Best Data Quality Tools in 2026: Real Pricing, Real Opinions
Data professionals spend nearly 40% of their time firefighting - broken pipelines, explaining why the board deck doesn't match the dashboard, fixing records that should've been caught upstream. Meanwhile, 43% of COOs now identify data quality as their most significant data priority, and over a quarter of organizations estimate they're losing more than $5M annually to bad data. With 45% of business leaders citing data accuracy and bias as the leading barrier to scaling AI, the right tooling has never mattered more.
The number of solutions has multiplied to match the problem. But most "best of" lists lump observability platforms, open-source testing frameworks, and enterprise governance suites into one undifferentiated pile - then skip pricing entirely. You don't need a list of 15 logos. You need to know which category of tool solves your actual problem, what it'll cost, and whether the open-source option is genuinely production-ready or just a weekend project.
Our Picks
| Category | Pick | Why | Starting Price |
|---|---|---|---|
| Data Observability | Monte Carlo | ML anomaly detection, lineage | ~$50K+/yr |
| Open-Source Testing | Soda Core | Declarative YAML, fast setup | $0 |
| Enterprise Governance | Ataccama ONE | Unified platform, rated 4.4 on Gartner Peer Insights (88 ratings) | Six figures/yr |
| Budget-Friendly Start | Soda (Team) | Transparent pricing, free tier | $750/mo |
| B2B Contact Data Quality | Prospeo | 98% email accuracy, 7-day refresh | Free (75 emails/mo) |
Five Categories You Should Know
Stop tool-shopping. Start category-shopping. The biggest mistake teams make is comparing Monte Carlo to Collibra - they solve fundamentally different problems.

Data Observability - continuous monitoring that detects anomalies you didn't write rules for. Think Monte Carlo, Anomalo, Bigeye. These watch your pipelines and alert when something looks wrong.
Data Testing & Validation - predefined checks that run against your data. Great Expectations, Soda Core, dbt tests. You write the rules; the tool enforces them.
Data Governance & Catalogs - metadata management, lineage, stewardship, and policy enforcement. Collibra, Ataccama, Alation. These are about knowing what data you have and who's responsible for it.
Enterprise MDM & Quality Suites - heavyweight platforms for master data management, deduplication, and standardization. Informatica, Precisely Trillium, IBM InfoSphere. Typically bundled into broader enterprise data contracts.
B2B Contact Data Quality - verification, enrichment, and freshness of the people data in your CRM. This is the category nobody covers, and it's where revenue teams feel the most pain.
Best Tools by Category
Data Observability
Monte Carlo
Use this if you're a mid-market or enterprise data team that needs always-on monitoring across a complex warehouse environment. Monte Carlo's ML-based anomaly detection catches issues you'd never think to write rules for - distribution drift, freshness delays, schema changes - across your entire data estate.
