How to Build a Lead Scoring Framework That Sales Won't Ignore
A founder we know built a 100-point scoring model in HubSpot. Whitepaper downloads, pricing page visits, case study clicks - the whole playbook.
His biggest deal that quarter, a $20K ARR contract, came from a lead that scored 12 out of 100. The lead scoring 89? A grad student researching a thesis. After scrapping the model and qualifying manually on three questions - problem, budget, decision-maker - his close rate tripled.
That's not an edge case. That's the default outcome of every lead scoring framework built around engagement instead of buying intent.
Why Most Scoring Models Fail
The core problem is single-axis scoring. When you dump firmographic fit and behavioral signals into one number, a student who downloads five whitepapers outranks a VP who visits your pricing page once and books a demo. The model measures curiosity, not purchase intent, and it teaches reps to ignore the score because it keeps being wrong in the same predictable ways.
A scoring model is a contract between Sales and Marketing. If Sales didn't co-sign it, it's not a contract - it's a suggestion. And suggestions get ignored.
We've watched this play out dozens of times: Marketing ships a model in isolation, reps glance at it for a week, then go back to gut instinct because at least their gut doesn't pretend to be math. As one RevOps practitioner put it on r/hubspot: "If your best customers score 12 and students score 95, the model is measuring the wrong thing."
Two structural flaws kill models repeatedly:
First, no feedback loop. Scoring degrades the moment you ship it. Without quarterly recalibration against closed-won data, thresholds drift, your MQL bucket fills with junk, and Sales starts treating "MQL" as a polite synonym for "not my problem."
