Firecrawl Pricing, Reviews, Pros and Cons: The Credit Math Other Reviews Skip
You signed up for Hobby thinking 3,000 credits equals 3,000 pages. Your first JSON extraction project burned through them on 333 pages. That's not a bug - it's how Firecrawl's credit modifiers work, and almost no review explains it properly.
Let's fix that.
30-Second Verdict
Firecrawl is a top-tier managed web-scraping API for feeding LLMs - if you understand the real credit costs. The $16/mo Hobby plan's 3,000 credits cover 3,000 basic pages at 1 credit/page, but only ~333 pages once you enable JSON format (+4) plus Enhanced Mode (+4), totaling 9 credits per page. Standard ($83/mo) is the realistic starting point for production workloads. And if your actual goal is B2B contact data - emails, phone numbers, company info - skip the scraping pipeline entirely and use a purpose-built data platform like Prospeo.
What Is Firecrawl?
Firecrawl, built by Mendable.ai, is an API that scrapes, crawls, maps, and searches the web, then returns clean markdown or structured JSON ready for LLM consumption. Its core endpoints - Scrape, Crawl, Map, and Extract - handle JavaScript rendering, proxy rotation, and anti-bot handling so you don't have to. The repo has ~97k GitHub stars and ships under an AGPL-3.0 open-source license, though the hosted cloud version adds features the self-hosted version doesn't include. Firecrawl isn't yet listed on G2 or Capterra, so community signals come primarily from GitHub issues and developer forums.
Pricing Breakdown for 2026
Other reviews cite $19/mo for Hobby and $99/mo for Standard. Those numbers are outdated. Here's what the pricing page shows on annual billing:
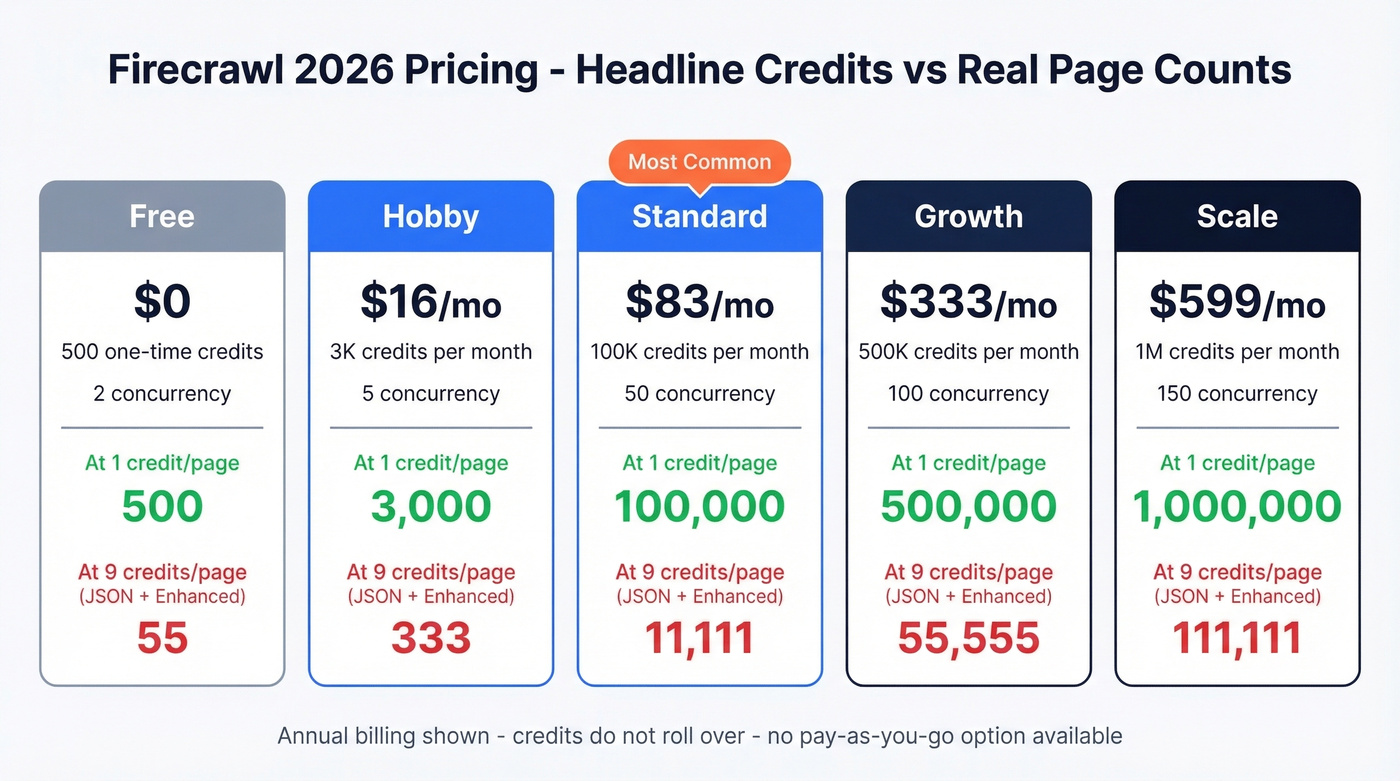
| Plan | Monthly Cost | Credits/Mo | Concurrency | Extra Credits |
|---|---|---|---|---|
| Free | $0 | 500 (one-time) | 2 | N/A |
| Hobby | $16 | 3,000 | 5 | $9 per extra 1k |
| Standard | $83 | 100,000 | 50 | $47 per extra 35k |
| Growth | $333 | 500,000 | 100 | $177 per extra 175k |
| Scale | $599 | 1,000,000 | 150 | Contact sales |
| Enterprise | Custom | Custom | Custom | Bulk discounts |
Credits don't roll over month to month. There's no pay-as-you-go option. The /extract endpoint is billed separately on a token-based track, which is easy to miss when budgeting.