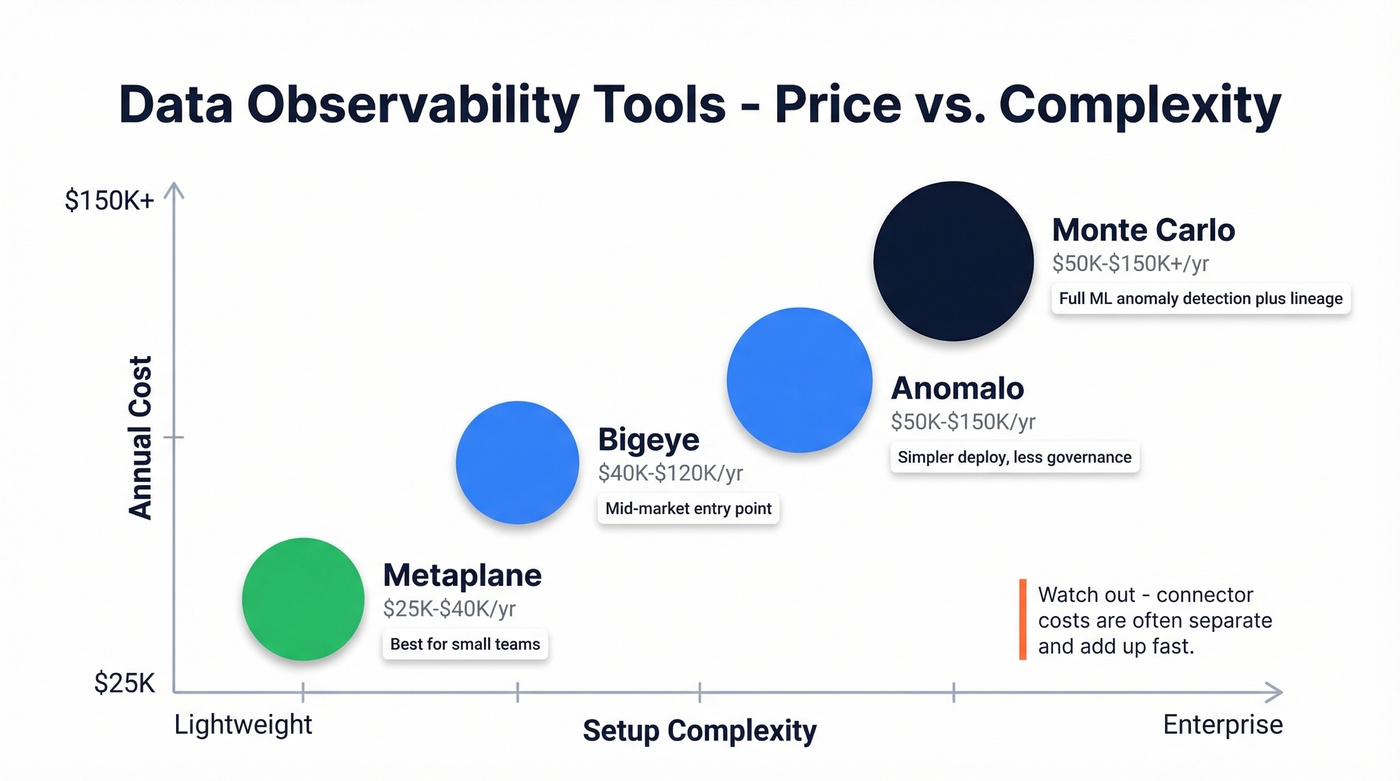
Skip this if you're a small team with fewer than 50 tables or a tight budget. The pay-per-table model means costs scale fast.
Three tiers exist: Start (up to 10 users, pay per table up to 1,000 tables, 10,000 API calls/day), Scale (unlimited users, 50,000 API calls/day), and Enterprise (100,000 API calls/day, multi-workspace, governance integrations, audit logging). All are pay-per-table with no public dollar figures, but expect $50K-$150K+/year depending on your data estate size. G2 pricing insights peg implementation at about 2 months and ROI at 9 months, with an average negotiated discount around 20%. The most common G2 complaint across 487 reviews? Having to purchase integrations separately - and that adds up fast.
Anomalo
Monte Carlo's closest competitor, with a different philosophy. Anomalo takes a similar ML-driven approach to anomaly detection but positions itself as simpler to deploy for teams that don't need Monte Carlo's full governance integration layer. If Monte Carlo's connector pricing frustrates you, Anomalo is the first place to look. Expect $50K-$150K/year.
Skip this if you need deep lineage mapping or multi-workspace governance.
Bigeye
Budget-friendly observability for mid-market teams. Bigeye runs $40K-$120K/year and covers the core monitoring use cases without the enterprise overhead. Good entry point if you've outgrown dbt tests but aren't ready for Monte Carlo pricing.
Metaplane
Lightweight and fast to set up - Metaplane targets smaller data teams that need basic observability without a six-figure commitment. This is the "just get started" option in the category, with pricing in the low five figures annually ($25K-$40K).
Data Testing and Validation (Open Source)
Great Expectations
Great Expectations is the foundational open-source data testing framework, and it's earned that reputation. It's also not for everyone.

