Lead Scoring Is Broken at Most Companies - Here's How to Fix It
Marketing sent 200 MQLs last month. Sales booked four meetings. The VP of Sales drops a Slack message that lands like a grenade: "These leads are garbage." Marketing fires back with engagement data showing those 200 leads opened emails, downloaded content, and hit the pricing page. Both teams are right - and that's the problem with how most companies handle lead scoring.
Only 44% of organizations use scoring at all. The ones that do mostly collapse three separate questions into a single number: Is this the right company? Is this the right person? Is this the right time? When you blend those into one score, an intern who downloads three whitepapers outranks a VP who visited your pricing page once. Scoring isn't broken because the concept is wrong. It's broken because most implementations are lazy.
Here's the framework in three bullets:
- Score three dimensions separately - company fit, person fit, and timing/intent. A single blended number hides the "why" and forces reps back to gut feel.
- Clean your data before you build a model. If a third of your emails bounce, your scores are fiction.
- Pair scoring with a 15-minute response SLA. A perfect model with a 29-hour response time loses to a mediocre model with fast follow-up. Every time.
What Is Lead Scoring?
Lead scoring assigns numerical values to leads based on how likely they are to buy. It separates "worth a phone call" from "nurture for six months."
The data feeding your model falls into two buckets. Explicit data is what you know about the lead - job title, company size, industry, revenue. Implicit data is what the lead does - page visits, email clicks, content downloads, demo requests. Most platforms let you set a threshold where a lead crosses from marketing-qualified (MQL) to sales-qualified (SQL) and gets routed to a rep.
The concept is simple. The execution is where teams go sideways.
Consider the classic failure: an intern at a target account downloads three whitepapers and attends a webinar. Score: 85. A VP of Engineering visits your pricing page once and bounces. Score: 22. Your model just told sales to call the intern first. That's not a scoring problem - it's a dimensional problem. You scored engagement without weighting who's engaging.
Why Scoring Matters for Revenue Teams
Benchmarks show 138% ROI with lead scoring vs. 78% without. Nearly double.
When you layer in machine learning, the numbers get more dramatic. ML-powered scoring drives 75% higher conversion rates compared to rule-based models. Mid-sized companies running these models see +38% lead-to-opportunity conversion, 28% shorter sales cycles, 17% higher average deal values, and up to 35% lower cost per acquisition. Some successful AI implementations report ROI in the 300%-700% range.
Yet only 13% of marketers use AI for scoring. The other 87% are either running manual rules or flying blind. That gap is mostly a data quality and implementation problem, not a technology problem.
Why Most Models Fail
Four failure modes kill most scoring implementations.

1. The single-number trap. Most teams score firmographics plus a few activity points and call it done. The framing in this r/b2bmarketing thread nails it: a single blended score hides whether the lead is the right company, the right person, or just showing up at the right time. Reps end up back on gut feel anyway.
2. Black-box distrust. Enterprise scoring platforms like 6sense are often perceived as black boxes that prioritize accounts without explaining why. Reddit threads consistently flag this as a trust killer - reps won't act on a score they can't interrogate. If your sales team doesn't trust the model, you've spent six figures on software nobody uses.
3. Bot-corrupted engagement signals. If you're scoring email opens and clicks, you're probably scoring spam filters and security bots. Corporate email security software auto-opens and auto-clicks links before delivering messages. A lead who never read your email can look like a hot prospect.
4. Set-and-forget decay. Your ICP evolves. Your product changes. A scoring model built 18 months ago is scoring against a reality that no longer exists. Quarterly recalibration isn't optional - it's what keeps the model from drifting into irrelevance.
How to Build Your Lead Scoring Model
Score Three Dimensions Separately
Stop collapsing everything into one number. Maintain three distinct scores that travel with every lead.
