Firecrawl vs Scrapy: The Honest Comparison Nobody Else Will Write
Firecrawl and Scrapy aren't direct substitutes for most teams. Comparing them is like comparing a taxi to buying a car - one gets you there fast with zero setup, the other costs more upfront but pays for itself at scale.
30-Second Verdict
Firecrawl wins if you're scraping fewer than 1,000 pages/month, need LLM-ready markdown/JSON, and don't want to touch infrastructure.
Scrapy wins if you're past 10,000 pages/month, care about cost control, and want full orchestration power.
Under 10 pages? Use requests + BeautifulSoup. Don't overthink it.
What Each Tool Actually Is
Firecrawl
Firecrawl is an API-first scraping service that outputs clean markdown and structured JSON - formats LLMs consume directly without downstream parsing. It handles JavaScript-heavy pages, and the cloud version manages proxy rotation so you don't have to build that infrastructure yourself. The project is open source under AGPL-3.0, but the features that matter most for production (Agent, Browser sandbox, Actions, Enhanced proxies) are cloud-only. Self-hosting gets you the basics. The managed service is where the real value lives.
Here's the thing most comparisons skip: LLM-based extraction is less brittle than CSS/XPath selectors. When a site redesigns its DOM, your Scrapy spider breaks. Firecrawl's semantic extraction usually survives the change. For teams without dedicated scraping engineers, that maintenance difference matters more than raw throughput.
Scrapy
Scrapy is a Python framework built on the Twisted async engine - 55.1k GitHub stars, maintained by Zyte with over 500 contributors, current version 2.14.2. You write spiders using CSS/XPath selectors, plug in middlewares and pipelines, and host everything yourself.
The ecosystem runs deep: scrapy-playwright for JS rendering, scrapy-impersonate for request impersonation and TLS fingerprinting, and hundreds of community extensions. For most targets, Scrapy's direct-HTTP approach works fine without Playwright overhead. Practitioner rule-of-thumb says roughly 80% of e-commerce sites can be scraped browserless.
Head-to-Head Feature Comparison
| Feature | Firecrawl | Scrapy |
|---|---|---|
| Type | Managed API | Python framework |
