Deanonymization Explained: From Privacy Threat to B2B Marketing Buzzword
A RevOps lead we know spent $500-$700/month on a visitor identification tool last year. It told her which companies hit the pricing page. It didn't tell her who was browsing - and the "likely contacts" it surfaced bounced at around 30%. That gap between what tools that claim to deanonymize website visitors promise and what they actually deliver is the story of 2026.
What "Deanonymize" Actually Means
Deanonymize (verb): To reverse the anonymization of data, re-identifying individuals from datasets intended to be anonymous. In B2B marketing, it also refers to identifying anonymous website visitors at the company or contact level.
Three terms get tangled together constantly. Anonymization strips all identifying information so thoroughly that re-identification isn't reasonably possible - even with auxiliary data. Pseudonymization replaces direct identifiers like names, emails, and phone numbers with tokens or codes, but the link back to the original person still exists if you have the key. De-identification is the broader umbrella covering any technique that removes or obscures personal identifiers.
Here's the thing: most datasets that organizations call "anonymized" are really pseudonymized. The link back to real people isn't gone. It's just hidden. That distinction is exactly what makes re-identification possible.
How Deanonymization Works
The foundational insight comes from Latanya Sweeney's research: 87% of Americans can be uniquely identified using just three data points - ZIP code, date of birth, and sex. Yves-Alexandre de Montjoye later showed that just four spatio-temporal data points are enough to identify 95% of people in a mobility dataset. These are quasi-identifiers. Individually, harmless. Combined, a fingerprint.
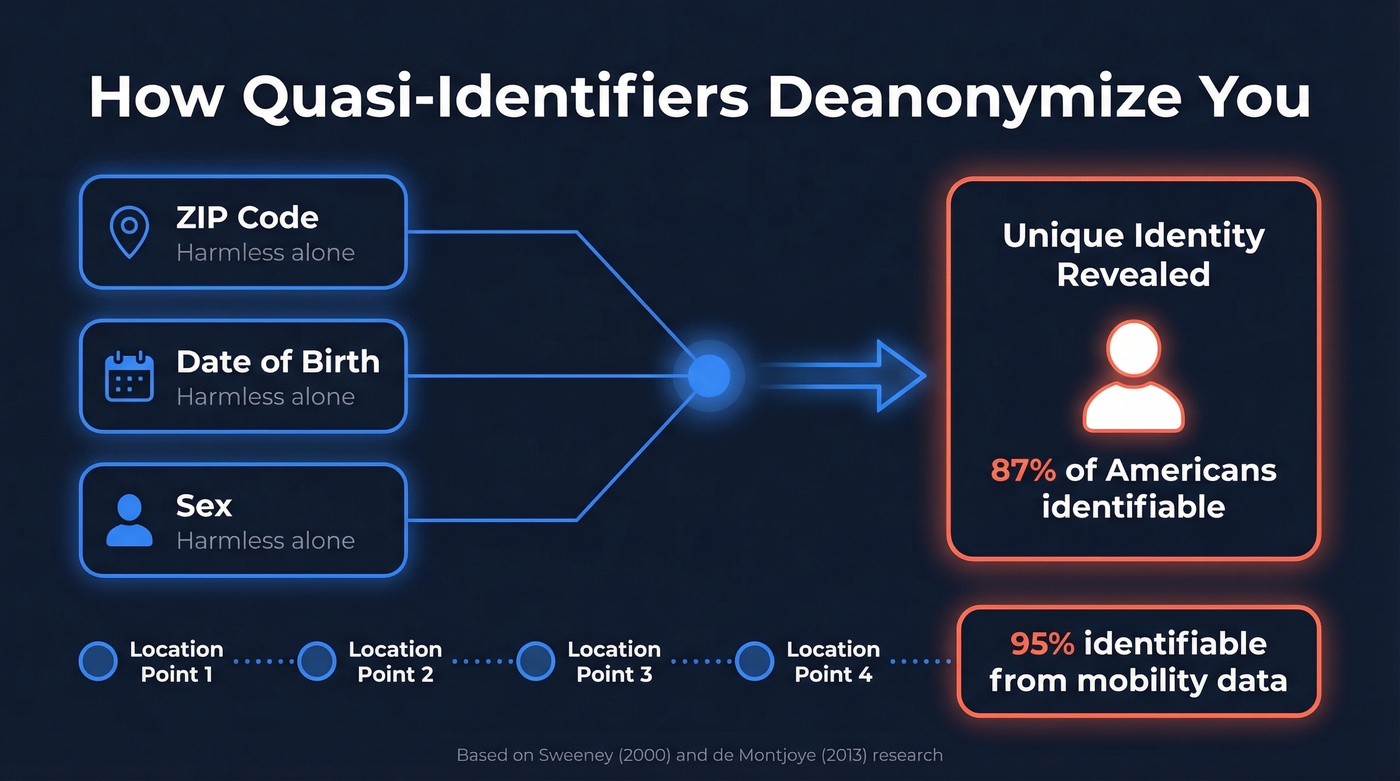
Deanonymization attacks exploit this principle through two main mechanisms. Linkage attacks cross-reference an "anonymized" dataset with external data sources to identify individuals. Attribute disclosure infers sensitive information about someone already partially identified - you don't need their name if you can figure out their medical history.
The real-world track record is sobering. In 2006, AOL released "anonymized" search logs for research purposes. Journalists identified user No. 4417749 as Thelma Arnold, a 62-year-old widow in Georgia, simply by analyzing her search patterns. The Netflix Prize dataset - 500,000 subscribers' movie ratings, stripped of names - was re-identified by researchers who cross-referenced it with public IMDb reviews. And Strava's global heatmap of exercise routes inadvertently revealed the locations and movement patterns of military personnel on classified bases.