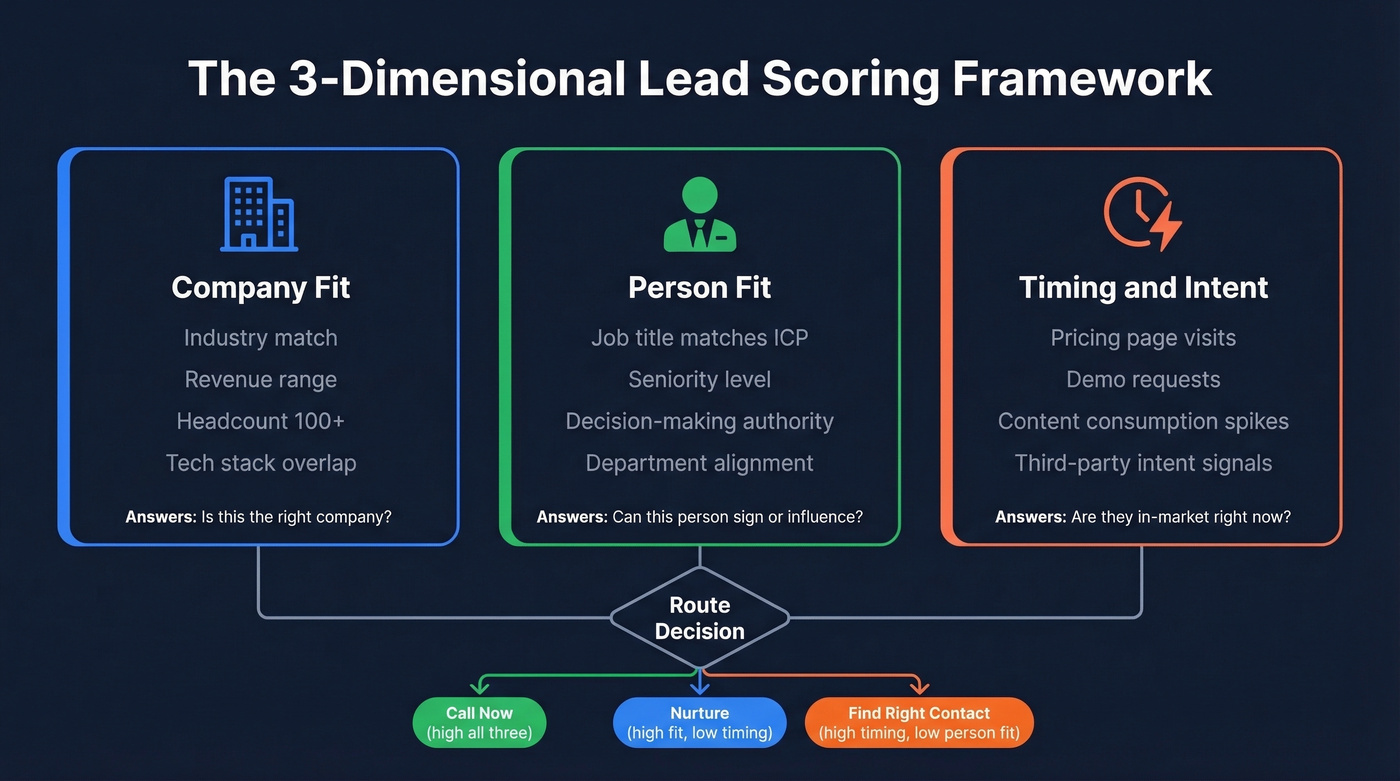
Company fit covers firmographics: industry, revenue, headcount, tech stack, funding stage. This answers "is this the kind of company that buys from us?"
Person fit covers the individual: title, seniority, department, decision-making authority. This answers "can this person sign a check or influence the deal?" (If you need a quick way to define and score this, use an ideal customer profile template.)
Timing covers behavioral and intent signals: pricing page visits, demo requests, content consumption patterns, third-party intent data. This answers "are they in-market right now?" (More on turning those signals into a system in our guide to identifying buying signals.)
When a rep sees high company fit, high person fit, but low timing, they know to nurture - not call. When timing spikes but person fit is low, they know to find the right contact at that account. A single blended score can't communicate any of that.
In our experience, teams that separate these dimensions see 10-30% lift in MQL-to-SQL conversion once they add fit, intent, decay, and an SLA together.
