Behavior Scoring Done Right: From First Model to Quarterly Recalibration
Your best customer last quarter - the one who closed in 11 days and expanded twice - scored a 12 in your marketing automation platform. Meanwhile, a grad student downloading every whitepaper you've ever published hit 87. Only 27% of leads marketing sends to sales are actually qualified. That gap between score and reality is where behavior scoring either earns its keep or becomes another dashboard nobody trusts.
The problem isn't the concept. Tracking what prospects do and assigning weight to those actions is sound logic. The problem is execution: arbitrary points, zero decay, no sales input, and models built on data that was stale before the first rule fired.
What Is Behavior Scoring?
Behavior scoring assigns numerical values to prospect actions - page visits, content downloads, demo requests, email clicks - to measure buying readiness. It's the engagement layer of lead scoring, focused on what people do rather than who they are. Fit scoring handles the demographic and firmographic side, and we'll separate the two shortly.
Quick disambiguation: "behavior scoring" means different things in different industries. In consumer credit, teams build credit-risk models to predict repayment likelihood - TransUnion's Q3 2025 data shows 40.9% of consumers now sit in the super-prime tier. In product design, it tracks feature adoption. This guide is about B2B marketing and sales: using behavioral data to prioritize leads and route them to the right team at the right time.
As of early 2026, the lead scoring market has passed $2.23B and is growing at 11.4% CAGR. A lot of that budget goes to models that never get recalibrated. Let's build one worth maintaining.
The Playbook in Six Moves
Before the full methodology, here's the short version:

- Separate fit scoring from engagement scoring. Two layers, not one tangled mess.
- Start with 5-7 criteria validated against your last 50 closed-won deals.
- Set three thresholds: route to sales (40+), nurture (15-39), top-of-funnel (<15).
- Add 30-day decay. Scores without expiration dates are fiction.
- Launch in two weeks, tune after 45 days. Perfection is the enemy of pipeline.
- Don't score email opens. And if someone requests a demo, skip the score entirely - send them to sales immediately.
The prerequisite for all of this? Clean contact data. Scoring ghosts in your CRM is worse than not scoring at all.
Why Most Scoring Models Fail
Across B2B teams, the same five anti-patterns show up over and over.

1. Arbitrary point values. The consensus on r/digital_marketing is blunt: systems like "opened email = 5 points" are completely made up and rarely correlate with buying readiness. Patterns of engagement over time matter, not isolated actions with invented weights.
2. Students outscoring buyers. A researcher downloading every asset on your site will outscore the VP who visits your pricing page and books a demo. If your model rewards volume over quality of intent, your scores are broken by design.
3. Scoring email opens. Bot clicks, auto-previewing clients, and Apple Mail Privacy Protection make open data unreliable. Assign email opens zero points. Full stop.
4. Set-and-forget decay. Your ICP shifts, buying committees evolve, and channels change. A scoring model built in Q1 that hasn't been touched by Q4 is measuring a market that no longer exists. Even teams using modern scoring tools feel like they're starting from zero every time they rebuild - usually because the previous version was never maintained.
5. Sales wasn't in the room. Marketing builds the model alone, sales doesn't trust the output, and MQLs pile up unworked. Here's the thing: scoring without sales alignment is an exercise in self-congratulation.
How to Build a Scoring Model
Separate Fit From Behavior
Run two scoring layers in parallel. Fit scoring evaluates who the prospect is - title, company size, industry, tech stack. Behavioral scoring evaluates what they've done - pages visited, content consumed, forms submitted.
Use binary disqualifiers for ICP mismatch. If someone's in an industry you don't serve or has a title that never buys, no amount of engagement should push them to sales. A student with a 90 engagement score and a failing fit grade stays in nurture. A VP with a 15 engagement score and a perfect fit grade gets a different workflow entirely.
Validate With Closed-Won Data
Pull your last 50 closed-won and 50 closed-lost deals. Map the engagement patterns: which pages did closed-won contacts visit before converting? How many touchpoints? What was the time between first touch and demo request?
