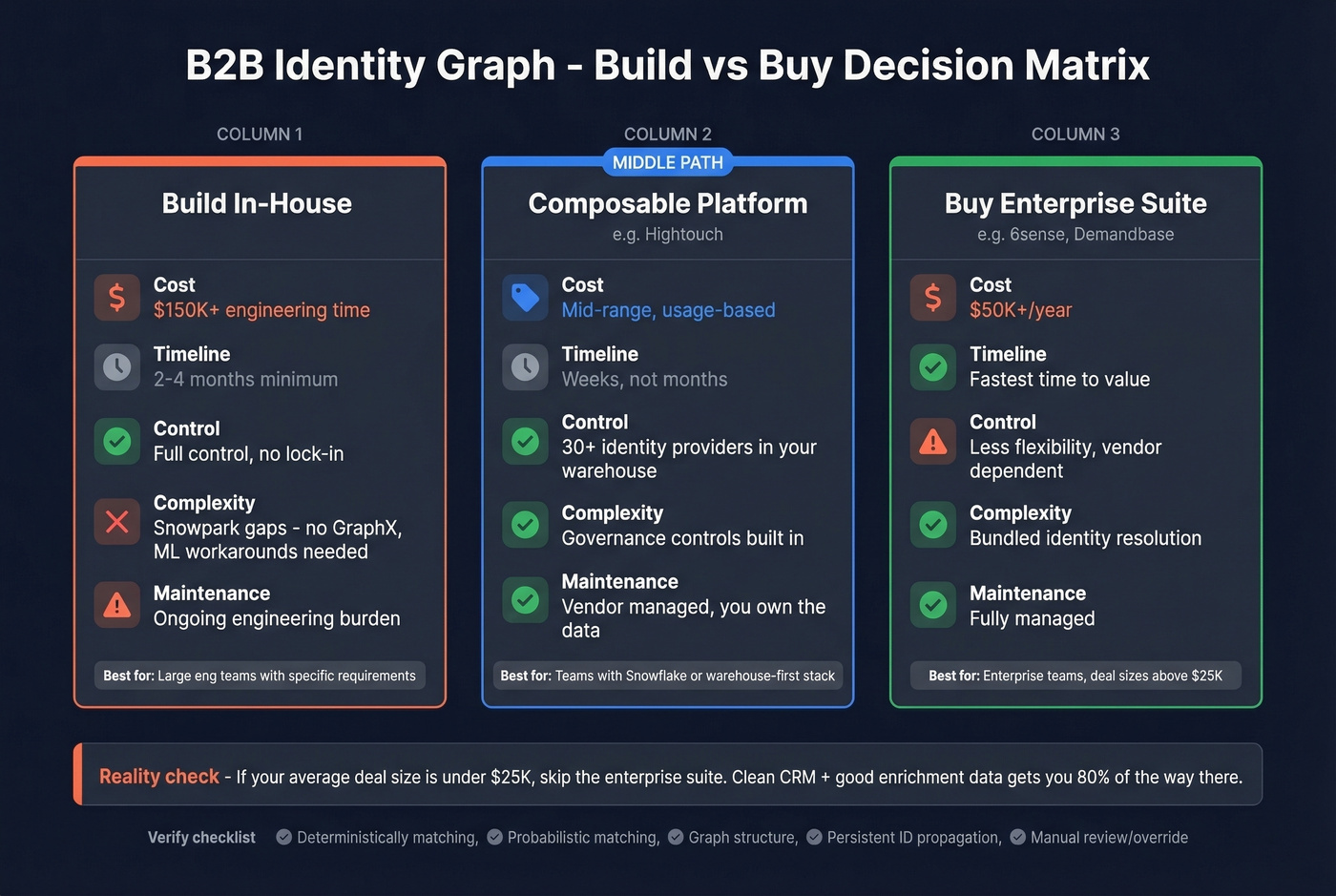
Composable platforms like Hightouch offer a middle path: combining 30+ identity providers directly in Snowflake with governance controls baked in.
Buying a solution means enterprise ABM suites like 6sense or Demandbase, which bundle identity resolution at $50K+/year. Faster time-to-value, less flexibility. Before signing, verify five non-negotiable capabilities per MarTech's warehouse-native framework: deterministic matching, probabilistic matching, graph structure, persistent ID propagation, and manual review/override.