GX is code-first and Python-native, giving you the most flexible option for complex custom validations. The auto-generated Data Docs - browsable HTML documentation of every check and result - are genuinely excellent. GX Cloud now offers a free tier for teams that want a managed layer on top, and the community ecosystem is massive.
The tradeoff is real, though. Setup is steep: Data Contexts, Batch Requests, and Expectation Suites all need configuration before you validate a single row. Maintenance burden grows with your data estate, and someone has to own the expectation library. If your team has strong Python engineers who want granular control, GX is the right choice. If your team is mostly SQL-oriented analytics engineers, you'll fight the framework more than you'll use it.
Soda / Soda Core
Soda Core takes the opposite design philosophy: declarative YAML checks, SQL-friendly syntax, and a setup process that takes minutes instead of days.
The declarative YAML approach means analytics engineers and SQL-heavy teams can write checks without touching Python. Pricing is fully transparent: Free ($0, up to 3 production datasets), Team ($750/mo, 20 datasets, $8 per additional dataset, unlimited users), Enterprise (custom). It carries a 4.4/5 on G2 across 55 reviews - users consistently praise the clean interface and fast time-to-value. When you need more power, it extends with custom SQL checks and Python UDFs.
The free tier's 3-dataset limit means most teams outgrow it quickly, and it's less flexible than GX for deeply custom programmatic validations. But Soda Core gives you 80% of the value in 20% of the setup time. For most data teams, that's the right tradeoff.
Deequ
Apache Spark-native, open-source, and free. If your pipelines already run on Spark, Deequ slots in without adding a new dependency. Not the right choice if you're on Snowflake or BigQuery - it's purpose-built for the Spark ecosystem.
dbt Tests
Over 25,000 companies use dbt, and most rely on built-in tests for basic data quality. dbt Core is free; dbt Cloud starts at $100/mo per seat. Here's the thing: dbt tests are a starting point, not a strategy. They catch nulls and uniqueness violations. They don't catch distribution drift, freshness anomalies, or the hundred other ways data breaks silently.
Data Governance and Catalogs
Collibra
Use this if you're a Fortune 500 company with a dedicated data governance team, regulatory requirements, and a budget that starts with "mid six figures."
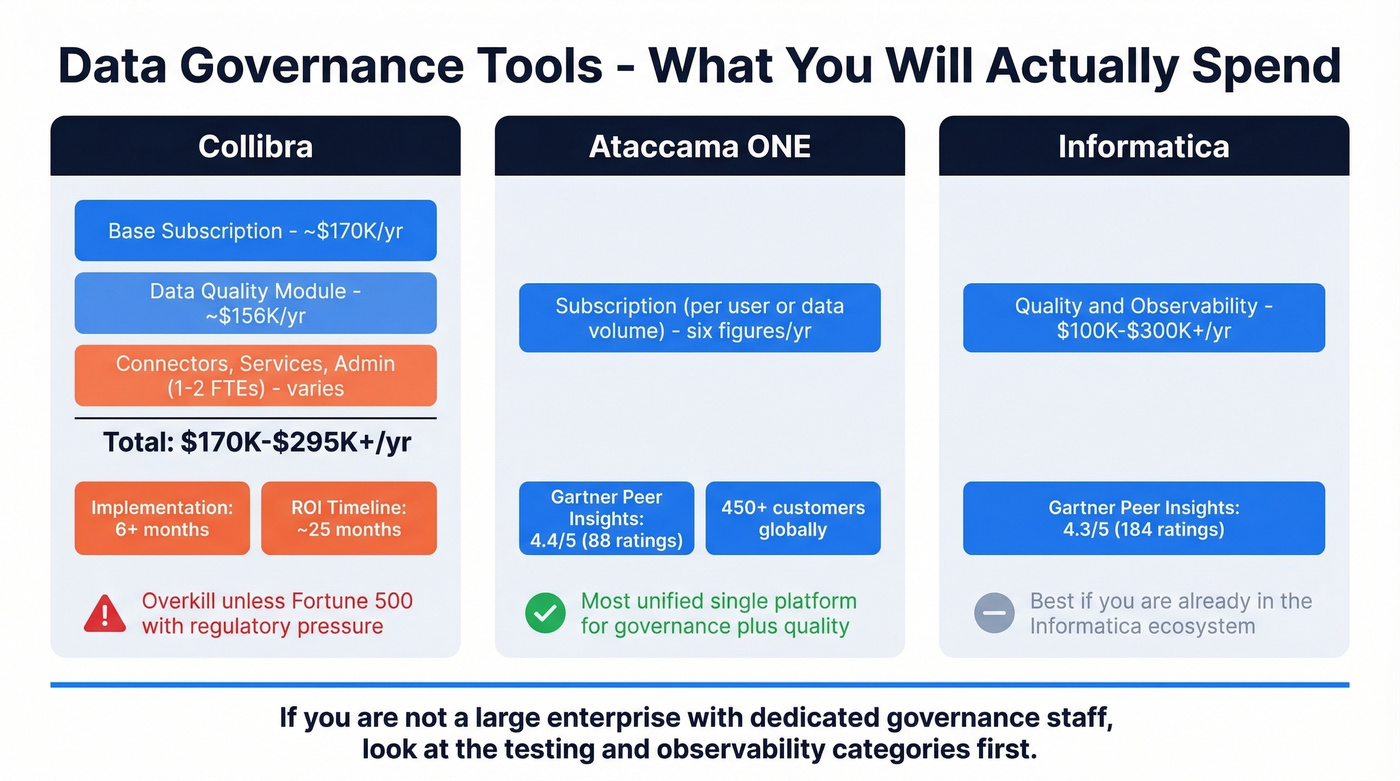
Skip this if you're anything smaller. Seriously.
