Deterministic Matching: What It Is, How to Implement It, and When It Breaks Down
Poor data quality costs organizations [$12.9 million per year](https://www.gartner.com/en/data-analytics/topics/data-quality), according to Gartner. A big chunk of that waste traces back to one problem: records that should be linked aren't, and records that shouldn't be linked are. Deterministic matching is the foundational technique for solving this - and most guides explain it in 300 words, then move on.
That's like explaining what a hammer is without showing anyone how to build a house.
The Short Version
This approach links records by requiring exact matches on shared identifiers - email, phone, SSN, SKU. It's high-precision but low-coverage whenever those identifiers are missing or inconsistent. Many production systems layer probabilistic or ML-based matching on top. But the single biggest lever isn't your matching logic. It's the quality of your source data upstream.
If your identifiers are clean and consistently collected, deterministic matching alone can reach 95-98.9% precision. If they're not, you'll hit a coverage ceiling fast and need a hybrid approach.
What Is Deterministic Matching?
This method connects two records only when they share an exact match on one or more unique identifiers. No scoring, no probability thresholds, no ambiguity. Record A has email jsmith@acme.com. Record B has email jsmith@acme.com. They match. Done.
The identifiers powering exact-match resolution include email addresses, Social Security numbers, phone numbers, device IDs, SKUs, and loyalty card numbers - anything that should uniquely identify an entity. The strength is precision: when the identifier is truly unique and correctly captured, false positives are very low.
The weakness is coverage. The moment records lack that shared identifier - a misspelled email, a missing phone number, a customer who used two different accounts - the system has nothing to work with. That's where probabilistic matching enters the picture.
Types of Exact-Match Resolution
GrowthLoop outlines three common deterministic patterns: single-field matching, composite-field matching, and cascading deterministic heuristics.
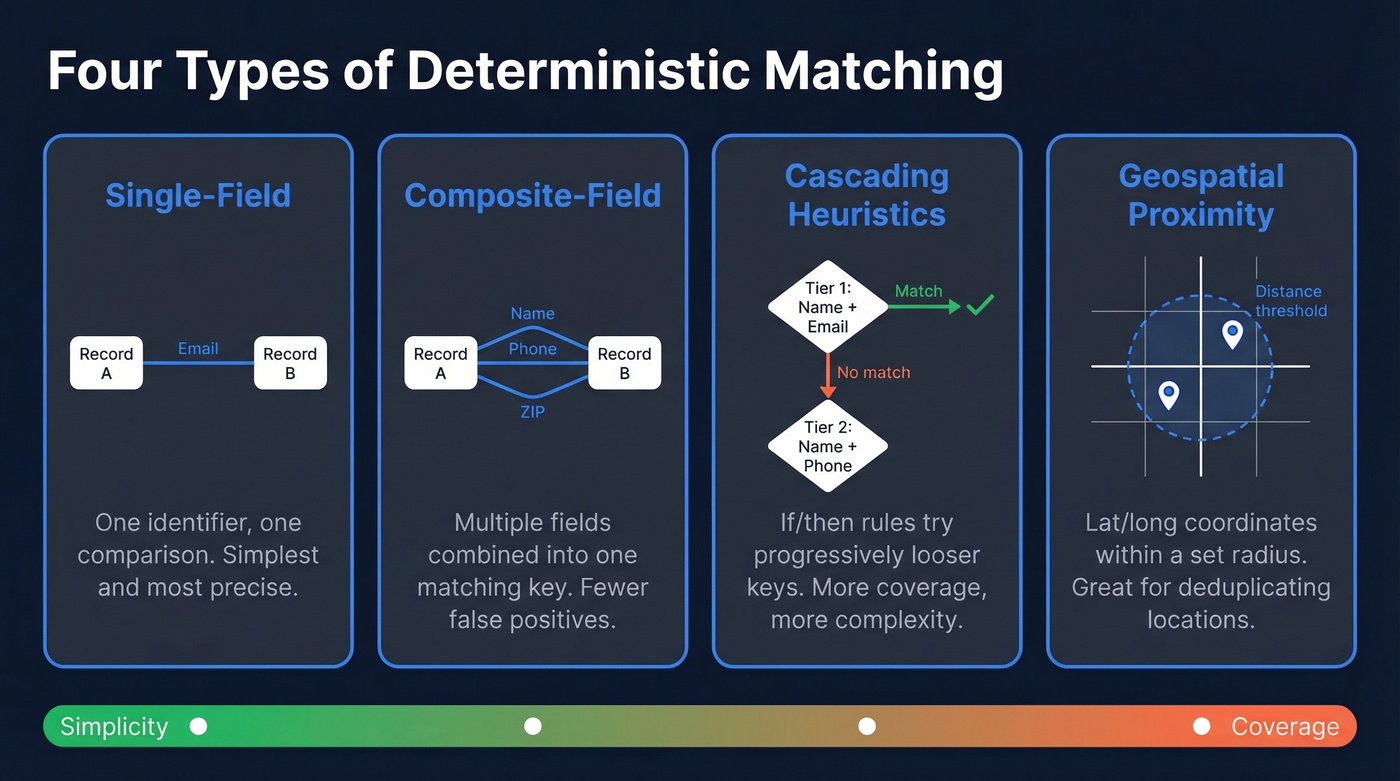
Single-field matching is the simplest form. One identifier, one comparison. Email-to-email. SSN-to-SSN. It works beautifully when you have a truly unique, consistently collected field, and most B2B deduplication starts here.