Let's be honest: if your average deal size is under $25K, you probably don't need a $50K+ identity platform. A clean CRM, good enrichment data, and disciplined account tagging will get you 80% of the way there. Skip the enterprise suite and invest in data quality instead.
Where Vendors Mislead
Vendors love quoting 90%+ match rates. Bombora claims 90%+ resolving "almost every impression" to account and persona. Intentsify cites 1.1T monthly intent signals and 382M contact records - and their own product page lists both "203M IP addresses" and "4.6B tracked IP addresses," a discrepancy that shows how loosely vendors define their metrics. We couldn't find a single credible third-party benchmark study validating these numbers.
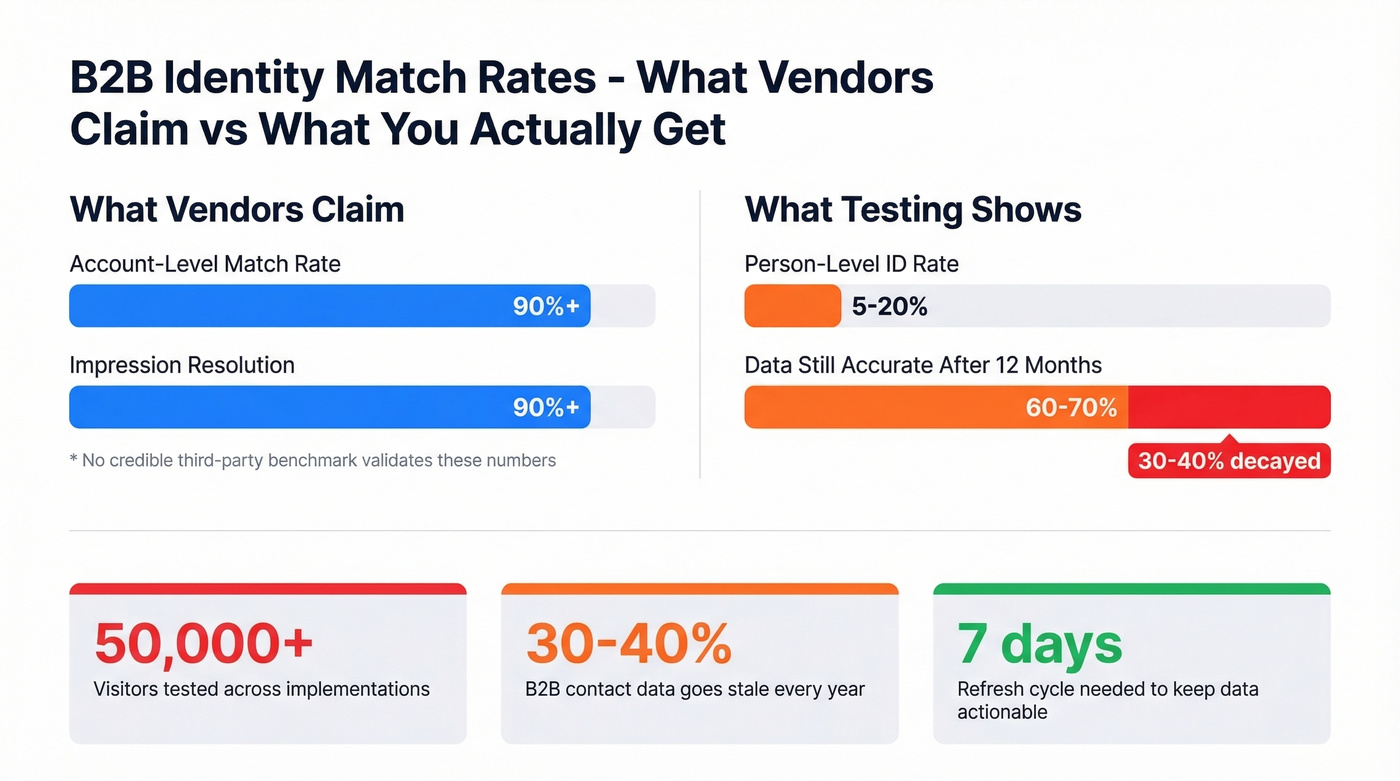
Person-level identification rates in testing across 50,000+ visitors run about 5-20%. In practice, that's generous for most mid-market implementations.