The Scoring Rubric
Here's a working rubric adapted from HubSpot-style models with point values you can steal and adjust:
| Signal | Type | Points |
|---|---|---|
| Job title matches ICP | Person fit | +10 |
| Company size >100 | Company fit | +5 |
| Clicked email link | Timing | +10 |
| Viewed pricing page | Timing | +15 |
| Filled contact form | Timing | +20 |
| Requested demo | Timing | +100 |
| No company email | Person fit | -15 |
| Competitor domain | Company fit | -1,000 |
| Unsubscribed | Timing | -15 |
| 30+ days inactive | Decay | -5/week |
That -1,000 for competitor domains isn't a typo. Competitors downloading your content, attending your webinars, and visiting your pricing page will score high on every behavioral metric. Nuke them from your pipeline with a score so negative it can't be overcome.
To calibrate these numbers for your business, compare each attribute's close rate to your overall baseline. If your average close rate is 2% but leads with "VP" titles close at 8%, that 4x lift justifies a higher point value. Don't copy arbitrary numbers - derive them from your own conversion data. (If you want benchmarks to sanity-check your math, see our average B2B lead conversion rate guide.)
The LeadsBridge example roundup shows about 40% of leads landing in the 41-60 range, with fewer than 10% reaching 81-100. Most leads cluster in the middle, which is exactly why your threshold needs calibration to your specific sales capacity.
Thresholds and Decay Rules
Start with score >50 as your MQL threshold, then adjust based on reality:
- MQL threshold: Tie it to sales capacity. If you're generating 50 MQLs/week and sales can handle 30, raise the bar until volume matches capacity.
- Engagement decay: Subtract 5 points per week after 30 days of inactivity. A pricing page visit from two months ago doesn't mean what it meant then.
- Hard reset: After 90-180 days of zero activity, reset the timing score entirely.
- Quarterly recalibration: Pull conversion data every quarter. Which scored leads actually became opportunities? Adjust weights accordingly.
- Override rule: Demo, trial, or "talk to sales" requests bypass the model entirely. Route to a rep immediately. Disqualification happens via human conversation, not formula.
You just read that bad data kills scoring models. If a third of your emails bounce, your scores are fiction. Prospeo delivers 98% email accuracy with a 7-day refresh cycle - so every firmographic, title, and intent signal feeding your model reflects reality, not stale records.
Clean data in, accurate scores out. It starts at $0.01 per email.
Predictive Scoring - When It's Worth It
A 2025 study published in Frontiers in AI tested 15 classification algorithms on B2B lead data and found Gradient Boosting hitting 98.39% accuracy, with XGBoost and LightGBM reaching ~99% AUC. Traditional rule-based scoring tops out around 60-70%. The gap is massive. (If you're evaluating this path, our overview of B2B predictive analytics can help you set expectations.)

But here's the decision framework that actually matters: if you're generating fewer than 1,000 leads per year or closing fewer than 100 deals, manual rules will outperform AI. There simply isn't enough training data. You need 12-24 months of clean CRM data and 100+ conversions before predictive scoring has enough signal to work with.
Let's be honest - if your average deal size is under $15k and your team is under 50 people, skip predictive scoring entirely. A well-built manual model with clean data and a fast SLA will outperform a poorly implemented AI model every time. The 62% failure rate for AI initiatives in sales isn't because the technology doesn't work. It's because teams buy the model before they've earned the data.
Speed-to-Lead Makes or Breaks Scoring
You can build the most sophisticated scoring model in the world, and it won't matter if your team takes 29 hours to respond. That's the actual average, per a study of 1,000 companies. Even worse: 63.5% of companies never respond at all.
81.2% of companies responding in more than an hour report losing leads to faster competitors. Companies with a formal response-time SLA are nearly twice as likely to respond within 15 minutes - 54.9% vs. 29.5% without an SLA. (If you need copy you can deploy fast, use these sales follow-up templates.)

Here's the thing: a good-enough scoring model plus clean data plus a 15-minute SLA beats a sophisticated model plus dirty data plus a 29-hour response time. Every single time. Speed compounds the value of scoring. Without speed, scoring is just an expensive way to sort a list nobody calls.
