BANT Score: The Scoring Model Every Guide Forgets to Include
Sales teams waste up to half their time chasing leads that never close. The BANT framework has been around since the 1950s, but almost nobody has turned it into an actual scoring model - a rubric with points, thresholds, and something you can implement today.
Most teams use BANT informally: four questions, a gut feel, and no numeric output. That doesn't scale. It doesn't transfer between reps. And it gives RevOps nothing to measure. A BANT score turns that gut feel into a 0-100 number. Here's the model.
Quick Version
BANT scoring assigns 0-25 points per dimension - Budget, Authority, Need, and Timeline - for a 0-100 total. 75+ means a hot lead ready for sales. 50-74 is warm and worth nurturing. Below 50, deprioritize or disqualify. Below you'll find the full rubric with point breakdowns, implementation steps across three budget levels, and a framework comparison for choosing the right approach.
What Is a BANT Score?
The BANT framework is the methodology - four questions about Budget, Authority, Need, and Timeline that IBM developed to qualify leads. The score is the numeric output: a 0-100 number that tells you exactly how qualified a lead is and what to do next.
A 2023 Gartner Digital Markets survey found over 52% of salespeople still find BANT reliable for qualifying prospects. But most run it without a scoring system. That's like forecasting pipeline by vibes.
The 0-100 Lead Scoring Rubric
Each dimension gets 0-25 points. Total possible: 100.
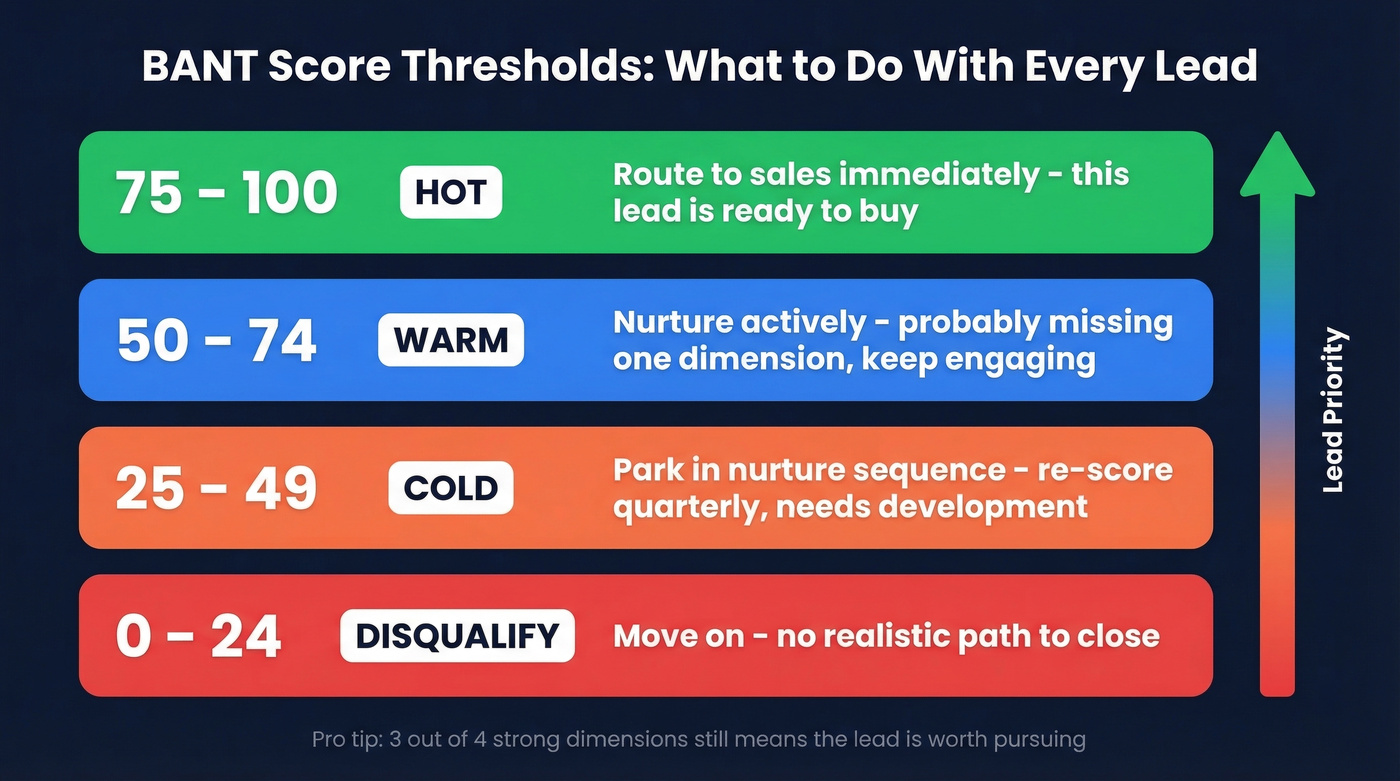
- 75-100 (Hot): Route to sales immediately. This lead has budget, access to a decision-maker, a real problem, and urgency.
