How to Build a Data Enablement Strategy That Doesn't Die in Committee
Poor data quality costs the average organization at least $12.9 million per year. That's a Gartner number - and over a quarter of organizations estimate losses exceeding $5 million annually, with 7% reporting losses above $25 million. Meanwhile, your CEO is in the quarterly review asking why nobody trusts the dashboards, and the data team is buried in Slack threads trying to figure out which pipeline broke overnight.
The gap between "we have data" and "we can actually use data" is what a data enablement strategy is supposed to close. Most programs don't. Here's how to build one that does.
What You Need (Quick Version)
Data enablement has three non-negotiables: ownership, SLAs, and a catalog. Most programs fail because they buy a $100k tool before defining who owns what. Start with your top 10 data assets this quarter, assign owners, and pick a catalog you can deploy in weeks, not months. Everything else is iteration.
What Data Enablement Actually Means
IBM frames data enablement as delivering the right data to the right resource at the right time. Sounds simple. It isn't - because most organizations can barely tell you where their data lives, let alone whether it's trustworthy.
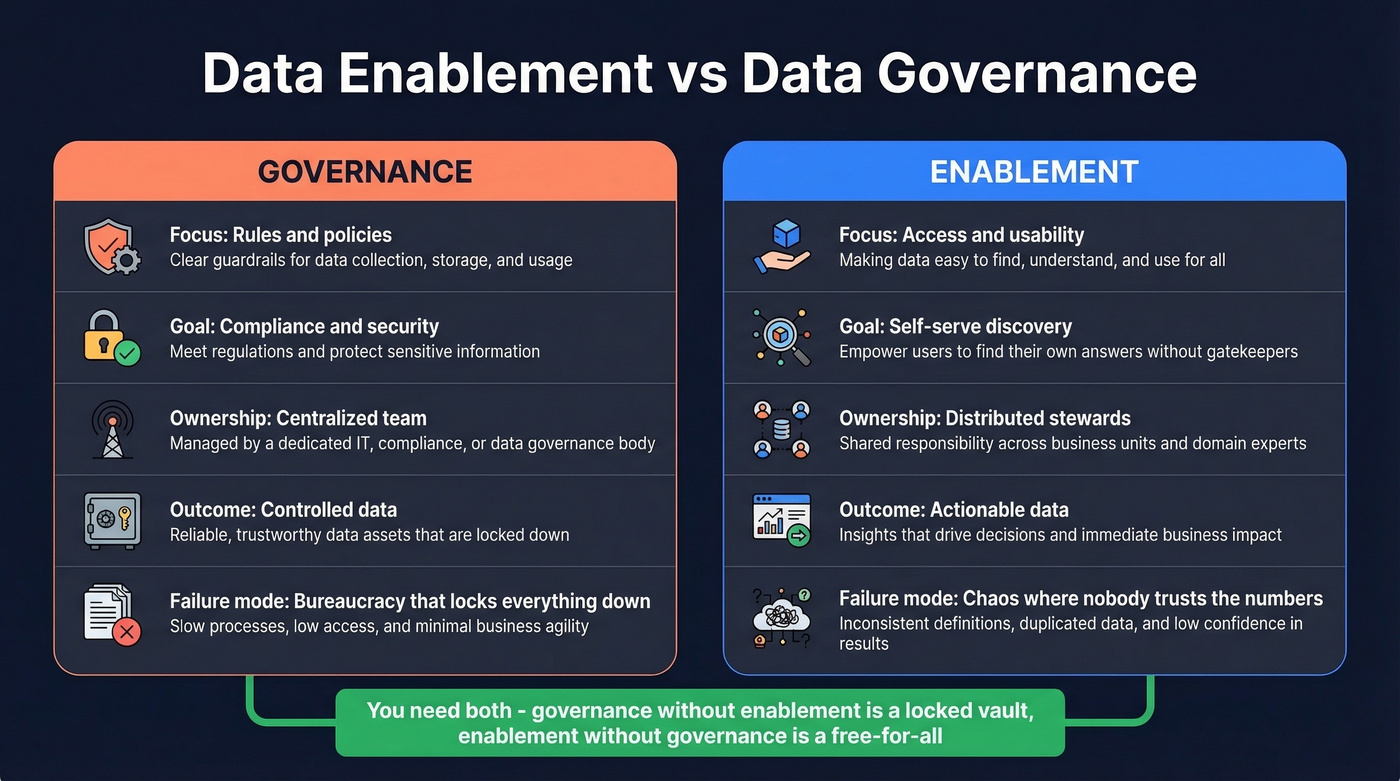
In practice, data enablement is the discipline of making data accessible, usable, and reliable across an organization so people can find and act on it without filing a Jira ticket. The confusion usually starts with governance, because enablement and governance aren't the same thing - they're complementary layers of the same operating model.