Weight intent signals above vanity engagement. Pricing page visits, trial signups, multi-stakeholder engagement from the same account, and technical documentation views are stronger predictors than blog reads or social clicks. Your historical data tells you which behavioral signals actually matter - don't guess.
Example Point Values
We've tested variations of this framework across multiple campaigns, and this starter model combining practitioner recommendations with real-world calibration holds up well:
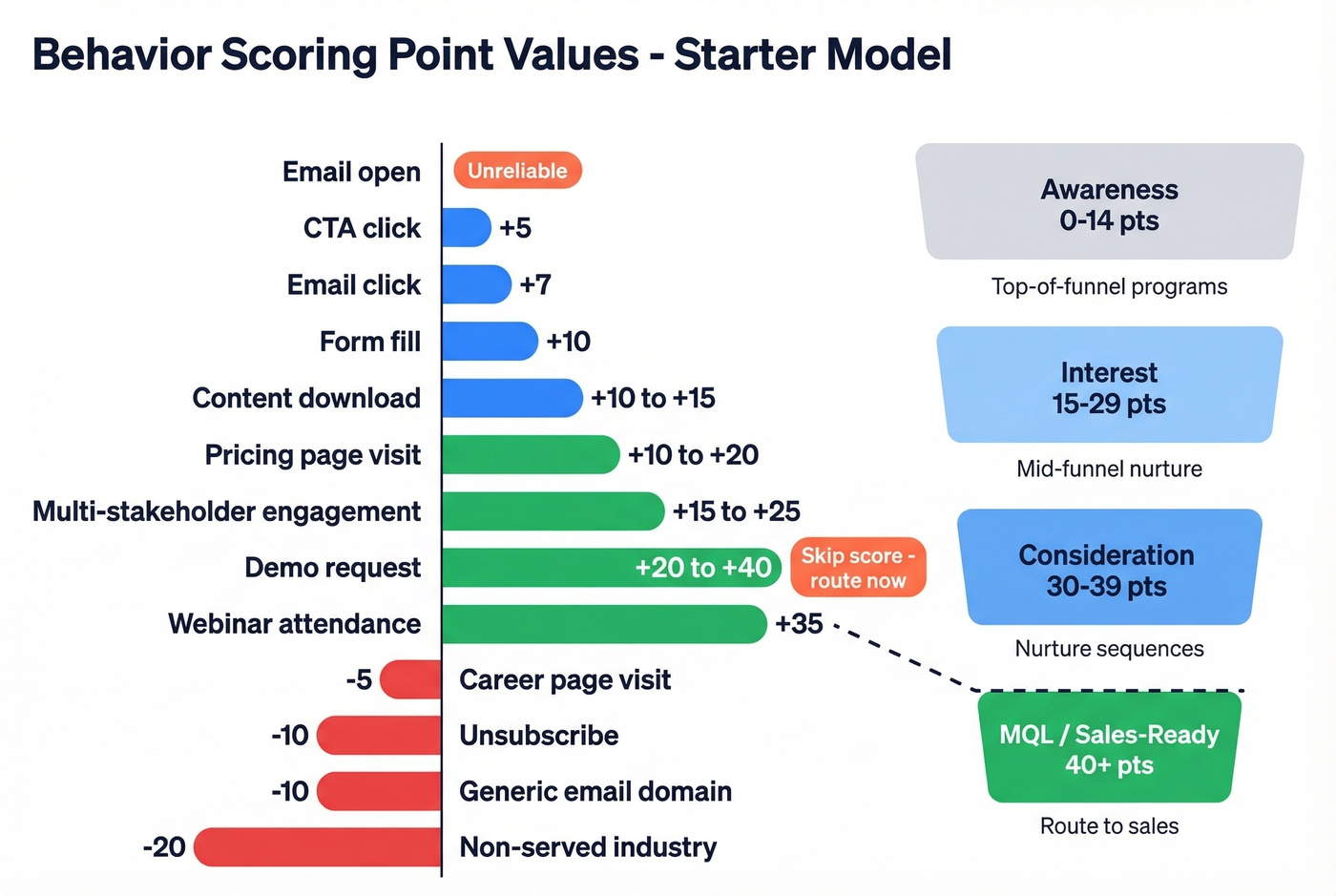
| Action | Points | Rationale |
|---|---|---|
| Email open | 0 | Unreliable signal |
| Email click | +7 | Active engagement |
| CTA click | +5 | Mid-funnel interest |
| Form fill | +10 | Deliberate action |
| Content download | +10 to +15 | Depth of interest |
| Pricing page visit | +10 to +20 | High intent |
| Multi-stakeholder engagement (same account) | +15 to +25 | Account-level buying signal |
| Demo request | +20 to +40 | Skip score - route now |
| Webinar attendance | +35 | Time investment |
| Unsubscribe | -10 | Disengagement |
| Career page visit | -5 | Wrong intent |
| Generic email domain | -10 | Low fit signal |
| Non-served industry | -20 | Disqualifier |
Map these to funnel bands: Awareness (0-14), Interest (15-29), Consideration (30-39), MQL/Sales-ready (40+). Negative scoring is just as important as positive - it keeps noise out of your pipeline.