- 50-74 (Warm): Worth nurturing. Probably missing one dimension - usually timeline or confirmed budget.
- 25-49 (Cold): Needs significant development. Park in a nurture sequence and re-score quarterly.
- Below 25 (Disqualify): Move on.
The 3-out-of-4 heuristic works well: if a lead scores strong on three dimensions but weak on one, they're still worth pursuing. Missing both Budget and Authority? That's a disqualifier.
Budget (0-25 Points)
| Points | Criteria |
|---|---|
| 25 | Confirmed budget allocated for this type of solution |
| 15 | Budget exists but isn't yet allocated; prospect can influence spend |
| 5 | No current budget, but prospect acknowledges willingness to explore |
| 0 | No budget, no willingness, or price is a dealbreaker |

The discovery question that matters most: "Has your team set aside budget for solving this, or would this need to go through a new approval process?"
A prospect who scores 0 on Budget but 25 on Need and 25 on Timeline isn't dead - they're one internal champion away from finding the dollars. Don't let a low Budget score kill a deal that's strong everywhere else.
Authority (0-25 Points)
"Who else would need to sign off before this moves forward?"
Start every Authority assessment with that question. The answer tells you more than any job title. Modern B2B buying often involves around seven stakeholders, so "Authority" isn't about reaching the CEO - it's about mapping the buying committee across three roles: decision-maker, influencer, and budget holder.
| Points | Criteria |
|---|---|
| 25 | Direct contact with the decision-maker who signs off |
| 15 | Talking to an influencer or budget holder who can champion internally |
| 5 | Contact is an end-user or researcher with no buying power |
| 0 | Can't identify anyone in the buying process |
If you're talking to at least one of those three roles, you've got something to work with.
Need (0-25 Points)
Need is the dimension that separates real pipeline from wishful thinking. I've watched reps score a lead as "high need" because the prospect said "we're always looking to improve." That's a 5 at best. A prospect who can describe their pain in specific terms - lost revenue, wasted hours, compliance risk - scores 25.
| Points | Criteria |
|---|---|
| 25 | Active, acknowledged pain that your solution directly solves |
| 15 | Latent need - prospect recognizes the problem but isn't actively solving it |
| 5 | Vague interest, no specific pain articulated |
| 0 | No fit between their problem and your solution |
The question that cuts through vagueness: "What happens if you don't solve this problem in the next six months?"
Timeline (0-25 Points)
Here's a scenario we see constantly: your rep just had a great discovery call. The prospect loves the product, has budget, and the VP is on the next call. But when asked about timing, they say "sometime this year." That's a 5. Compare that to "we need to decide before our contract with [competitor] renews in March" - that's a 25, and it changes everything about how you prioritize the deal.
| Points | Criteria |
|---|---|
| 25 | Active buying process, decision expected this quarter |
| 15 | Planning to decide within 6 months; specific trigger event identified |
| 5 | "Sometime this year" or "we're exploring" |
| 0 | No timeline, no urgency, purely educational |
Ask: "Is there a specific event - a contract renewal, a board meeting, a product launch - driving the timing on this?"
Weighting by Sales Motion
The default 25/25/25/25 split works for most teams, but your sales motion should influence how you weight each dimension.