| Governance | Enablement | |
|---|---|---|
| Focus | Rules and policies | Access and usability |
| Goal | Compliance, security | Self-serve discovery |
| Ownership | Centralized team | Distributed stewards |
| Outcome | Controlled data | Actionable data |
| Failure mode | Bureaucracy | Chaos |
Governance without enablement creates a locked vault nobody can open. Enablement without governance creates a free-for-all where nobody trusts the numbers. You need both.
Why Most Enablement Programs Fail
We've watched enough of these programs stall to see the patterns. Alation's breakdown of common mistakes maps closely to what we see in the field. Five anti-patterns kill programs before they deliver value - and there's a sixth that shows up constantly in RevOps-heavy orgs.
1. Tool-first thinking. Someone sees a demo of Collibra, gets excited, and signs a catalog contract that often starts around $100k+/year before the org has defined a single data owner. The tool sits half-deployed for 18 months. The vendor isn't your strategy.
2. No change management. Leadership signs off on a "data enablement initiative" but never communicates why it matters. Analysts keep doing what they've always done. Adoption flatlines.
3. No discovery layer. Teams can't find datasets, so they build their own. You end up with six versions of "monthly revenue" and nobody agrees which is right.
4. Retrofitting legacy instead of designing forward. Slapping metadata on a decade of undocumented pipelines feels productive but rarely is. Start with net-new assets and work backward selectively.
5. No measurement. If you can't show that time-to-insight dropped, the program loses funding in the next budget cycle. KPIs aren't a nice-to-have - they're your survival mechanism.
6. Treating CRM data as someone else's problem. Here's the thing: your CRM is probably the most-used and least-governed dataset in the org. Revenue teams build pipeline on stale records, marketing segments off dirty fields, and nobody owns the cleanup. Every enablement program that ignores operational data quality is incomplete. This is where a solid RevOps data strategy becomes essential - without one, sales, marketing, and CS teams all operate from different versions of the truth.
