
7 Crawlbase Alternatives Worth Switching To in 2026
Crawlbase works fine until it doesn't. You hit a Cloudflare-protected target, requests start failing, and suddenly you're burning credits on retries instead of collecting data. Here's the thing: most valuable scraping targets in 2026 sit behind some form of bot protection. That's where teams start shopping for Crawlbase alternatives - and where the real differences between tools show up.
Why People Leave Crawlbase
Crawlbase carries a 4.2/5 on G2 from just 5 reviews - a thin signal at best. The recurring complaints boil down to three things:
Retries on protected sites. When targets sit behind Cloudflare, DataDome, or PerimeterX-style defenses, teams end up retrying and babysitting jobs instead of shipping data downstream.
PAYG cost creep. The per-request model looks clean until retries on complex domains double or triple your actual spend. We've seen teams realize their effective cost was 3x the sticker price after a month of scraping retail sites.
Not enough anti-bot depth for hard targets. Basic crawling works. Anything requiring heavier browser-style behavior or stronger proxy strategy gets painful fast.
G2 lists Oxylabs as the best overall alternative, but that's typically priced for teams that can justify an enterprise contract. We focused on tools that deliver more without requiring one.
Our Picks (TL;DR)
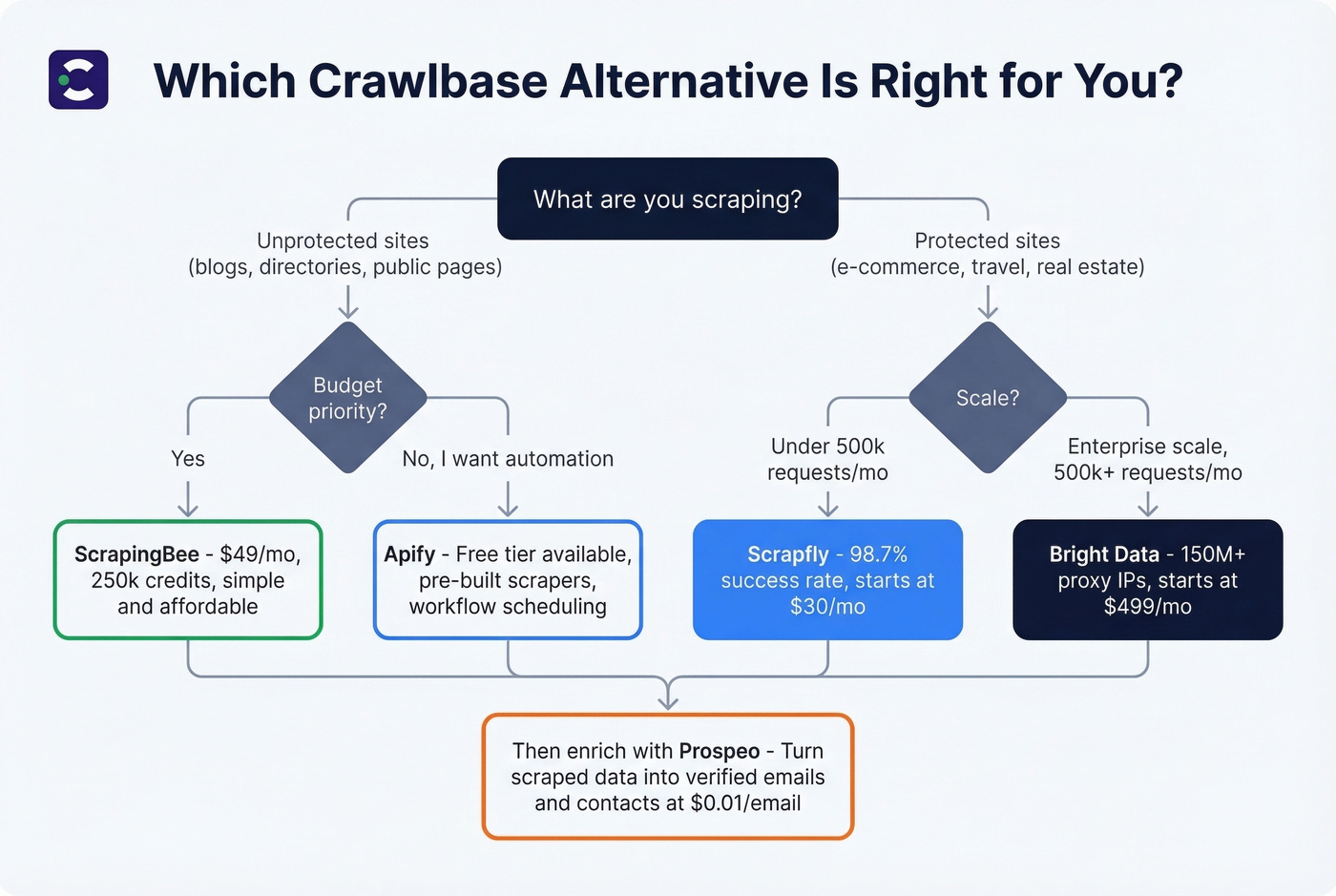
- Best for B2B data enrichment: Prospeo
- Best for protected sites: Scrapfly
- Best for automation workflows: Apify
- Best for enterprise scale: Bright Data
- Best budget option: ScrapingBee
Pricing & Performance Overview