What "1 Credit Per Page" Actually Means
"1 credit per page" is technically true for a bare scrape/crawl. But the moment you turn on features most teams actually need, modifiers stack:

| Modifier | Extra Credits |
|---|---|
| Base scrape/crawl | 1 |
| JSON format (LLM extraction) | +4 |
| Enhanced Mode | +4 |
| Zero Data Retention | +1 |
| Total (all on) | 10/page |
Search costs 2 credits per 10 results. Browser sandbox runs 2 credits per browser minute.
We ran the numbers on a typical LLM pipeline project using Hobby's 3,000 credits. With JSON format + Enhanced Mode enabled - a common combo for RAG pipelines - you're spending 9 credits per page. That's 333 pages, not 3,000. On Standard at 100,000 credits, the same config gets you ~11,111 pages. Still solid, but a far cry from the "100,000 pages" headline.
This is a common complaint in developer communities: the headline credit count feels misleading once you flip on the features you actually need. Budget 1-10+ credits per successful page depending on which modifiers you enable, and budget higher for protected sites where retries eat credits too.
The Agent endpoint adds another wrinkle: 5 free daily runs, then dynamic pricing that's hard to predict before you ship.
Pros
LLM-ready output. Markdown and structured JSON come back clean, reducing token waste and preprocessing in RAG pipelines.
Managed infrastructure. Proxy rotation, JavaScript rendering, and anti-bot handling are handled for you. No Puppeteer clusters to babysit.
Developer-friendly. SDKs for Python, Node.js, Go, and Rust. Webhook signing via HMAC-SHA256 for production crawl workflows. MCP server integration for AI coding tools like Cursor and Claude Desktop.
High concurrency at scale. Up to 150 concurrent requests on the Scale plan - enough for serious data pipeline work.
Active development. ~97k GitHub stars, frequent releases, and a responsive team on issues.
If you're evaluating Firecrawl to extract B2B contact data from websites, you're overengineering it. Prospeo gives you 143M+ verified emails and 125M+ mobile numbers - no scraping, no credit modifiers, no pipeline to maintain. 98% email accuracy at ~$0.01 per lead.
