10 Common Data Quality Issues That Are Quietly Costing You Millions
Your AI initiative just failed. Not because the model was wrong - because the training data was garbage. Customer addresses had three different formats, 20% of the CRM records were duplicates, and half the contact emails bounced. Six months building a recommendation engine on a foundation of sand.
This isn't hypothetical. 43% of chief operations officers say data quality is their most significant data priority right now. Gartner estimates companies lose $12.9M annually to poor-quality data. With 79% of organizations adopting AI agents and AI spending set to surpass $2T in 2026, the cost of dirty data isn't just operational - it's existential.
Most guides list the issues and call it a day. That's a taxonomy, not a solution. What follows: a measurement framework, specific fixes, and the one category everyone ignores.
Quick Summary
- The mental model: 7 core dimensions of data quality - accuracy, completeness, validity, timeliness, uniqueness, integrity, consistency. Every issue maps to at least one.
- The top 3 by business impact: Inaccurate data, duplicate records, and outdated/stale data. These three alone account for the majority of financial damage.
- The measurement approach: Build a scorecard with thresholds, scores, and trends per dimension. If you can't measure it, you can't fix it.
- The blind spot: B2B contact data decays fast - often 30%+ per year. Most data quality programs ignore prospect data entirely.
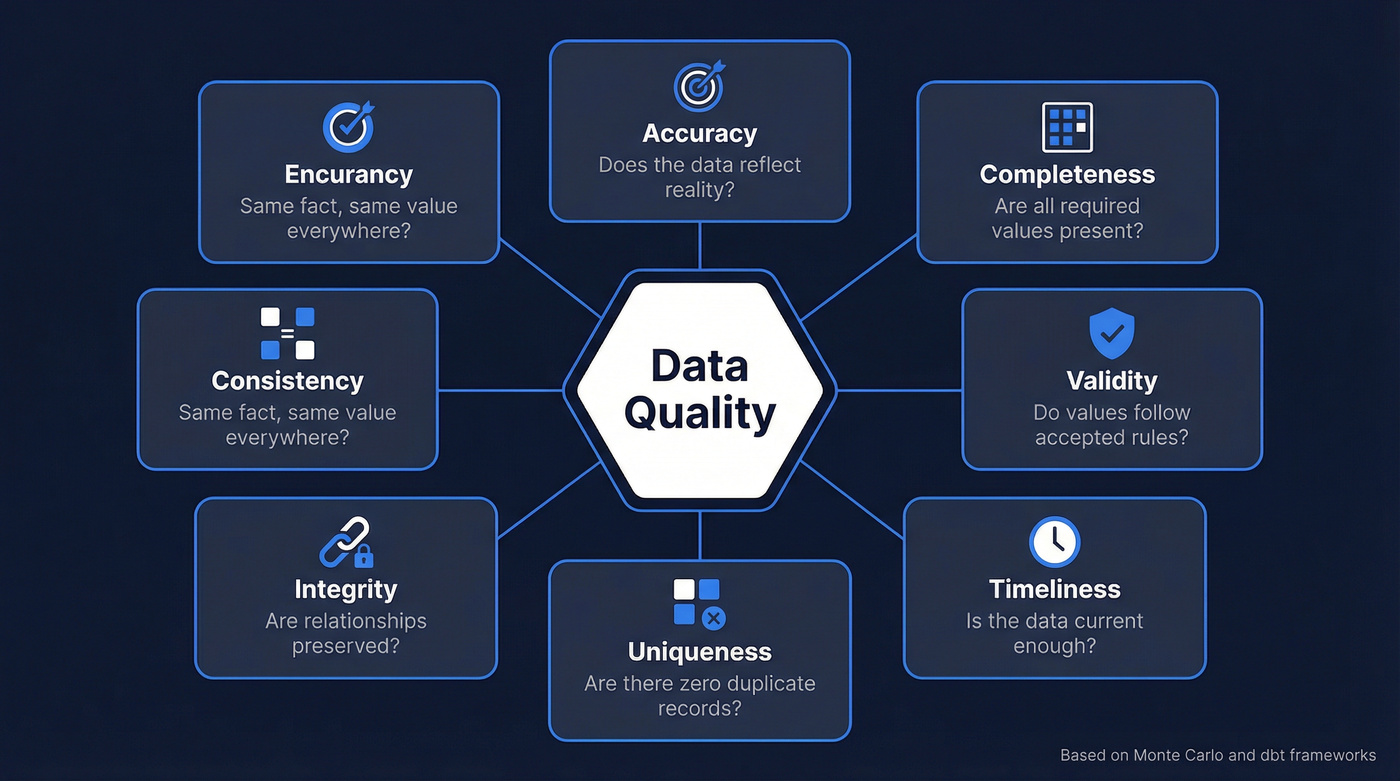
The 7 Dimensions of Data Quality
Before getting into specific problems, you need a shared vocabulary. The Monte Carlo framework lays out six classic dimensions and adds a seventh - consistency - for modern multi-system data flows. dbt's taxonomy also includes "usefulness," meaning whether the data actually gets used at all.