Second, overweighting noise signals. Email opens are a mess, and a lot of "activity" isn't a human at all - bot traffic is a real chunk of the web, and many email clients preload images whether the message gets read or not.
And one rule we feel strongly about: demo requests should never be gated behind a score threshold. If someone asks to talk to Sales, route them immediately. Full stop.
Two-Axis Scoring: Fit + Intent
Here's the thing: you need two separate scores, not one.
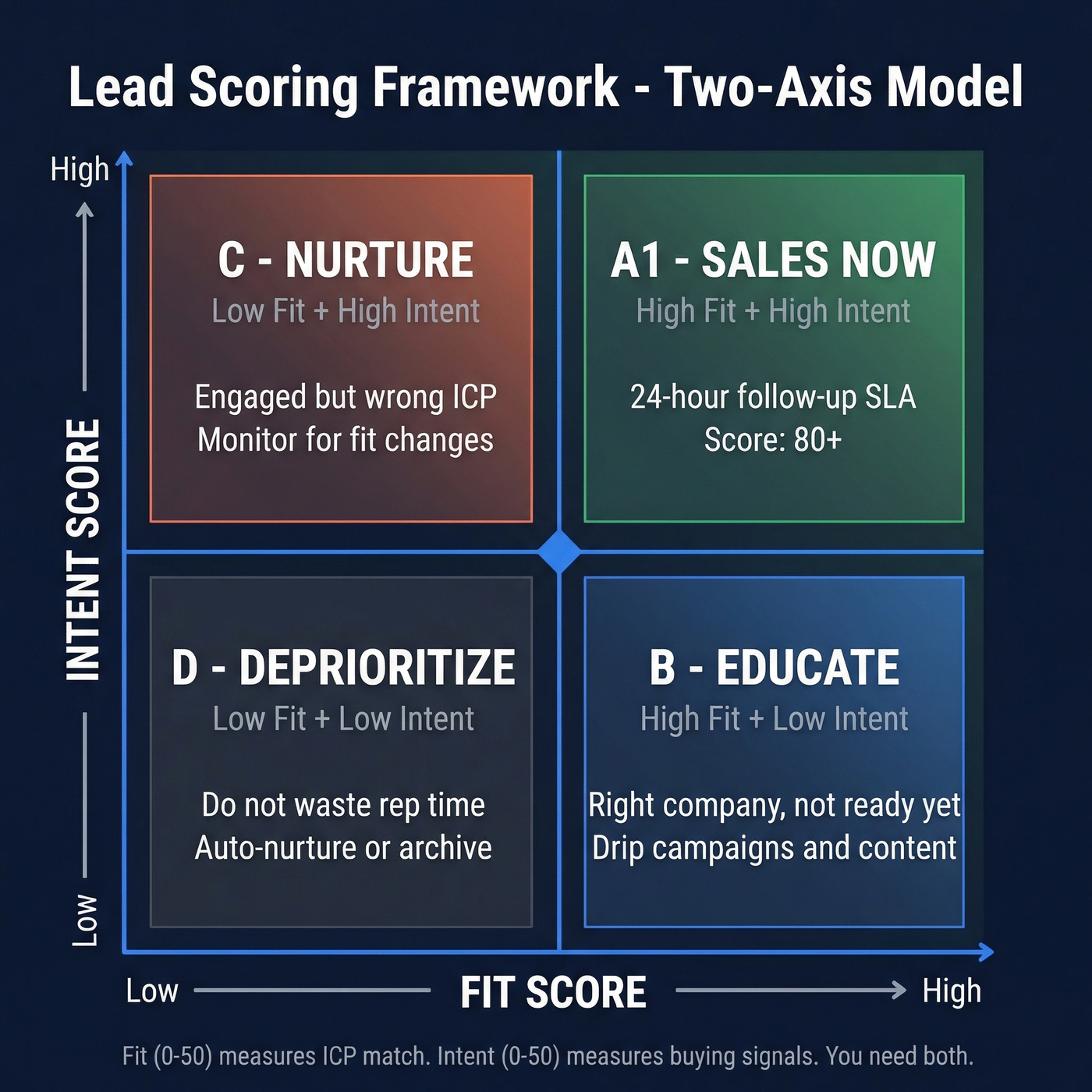
- Fit (0-50) measures whether this person matches your ICP.
- Intent (0-50) measures whether they're actively buying.
A lead needs both to be worth a rep's time. This is the simplest way to stop "high engagement" from masquerading as "high intent."
Most guides show a 2x2 grid and call it a day. Let's break this down into point values you can actually start with, then tune using your own closed-won data.
Starter point values (copy/paste)
Fit scoring works best with hard gates for non-negotiables. If the company doesn't match your firmographic size range, cap their total Fit score at 10 no matter how perfect the title looks. Intent scoring should weight actions by purchase signal strength, with recency baked in.

| Signal | Category | Points | Notes |
|---|---|---|---|
| ICP company size | Fit | +15 | No match -> cap Fit at 10 |
| Decision-maker title | Fit | +15 | VP/C-level/Director |
| Target industry | Fit | +10 | Based on closed-won patterns |
| Revenue in range | Fit | +10 | Use enrichment to fill gaps |
| Demo request | Intent | +20 | Route immediately |
| Pricing page visit | Intent | +10 | High-intent page |
| Trial signup | Intent | +15 | Product engagement |