Each incident followed the same pattern: data that looked anonymous in isolation became identifiable the moment someone combined it with another dataset. The attack surface isn't the data itself - it's the existence of other data.
AI Can Now Deanonymize You in Seconds
Everything above required human effort - hours or days of manual cross-referencing. A February 2026 paper from ETH Zurich and Anthropic changed the calculus entirely.

The researchers built an LLM pipeline that performs fully automated re-identification attacks on unstructured text at scale. It works in four stages: extract biographical and stylistic signals from a pseudonymous profile, search a candidate pool using embeddings, reason about which candidate matches, then calibrate confidence scores.
In the closed-world setting, where the real identity exists in a known candidate pool, the pipeline achieved 68% recall at 90% precision. That means it correctly identified more than two-thirds of pseudonymous accounts while being right nine times out of ten. The best non-LLM baseline scored near 0% at that same precision threshold.
The open-web agent results are arguably more alarming. Without any pre-built candidate pool, it achieved 25-67% recall with 70-90% precision on Hacker News and Reddit profiles. When linking Hacker News accounts to professional profiles specifically, the pipeline improved recall from 0.1% to 45.1% at 99% precision compared to the best traditional method.
As study author Daniel Paleka put it: if your security model assumes nobody will spend hours investigating you, "this security model is now broken." The work that took a dedicated investigator hours now takes five seconds for pennies of inference cost.
This goes beyond social media. A March 2025 paper in NPJ Digital Medicine cataloged how AI-based biometrics can infer identity from traditionally de-identified signals - ECGs, gait patterns, even typing rhythms. The attack surface now extends into biometrics, behavioral data, and any unstructured text you've ever posted online.
Visitor ID tools give you company names. You need verified contacts. Prospeo delivers 98% accurate emails and 125M+ verified mobile numbers - real people, not probabilistic guesses from IP lookups that bounce at 30%.
Skip the guesswork. Start with contacts that actually connect.
B2B Visitor Identification: What the Tools Actually Do
The B2B marketing world borrowed "deanonymize" to describe something much narrower: figuring out which companies and people visit your website. The core problem is real - prospects research solutions extensively before ever filling out a form, leaving sales teams blind to the early stages of the buying cycle.