| Dimension | What It Measures | Example Failure |
|---|---|---|
| Accuracy | Data reflects reality | Revenue field shows $0 for active accounts |
| Completeness | No missing values | 40% of contacts lack phone numbers |
| Validity | Values within accepted rules | Date field contains "13/32/2026" |
| Timeliness | Data is current enough | Address list is 18 months old |
| Uniqueness | No duplicate records | Same company appears 6 times in CRM |
| Integrity | Relationships are preserved | Order references a deleted customer ID |
| Consistency | Same fact, same value everywhere | Billing says "Acme Inc," CRM says "ACME" |
Every issue in the next section maps back to one or more of these dimensions. Keep this table handy.
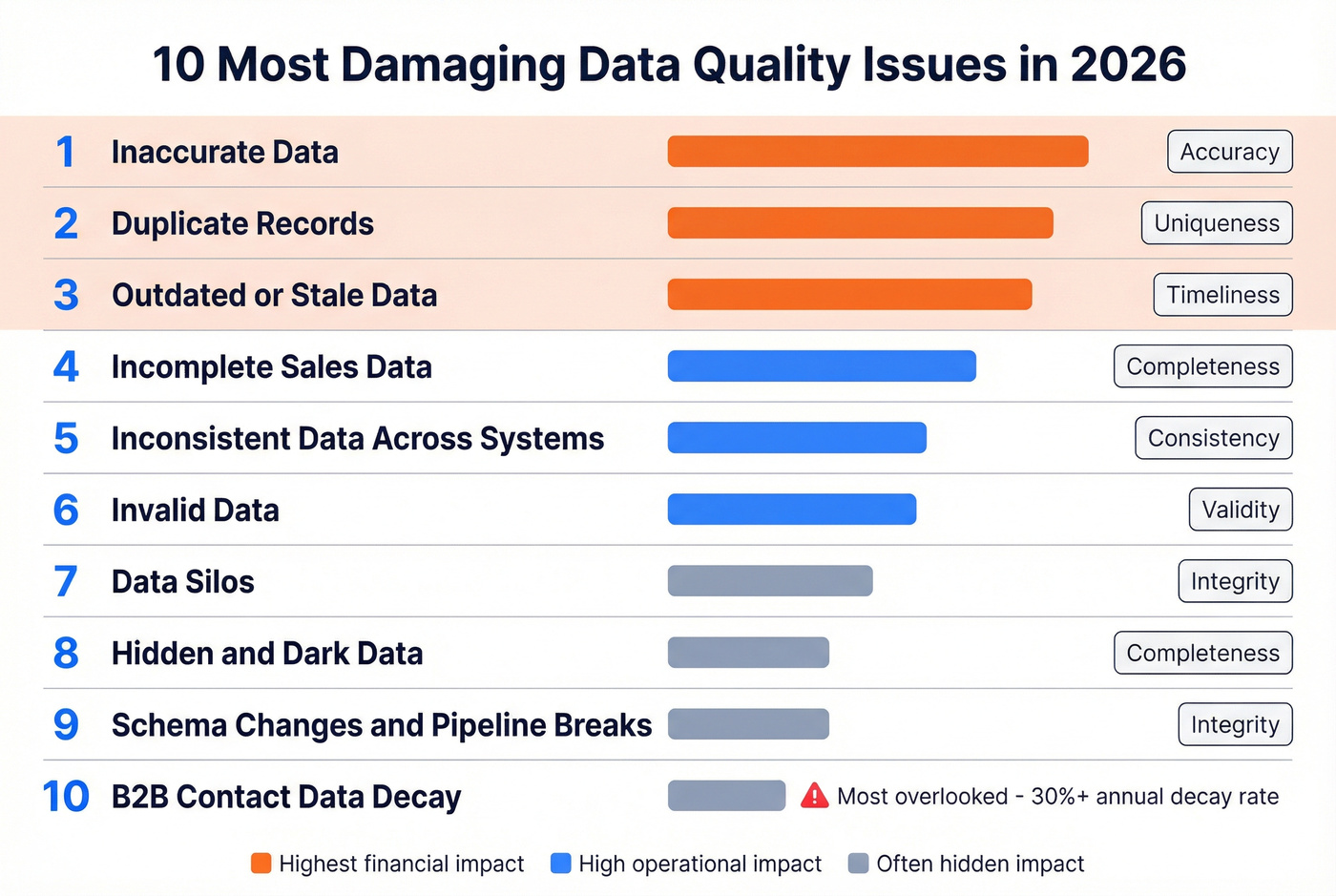
The 10 Most Damaging Data Quality Problems
1. Inaccurate Data
A contact's job title is two promotions old. A revenue figure is off by a decimal. A shipping address points to a building demolished in 2019. Over 25% of organizations estimate they lose more than $5M annually to poor data quality, and 7% report losses exceeding $25M. Inaccuracy is the root cause in most of those cases - and one of the clearest examples of quality failures that directly erode revenue.