Composite-field matching combines two or more identifiers into a single matching key - first name + email, or last name + phone + ZIP code. This reduces false positives when no single field is unique enough on its own, but it also increases the chance of false negatives when any one component is missing or inconsistent.
Cascading deterministic heuristics add conditional logic. A Salesforce practitioner on r/salesforce described a two-tier scheme in Salesforce Flow: Tier 1 matches on the first three characters of the first name plus the full email address. If that doesn't hit, Tier 2 falls back to name plus the last 10 digits of the phone number. This cascading approach trades simplicity for coverage - you're writing if/then rules that try progressively looser keys until something matches. It's also where rule complexity starts to become a real maintenance headache, which we'll cover in the failure modes section.
There's also geospatial proximity matching, which compares latitude/longitude coordinates within a distance threshold to deduplicate location records. Melissa describes this pattern as "Proximity Matching," using coordinates and proximity thresholds to detect matches across addresses within a specified distance.
Why It Matters in 2026
Privacy shifts have made deterministic matching more important, not less.

[34.9% of US browsers](https://www.emarketer.com/content/third-party-cookies-here-stay-google-pivots) already block third-party cookies by default. Twenty US states now enforce data protection laws. GDPR cumulative fines hit EUR5.88B as of early 2025. The probabilistic signals marketers relied on for cross-device tracking - cookies, device fingerprints, IP-based inference - are eroding fast.
Google reversed its cookie deprecation plans in April 2025 and later scrapped Privacy Sandbox by October 2025. But that doesn't change the trajectory. 62% of brand marketers say first-party data will become more important over the next two years. A common projection puts the share of organizations relying mainly on traditional identifiers dropping from 74% to 35% by end of 2026 - meaning the teams that build strong first-party deterministic foundations now will have a structural advantage.
First-party data means deterministic identifiers: emails, phone numbers, login-based IDs. If you're building an identity strategy for 2026 and beyond, exact-match resolution on first-party identifiers isn't optional. It's the foundation.
Deterministic vs. Probabilistic Matching
Let's be honest: the deterministic-vs.-probabilistic framing is a false choice. Most production systems use both. But understanding the tradeoffs matters for deciding where to start and how to layer them.

| Dimension | Deterministic | Probabilistic | Edge goes to |
|---|---|---|---|
| Precision | 95-99% with strong IDs | Varies by threshold tuning | Deterministic |
| Coverage | Low without unique IDs | Higher with fuzzy tolerance | Probabilistic |
| Complexity | Low, rule-based | Higher, weight calibration | Deterministic |
| Auditability | High - easy to debug | Lower - "why did this match?" | Deterministic |
| False positives | Very low | Moderate, threshold-dependent | Deterministic |
| False negatives | High when IDs missing | Lower | Probabilistic |
| Best for | Dedup, compliance, verification | Cross-device, MDM, messy data | Depends on use case |
Probabilistic matching assigns weights to multiple fields and calculates a composite match score. Two records sharing a last name (weak signal), a ZIP code (weak), and a birth year (moderate) are individually meaningless but collectively suggestive. The system scores the pair and compares it against a threshold.
About the conflicting accuracy numbers you'll see online: LiveRamp reports 95-98.9% precision, tested by comScore against roughly 12 million verified devices. GrowthLoop cites 70-80% accuracy. These aren't contradictory - they're measuring different things. The first is precision: of the matches made, how many are correct. The second is overall program match rate: what percentage of your total records actually get matched. Exact-match logic is extremely precise when it fires. It just doesn't fire often enough when identifiers are missing.