The sticker number on scraping APIs is almost never what you actually pay. Credit multipliers for JavaScript rendering and residential proxies inflate costs 5-25x. This table uses Scrapeway's independent benchmarks (Feb 27-Mar 13, 2026) where available.
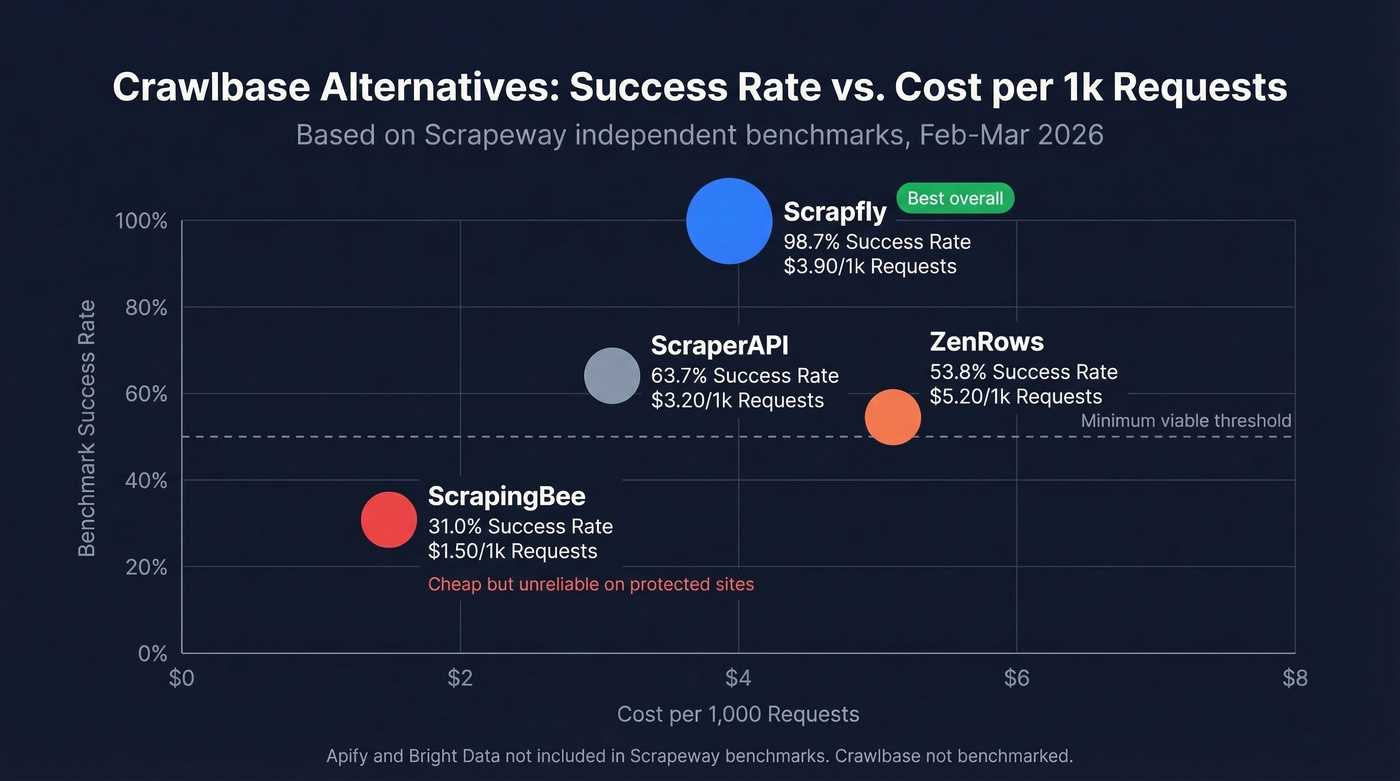
| Tool | Starting Price | Benchmark Success | Cost/1k (Scrapeway) | Best For |
|---|---|---|---|---|
| Scrapfly | $30/mo | 98.7% | $3.90 | Protected sites |
| Apify | $0 (free tier) | Not benchmarked | Varies (CU-based) | Automation |
| Bright Data | $4/1k PAYG | Not benchmarked | $4-8/1k | Enterprise scale |
| ScrapingBee | $49/mo | 31.0% | $1.50 | Budget / simple targets |
| ZenRows | $69.99/mo | 53.8% | $5.20 | Pay-for-success model |
| ScraperAPI | ~$49/mo | 63.7% | $3.20 | Simple REST integration |
Hot take: If your targets are mostly unprotected, ScrapingBee at $49/mo gives you 250k credits - solid value with a simple dashboard. But the moment you need to scrape anything behind a WAF, that 31% success rate makes it a money pit. For protected sites, Scrapfly isn't just better. It's in a different league.
Scrapeway's per-target data makes the gap obvious. Scrapfly posts top-tier results on hard targets - Walmart at 100%, Amazon around 97% in the benchmark examples. ScrapingBee sits at the bottom of the leaderboard overall, and ScraperAPI lands in the middle at 63.7% aggregate.
Every scraping tool on this list returns raw HTML. Prospeo turns that data into pipeline. Upload your scraped domains or company names and get back verified emails (98% accuracy) and direct dials from 300M+ profiles - at $0.01 per email.
Stop scraping into spreadsheets that sit there. Turn raw data into booked meetings.
The Best Crawlbase Alternatives Compared
Scrapfly