| JS rendering | Built-in | Needs scrapy-playwright |
| Anti-bot | Enhanced proxies + Enhanced Mode (cloud) | DIY via proxies + plugins |
| Output format | Markdown, JSON, HTML | Raw HTML (you parse) |
| Pricing | Credit-based (1-9 credits/page depending on options) | Free + infra costs |
| Learning curve | Low (API calls) | Medium-high (Python required) |
| Throughput | ~2,276 results/hr | 10,000+ pages/hr on cooperative targets |
| Self-hostable | Yes (AGPL-3.0, limited features) | Yes (fully open) |
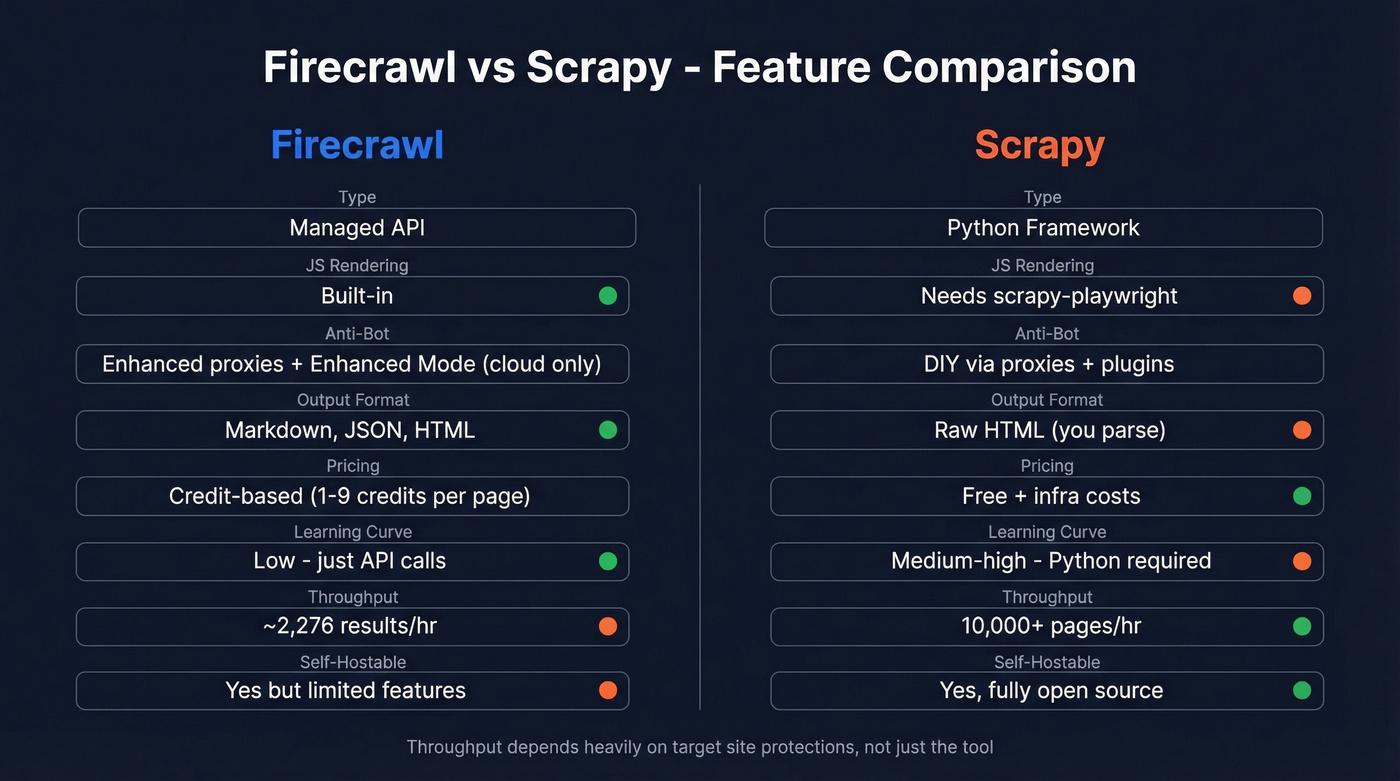
The throughput gap is real but misleading. Firecrawl's 2,276 results/hr comes from a Proxyway benchmark testing against well-protected sites. Scrapy's 10k+ figure assumes cooperative targets with minimal anti-bot defenses. The bottleneck is always the target site's protections, not the framework.
Firecrawl and Scrapy get you raw data. Neither gives you verified contact info. Prospeo's enrichment API takes your scraped domains and returns 98% accurate emails, direct dials from 125M+ verified mobiles, and 50+ data points per contact - at a 92% match rate.
Turn scraped company lists into outreach-ready contacts in seconds.
Credit Math Firecrawl Doesn't Advertise
Firecrawl's billing page says 1 credit per page. Technically true - for the simplest scrape with no options enabled. Turn on JSON mode for LLM extraction? That's +4 credits. Need Enhanced Mode for anti-bot handling? Another +4. A single page with both options costs 9 credits.
If you're using scraping for web scraping lead generation, this credit math is the difference between a test and a budget line item.

The Standard plan gives you 100,000 credits/month. Sounds generous until you do the math: at 9 credits per page, that's roughly 11,111 pages, not 100,000. Firecrawl offers a free tier with 500 one-time credits and a Hobby plan with 3,000 credits/month - enough to test the API but nowhere near production volume. They've admitted they're "actively working on improvements to make credit usage easier to understand."
Translation: the current system confuses people.
Real-World Cost Comparison