One underappreciated reason to favor deterministic rules: auditability. A practitioner on r/vibecoding built a verification layer for LLM outputs using deterministic substring and regex matching specifically because it's predictable, debuggable, and fast. When you need to explain why two records matched - to a regulator, a data steward, or a frustrated sales rep - deterministic rules give you a clear answer. Probabilistic scores give you a number.
Deterministic matching fails when identifiers are missing or stale. Prospeo's 5-step verification and 7-day data refresh cycle give you the clean, current emails and phone numbers that exact-match resolution demands - 98% email accuracy across 300M+ profiles.
Your matching logic is only as good as the data feeding it.
How to Implement It Step by Step
Most guides stop at the definition. Let's actually build the thing. This seven-step pipeline draws from a practical implementation blueprint and covers the full lifecycle from raw data to evaluated results.
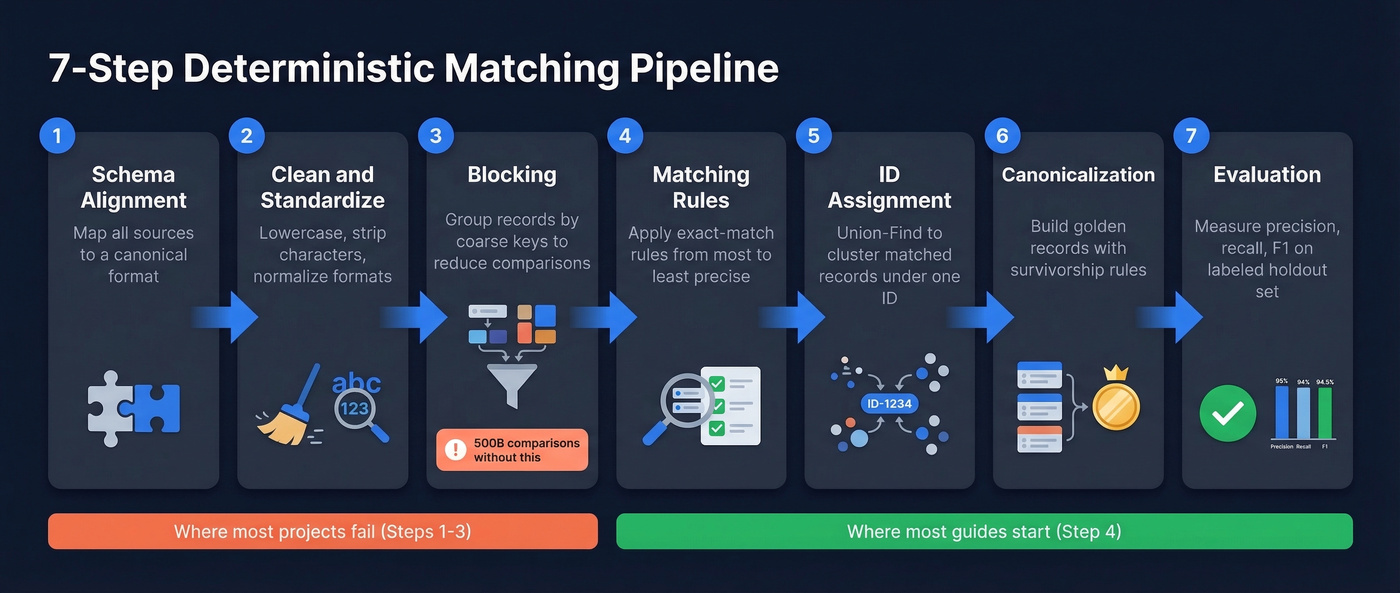
Step 1: Schema Alignment
Before you match anything, your fields need to speak the same language. If System A stores phone numbers as +1-555-123-4567 and System B stores them as 5551234567, those are the same number but they won't match. Map every source system's schema to a canonical format, standardizing data types, formats, and naming conventions.
Step 2: Cleaning and Standardization
This is where most matching projects succeed or fail.
Lowercase text fields where case isn't meaningful. Strip whitespace and special characters from phone numbers. Normalize email formatting. Parse addresses into components. Remove honorifics and suffixes from names. Your matching rules are only as good as the identifiers feeding them - and we've seen teams spend weeks tuning matching logic when 30 minutes of upstream data validation would've solved the problem.