Collibra's base subscription starts around $170K/year. The Data Quality module is commonly budgeted separately at roughly $156K/year. Total spend for a meaningful deployment runs $170K-$295K/year before connectors, professional services, and the 1-2 full-time admins you'll need. Implementation takes 6+ months, and ROI typically lands around 25 months. Collibra is overkill unless you're operating at genuine enterprise scale with regulatory pressure that justifies the investment.
Ataccama ONE
Use this if you want the most unified platform for governance and quality in a single product. Ataccama ONE is rated 4.4 on Gartner Peer Insights across 88 ratings, and it's the closest thing to a single pane of glass for data profiling, monitoring, cataloging, and stewardship.
Skip this if you only need observability or testing - you'd be buying a Swiss Army knife to open a letter.
Pricing is subscription-based, typically structured per user or per data volume. Expect six figures annually. With 450+ customers globally, Ataccama's sweet spot is mid-to-large enterprises that want to consolidate governance and quality tooling rather than stitching together point solutions.
Informatica
The incumbent. Informatica Data Quality and Observability is rated 4.3 with 184 ratings on Gartner Peer Insights and runs $100K-$300K+/year. Best for teams already deep in the Informatica ecosystem - if you're running PowerCenter or IDMC, adding their quality module makes sense. If you're not, there are more modern options.
Enterprise MDM and Quality Suites
Precisely Trillium
Enterprise MDM with a focus on address validation, matching, and standardization. Runs $75K-$200K+/year. If your problem is fundamentally about master data - deduplicating customer records, standardizing addresses across systems - Trillium is purpose-built for it.
IBM InfoSphere QualityStage
Typically bundled with broader IBM data platform contracts at $50K-$200K+/year. If you're already an IBM shop running InfoSphere, QualityStage is the natural add-on. If you're not, there's no compelling reason to start here.
B2B Contact Data Quality
Most guides on data quality ignore CRM data entirely - but if your outbound team is bouncing 15% of emails, your revenue pipeline has a problem no observability tool will catch.

Prospeo covers 300M+ professional profiles with 143M+ verified emails and 125M+ verified mobile numbers. The 98% email accuracy rate comes from a proprietary 5-step verification process that includes catch-all handling, spam-trap removal, and honeypot filtering. Data refreshes every 7 days, while the industry average sits at 6 weeks - meaning most databases are serving you stale contacts by default.