The Framework: Source to Improve
Monte Carlo's lifecycle model is the most practical framework we've seen for structuring a data enablement strategy. Six stages, each with a clear owner and SLA.
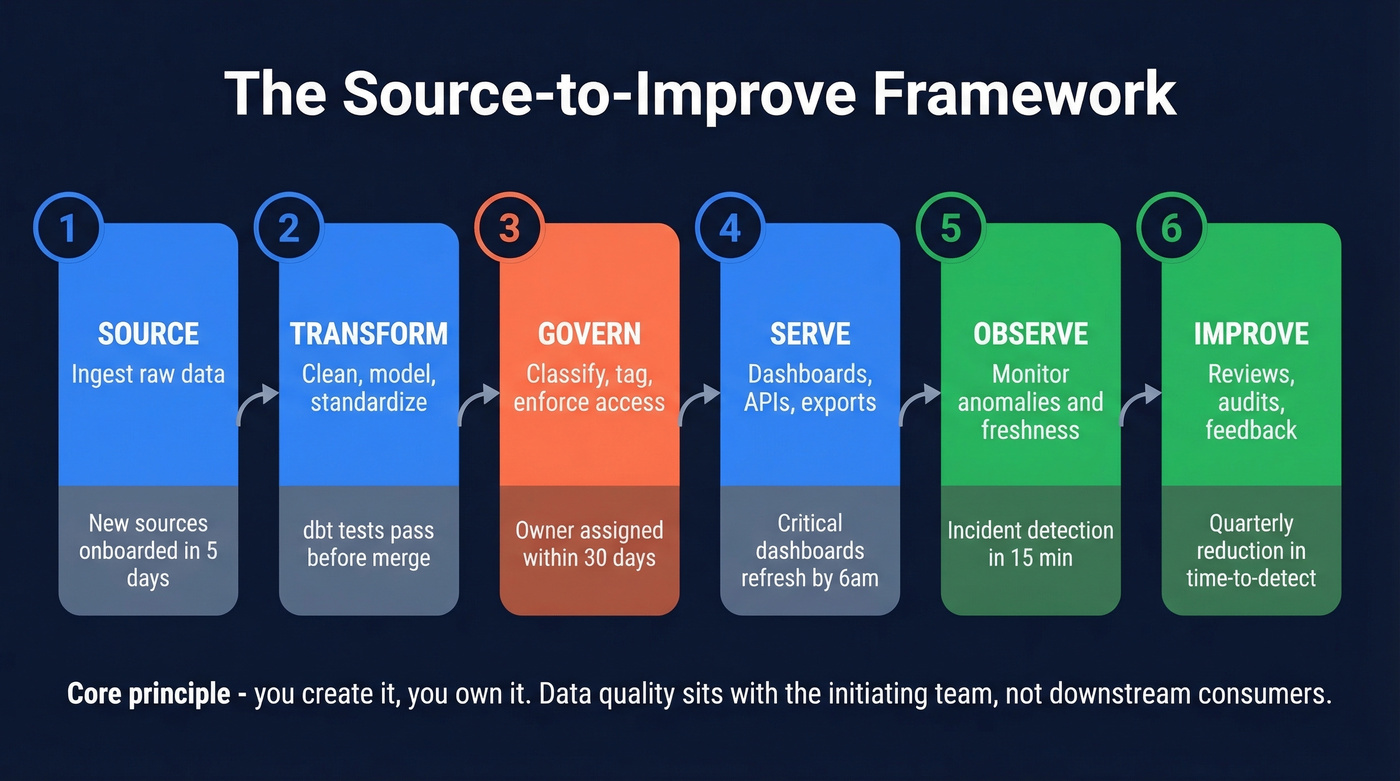
- Source - Ingest raw data. New sources onboarded within 5 business days, schema documented on arrival.
- Transform - Clean, model, and standardize. dbt tests pass in CI before merge; canonical metrics carry plain-English definitions.
- Govern - Classify, tag, enforce access policies. Every dataset gets an assigned owner within 30 days of creation. If nobody owns it, nobody fixes it.
- Serve - Deliver to consumers via dashboards, APIs, or exports. Critical dashboards refresh by 6am local time. When they don't, the owner hears about it within minutes, not days.
- Observe - Monitor for anomalies, freshness, and volume. Set a tier-1 target like incident detection within 15 minutes.
- Improve - Monthly incident reviews, dashboard hygiene audits, feedback loops. Drive a quarterly reduction in time-to-detect.
The core principle: "you create it, you own it." Data quality responsibility sits with the initiating team, not downstream consumers. When validation fails, suspect data goes into an exception queue until the owner corrects it. Real-time reporting on that queue creates executive visibility - and incentive.
You just read that CRM data is the most-used and least-governed dataset in most orgs. Prospeo fixes the root cause: stale, unverified contact records. With a 7-day refresh cycle, 98% email accuracy, and CRM enrichment returning 50+ data points per contact, your enablement strategy starts with data you can actually trust.
Stop governing garbage. Start with data that's already clean.
Quick Maturity Check
Before you build a roadmap, figure out where you're starting. The Gartner-style maturity model that Atlan summarizes gives you five levels.