Step 3: Blocking
Here's where naive implementations blow up. If you have 1 million records and compare every pair, that's 500 billion comparisons. Blocking assigns each record a "blocking key" - a coarse grouping attribute - and only compares records within the same block.
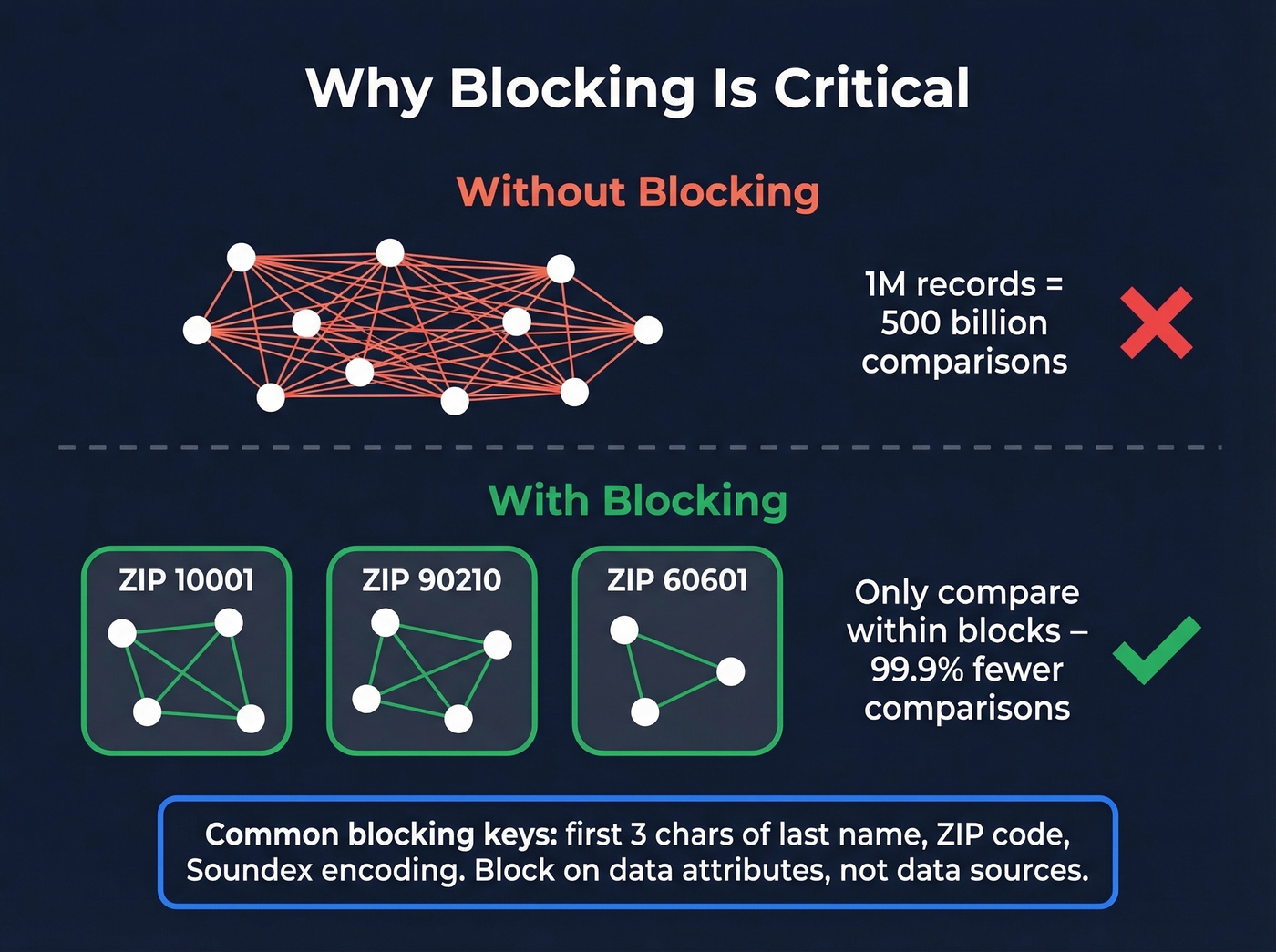
Common blocking keys include the first three characters of a last name, a ZIP code, or a phonetic encoding like Soundex, which maps similar-sounding names to the same code. The critical mistake we see teams make: blocking on source system - "only compare records from System A against System B." Duplicates exist within systems too. Block on data attributes, not data sources.