| 3+ stakeholders engaged | Intent | +10 | Multi-threading signal |
| 3+ nurture opens | Intent | +5 | Weak signal - don't overweight |
| Personal email | Negative | -15 | Gmail, Yahoo, Hotmail |
| Competitor domain | Negative | -50 | Disqualify |
| Careers page visit | Negative | -10 | Job seeker signal |
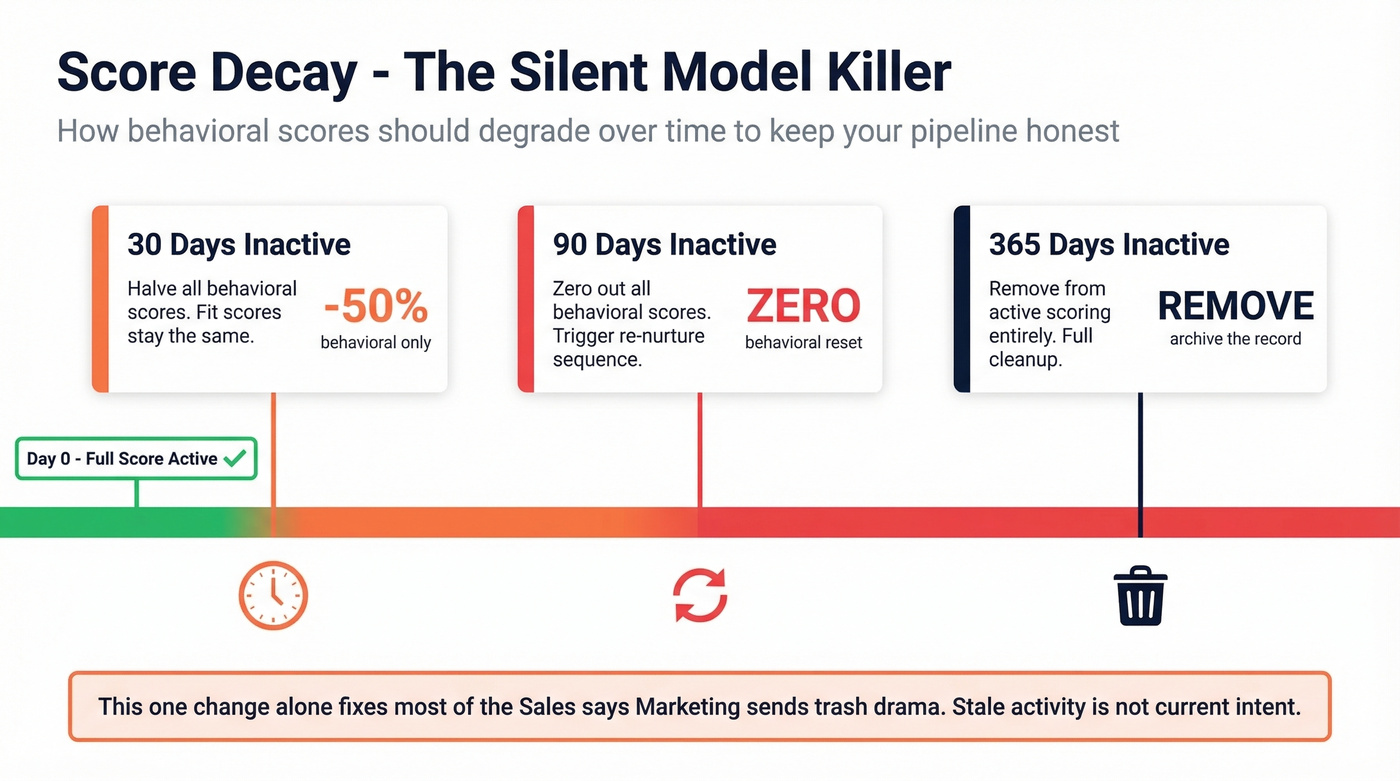
| 30 days inactive | Decay | -50% behavioral | Recency matters |
| 90 days inactive | Decay | Zero behavioral | Reset and re-nurture |
| 365 days inactive | Decay | Remove from scoring | Full cleanup |
Start with MQL at 60+ combined and SQL at 80+ combined, then adjust quarterly based on conversion data. Don't argue about the "right" threshold in a meeting. Put it in production, measure it, and change it with evidence.
Data quality comes first (or your Fit score is fiction)
Your scoring matrix is only as good as the data underneath it. If firmographic fields are empty - and in most CRMs, they are - Fit scoring turns into educated guessing, and educated guessing doesn't scale past the first couple of reps.
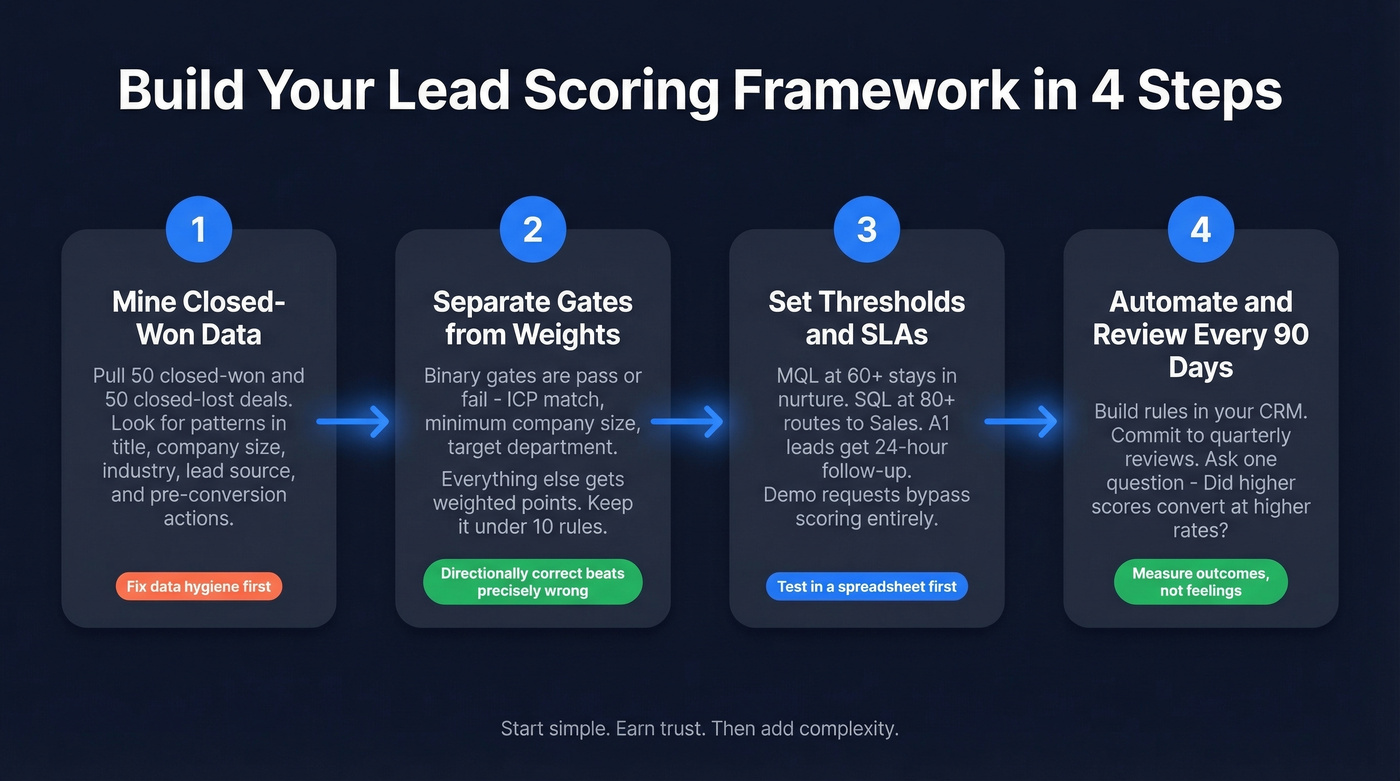
Build Your Framework in 4 Steps
Step 1: Mine closed-won (and closed-lost)
Pull your last 50 closed-won and 50 closed-lost deals. You're looking for patterns in title, company size, industry, lead source, and the actions that happened before conversion.
This is also where the ugly stuff shows up. If half your records are missing industry or revenue, you don't have a scoring problem yet - you have a data hygiene problem, and scoring will only hide it for a month or two.
Step 2: Separate gates from weights
Binary gates are pass/fail: ICP match, minimum company size, target department, country coverage. Everything else gets weighted points.