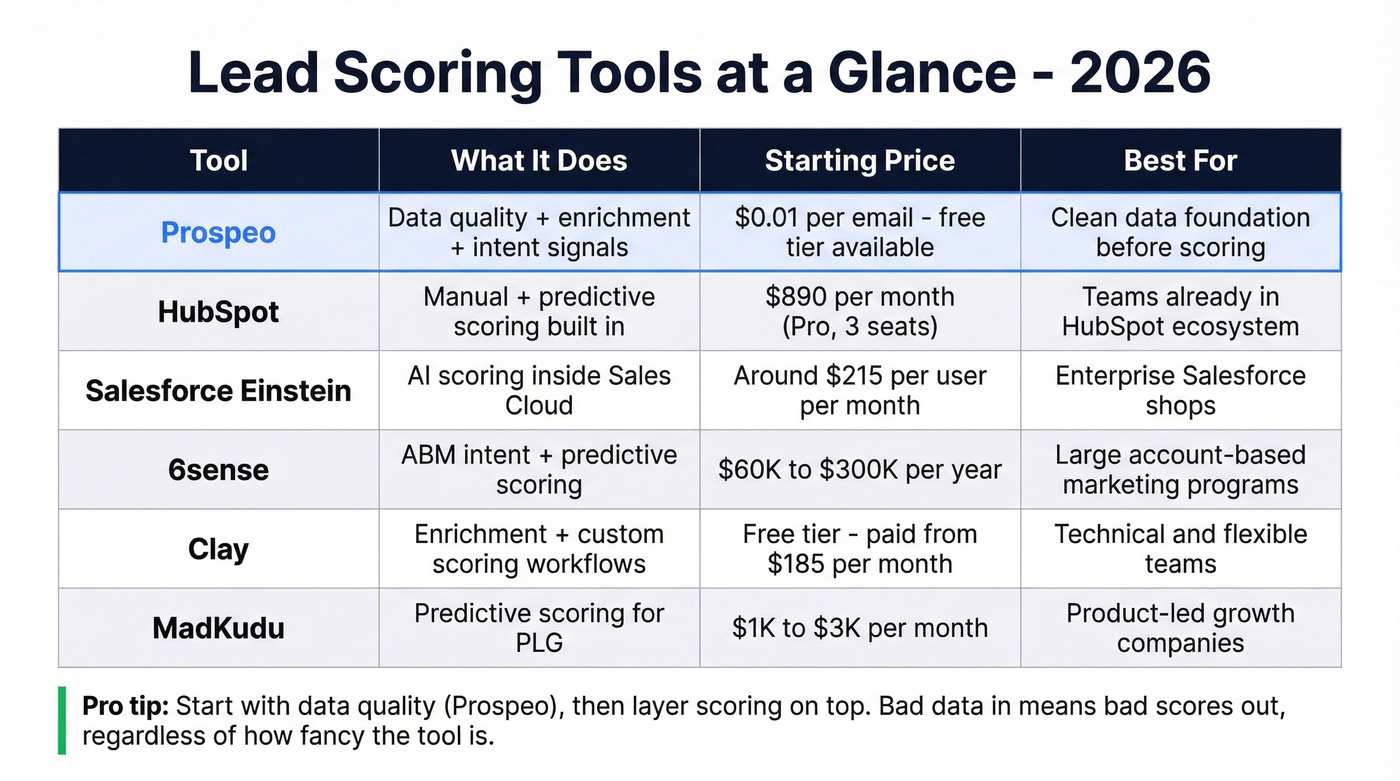
Lead Scoring Tools Compared
| Tool | What It Does | Starting Price | Best For |
|---|---|---|---|
| Prospeo | Data quality + enrichment + intent | ~$0.01/email; free tier | Clean data before scoring |
| HubSpot | Manual + predictive scoring | $890/mo (Pro, 3 seats) | HubSpot ecosystem teams |
| Salesforce Einstein | AI scoring in Sales Cloud | ~$215/user/mo total | Enterprise SF shops |
| 6sense | ABM intent + predictive | ~$60K-$300K/yr | Large ABM programs |
| Clay | Enrichment + custom scoring | Free; paid from $185/mo | Technical, flexible teams |
| MadKudu | Predictive for PLG | ~$1K-$3K/mo | Product-led growth |
| Apollo | Prospecting + basic scoring | Free; paid from ~$49/mo | SMBs starting outbound |
HubSpot now supports multi-model scoring and better explainability. Manual scoring comes with Professional at $890/mo, and AI-generated engagement/fit scoring requires Marketing Hub Enterprise. The Breeze Intelligence add-on starts at $45/mo for 100 credits if you need enrichment on top.