Use this if: You're scraping protected sites and can't afford failures. Scrapfly's benchmark numbers lead the field - 98.7% success rate across all targets in the latest Scrapeway tests, processing 15B+ API requests monthly across 55,000+ developers. Plans start at $30/mo for 200k credits.
The anti-bot bypass is where Scrapfly earns its keep. While most APIs choke on Cloudflare Turnstile or DataDome challenges, Scrapfly handles them natively without you writing custom logic. For teams scraping e-commerce, real estate, or travel sites - basically anything worth scraping in 2026 - this matters more than any other feature.
Skip this if: You only scrape unprotected sites. The credit multiplier math matters here: browser rendering costs +5 credits per request, residential proxies +25. That means 1M credits on the Pro plan ($100/mo) translates to roughly 33k protected-site requests, not 1M. Still the best success rate by a wide margin, but budget accordingly.
Prospeo
Use this if: Your scraping pipeline feeds into outbound sales or lead generation. Every other tool on this list returns raw HTML. Prospeo bridges the gap between scraped data and actionable contacts - upload a CSV of scraped company names or domains, and the enrichment engine matches against 300M+ professional profiles to return verified emails (98% accuracy) and mobile numbers (125M+ verified globally, 30% pickup rate).
The enrichment API returns 50+ data points per contact at a 92% match rate: job title, seniority, department, technographics, and buyer intent signals across 15,000 topics. At roughly $0.01 per email, it's a fraction of what enterprise data vendors charge. The free tier includes 75 emails/month, enough to validate the workflow before committing.
Skip this if: You need a raw scraping API. Prospeo doesn't crawl websites - it enriches the data you've already collected with any scraping tool on this list.