Skip the scraping pipeline. Get the contacts directly.
Cons
Here's the thing: the cons aren't dealbreakers if you go in with eyes open. But most people don't.
Credit modifiers make real costs 5-9x the headline. JSON format + Enhanced Mode turns a 1-credit page into a 9-credit page. Most teams discover this after their first real project. Unused plan credits vanish at the end of each billing cycle - no rollover.
No pay-as-you-go. A TypingMind community thread flags this directly - if you need occasional scraping, you're stuck buying a monthly plan you won't fully use.
Free plan crawl is effectively broken for some use cases. Users report "Insufficient credits" errors on crawl attempts. GitHub issue #2460 was closed as "not planned."
Self-hosted version is a subset, not a mirror. No Agent, no Browser sandbox, no Actions, no proxy rotation, no dashboard. GitHub issues from early 2026 also report crawls hanging indefinitely and 429 rate-limit errors on concurrent scrapes. AGPL-3.0 means commercial self-hosting has licensing implications your legal team should review.
Open Source vs Cloud
| Feature | Open Source | Cloud |
|---|---|---|
| Scrape/Crawl/Map | Yes | Yes |
| Extract + JSON | Yes | Yes |
| SDKs + Search | Yes | Yes |
| Agent + Browser | No | Yes |
| Proxy rotation | No | Yes |
| Dashboard + Actions | No | Yes |

Self-hosting saves money but strips out the features that make the cloud product worth paying for. In our experience, the gap between the two is wider than it looks on paper.
Who Should (and Shouldn't) Use It
Use it if you're building AI/RAG applications that need clean markdown from arbitrary web pages, you need managed JS rendering at scale without running your own proxy fleet, and your team is comfortable with API-first tools and can budget for real credit costs.
Skip it if you only scrape occasionally, you're budget-constrained and the credit burn math doesn't work at your volume, or your actual goal is B2B contact data rather than raw web content. If you need emails and phone numbers from company websites, you don't need a scraping API - that's a different category of tool entirely.
Look, Firecrawl is genuinely best-in-class for LLM-ready web data. But at least half the people evaluating it actually need contact data, not a scraping pipeline. If that's you, stop here and go get a data platform. You'll save weeks of building something you didn't need to build.
Alternatives Worth Considering