For CRM and CSV enrichment, Prospeo returns 50+ data points per contact with a 92% match rate. Snyk's team of 50 AEs saw their bounce rate drop from 35-40% to under 5% after switching, with AE-sourced pipeline up 180% and 200+ new opportunities per month.
The free tier gives you 75 verified emails per month with no credit card required, plus 100 Chrome extension credits/month. Paid plans run about $0.01 per email - a fraction of what enterprise data platforms charge for contact data that's often less accurate.
You're investing in tools to monitor pipelines and validate schemas - but what about the contact data your revenue team actually sends to? Bad emails and stale records cost deals, not just dashboard trust. Prospeo verifies 143M+ emails at 98% accuracy on a 7-day refresh cycle, turning your CRM from a liability into a pipeline engine.
Stop firefighting bounced emails. Start with data that's accurate on day one.
Datafold
Datafold doesn't fit neatly into any of the categories above - it's a data diffing tool for CI/CD pipelines. It catches regressions before they hit production by comparing data outputs across code changes. Think of it as a safety net for data engineers shipping dbt or SQL changes. Niche but genuinely useful if your quality problems stem from code deployments rather than source data issues. Pricing starts around $30K-$60K/year for mid-market teams.
Every data quality category on this list solves for warehouse reliability - except one. B2B contact data quality is where revenue teams bleed the most: 35%+ bounce rates, dead phone numbers, outdated job titles. Prospeo's 5-step verification, catch-all handling, and spam-trap removal deliver under 4% bounce rates for teams like Snyk and Meritt. Starting at $0.01/email with no contracts.
The cheapest data quality fix is never sending to a bad email in the first place.
Full Pricing Comparison
Every tool on this list with actual dollar figures - not "contact us" placeholders.
| Tool | Category | Best For | Starting Price | Open Source? | AI/ML? |
|---|---|---|---|---|---|
| Monte Carlo | Observability | Enterprise data teams | ~$50K+/yr | No | Yes |
| Anomalo | Observability | ML-driven monitoring | ~$50K+/yr | No | Yes |
| Bigeye | Observability | Mid-market teams | ~$40K+/yr | No | Yes |
| Metaplane | Observability | Small data teams | ~$25K+/yr | No | Yes |
| Great Expectations | Testing | Python-heavy teams | $0 | Yes | No |
| Soda Core | Testing | SQL/analytics teams | $0 | Yes | No |
| Soda Team | Testing (Commercial) | Growing teams | $750/mo | No | No |
| Deequ | Testing | Spark pipelines | $0 | Yes | No |
| dbt Tests | Testing | dbt users | $0-$100/mo/seat | Yes (Core) | No |
| Collibra | Governance | Fortune 500 | ~$170K+/yr | No | No |
| Ataccama ONE | Governance + Quality | Enterprise unified | ~$100K+/yr | No | Yes |
| Informatica | Governance + Quality | Informatica ecosystem | ~$100K+/yr | No | No |
| Precisely Trillium | Enterprise MDM | Address/MDM | ~$75K+/yr | No | No |
| IBM InfoSphere | Enterprise MDM | IBM ecosystem | ~$50K+/yr | No | No |
| Prospeo | Contact Data Quality | Sales/RevOps teams | Free-$0.01/email | No | No |
The data quality tools market is valued at $3.94 billion in 2026 and projected to hit nearly $16 billion by 2034. Enterprise tools aren't getting cheaper.
GX vs. Soda Core: The Real Debate
This is the most debated choice in data engineering communities, and the consensus on r/dataengineering leans toward a simple heuristic: match the tool to your team's primary language.
Great Expectations gives you maximum flexibility through code-first, programmatic validations and auto-generated Data Docs. The cost is setup time and ongoing maintenance.
Soda Core gives you speed-to-value through declarative YAML and SQL-friendly syntax. The cost is less flexibility for deeply custom checks.