Apify
Apify isn't a scraping API - it's an automation platform. The consensus on r/webscraping is that it's basically "an app store for scrapers," and that's accurate. Need to scrape Amazon product pages? There's a pre-built Actor for that. Want to monitor job postings across 50 sites? Someone's already published that workflow.
Plans start at $29/mo on a compute-unit model ($0.30/CU), with a free tier that includes $5 in compute. Residential proxies run $8/GB. It's a different mental model than a simple API call - you're orchestrating workflows, not firing off requests - but for teams running recurring scraping jobs, the scheduling and pre-built marketplace save serious development time. The tradeoff is a steeper learning curve and less predictable per-request costs.
Bright Data
Bright Data is the enterprise beast: 150M+ proxy IPs across 195 countries, serving 20,000+ organizations. The Web Scraper API starts at $4/1k requests on PAYG, with Growth plans at $499/mo.
If you're running fewer than 500k requests/month, Bright Data is overkill. But we've seen teams migrate here after outgrowing mid-tier tools, and the jump in reliability on geo-restricted targets is real. The proxy network depth alone - datacenter, residential, ISP, mobile - gives you options that smaller providers simply can't match. Expect a sales conversation and a contract.
ScrapingBee
ScrapingBee starts at $49/mo for 250k credits with 1,000 free API calls to test. The price is right for simple targets. The problem: a 31% benchmark success rate on protected sites, the lowest Scrapeway tested.
Let's be honest - for unprotected HTML pages, blog content, or public directories, ScrapingBee is perfectly fine and hard to beat on price. But if your target list includes anything behind a WAF, you'll burn through credits watching requests fail. Budget-friendly for basic scraping, unreliable for anything else. (If you're comparing options in this tier, see our breakdown of ScrapingBee alternatives.)
ZenRows
ZenRows runs $69.99/mo with a "pay only for success" model - you're not charged for failed requests. Sounds great until you learn that HTTP 404 and 410 responses still count as "successful" and consume credits. Then do the multiplier math: JS rendering (5x) plus premium proxies (10x) means protected-site requests cost 25x base rate, turning $0.28/1k into $7/1k for protected pages. The 53.8% benchmark success rate is middling. Not terrible, not great.
ScraperAPI
ScraperAPI is the "just give me a REST endpoint" option - roughly $49/mo for an entry tier. Simple to integrate, decent 63.7% success rate in benchmarks. Good for developers who want minimal setup without a full platform. It won't wow you on protected sites, but it won't frustrate you on simple ones either.