One Scrapy operator on r/webscraping shared their setup: 10k-30k news articles per day, 3.8M articles scraped total, running on about $150/month in infrastructure. They estimated a managed API would've cost $3k-$4.5k/month for the same volume. The targets were cooperative (RSS feeds, sitemaps, news sites), but the cost difference is staggering.
If you're trying to justify that spend internally, it helps to frame it as lead generation metrics and cost-per-record, not just "scraping costs."
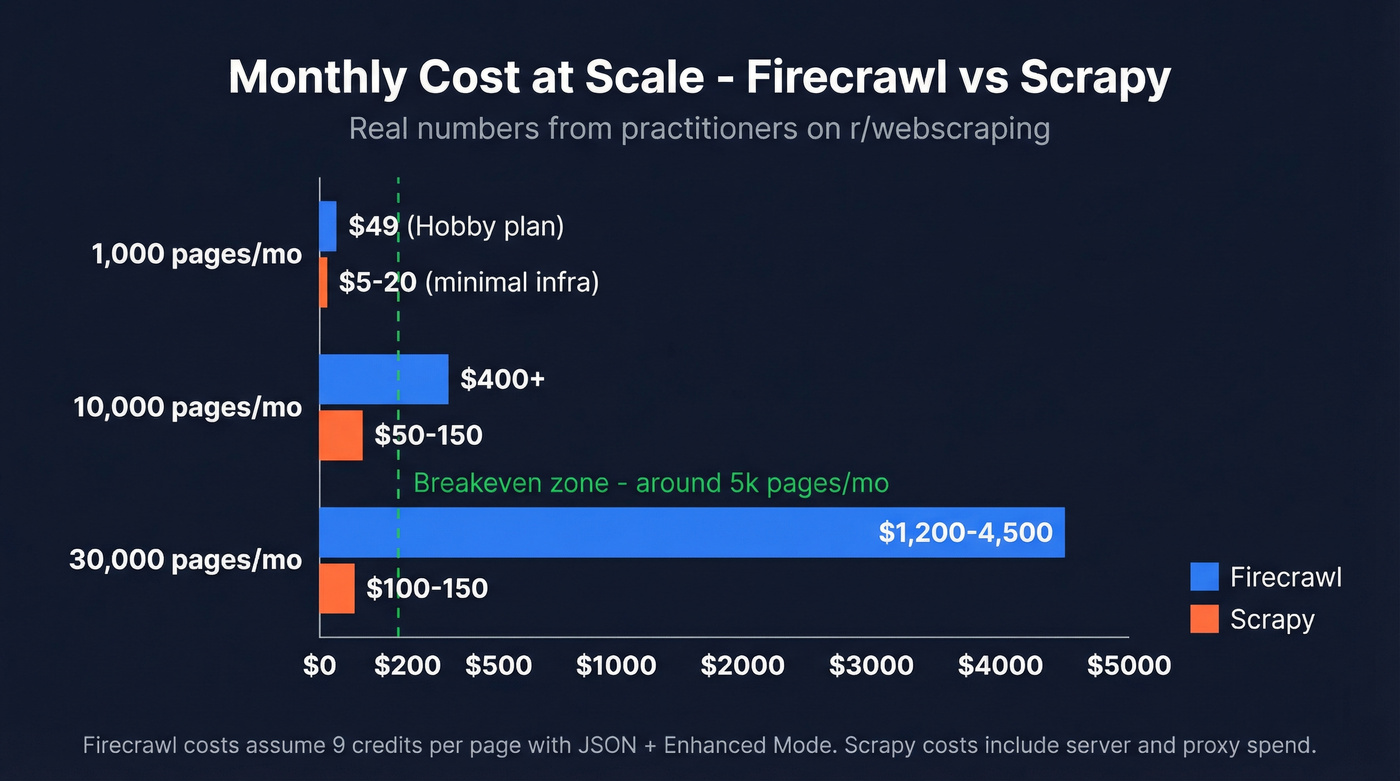
On the other side, a Firecrawl user scraping 10,000 domains for job postings called it "super slow" and "super expensive," estimating ~$400/month in API spend. We've seen this pattern repeatedly - managed APIs work great until you hit scale, then the math breaks. Though DIY at scale isn't free either: one practitioner running 25M requests/day reported $1,240/month in anti-detection costs alone.
Let's be honest: if you're scraping fewer than 5,000 pages/month and your time is worth more than $50/hour, Firecrawl saves you money. Past that threshold, every additional page is a tax on laziness. Learn Scrapy.
When to Use Which
LLM/RAG ingestion under 1k pages/month - Firecrawl. The markdown output saves hours of parsing, and the credit costs stay manageable.
If your end goal is outbound, pair that with a data enrichment tool so the scrape turns into usable contacts.
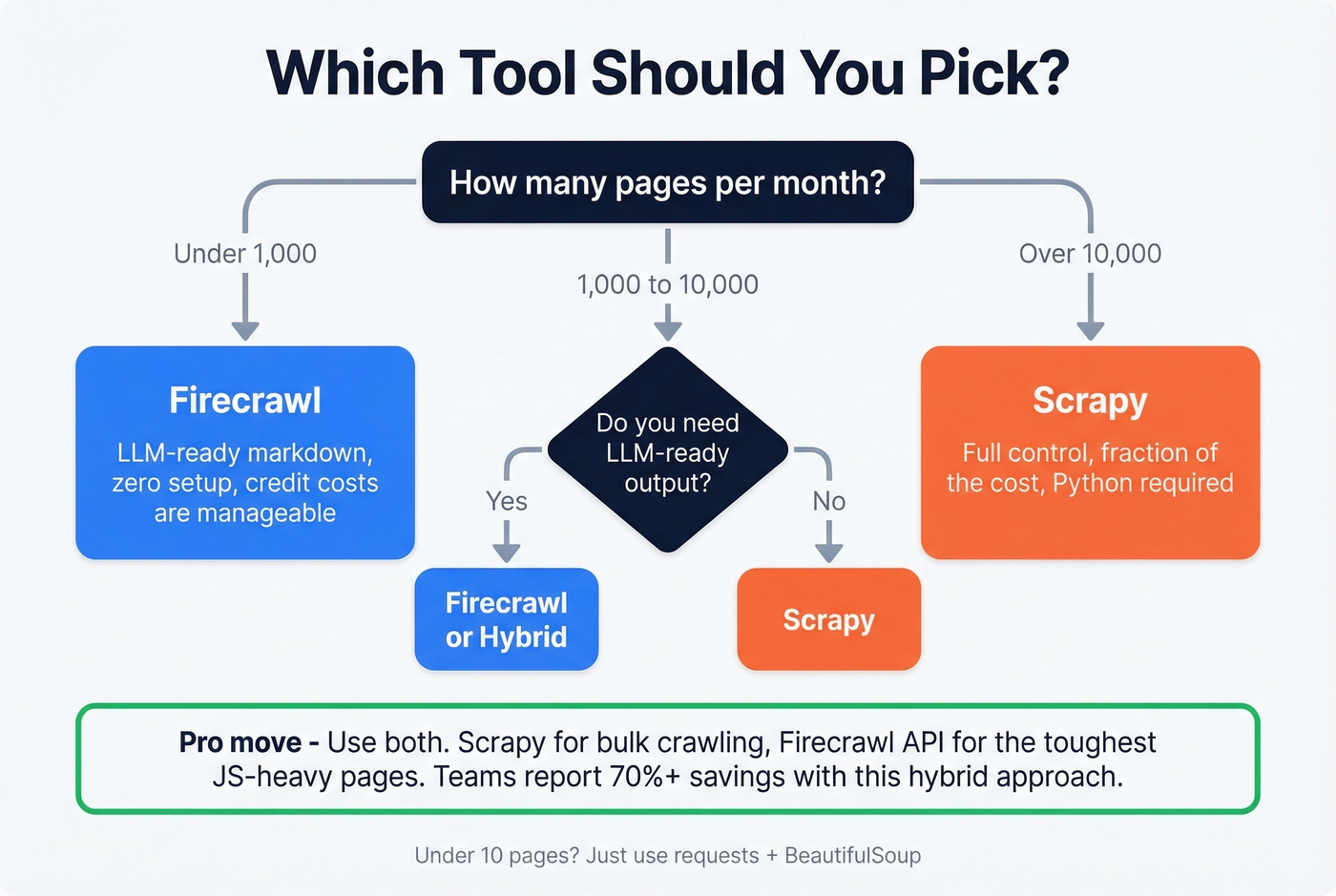
Scale past 10k pages/month - Scrapy. The economics aren't close. Even with proxy costs, you'll spend a fraction of what Firecrawl charges.
Heavily protected sites like Cloudflare or Akamai - neither tool alone solves this. You'll need Scrapy paired with commercial proxies or a dedicated unblocking API. Firecrawl hit ~33.69% success in the Proxyway benchmark against well-protected sites, which isn't production-grade.
The hybrid pattern - in our experience, this is underused. Run Scrapy for orchestration and crawl logic, then route the toughest JS-rendered pages through Firecrawl's API. You get cost control on the bulk while using Firecrawl where it actually adds value. We've seen teams cut their Firecrawl spend by 70%+ just by being selective about which URLs they send to the API.
Turning Scraped Data into Contacts