Fix it: Automated validation rules at ingestion, cross-source reconciliation comparing CRM data against billing, support, and third-party sources, and regular audits of high-value fields like revenue, title, and address.
2. Incomplete Sales Data
Fields are blank, records are half-populated, critical attributes are missing entirely. A lead comes in with an email but no company name. A customer record has revenue but no industry code. This kind of incomplete data causes segmentation to break, lead scoring to misfire, and reporting to become unreliable. Run null/blank field checks on every critical column - if completeness drops below 95% on fields that drive decisions, you've got a problem.
Fix it: Required-field enforcement at data entry, enrichment workflows that backfill missing attributes automatically, and completeness monitoring dashboards that flag degradation before it hits reports.
3. Duplicate Records
Skip this if your CRM has fewer than 1,000 records. For everyone else: CRM duplication rates reach up to 20%, and 70% of organizations struggle with duplicate or inconsistent data due to a lack of matching technology. We've seen companies trace quarterly reporting confusion to thousands of duplicate records inflating activity metrics - leadership was making decisions on phantom pipeline.
Duplicates don't just waste storage. They skew forecasts and trigger double-outreach. Nothing kills credibility faster than two reps emailing the same buyer on the same day.
Fix it: Deduplication tools with fuzzy matching, entity resolution for complex cases like the same company under different spellings, and unique constraints on key identifiers at the database level.
4. Inconsistent Data Across Systems
"IBM" vs "International Business Machines" vs "I.B.M." - same company, three records, zero reconciliation. 60% of the data quality challenge comes from variations in business names, personal names, and addresses. And 40% of organizations face compliance or regulatory challenges tied directly to inconsistent data formats.
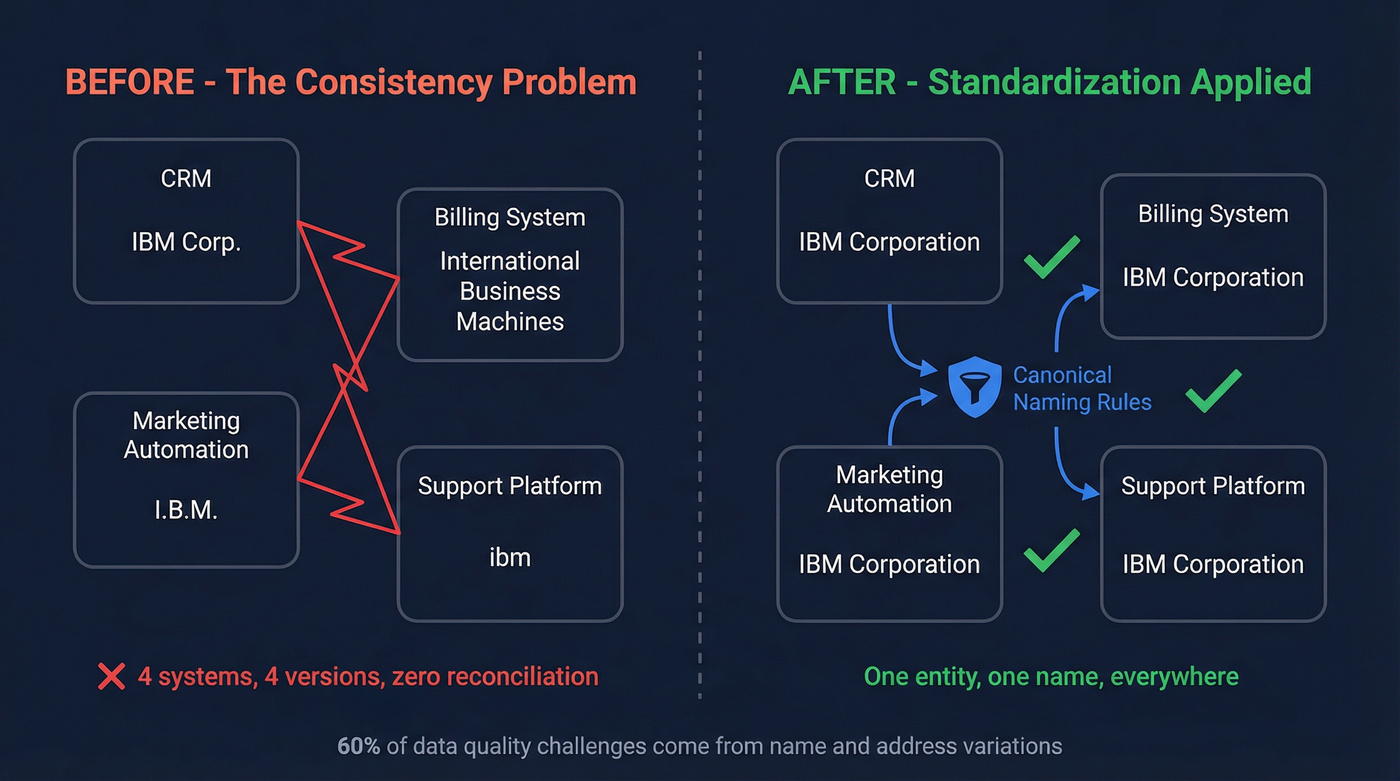
Standardization rules applied at ingestion, not after the fact. Schema enforcement across all data sources. A canonical naming convention for key entities. These three steps eliminate the majority of formatting issues before they propagate.
5. Outdated or Stale Data
One organization ran a direct mail campaign and hit a 30% return rate - nearly a third of the addresses were wrong. That's not a data problem you discover in a dashboard. That's money in the trash.