Crawl4AI. Free, open-source Python library with zero credit system and full local control. You manage infrastructure, proxies, and scaling yourself - great for developers who don't mind the ops work, but it won't hold your hand. The consensus on r/webscraping is that it's the go-to for teams with strong Python chops and modest scale requirements. If you're specifically doing web scraping lead generation, it's worth comparing the operational overhead.
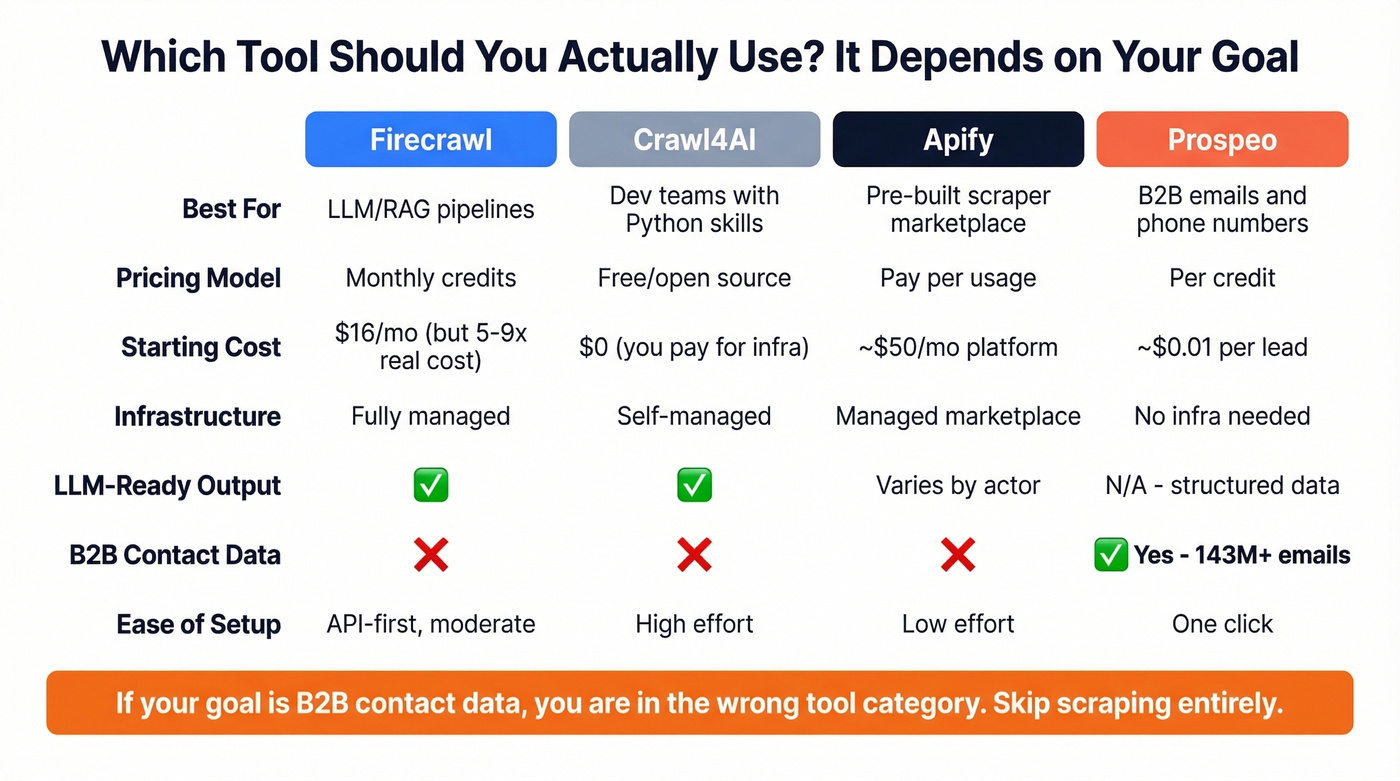
Apify. A marketplace of pre-built scrapers with a pay-per-usage model that solves the no-pay-as-you-go problem. Plans start around $50/mo for platform features, with per-result pricing on individual actors. Better for teams who want ready-made solutions without writing custom scraping logic.
Prospeo. Different tool for a different job. If you're evaluating Firecrawl because you need emails and phone numbers from company websites, skip the scraping pipeline. Prospeo provides 300M+ professional profiles, 143M+ verified emails with 98% accuracy, and 125M+ verified mobile numbers - no code required, no credit modifiers to decode. If you're comparing tools in this category, start with data enrichment services and best sales prospecting databases.
Other options worth a look: Bright Data for enterprise proxy networks and Skyvern for vision-based browser automation.
Final Verdict
The credit burn was the single biggest surprise in our testing - and it's the thing that determines whether Firecrawl is a good deal or a bad one for your specific workload. Standard at $83/mo is the realistic starting point for production use cases. Self-hosting saves money but strips out the features that justify the product.
And if your goal was always contact data - verified emails, direct dials, company info - you were looking at the wrong category entirely. Understanding Firecrawl pricing, reviews, pros and cons comes down to one thing: run the credit math on your actual workload before you commit. If you're building outbound around that data, pair it with sales prospecting techniques, a solid lead generation workflow, and the right SDR tools.
Firecrawl's 9-credit-per-page math means your Standard plan covers ~11K pages. Prospeo's Chrome extension pulls verified emails and direct dials from any company website in one click - 40,000+ users already do. No proxies, no rendering, no credit surprises.
One click beats a thousand lines of scraping code.