Real talk: directionally correct beats precisely wrong. A model with eight clear rules that reps understand will outperform a model with 60 rules that nobody trusts.
Step 3: Set thresholds and SLAs people can live with
- MQL 60+: stays in nurture unless it hits an SQL trigger.
- SQL 80+: routes to Sales.
- A1 leads (high fit, high intent): 24-hour follow-up SLA.
- Demo requests: bypass scoring entirely.
For testing, a spreadsheet is fine. This Google Sheets template is a good starting point, and it keeps the conversation grounded because everyone can see the math.
One detail teams forget: stitch anonymous browsing behavior to known profiles after form fill. If you don't, you lose the early intent context that often matters most (pricing page, integration docs, security page, and so on).
Step 4: Automate, then review every 90 days
Build the rules in your CRM scoring tool and commit to a 90-day review cadence. HubSpot's overview of how scoring works is a solid reference for implementation details: HubSpot lead scoring tool docs.
When you review, don't just ask "Did MQLs go up?" Ask the only question that matters: "Did higher scores convert at higher rates?"
Your Fit score is fiction if half your CRM records are missing industry, revenue, and company size. Prospeo enriches contacts with 50+ data points at a 92% match rate - so your scoring model scores real attributes, not empty fields.
Stop scoring leads against data you don't have.
Mistakes That Quietly Kill Your Model
The most common failure we see isn't a bad rule - it's too many rules. Teams spend months building elaborate 100-point models that reps bypass within a week because nobody can explain what the score means, where it comes from, or what to do with it in the next 10 minutes of their day.