From Raw HTML to Real Contacts
Every scraping tool above gets you HTML. None of them get you the email address of the VP of Engineering at the company you just scraped. That's a different problem entirely.
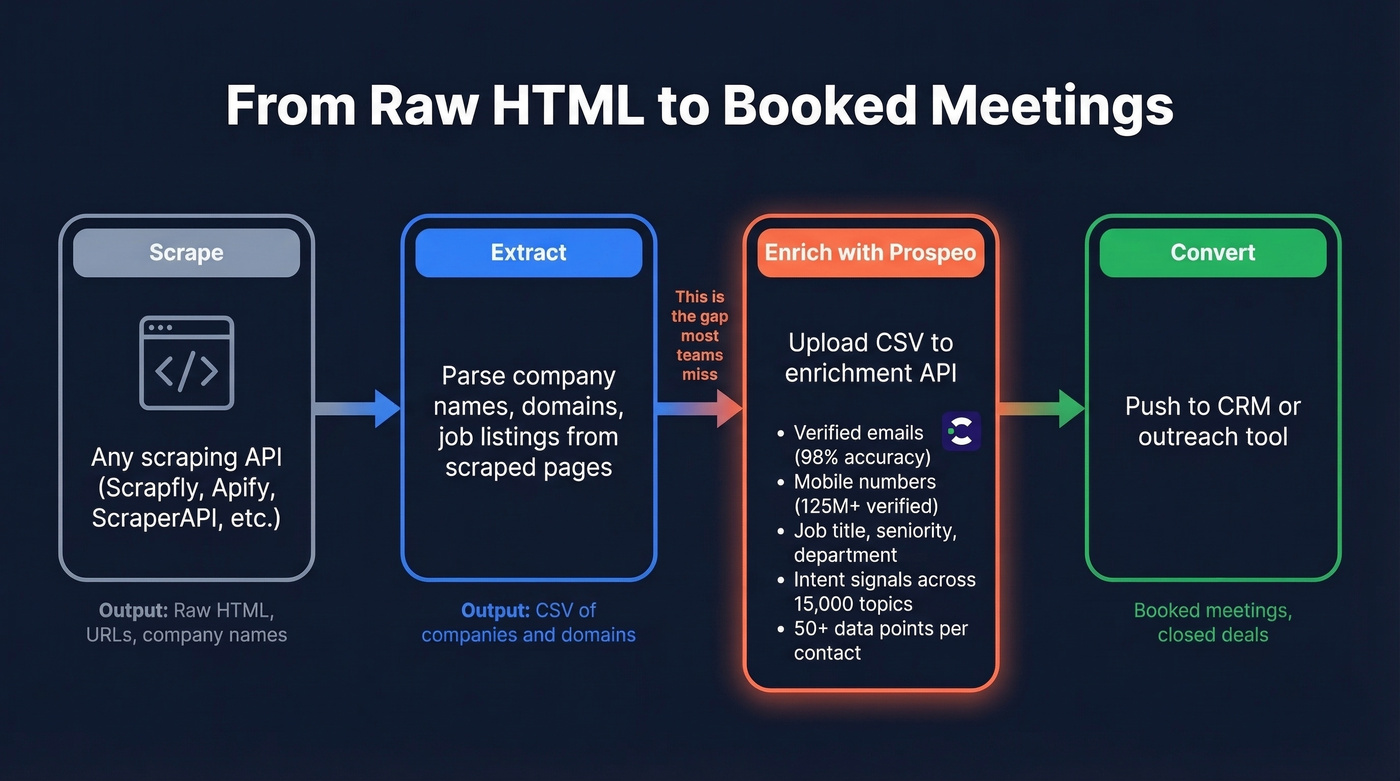
Pair any Crawlbase alternative with Prospeo's enrichment API. Feed in scraped company data, get back 50+ data points per contact at a 92% match rate - verified emails, mobile numbers, job titles, intent signals across 15,000 topics. No enterprise contract required.
Your scraping pipeline deserves a data layer that actually converts.
The Credit Multiplier Trap
When a vendor says "1 million credits," ask what that actually means for protected sites. Scrapfly's 1M credits at 30 credits per protected request (browser + residential) = ~33k real requests. ZenRows' 25x multiplier turns $0.28/1k into $7/1k. We've run the numbers across every tool here, and the pattern is consistent: always calculate your effective cost per successful protected request, not the headline credit number. That single metric is the only one that matters for budgeting.
If your end goal is pipeline, the multiplier math is only half the story: you also need a data enrichment step that turns scraped company records into usable contacts.

A quick formula: take your plan's total credits, divide by the per-request cost for your specific target type (including JS rendering and proxy multipliers), then multiply by the tool's benchmark success rate. That's your real throughput. Anything else is marketing math.
FAQ
Is Crawlbase good for scraping protected sites?
It handles basic targets but struggles with heavily protected sites behind Cloudflare or DataDome. For protected-site scraping, Scrapfly leads with a 98.7% success rate in independent Scrapeway benchmarks - roughly 3x the reliability of budget-tier APIs.
What's the cheapest alternative to Crawlbase?
ScrapingBee at $49/mo for 250k credits or Apify's free tier with $5 in compute units. Both undercut typical PAYG spend on unprotected targets. For enrichment after scraping, Prospeo's free tier includes 75 verified emails/month at no cost.
How do credit multipliers affect real scraping costs?
Most APIs charge 5-25x base credits for JavaScript rendering and residential proxies. A "$0.28/1k" rate can become $7/1k on protected pages after multipliers. Always divide your plan's total credits by the per-request cost for your specific target type to get the true price.
Can I get contact data from scraped websites?
Scraping APIs return raw HTML, not structured contact information. You need a separate enrichment step - tools like Prospeo take scraped company domains or names and return verified emails, mobile numbers, and 50+ data points per contact at roughly $0.01/email.