For PLG or inbound SaaS with shorter cycles, Need and Timeline deserve more weight - these leads self-selected, so budget and authority are often already implied. Bump Need and Timeline to 30 each, drop Budget and Authority to 20. For enterprise outbound where you're selling six-figure contracts into buying committees, Authority and Budget matter more. A VP who loves your product but can't get procurement to move is a warm lead at best. Weight Authority and Budget at 30, Need and Timeline at 20.
Budget is the most overweighted dimension in BANT. Procurement finds money for urgent problems. If Need and Timeline are both 25s, the budget conversation often resolves itself. Stop killing deals over a dimension that can be solved once the problem is real and the timing is tight.
A perfect BANT score means nothing if you can't reach the decision-maker. Prospeo gives you 98% verified emails and 125M+ direct dials so your 75+ leads get a call within minutes, not days.
Stop scoring leads you can't actually contact.
BANT Metrics and KPIs Worth Tracking
Structured qualification isn't just a process improvement - it's a conversion multiplier. SQLs convert to opportunities at 20-30% compared to MQLs at 5-15%. The average MQL-to-SQL conversion rate sits around 13%, but top performers using behavioral scoring and fast follow-ups reach 40%.

Speed compounds the advantage. Following up within the first hour yields a 53% conversion rate vs 17% after 24 hours. Responding within five minutes makes you 21x more likely to convert compared to waiting 30 minutes. A numeric score gives your team the confidence to prioritize instantly - hot leads get called now, warm leads get sequenced, cold leads get parked.
Companies implementing BANT see a 59% increase in conversion rates. That's the gap between "we eyeball it" and "we score it."
Track these three metrics to close the feedback loop: score-to-opportunity rate, average score at close, and time-in-stage by tier. They'll tell you whether your rubric is calibrated correctly or whether you need to adjust thresholds.