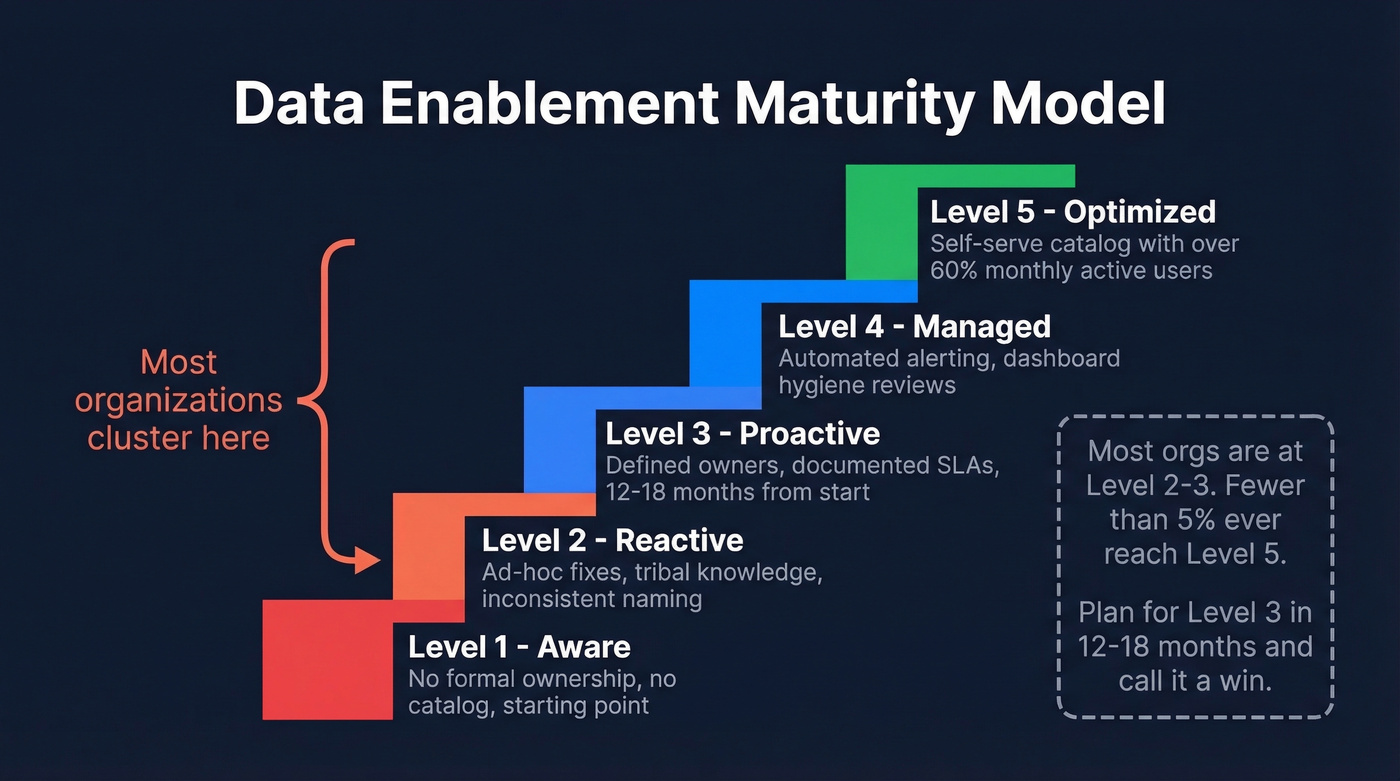
| Level | Name | Typical Signals | Timeline |
|---|---|---|---|
| 1 | Aware | No formal ownership | Starting point |
| 2 | Reactive | Ad-hoc fixes, tribal knowledge | 6-12 months from L1 |
| 3 | Proactive | Defined owners, documented SLAs | 12-18 months from L1 |
| 4 | Managed | Automated alerting, dashboard hygiene reviews | +18-24 months |
| 5 | Optimized | Self-serve catalog with >60% MAU | <5% of orgs reach this |
Most organizations cluster at levels 2-3. If you're at level 1, don't plan for level 5 - plan for level 3 in 12-18 months and call that a win. The teams that try to leapfrog are the ones whose programs die in committee.
Concrete signals you're stuck at level 2: inconsistent naming conventions, duplicate records across systems, unclear ownership documentation, batch-only pipelines, and shadow IT data sources that nobody admits to using. If that list sounds familiar, you've got company.
What to Measure
Pick KPIs across three categories and track them monthly.