Start with fewer than 10 rules. Earn trust first. Then add nuance.
Score decay is the second silent killer. A lead who was active six months ago isn't active now, but their score says otherwise. Halve behavioral scores at 30 days, zero them at 90, and remove leads from active scoring entirely at 365 days. That one change alone fixes a shocking amount of "Sales says Marketing sends trash" drama, because you're no longer treating stale activity like current intent.
Don't run multiple competing models, either. One scalable model, reviewed quarterly, beats three "experimental" models that confuse everyone and create loopholes for cherry-picking.
And yes, bots and spam happen. When you find fake leads, reset their scores to zero rather than permanently disqualifying them. People change jobs, old emails get reused, and sometimes a real buyer looks weird on day one.
Hot take: If your average contract value is under $10K annually, you probably don't need a scoring model at all. Three qualifying questions on a form and a 24-hour SLA on demo requests will outperform any algorithm at that scale.
When to Go Predictive
Rules-based scoring works until you outgrow it.
HubSpot's predictive scoring needs real volume to behave. One practical benchmark: at least 1,000 contacts and 100 closed deals before you expect stable output. Below that, rules-based scoring wins because you can see exactly why a lead got a score, and you can fix it without retraining anything.
Once you do have enough data, predictive models can be genuinely useful. A peer-reviewed study on B2B CRM classification tested 15 algorithms and found Gradient Boosting performed best on accuracy and ROC AUC. The most predictive features were refreshingly unsexy: lead source and lead status beat a lot of exotic behavioral signals.
Pricing and tooling matter here, too. HubSpot Professional (often around $890/month) covers manual scoring for many teams, while Enterprise (often around $3,600/month plus onboarding) is where predictive features typically show up. Salesforce also supports lead scoring workflows, and their overview is worth reading if you're in that ecosystem: Salesforce on lead scoring.
If you want to add intent signals without signing a separate enterprise intent contract, Prospeo includes intent data across 15,000 topics powered by Bombora, which you can layer into your Intent score alongside your first-party behavior.
A lead scoring framework built on stale data decays faster than your 90-day review cycle can catch. Prospeo refreshes every record every 7 days - not the 6-week industry average - so your Fit and Intent scores reflect reality, not last quarter's org chart.
Fresh data every 7 days means your scores actually mean something.
Measuring If Your Lead Scoring Framework Works
Track outcomes, not feelings.

Start with MQL -> SQL conversion and SQL -> close rate, then segment by score band. This RevOps playbook has a practical set of benchmarks and definitions you can use to sanity-check your funnel: RevOps lead scoring playbook.
As rough ranges: 25-35% MQL -> SQL is common, and 40-50% usually means Sales and Marketing are actually working the same plan. Win rates often land 20-30% overall, with top-scored leads pushing 30-45% if your model's doing its job.
A simple quarterly test: pull your highest-scored leads from last quarter and compare them to closed-won outcomes. If the correlation drifted, rerun the 50/50 analysis and adjust weights. Don't be precious about the original model. The market changes, your messaging changes, your ICP tightens, and your scoring has to keep up.
FAQ
What's a good MQL threshold for scoring?
Start at 60 out of 100 combined Fit + Intent. If Sales complains about lead quality, raise it to 70. If pipeline's thin, lower it to 50.
Review quarterly against your SQL conversion rate. The right number is wherever conversion stabilizes above 25% without starving the team.
How often should we recalibrate our model?
Quarterly at minimum, using your latest closed-won and closed-lost data.
Warning signs it's overdue: reps are ignoring MQLs, or your SQL -> close rate dropped 10%+ from baseline.
Do we need intent data for lead scoring?
Not at first. A solid Fit + behavior model built from your own CRM data beats a sloppy intent layer every time.
Add intent once your basics are stable and your routing is disciplined. Then it becomes a force multiplier instead of another dashboard nobody trusts.
Can we build a scoring model in a spreadsheet?
Yes, and you should start there. A Google Sheets model with 8-10 rules lets you test thresholds against real deals before committing to CRM automation.
Skip this if you're already at high volume with clean data and a dedicated RevOps owner who can maintain the model weekly. Otherwise, the spreadsheet phase saves you from rebuilding everything 90 days later.