Whether you pick Firecrawl or Scrapy, scraped data is only half the pipeline. If you're pulling company directories, team pages, or job boards for sales intelligence, you've got URLs and company names - not contacts.
Prospeo handles the next step: upload a CSV of domains, get back verified emails with 98% accuracy and direct dials from 125M+ verified mobiles. With a 92% API match rate and 50+ data points returned per enrichment, you go from raw scrape to outreach-ready list without manual research.
Once you have contacts, the next bottleneck is messaging and sequencing - use proven sales prospecting techniques and keep your follow-ups tight with sales follow-up templates.
You just spent hours debating frameworks, configuring proxies, and optimizing credit spend. Don't waste that effort on manual contact research. Upload your scraped CSV to Prospeo and get verified emails at $0.01 each - with a 7-day data refresh cycle that keeps your lists clean.
Stop scraping for contacts when 143M+ verified emails are already waiting.
FAQ
Can Firecrawl replace Scrapy entirely?
No. Firecrawl excels at LLM-ready output, not high-volume orchestration. At 9 credits per page with full options, 100k credits covers only ~11k pages. For anything beyond light-volume extraction, you need a framework that doesn't meter every request.
Is Scrapy still worth learning in 2026?
Absolutely. With 55.1k GitHub stars, 500+ contributors, and active maintenance by Zyte, it's the most battle-tested open-source crawling framework available. The ecosystem keeps it competitive against modern anti-bot defenses, and nothing else matches its cost efficiency at scale.
What's the best way to enrich scraped company data with contacts?
Upload your scraped CSV - domains, company names, URLs - to a data enrichment tool like Prospeo. It returns verified emails and phone numbers with a 92% API match rate, so you move straight from raw data to outreach without manual research.
Should I self-host Firecrawl instead of paying for the API?
Self-hosting saves on credits but strips the most valuable features. Enhanced Mode, Agent, and managed proxies are cloud-only. If you've got the DevOps capacity, self-hosting works for basic markdown extraction. For anti-bot handling or structured LLM output, you'll still need the paid API or a Scrapy-based alternative.