But let's be honest about what these tools can and can't do.
How IP-to-Company Matching Works
When someone lands on your site, the only data you have is an IP address. Visitor identification tools map that IP to a company using databases of ISP IP ranges, business network datasets, browser extension data, and vendor ecosystem signals. Koala's technical guide explains that tools like Clearbit Reveal assign confidence levels - Low, Medium, High, Very High - to each match because the process is inherently probabilistic. IPs change, employees work from home, and VPNs muddy the signal.
A practical tip most vendors won't tell you: set "Very High" confidence thresholds for sales alerts and lower thresholds for marketing audience building. The same tool produces very different results depending on how you tune it.
The result is a company name, sometimes an industry, and occasionally a headquarters location. The IP tells you "someone at Acme Corp visited your pricing page." It doesn't tell you who.
Realistic Match Rates
Vendors love to report blended match rates that obscure a critical gap:

| Identification Type | Realistic Match Rate | What You Actually Get |
|---|---|---|
| Company-level (IP) | 30-65% | Company name, industry |
| Person-level (pixel) | 5-20% | "Likely contacts" - often unverified |
| Combined (vendor-reported) | 60-80% | Blended number hiding the gap |
Over 60% of knowledge workers are now remote or hybrid, which degrades IP-based identification significantly. A "match" from a home IP in suburban Denver maps to Comcast, not to the Series B SaaS company your prospect actually works at.
The Reddit consensus on tools like Warmly and RB2B reflects this reality. Practitioners report that these tools quickly identify the employer but don't identify the actual person. The "likely contacts" they surface are often just people who match the company and a job title filter - not confirmed visitors. Person-level claims from Warmly and RB2B are consistently overstated in practitioner reports.
B2B Tool Pricing
| Tool | Starting Price | Primary Method |
|---|---|---|
| Prospeo | Free-$39/mo+ | Verified contacts, ~$0.01/ea |
| Snitcher | $39/mo | IP-to-company |
| RB2B | $79/mo | Person-level |
| Koala | Free plan + paid tiers | IP-to-company + identity graph |
| Factors | $99-$499/mo | IP-to-company |
| Warmly | $700/mo+ | Person-level + enrichment |
| Demandbase | ~$18K/yr | ABM + intent + visitor ID |
| ZoomInfo | $15K+/yr | Full platform + visitor ID |
| 6sense | ~$55K/yr | ABM + intent + visitor ID |

If your average deal size is under $10K, you don't need a $15K+ visitor ID platform. Use a $39/month tool for company-level signals and spend the savings on verified contact data you can actually email.
Turn Anonymous Visitors Into Real Conversations
We see the same pattern play out over and over: a team installs a visitor ID pixel, gets excited about company-level traffic data for two weeks, then realizes they still can't email anyone. The "likely contacts" bounce. The person-level matches are sparse. And they've spent $500-$700/month learning which logos visited their blog.
The smarter workflow is to use visitor ID for company-level intent signals - which companies are researching your category - and then look up verified contacts separately. Prospeo covers 300M+ professional profiles with 143M+ verified emails at 98% accuracy, refreshed on a 7-day cycle so you're not emailing someone who changed jobs six weeks ago. Use the 30+ search filters to find the right people at the companies your visitor ID tool flagged, then export directly to Salesforce, HubSpot, Lemlist, or Instantly.
The free tier gives you 75 verified emails per month to test the workflow. Paid plans run about $0.01 per email with no contracts. Compare that to $700/month for Warmly's probabilistic guesses.
AI can now deanonymize pseudonymous profiles in seconds. But you don't need an LLM pipeline to find your buyers - Prospeo's 300M+ verified profiles with 30+ filters let you reach decision-makers directly at $0.01 per email, no reverse-engineering required.
Find real buyers without reverse-engineering anonymous traffic.