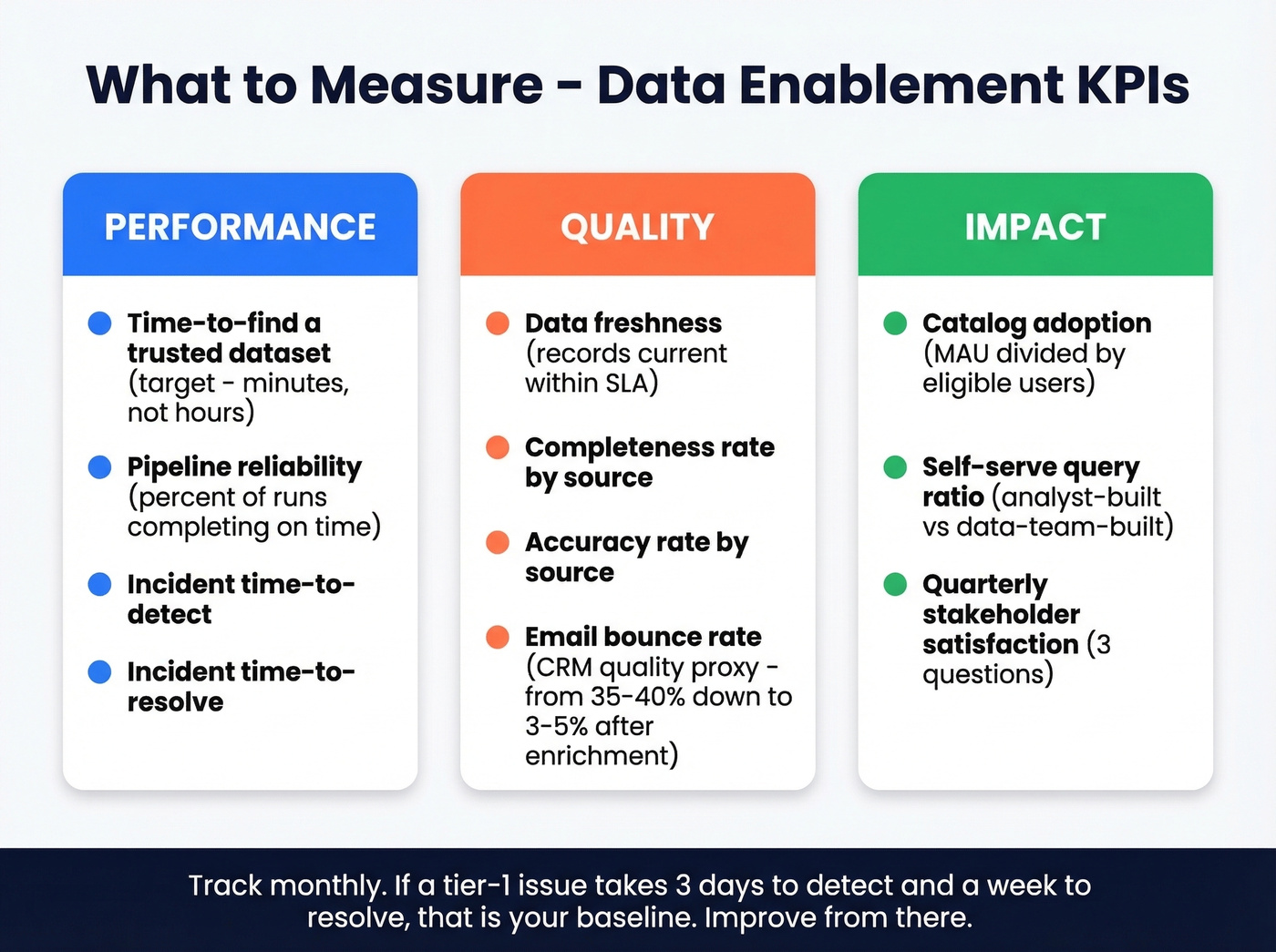
Performance covers operational health. Time-to-find a trusted dataset should be measured in minutes, not hours. Pipeline reliability - the percentage of scheduled runs completing on time - tells you whether your infrastructure is keeping promises. Incident time-to-detect and time-to-resolve are your most important operational metrics; track them like you'd track product incidents.
Quality is where most teams have the biggest blind spots. Data freshness measures whether records are current within SLA. Completeness and accuracy rates by source expose your weakest links. Email bounce rate works as a surprisingly effective CRM data quality proxy - we've seen Prospeo customers drop bounce rates from 35-40% to under 3-5% after enrichment, which tells you just how bad the baseline usually is.
Impact proves the program's value to leadership. Catalog adoption as a ratio of monthly active users to total eligible users shows whether people are actually using what you built. Self-serve query ratio - analyst-built versus data-team-built - measures whether you're reducing bottlenecks. A quarterly stakeholder satisfaction survey, kept to three questions, rounds it out.
If a tier-1 data issue takes three days to detect and a week to resolve, that's your baseline. Improve from there.