Step 4: Matching Rules
Define your deterministic rules within each block. Start with your strongest identifier. If you have verified email addresses, a single-field email match is your Tier 1 rule. Layer composite rules as fallbacks: name + phone, name + company + domain.
Keep rules ordered from most precise to most permissive. Document every rule and its expected precision. If you keep adding more and more composite rules just to squeeze out coverage, that's a sign you need probabilistic scoring, not more rules.
Step 5: ID Assignment
Every cluster of matched records needs a single, persistent identifier. Use a Union-Find (disjoint set) data structure to group records transitively: if A matches B and B matches C, all three get the same cluster ID.
Design these identifiers to be stable over time - as new data arrives and clusters split or merge, downstream systems that reference those IDs shouldn't break. But be careful: transitive closure can create serious problems we'll cover in the failure modes section.
Step 6: Canonicalization
Once records are clustered, build a "golden record." Which name spelling wins? Which address is most current? Define survivorship rules: prefer the most recently updated value, the most complete record, or the source system you trust most.
Step 7: Evaluation
You can't improve what you don't measure. Build a labeled holdout set - a sample of record pairs manually reviewed as "match" or "non-match." Calculate precision, recall, and F1 score.
Here's the thing: most teams skip this step and regret it within a quarter. Without evaluation, you're flying blind. Even a holdout set of 500 manually reviewed pairs gives you a meaningful signal. Revisit evaluation after every rule change.
Common Failure Modes
In real datasets, exact-match logic isn't 100% accurate. Here are the four ways it breaks in practice.
Shared Identifiers
Your CRM has two records for the same person because a parent used their email to sign up both kids. This is the family-address problem - a shared identifier that's valid for multiple distinct entities. The Salesforce practitioner who hit this was matching on first_name_prefix + email and merged two different children into one record.
The system assumes identifiers are unique. When they're not, you get false positives that are hard to detect and painful to unwind.
Transitive Closure Chains
A matches B on email. B matches C on phone. C matches D on address. Now A and D are in the same cluster, but they share nothing in common.
Amperity's SIGMOD'20 research highlights this as one of the most overlooked challenges in entity matching. Naive pairwise matching with Union-Find creates chains where the endpoints are completely dissimilar. You need conflict-aware cluster resolution - checking that all members of a cluster are mutually consistent, not just pairwise linked. The same research flags a related operational headache: as new data arrives and clusters evolve, your entity IDs need to remain stable, or every downstream system referencing them breaks.
Rule Explosion
When no single unique identifier exists, teams start building composite rules. Name + address + phone. Name + email domain + ZIP. Name + company + title. The permutations multiply fast, each rule needs testing, and rule sets become unmanageable. If you're maintaining a long list of composite rules and still not hitting acceptable coverage, that's your signal to switch to probabilistic scoring.
Coverage Collapse
A practitioner matching 3 million scraped products across websites found that exact-match logic on SKU and barcode only linked about 40% of the dataset. The remaining 60% lacked those identifiers entirely.
Skip deterministic-only approaches if more than 30% of your records lack strong unique identifiers. You'll spend weeks tuning rules for diminishing returns.
When to Go Hybrid
The deterministic-vs.-probabilistic debate ends the same way every time: you need both. The question is how to layer them.
A common Match360-style pattern runs probabilistic scoring as the base layer, then applies deterministic filters on top as hard business rules. If SSN + date of birth match exactly, it's a duplicate regardless of what the probabilistic score says. If two records share a last name, address, phone, date of birth, and gender but have different first names, a deterministic filter flags the twin edge case and prevents an incorrect merge.
For teams without enterprise MDM budgets, start deterministic on your strongest identifiers, add blocking to keep it scalable, then layer probabilistic or embedding-based matching for the records that fall through. The Reddit practitioner with the 3M product dataset found that text embeddings using OpenAI's text-embedding-3-small with cosine similarity outperformed image-based approaches for the 60% of records lacking deterministic keys. That pattern - exact-match rules for the easy matches, embeddings for the rest - is becoming a default hybrid architecture in 2026.
Here's our hot take: if your deal sizes are under $15K and you're spending more than two hours a week maintaining matching rules, you've over-engineered the problem. Start with clean, verified email as your single deterministic key, layer a basic probabilistic fallback, and move on. Perfection in entity resolution has diminishing returns that most teams never recoup.
Use Cases Beyond Marketing
Deterministic matching isn't just for ad targeting. It shows up everywhere records need linking.