Data decay compounds the problem. When 30-40% of contact data goes stale annually, an identity graph built on decaying records is an expensive org chart full of dead emails. On r/b2bmarketing, practitioners openly question whether visitor identification without cookies is even legal - and consistently point to accuracy gaps between what vendors promise and what actually holds up in outreach.
Compliance posture matters more than coverage. Under GDPR, CCPA, and the expanding patchwork of state laws, how a vendor sources identity data is as important as how much they have.
The Verification Gap
Your ABM platform says 500 accounts are in-market. The identity graph resolved buying committees across all of them. Your SDRs start outreach.
Then emails bounce, dials go to voicemail, and half the contacts have changed jobs since the data was last refreshed. The graph worked. The last mile failed. This is the part that drives us crazy - teams spend six figures on identity infrastructure and then lose deals because the phone number is wrong.
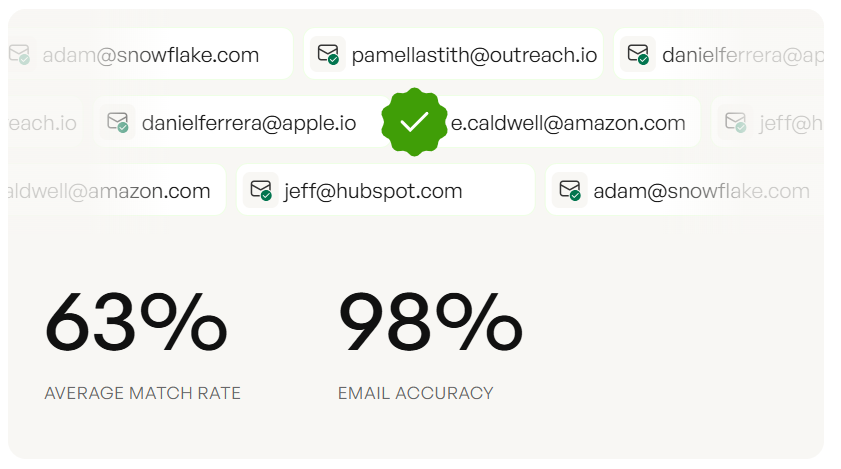
Prospeo closes this gap. With 300M+ professional profiles, 98% email accuracy, and a 7-day data refresh cycle, it's the verification layer that makes identity resolution actionable. Teams upload resolved contact lists, verify in bulk, and push clean data to their sequencer. The graph tells you who to reach. Verified data makes sure you actually can.
If you're evaluating providers, start with accuracy-first comparisons like the best B2B databases and verified contact databases lists.
You don't need a $50K identity platform to connect the right people to the right accounts. Prospeo gives you 300M+ profiles, 30+ filters including buyer intent and org hierarchy, and verified emails at $0.01 each - the people graph layer most enterprise suites overcharge for.
Build your people-to-account map with data you can actually trust.
FAQ
What's the difference between an identity graph and identity resolution?
An identity graph is the data structure - nodes connected by edges representing relationships between identifiers. Identity resolution is the process of building and maintaining that graph through matching, merging, and deduplication. The graph is the output; resolution is the engine that creates it.
Can you build a B2B identity graph in Snowflake?
Yes, but expect significant complexity. Snowpark lacks a Spark-style graph processing library, and ML workflows rely on Python workarounds. Composable platforms like Hightouch simplify this considerably. Budget $150K+ and 2-4 months minimum for a custom build.
How accurate are vendor match rates?
Vendors claim 90%+, but those are account-level numbers. Person-level identification rates run about 5-20% across 50,000+ visitor tests. Even accurate matches decay - 30-40% of B2B contact data goes stale annually. Always verify resolved lists with a tool that refreshes data weekly before activating outreach.
Is using an identity graph legal?
Deterministic matching on consented first-party data is generally safe across jurisdictions. Probabilistic matching on third-party data requires careful compliance review, especially under Maryland's Online Data Privacy Act and the DOJ's Bulk Data Rule. Always audit how your vendor sources data - the cheapest provider is often the riskiest one.