Timeliness is the dimension most teams underinvest in. Data doesn't just go bad when someone makes an error - it decays naturally as people move, companies merge, and markets shift. Set freshness SLAs by dataset tier: operational data under 24 hours, reference data weekly, archival monthly. Then build automated refresh cycles and decay monitoring that alerts you before campaigns go out on stale lists.
6. Invalid Data
What does invalid data actually look like? A date field that accepts "February 30th." A country code that doesn't exist. A revenue field storing text strings. These are violations of the validity dimension - values that fall outside accepted rules or data types.
dbt tests - not_null, unique, accepted_values, relationships - catch validity and integrity issues in the transformation layer. Input validation at the application level prevents them from entering in the first place. You need both.
7. Data Silos
65% of companies need smoother integration across multiple sources - Salesforce, HubSpot, billing systems, support platforms, marketing automation. When these systems don't talk to each other, the same customer exists in five places with five different versions of the truth.
Silos aren't just an IT problem. They're a trust problem. When sales and finance can't agree on revenue numbers because they're pulling from different systems, every meeting becomes a data reconciliation exercise instead of a strategy conversation. An integration layer via iPaaS or custom build, a shared data catalog so teams know what exists and where, and cross-team governance that assigns ownership to critical data domains - that's how you break them down.
8. Hidden and Dark Data
Splunk estimates up to 55% of a company's data is dark data - collected but never analyzed, never used, never even cataloged. It sits in file shares, legacy databases, and forgotten S3 buckets.
Here's the thing: dark data is a dual threat. It's a compliance liability because you can't protect data you don't know you have, and GDPR doesn't care about your ignorance. It's also a missed opportunity, because there might be gold in those unused datasets. Most data quality programs focus exclusively on data they know about. The stuff they don't know about is often worse.
Fix it: Data profiling audits to discover what you actually have, usage tracking to identify datasets nobody touches, and archival policies that either activate or delete dark data on a schedule.
9. Schema Changes and Pipeline Breaks
This is the modern data engineer's nightmare. An upstream team renames a column, changes a data type, or adds a field - and every downstream consumer breaks silently. Schema drift is insidious because it doesn't always throw errors. Sometimes it just produces wrong numbers, and nobody notices for weeks.