Healthcare record linkage is one of the highest-stakes applications. Patient records are distributed across hospitals, clinics, pharmacies, and insurers. Two patients named Jane Smith at the same Pennsylvania hospital - merge them incorrectly and you're looking at a misdiagnosis or duplicate treatments. Exact-match resolution on patient ID or SSN produces a complete medical history, but the consequences of a false positive are severe.
Fraud detection uses deterministic matching to link seemingly unrelated records - same phone number across multiple applications, same device ID across different accounts - to reveal suspicious patterns that probabilistic signals alone would miss.
Master data management relies on exact-match logic to build a trusted source of truth for core entities. When your ERP, CRM, and billing system all have a record for the same customer, matching on account number or tax ID creates the golden record.
LLM verification middleware is a newer use case. Teams are using deterministic substring and regex matching to verify LLM-generated claims against source documents before allowing automated actions, choosing this approach over embeddings specifically for predictability and auditability.
In B2B prospecting, email-based identity resolution is the standard for deduplication and CRM hygiene. The entire pipeline depends on whether the emails you're matching against are actually correct - stale or unverified records create false negatives on day one. Prospeo's 98% email accuracy and 7-day refresh cycle give matching systems identifiers they can trust from the start.
Tools and Platforms
| Tool | Type | Pricing | Notes |
|---|---|---|---|
| Prospeo | Commercial (B2B data) | Free tier available; ~$0.01/email | 98% email accuracy, 92% API match rate, 7-day refresh |
| Splink | Open-source (Python) | Free | Popular for record linkage pipelines |
| Dedupe | Open-source (Python) | Free | Good for smaller datasets |
| recordlinkage | Open-source (Python) | Free | Academic, great for prototyping |
| Melissa MatchUp | Commercial (MDM) | Enterprise pricing | Uses 20+ fuzzy matching algorithms |
| LiveRamp | Commercial (identity) | Enterprise pricing | 95-98.9% precision benchmark |
| IBM Match360 | Commercial (MDM) | Enterprise pricing | Hybrid deterministic + probabilistic |
Splink is a standout open-source option for teams building record linkage pipelines in Python. Dedupe works well for smaller datasets where you don't need as much scale. The recordlinkage library is more academic in orientation but excellent for prototyping.
On the commercial side, the tools split into two categories: identity resolution platforms like LiveRamp and IBM Match360 that handle the matching itself, and upstream data quality platforms that ensure the identifiers feeding your matching system are accurate in the first place. If your source data is garbage, no matching algorithm saves you.
If you're evaluating vendors, start with accuracy and refresh rate first - then compare pricing models across B2B databases, data enrichment tools, and verified contact databases.
You read it above: precision hits 95-99% when identifiers are correct and consistently collected. Prospeo's proprietary email infrastructure verifies 143M+ emails with catch-all handling, spam-trap removal, and honeypot filtering - at $0.01 per email.
Feed your deterministic matching engine identifiers you can actually trust.
FAQ
What's the difference between deterministic and probabilistic matching?
Deterministic matching requires exact matches on shared identifiers like email or SSN, delivering 95-98.9% precision but missing records that lack those identifiers. Probabilistic matching uses weighted scoring across multiple fields to estimate match likelihood, trading some precision for significantly higher coverage. Most production systems combine both.
How accurate is deterministic matching?
Precision reaches 95-98.9% with strong identifiers, per a comScore-validated benchmark against roughly 12 million verified devices. Overall program match rates typically land at 70-80% because many records lack the required identifiers. The gap between precision and coverage is the core tradeoff.
When should I switch to a hybrid approach?
Switch when coverage drops below your acceptable threshold - typically when 30%+ of records lack strong unique identifiers. Most B2B and healthcare implementations go hybrid within the first quarter. Start with exact-match rules on your best identifiers, then layer probabilistic or embedding-based scoring for the remainder.
What tools support identity resolution for B2B teams?
Open-source options include Splink, Dedupe, and Python's recordlinkage library. Enterprise platforms like IBM Match360 handle matching at scale. For upstream data quality, Prospeo provides 98%-accurate verified emails on a 7-day refresh cycle - the free tier includes 75 emails/month.
Does deterministic matching work without unique identifiers?
Poorly. Without strong IDs, you're forced into complex composite rules that create maintenance overhead and rule explosion. One practitioner hit a 40% match ceiling on a 3M-record dataset using only SKU and barcode. At that point, probabilistic or embedding-based matching is more practical and significantly easier to maintain.