Salesforce Einstein vs. 6sense is the enterprise fork in the road. Einstein is powerful if you're already deep in Salesforce, but a 10-person team is looking at $40K+/year before implementation. 6sense runs $60K-$300K annually and is genuinely impressive for large ABM programs, but the black-box perception hurts rep adoption. We've seen teams spend months on 6sense onboarding only to have reps ignore the scores because they can't explain them to their managers.
Clay offers incredible flexibility for technical teams building custom scoring workflows. The risk: one Reddit user reported blowing 64% of their monthly budget on a single workbook. At $229/mo for 3,000 credits, experimentation gets expensive fast. (If you're building workflows there, this Clay list building breakdown will help you avoid cost surprises.)
Apollo is the budget entry point - free tier plus basic scoring gets SMBs started, though the data quality ceiling is lower. If you're just getting started with outbound and don't have a scoring model yet, it's a reasonable place to learn. Skip it once you outgrow the data accuracy.
Data Quality - The Prerequisite Nobody Talks About
Your scoring model is only as good as the data feeding it. If emails bounce, your engagement scores are built on contacts who never received your messages. If job titles are six months stale, your person-fit scores are grading against roles people no longer hold. (To quantify and fix this, see our email bounce rate guide.)
Prospeo addresses this with 98% email accuracy and a 7-day data refresh cycle - compared to the 6-week industry average. The platform covers 300M+ professional profiles with 143M+ verified emails, and includes intent data across 15,000 topics you can use as timing signals in your scoring model. Native integrations with Salesforce and HubSpot mean enriched data flows into your CRM without manual imports. (If you're comparing vendors, start with these data enrichment services.)
The proof is in the outcomes. Snyk's outbound team cut bounce rates from 35-40% down to under 5% after cleaning their data pipeline. Meritt tripled their pipeline from $100K to $300K per week. Those aren't scoring improvements - they're data quality improvements that made scoring actually work.
You can spend $3,600/mo on HubSpot Enterprise's predictive scoring or $60K/year on 6sense. But if a third of your contact records are stale, you're running a sophisticated algorithm on fiction. Fix the data first. It's cheaper and it has a bigger impact. (If you want the underlying definitions, Company fit covers firmographics and technographics - and both need to be accurate.)
Scoring three dimensions means you need company fit, person fit, and timing data that's actually reliable. Prospeo's 30+ search filters cover technographics, headcount growth, funding, and buyer intent across 15,000 topics - every signal your model needs, verified and fresh.
Stop scoring against stale data. Build your model on 300M+ verified profiles.
Common Mistakes
Overvaluing isolated actions without sequence context. A single whitepaper download means almost nothing. Three pricing page visits clustered after a demo request? That's a buying signal. Score behavior in context, not in isolation.
Ignoring data quality. Stale job titles, bounced emails, and duplicate records corrupt every dimension of your model. Clean your data before you trust your scores. (If you're building a repeatable process, use a documented lead generation workflow so scoring inputs stay consistent.)
Building multiple parallel models. Teams sometimes create separate scoring models per product line, geography, or segment. This sounds logical but becomes a maintenance nightmare within two quarters. One model with incorporated variations is almost always better than four models nobody maintains.
FAQ
What is lead scoring?
Lead scoring assigns numerical values to each lead based on demographic fit and behavioral engagement so sales teams can prioritize prospects most likely to convert. Without a structured ranking system, reps waste time on contacts who were never going to buy.
What's the difference between scoring and grading?
Scoring measures behavioral engagement - actions a lead takes like page visits and demo requests. Grading measures demographic and firmographic fit - who the lead is. Best practice is to use both, because high engagement from the wrong persona wastes pipeline.
How many points should trigger an MQL?
Start at 50, then adjust based on sales capacity and conversion data. If reps can't follow up on all MQLs within 15 minutes, raise the threshold. Recalibrate quarterly using closed-won data to keep the number honest.
When should I switch from manual to predictive scoring?
When you have 12-24 months of clean CRM data and 100+ closed-won deals. Below that threshold, manual rules outperform AI because there isn't enough training data for algorithms to find meaningful patterns.
How does data quality affect my scoring model?
Directly and severely. If emails bounce, engagement scores reflect contacts who never received your messages. Tools like Prospeo, Clay, and Apollo can help ensure your model scores real people, not outdated records - but the key is building a verification step into your workflow before any scores get assigned.