Set Thresholds and Decay
Three thresholds keep routing simple. Leads scoring 40+ go to sales. Leads between 15 and 39 enter mid-funnel nurture. Below 15, they stay in top-of-funnel programs.
Decay is non-negotiable. Reduce scores by 25% monthly for contacts with no new activity. Tie your rolling scoring window to your average sales cycle - if deals typically close in 90 days, score actions within that window and let older signals fade. The goal is to capture the top 20% of leads as MQLs, not inflate your pipeline with stale records.
Your scoring model is only as good as the data underneath it. Scoring ghosts and outdated contacts inflates your pipeline with noise - the exact anti-pattern this article warns against. Prospeo refreshes 300M+ profiles every 7 days and delivers 98% email accuracy, so every point you assign maps to a real, reachable buyer.
Stop scoring dead leads. Start with data that's verified this week.
Rules-Based vs. Predictive Scoring
| Dimension | Rules-Based | Predictive (ML) |
|---|---|---|
| Data inputs | 5-10 attributes | Hundreds of signals |
| Setup | Manual rules | ML model training |
| Maintenance | Static, degrades | Dynamic, improves |
| Minimum data | Any CRM history | ~1,000 converted leads |
| Cost entry point | ~$890/mo (HubSpot Pro) | HubSpot Enterprise starts at ~$3,600/mo+ |

ML-powered scoring delivers 75% higher conversion rates than rules-based models in ideal conditions. But "ideal conditions" is doing a lot of heavy lifting in that sentence.
For most teams under 5,000 leads per quarter, rules-based scoring done well outperforms a poorly configured ML model. If you don't have 1,000+ converted leads for the algorithm to learn from, clean CRM data, and budget for Enterprise-tier tools, start with rules. You can always upgrade later. Skip predictive scoring if your CRM data is messy and your converted-lead count is in the hundreds - you'll spend more time debugging the model than benefiting from it.
Tools and Pricing
| Platform | Scoring Type | Price | Notes |
|---|---|---|---|
| HubSpot Pro | Rule-based | $890/mo (3 seats) | Fastest time-to-value |
| HubSpot Enterprise | Predictive | $3,600/mo (10-seat min) + $3,500 onboarding | Best for scaling teams |
| Salesforce Einstein | Predictive | $165/user/mo + $50/user AI add-on | 10 users = $40K+/yr |
| 6sense | Predictive + intent | $60K-$300K/yr | Enterprise only |
| Marketo Engage | Rule-based + advanced | ~$1,500-$3,000/mo | Best SFDC campaign sync |
| Pardot (Account Engagement) | Rule-based + grading | Custom pricing | Native but rigid |
The decision framework is straightforward. HubSpot Professional if you don't have dedicated marketing ops - it's the fastest path to a working model. Marketo if you're enterprise-scale with a dedicated ops team and need tight Salesforce campaign alignment. Pardot if you're already deep in the Salesforce ecosystem and want native scoring plus grading without another vendor.