Industry MQL-to-SQL Benchmarks
| Industry | MQL-to-SQL Rate |
|---|---|
| Consumer Electronics | 21% |
| FinTech | 19% |
| Automotive | 18% |
| Healthcare | 13% |
| Oil & Gas | 12% |
How to Implement BANT Scoring
Three paths. The right one depends on your team size and budget.
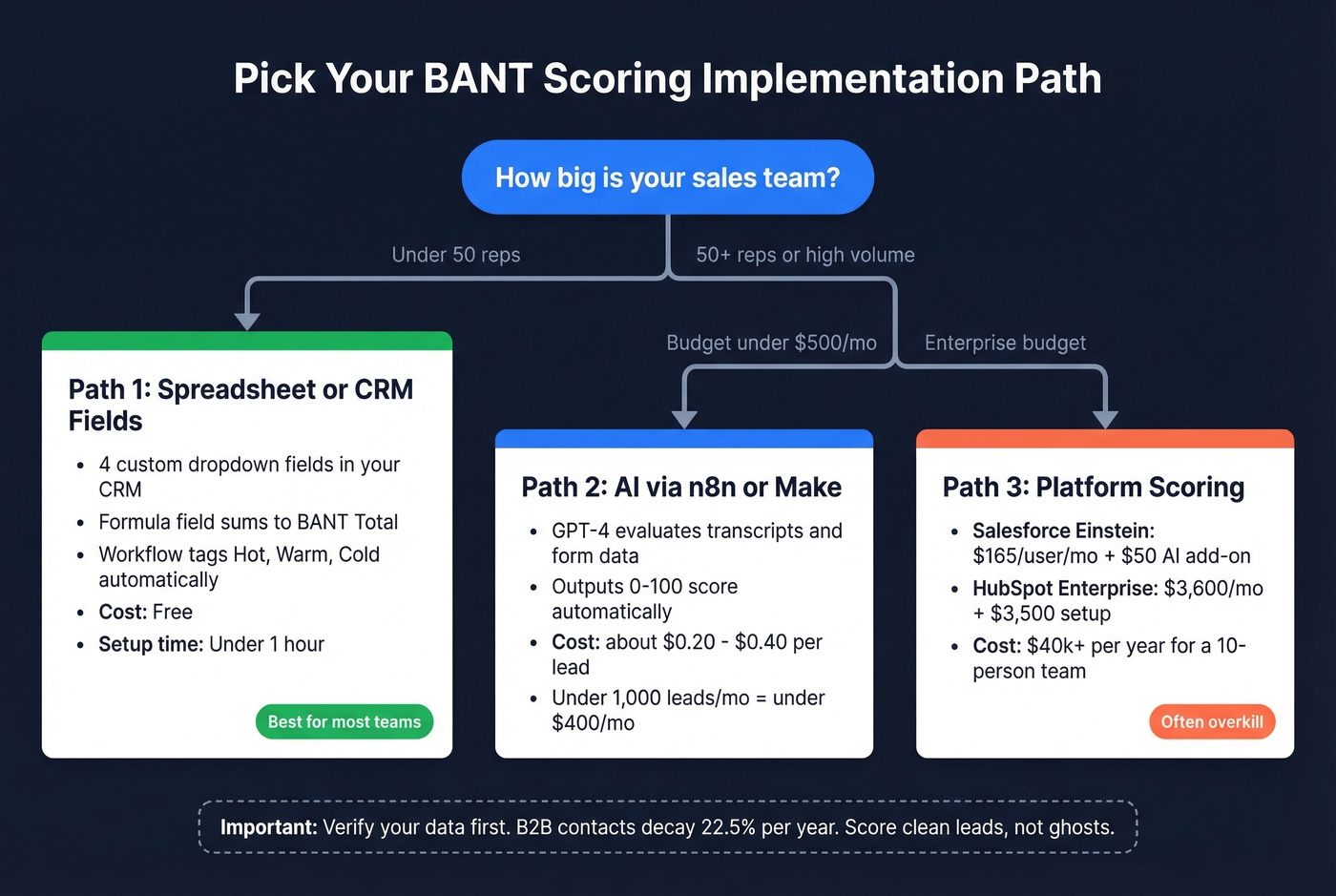
Spreadsheet or CRM Fields
For teams under 50 reps, skip predictive scoring tools. A spreadsheet or four custom CRM fields will get you 80% of the value at 0% of the cost. We've seen teams implement this in under an hour.
In your CRM, create four dropdown fields: BANT_Budget (0 / 5 / 15 / 25), BANT_Authority (0 / 5 / 15 / 25), BANT_Need (0 / 5 / 15 / 25), BANT_Timeline (0 / 5 / 15 / 25). Add a formula field for BANT_Total that sums them. Set up a workflow that tags leads as Hot/Warm/Cold based on the thresholds above. Reps fill in the dropdowns after discovery calls, and the score updates automatically.
AI-Powered Scoring
If you want to automate the scoring itself - not just the math - you've got options at very different price points.
GPT-4 via n8n or Make can evaluate form submissions, call transcripts, or enrichment data against your BANT rubric and output a 0-100 score. Cost: roughly $0.20-$0.40 per lead. For most teams doing under 1,000 leads/month, that's under $400.
Salesforce Einstein scores leads 1-100 but requires Sales Cloud Enterprise at $165/user/month plus a $50/user/month AI add-on. A 10-person team typically spends $40k+/year on Einstein capabilities. HubSpot's manual scoring requires Professional at $890/mo; predictive scoring requires Enterprise at $3,600/mo with a 10-seat minimum and $3,500 onboarding fee.
Let's be honest: if you're paying $40k/year for Einstein just to score leads, you're overengineering a problem a spreadsheet and clean data can solve.
Fix Your Data First
None of this works if your underlying data is garbage. B2B contact data decays 22.5% annually, and many providers refresh around every six weeks. By the time you score a lead, the email's already bouncing. You scored a ghost.