The Tooling Layer (With Real Prices)
Tooling is the last decision, not the first. But you'll need to budget for it, so let's be specific.
| Category | Tool | Price Range | Deploy Time |
|---|---|---|---|
| Catalog | Collibra | $100k+/yr | 3-9 months |
| Catalog | Secoda | ~$500/mo | 1-2 weeks |
| Catalog | DataHub (OSS) | Free (eng cost) | 2-4 weeks |
| Observability | Monte Carlo | $50k-$150k+/yr | 4-8 weeks |
| Transformation | dbt | Free / ~$50-$100+/seat/mo | Days |
| Warehouse | Snowflake / BigQuery / Databricks | ~$5-$50+/TB/mo | Days-weeks |
| B2B Data Quality | Prospeo | Free tier / ~$0.01/email | Same day |
Gartner predicts that by 2026, 50% of enterprises with distributed architectures will adopt data observability tools, up from less than 20% in 2024. That shift is happening because teams realized you can't manage what you can't see. For context, Kiwi.com reduced engineering documentation workload by 53% in 90 days after deploying Atlan as their catalog - that's the kind of result that justifies the spend.
Skip the enterprise stack if it doesn't fit. If your average deal size is under $50k and your data team is fewer than five people, you don't need Collibra or Monte Carlo. Start with Secoda or DataHub, add dbt for transformation, and use a tool like Prospeo to clean your CRM data. You can build a functional enablement program for under $1,000/month. The enterprise stack is for enterprise problems.
Every stage of the Source-to-Improve framework depends on data quality at the point of ingestion. Prospeo's 5-step verification, spam-trap removal, and 92% API match rate mean fewer exception queues, fewer incidents, and faster time-to-insight - at $0.01 per email instead of $1.
Cut your data quality incidents at the source for 90% less than ZoomInfo.
Why Your GTM Data Strategy Depends on This
Industry-wide AI infrastructure investment hit roughly $1.5 trillion in 2025. IBM, citing Gartner, forecasts AI spending will surpass $2 trillion in 2026 with 37% year-over-year growth. And yet, fewer than one in five organizations consider themselves data-ready, while 72% of leaders plan to prioritize data foundations over the next 12 months.

Let's be honest: if your org is pouring money into AI agents and copilots but hasn't solved basic data ownership and quality, you're building on sand. AI models trained on fragmented, inaccurate data produce what the WEF politely calls "AI slop." The enablement program you build now determines whether your AI investments pay off or become expensive experiments.
This is especially true for GTM teams. A coherent go-to-market data strategy ensures that the signals feeding your scoring models, outbound sequences, and attribution dashboards are actually trustworthy. The consensus on r/dataengineering is blunt - most "AI-ready" initiatives fail not because of model quality, but because the underlying data is garbage.
If you're building outbound on top of messy records, start by fixing your lead enrichment workflow and your ideal customer profile definitions so scoring and segmentation stop drifting.
Getting Started This Quarter
Don't overthink this. Three moves, this quarter.
- Assign ownership for your top 10 data assets. Name a person, not a team. If nobody owns it, nobody fixes it.
- Define one SLA per asset. Freshness, completeness, or accuracy - pick the dimension that matters most for each.
- Deploy a catalog you can launch this month. Secoda at ~$500/mo or self-hosted DataHub at zero license cost. Don't spend six months evaluating Collibra if you're at maturity level 2.
Everything else is iteration. Get the ownership and SLAs in place, make data findable, and improve from there. Once the foundation is solid, extend the same principles to your marketing data strategy - campaign attribution, lead scoring, and segmentation all depend on the same clean, well-governed datasets. That's the whole point of a data enablement strategy: building the foundation once so every team can trust the numbers.
FAQ
What's the difference between data enablement and data governance?
Governance defines the rules - who can access what, under what policies. Enablement makes it easy to actually follow those rules by providing tools, access, and training. You need governance to prevent chaos and enablement to prevent bureaucracy. They're complementary, not interchangeable.
How long does it take to see results?
Most organizations move from reactive to proactive maturity in 12-18 months. Reaching managed maturity takes an additional 18-24 months. Start with ownership assignments and SLAs to show measurable value - like reduced time-to-detect - within the first quarter.
What's the cheapest way to start?
Self-host DataHub for free or start Secoda at roughly $500/month for your catalog. Add a free-tier B2B data tool to tackle CRM data quality on day one. The expensive part isn't tools - it's the change management you skip.
How does enablement fit into a RevOps data strategy?
RevOps teams sit at the intersection of sales, marketing, and customer success - touching nearly every critical dataset. A formal enablement program gives RevOps the shared definitions, ownership clarity, and quality SLAs they need to stop reconciling conflicting numbers and start driving reliable pipeline reporting.