The tool matters less than the methodology. A $890/mo HubSpot Pro instance with a well-calibrated rules-based model will outperform a $300K 6sense deployment where nobody agreed on what "qualified" means.
Data Quality: The Real Foundation
Look, your scoring model is only as accurate as the contact data feeding it. If 35% of your emails bounce, you aren't scoring prospects - you're scoring ghosts. Every point you assign to a bounced email address or an outdated job title is noise that erodes sales trust in the entire system, and once that trust is gone, it's brutally hard to rebuild.
If you're seeing bounces, start by measuring your email bounce rate and fixing the root causes before you touch scoring weights.

In our experience, this is the single most overlooked factor in scoring accuracy. One of our customers, Meritt, was running a 35% bounce rate before cleaning up their data pipeline. After switching to verified data with Prospeo, bounces dropped under 4% and their pipeline tripled from $100K to $300K per week. The scoring model didn't change - the data underneath it did.
When you're scoring a pricing page visit, you want to know the person behind that visit still works at the company, still holds the title, and still has a valid email. A 7-day data refresh cycle and 98% email accuracy make that possible. Stale data on a 6-week refresh cycle doesn't.
Multi-stakeholder engagement is one of the strongest buying signals in your scoring model - but only if you can actually identify every contact at the account. Prospeo's 30+ search filters let you map entire buying committees by title, department, and intent signals across 15,000 Bombora topics, at roughly $0.01 per verified email.
Find the full buying committee before your competitor scores a single lead.
Launch, Measure, Recalibrate
Don't wait for perfection. This cadence works:
- Verify your contact database first. Run your list through a verification tool before activating any scoring rules. Bad data in means bad scores out. (If you need options, compare data enrichment services and verification workflows.)
- Launch your v1 model within two weeks. Five to seven criteria, three thresholds, basic decay. Ship it.
- Run for 30-45 days without changing anything. Collect conversion data. Let the model breathe.
- Review with sales and marketing together. Which MQLs converted? Which ones were junk? Adjust point values and thresholds based on actual outcomes, not opinions. Compare prospect scores against closed-won data to see where the model over- or under-weighted actions.
- Recalibrate quarterly. Marketing Ops owns the setup, decay rules, and weighting. Sales provides the feedback loop. Neither team operates in isolation.
The benchmarks to track: MQL-to-SQL conversion should land between 25-35% for typical teams and 40-50% for high-alignment orgs. Win rates run 20-30% overall, with top-score leads converting at 30-45%. Teams using scoring see 138% ROI versus 78% without. The gap isn't the model - it's the discipline to maintain it.
If you want a baseline for what “good” looks like, use current average B2B lead conversion rate benchmarks to sanity-check your funnel.
FAQ
What's the difference between behavior scoring and lead scoring?
Lead scoring is the umbrella covering both fit and behavior. Behavior scoring is the engagement layer - it tracks what prospects do (page visits, downloads, demo requests) rather than who they are (title, industry, company size). Run both layers in parallel for the best results.
How often should I recalibrate my scoring model?
Quarterly at minimum. Pull conversion data, get direct feedback from sales on MQL quality, and adjust point values and thresholds. Models that aren't recalibrated degrade within two to three quarters as engagement patterns drift away from actual buying signals.
Should I score email opens?
No. Bot clicks, auto-previewing email clients, and Apple Mail Privacy Protection make open data unreliable. Score clicks, form fills, pricing page visits, and demo requests - actions requiring deliberate engagement.
When should I switch from rules-based to predictive scoring?
When you have 1,000+ converted leads, clean CRM data, and budget for Enterprise-tier tools like HubSpot Enterprise at $3,600+/mo or Salesforce Einstein at $40K+/yr. Until then, a well-maintained rules-based model outperforms a poorly trained ML model every time.
How does data quality affect scoring accuracy?
Directly - and more than most teams realize. If emails bounce or contacts have outdated titles, you're scoring records that'll never convert. Meritt cut their bounce rate from 35% to under 4% with verified data and tripled pipeline without changing a single scoring rule. The model was fine. The data wasn't.