How to Defend Against Deanonymization
For Individuals
The most common opsec mistakes are embarrassingly simple. Linking a social media account to your phone number defeats Tor entirely - the phone number is the identifier, not the IP. Cookies persist across sessions, so clearing your IP via VPN while keeping the same browser profile accomplishes nothing. Metadata in files - EXIF data in photos, author fields in documents - is another common leak. Clean metadata before sharing anything you want to keep anonymous.

VPNs aren't anonymity tools. They're privacy tools, and there's a real difference. Your VPN provider can log your traffic, and the honest ones will tell you that.
Look, if a motivated adversary with LLM access wants to identify your pseudonymous account, the bar is now very low. Writing style, topic interests, and biographical details in your posts are enough.
For Organizations
Differential privacy remains the gold standard for protecting datasets. You add mathematically controlled noise to query results so that the inclusion or removal of any single person doesn't materially change the output. Apple and Google use differential privacy in their telemetry systems.
K-anonymity - ensuring each record is indistinguishable from at least k-1 others - sounds good in theory but fails in practice. Researchers re-identified 3 students from a k-anonymized Harvard/MIT edX dataset by cross-referencing it with public professional profiles.
Synthetic data is the emerging defense: generate statistically equivalent datasets that preserve patterns without containing any real individuals. It's not perfect - membership inference attacks can still sometimes detect whether a real person's data influenced the synthetic output - but it's the most promising direction for sharing research data safely.
Test your anonymization against realistic attacks before publishing. If an LLM agent can re-identify people in your dataset in five seconds, your anonymization isn't anonymization.
Legal Framework: GDPR, CCPA, and the Anonymization Myth
Under GDPR, anonymization is binary. Recital 26 establishes a "reasonably likely" test: if re-identification is reasonably possible considering available technology, time, resources, and foreseeable advances, the data is still personal data. There's no "mostly anonymous" category. It's either anonymous and outside GDPR's scope entirely, or it's personal data subject to the full regulation.
Pseudonymized data is explicitly still personal data under GDPR. This matters because most datasets labeled "anonymized" are really pseudonymized, and the 2026 LLM research makes this distinction even more critical: what was "not reasonably likely" to be re-identified in 2023 is now trivially re-identifiable for pennies.
On the US side, CPRA applies to businesses with $25M+ revenue, those processing data on 100,000+ consumers, or companies deriving 50%+ of revenue from selling or sharing personal data. CPRA's de-identification standard requires that data "cannot reasonably identify" an individual, plus operational safeguards - contractual restrictions on re-identification, technical controls, and ongoing monitoring.
We've seen organizations treat anonymization as a one-time checkbox. It isn't. As attack capabilities improve - and LLMs represent a step function, not an incremental improvement - the "reasonably likely" threshold shifts. Data that passed muster in 2024 won't necessarily hold up today.
FAQ
Is deanonymization legal?
It depends entirely on context and jurisdiction. Academic research and law enforcement use is generally permitted. Commercial re-identification of anonymized datasets can violate GDPR and several US state laws. B2B visitor identification is legal when limited to company-level data with proper cookie consent - person-level tracking without consent is where legal risk escalates.
Can AI deanonymize you from your writing style?
Yes. The 2026 ETH Zurich study showed LLMs can match pseudonymous accounts to real identities using writing patterns, topic interests, and biographical details - achieving 68% recall at 90% precision. Traditional stylometry methods scored near 0% at the same precision threshold. If you've posted extensively under a pseudonym, assume it's linkable.
What's the best defense against data re-identification?
Differential privacy is the current gold standard - it adds mathematically controlled noise so no single individual's inclusion changes query results. Synthetic data generation is the most promising emerging approach. K-anonymity alone has been repeatedly broken in practice. Test any anonymization scheme against LLM-powered attacks before publishing.
Why does the anonymous buying journey matter for B2B teams?
B2B buyers complete 60-70% of their evaluation before ever contacting sales. During this anonymous phase, prospects visit your site, read comparison pages, and check pricing - all without identifying themselves. Visitor identification tools exist to surface these hidden intent signals so sales teams can engage accounts while interest is high rather than waiting for a form fill that never comes.