Data observability tools that continuously monitor for schema changes are the first line of defense. Pair those with schema contracts between producers and consumers and automated alerts that fire before bad data reaches dashboards. Monte Carlo and similar platforms exist specifically for this use case.
10. B2B Contact and Prospect Data Decay
This is the data quality issue nobody talks about in most guides, because they're written for data engineers thinking about warehouses and pipelines. But if you're in sales or marketing, your prospect data decays fast as people change jobs, companies rebrand, and email addresses deactivate.
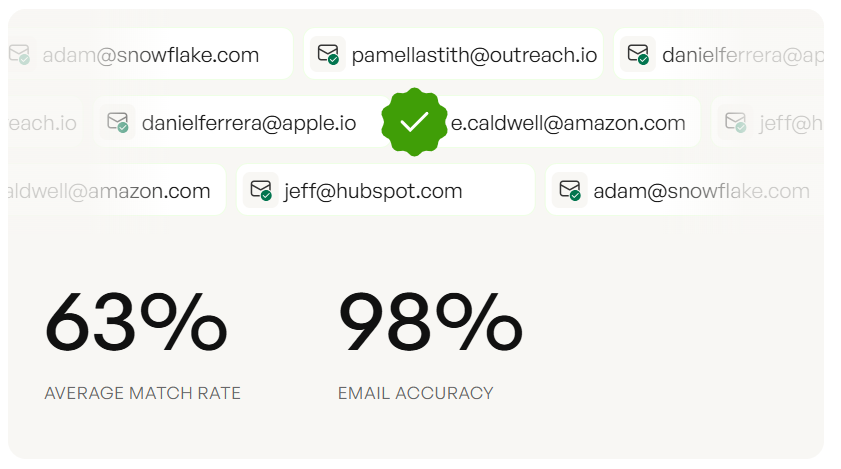
The impact is measurable and brutal. Meritt saw bounce rates of 35% before addressing contact data quality - more than a third of their outreach was hitting dead addresses. Snyk's team of 50 AEs was running 35-40% bounce rates. Both got under 5% after implementing real-time verification with Prospeo, which uses a 5-step process including catch-all handling, spam-trap removal, and honeypot filtering across 143M+ verified addresses.
The playbook: real-time verification before every campaign, scheduled re-verification of CRM contacts on a monthly cadence, and enrichment automation that backfills missing fields as contacts change roles. The consensus on r/sales is pretty clear - if you're not verifying before every send, you're gambling with your domain reputation.
You just read that B2B contact data decays 30%+ per year. Prospeo's 7-day refresh cycle keeps 300M+ profiles current - while most providers wait 6 weeks. 98% email accuracy, 5-step verification, catch-all handling, and spam-trap removal built in.
Stop building campaigns on data that expired last month.
Data Quality and AI - The 2026 Crisis
AI didn't create data quality problems. It exposed the ones you were ignoring.

BARC's survey of 421 global respondents found that between 2024 and 2025, data quality as the #1 AI obstacle jumped from 19% to 44%. That's not a trend - that's a reckoning. Meanwhile, 45% of business leaders cite data accuracy and bias concerns as a barrier to scaling AI, 51% of organizations report AI software costs exceeding expectations, and 43% had unexpected validation and quality control expenses they never budgeted for.
As Andrew Ng put it: "If 80 percent of our work is data preparation, then ensuring data quality is the most critical task for a machine learning team."
Two risks that didn't exist in the traditional BI world deserve attention. Data poisoning - malicious or misleading data injected to distort model training - is a growing attack vector. Synthetic data feedback loops, where re-feeding AI-generated data back into training sets degrades model quality over time like a photocopy of a photocopy, are even harder to detect. Mayo Clinic has highlighted imaging data issues (format inconsistency, resolution variance, incomplete metadata) that can undermine diagnostic AI, while JPMorgan Chase built real-time validation, anomaly detection, and drift monitoring specifically for fraud models. These aren't edge cases. They're the new normal.
Why These Problems Persist
Look, if 65% of companies are still scrubbing data in Excel in 2026, the tooling isn't the bottleneck - the culture is. Here are the five anti-patterns we see repeatedly:
Ignoring quality until it's too late. Teams treat data quality as a cleanup project after something breaks, not as a continuous discipline.
No clear data strategy. Without a roadmap that defines what "good" looks like, every team sets their own standards. The result is chaos dressed up as autonomy.
Siloed ownership. Data quality can't live exclusively in engineering or exclusively in ops. Leaders set governance standards, practitioners build automated checks, consumers flag anomalies. All three roles matter.