Before you build any scoring system, verify your lead list. Prospeo runs a 7-day data refresh cycle with 98% email accuracy, and the free tier covers 75 email verifications per month - enough to test the workflow before committing. You can also layer in 50+ data points per contact through CRM enrichment, giving your scoring model richer inputs for the Authority and Need dimensions.
| Tool | What You Get | Cost |
|---|---|---|
| Spreadsheet + verified data | Manual scoring + clean contacts | Free or ~$0.01/email |
| GPT-4 via n8n/Make | AI scoring per lead | ~$0.20-$0.40/lead |
| HubSpot Professional | Manual lead scoring | $890/mo |
| HubSpot Enterprise | Predictive scoring | $3,600/mo + $3,500 setup |
| Salesforce Einstein | AI lead scoring | $165/user/mo + $50 AI add-on |
You just built a scoring model that separates hot from cold. Now feed it better inputs. Prospeo's 30+ search filters - including buyer intent, job changes, and funding signals - let you pre-qualify leads on Budget, Authority, Need, and Timeline before the first call.
Pre-score your pipeline with real buyer signals for $0.01 per lead.
Is BANT Still Relevant in 2026?
The "BANT is dead" crowd has a point - but they're solving the wrong problem. The real issue was never the framework. It was how teams used it.
One analysis of 4,000+ cold email campaigns found that dropping rigid BANT qualification from outreach lifted response rates from 8% to 31%. That sounds damning until you realize the problem was using BANT as a disqualification gate on first touch, not as a scoring system for prioritization. There's a massive difference between "this lead doesn't meet BANT, don't contact them" and "this lead scores 45, sequence them into a nurture track."
84% of buyers go with the first vendor they engage. Waiting for perfect qualification before engaging means you've already lost. The fix isn't abandoning BANT - it's using the score to prioritize speed, not permission.
Lazy BANT is dead. A disciplined scoring strategy leads to faster routing, cleaner pipeline, and higher close rates. The lead scoring market reached $2.23B in 2025 and is growing at 11.4% CAGR - teams aren't moving away from scoring, they're getting more sophisticated about it.
BANT vs. MEDDIC vs. CHAMP
BANT isn't the only qualification framework, and it's not always the right one. In our experience, the $50k ACV threshold is where BANT starts to strain.
| Framework | Best For | Weakness | When to Switch |
|---|---|---|---|
| BANT | High-velocity SMB, <$50k deals, 1-3 stakeholders | Misses stakeholder complexity | ACV exceeds $50k or 5+ stakeholders |
| MEDDIC | Enterprise, high-ACV, multi-stakeholder | Can slow short-cycle deals | Short-cycle deals under $25k ACV |
| CHAMP | Mid-market consultative, pain-first | Too loose without discipline | Need-driven motions with clear ICP |
| ANUM/FAINT | Niche variants | Limited applicability | Edge cases only |
One documented case showed forecast accuracy jump from 62% to 89% after switching from BANT to MEDDIC for enterprise deals. That's not because BANT was wrong - the team was selling $200k deals into buying committees of 8+ people, and BANT simply doesn't have a mechanism for mapping decision processes at that scale.
Use BANT lead scoring for deals under $50k with 1-3 stakeholders. Once you're dealing with buying committees of five or more, graduate to MEDDIC. There's no shame in outgrowing a framework - it means your deals are getting bigger.
FAQ
What is a good BANT score?
75+ out of 100 is a hot lead ready for immediate sales engagement. 50-74 is warm and worth nurturing with targeted sequences. Below 50, deprioritize or park in a long-term cadence. Most teams route 75+ directly to AEs and re-score warm leads quarterly.
How many criteria does a lead need to qualify?
Most teams use a 3-out-of-4 rule - strong on three dimensions, weak on one, still worth pursuing. Missing both Budget and Authority is a disqualifier because there's no viable path to a purchase decision without at least one.
How do I keep scores accurate over time?
B2B contact data decays 22.5% annually, so scores built on stale data degrade fast. Use a verification tool with frequent refresh cycles and re-score leads quarterly. Update CRM fields after every meaningful interaction so the number reflects reality, not a snapshot from three months ago.
How does BANT scoring help with lead prioritization?
It gives every lead a numeric value that maps directly to a next action - call now, nurture, or disqualify. Without it, reps default to working leads in arrival order or based on gut feel, which means high-intent prospects sit in queue behind tire-kickers. The score replaces subjective judgment with a repeatable system.