Pick GX if your data engineers live in Python and want granular control. Pick Soda if your team is SQL-heavy and values fast adoption. The wrong choice isn't either tool - it's picking the one that doesn't match your team's skill set, because the friction will kill adoption before the tool ever proves its value.
How to Choose the Right Tool
Start with the four automation dimensions that matter most: baseline learning, monitoring coverage, structural change detection, and timeliness enforcement. Then look for must-have features: data profiling and monitoring, automated rule discovery, lineage tracking, matching and merging, and configurable alerts.
Let's break it down by team size.
Startup or small data team (1-5 people): Start with Soda Core or Great Expectations. Both are free. Add dbt tests if you're already in the dbt ecosystem, but don't rely on them alone.
Mid-market (5-20 data team members): Soda's Team plan at $750/month is the most cost-effective commercial option. Anomalo is worth evaluating if you want ML-driven detection without Monte Carlo's price tag.
Enterprise (20+ data team, regulatory requirements): Monte Carlo for observability, paired with Ataccama ONE or Collibra for governance. Budget $200K-$500K/year across the stack.
Here's our honest take: if your average deal size is under $75K, you probably don't need a six-figure observability platform. Start with Soda Core, add dbt tests, and invest the savings in fixing the problem that actually costs you revenue - your CRM contact data decaying at 30-40% annually.
Mistakes That'll Waste Your Budget
Writing manual uniqueness thresholds across hundreds of columns. ML-based tools learn baselines automatically - stop writing rules you'll spend more time maintaining than the issues they catch.
Hand-maintaining validity lists for low-cardinality fields. Every time someone adds a new product SKU or region code, your static list breaks. Modern tools detect distribution shifts without requiring you to enumerate every valid value.
Setting static freshness rules that create alert fatigue. If your data lands at slightly different times every day, a fixed threshold will fire false alerts constantly. Your team starts ignoring them, and that defeats the entire purpose.
Buying Collibra for a 5-person data team. I've seen this happen. The implementation alone takes longer than some startups exist. Match the tool to your actual scale, not your aspirational org chart.
Ignoring CRM data while perfecting warehouse data. We've watched teams obsess over pipeline observability while their sales org sends sequences to dead email addresses. Your dashboards can be pristine, but if 15% of outbound emails bounce, you've got a revenue problem no observability platform will surface.
If you’re evaluating vendors for contact data specifically, start with a B2B database that’s ranked on accuracy, then validate deliverability with an email verifier before you scale outreach.
If your issue is enrichment coverage (missing titles, phones, firmographics), compare data enrichment tools and align them to your RevOps tech stack so enrichment doesn’t break routing and reporting.
FAQ
What are the six dimensions of data quality?
Accuracy, completeness, timeliness, uniqueness, validity, and consistency. Modern tools automate monitoring across all six - the best ones learn baselines with ML rather than requiring you to manually configure thresholds for every column and table.
Are open-source tools production-ready?
Yes. Great Expectations and Soda Core are both used in production at scale. The tradeoff is engineering effort for setup and maintenance versus the managed experience of commercial platforms. Teams with strong data engineers can run open-source long-term without issues.
How much do enterprise platforms cost?
Expect $50K-$150K/year for observability tools like Monte Carlo and Anomalo. Governance suites like Collibra and Informatica run $170K-$300K/year with modules, connectors, and services. Soda's Team plan at $750/month is the most affordable commercial option with fully transparent pricing.
What's the difference between observability and testing?
Testing validates data against predefined rules - you write the checks, the tool enforces them. Observability monitors continuously and detects anomalies you didn't anticipate, using ML to learn what "normal" looks like. Most mature teams use both: testing as a baseline, observability as a safety net.
How do I handle CRM data quality separately?
CRM contact data decays 30-40% annually and requires specialized verification, not warehouse observability. Tools like Prospeo use multi-step email verification with catch-all handling, spam-trap removal, and honeypot filtering to catch bounces and stale records that general-purpose tools miss entirely.