Underestimating data literacy. You can build the best validation framework in the world, and it won't matter if the people entering data don't understand why formatting matters.
Failing to adapt. Schema drift, new sources, acquisitions, platform migrations - a quality program that worked two years ago is irrelevant today if nobody's updating it.
Let's be honest: most companies don't have a data quality problem. They have a data ownership problem. Until someone's name is next to every critical dataset with explicit accountability for its accuracy, no amount of tooling will save you.
How to Measure Data Quality
You can't fix what you don't measure. The Datafold scorecard approach gives you a structure: dimensions, scores, thresholds, trends, and action items in one shareable dashboard. This is the section worth bookmarking.
| Dimension | Metric | Target | Current | Status |
|---|---|---|---|---|
| Uniqueness | Duplicate rate | <2% | 4.3% | 🔴 Failing |
| Completeness | Critical field fill rate | >95% | 91% | 🟡 Warning |
| Timeliness | Freshness SLA (operational) | <24 hrs | 18 hrs | 🟢 Passing |
| Accuracy | Cross-source match rate | >98% | 96.5% | 🟡 Warning |
| Validity | Failed validation checks/week | <50 | 23 | 🟢 Passing |
The thresholds aren't universal - a 2% duplicate rate is aspirational for a company currently at 15%. Start with where you are, set realistic targets, and track trends. In our experience, teams that skip the scorecard step end up firefighting the same issues quarter after quarter because there's no baseline to measure progress against. IBM recommends tracking mean time to detection and incident frequency as operational metrics. Once the scorecard matures, wire it into automation: Slack alerts when a dimension drops below threshold, automated tickets for remediation, and weekly trend reports to leadership.
Tools for Fixing Data Quality
The tooling has evolved from manual cleanup to testing frameworks to continuous observability. Here's what's worth your time:
| Tool | Type | Best For | ~Cost |
|---|---|---|---|
| dbt tests | Testing (OSS) | Teams already in dbt | Free / Cloud ~$100/mo |
| Great Expectations | Testing (OSS) | Flexible Python validation | Free |
| Soda Core | Testing (OSS) | DSL-based checks | Free / Cloud ~$10K/yr |
| Monte Carlo | Observability | Enterprise pipelines | ~$30K-100K+/yr |
| Bigeye | Observability | Mid-market teams | ~$20K-60K/yr |
| Prospeo | B2B Verification | Contact/prospect data | Free tier / ~$0.01/email |
Start with dbt tests if you're already in that ecosystem - they're free and catch validity and integrity issues in the transformation layer. For production observability covering schema drift, volume anomalies, and freshness monitoring, Monte Carlo is the market leader, though the price tag is enterprise-grade. When your data quality problem is primarily about contact accuracy rather than pipeline engineering, a verification-first approach delivers faster ROI. Prospeo's 7-day refresh cycle keeps records current while 98% email accuracy prevents the bounce-rate spirals that damage sender reputation.
Duplicates, inconsistencies, and incomplete records wreck your CRM. Prospeo's enrichment fills in 50+ data points per contact at a 92% match rate - verified emails, direct dials, company data, and intent signals. All for about $0.01 per email.
Enrich your CRM and eliminate the data quality issues you just read about.
FAQ
What are the most common data quality issues?
The top three by financial impact are inaccurate data, duplicate records, and outdated information - together responsible for the majority of the $12.9M that Gartner estimates companies lose annually to poor-quality data. Other frequent problems include incomplete fields, inconsistent formatting across systems, invalid values, and data silos that prevent reconciliation.
How does poor data quality affect AI projects?
Bad training data produces unreliable models. Between 2024 and 2025, data quality as the #1 AI obstacle jumped from 19% to 44% according to BARC's survey of 421 organizations. Newer risks like data poisoning and synthetic feedback loops compound the problem. If you're investing in AI without investing in data quality, you're building on sand.
How do you fix B2B contact data quality?
Use real-time verification before every campaign rather than periodic bulk cleanups. Look for providers with short refresh cycles - a 7-day cycle vs the 6-week industry average makes a significant difference - and automate re-verification of CRM contacts monthly to catch job changes before they become bounces. Proactive verification is always cheaper than dealing with bounced campaigns and lost deals after the fact.
How often should you audit data quality?
Run automated checks continuously and conduct manual audits quarterly. High-impact fields like revenue, contact info, and account status deserve weekly monitoring via a scorecard. Operational datasets should meet freshness SLAs under 24 hours, while reference data can follow a weekly review cadence.