
Scrapy Alternatives: The Right Tool for Every Scraping Job in 2026
You're configuring scrapy-playwright for a JS-heavy site, it's painful on Windows, and you're two hours into debugging Twisted reactor conflicts. That's the moment you realize Scrapy isn't the right tool anymore. Here's the reality: 94% of modern websites now rely on client-side rendering, and Scrapy was built for a static HTML web. Its Twisted foundation puts it at odds with the Python ecosystem's move to Asyncio - every modern library from HTTPX to Playwright speaks Asyncio natively, and Twisted compatibility is a constant friction point.
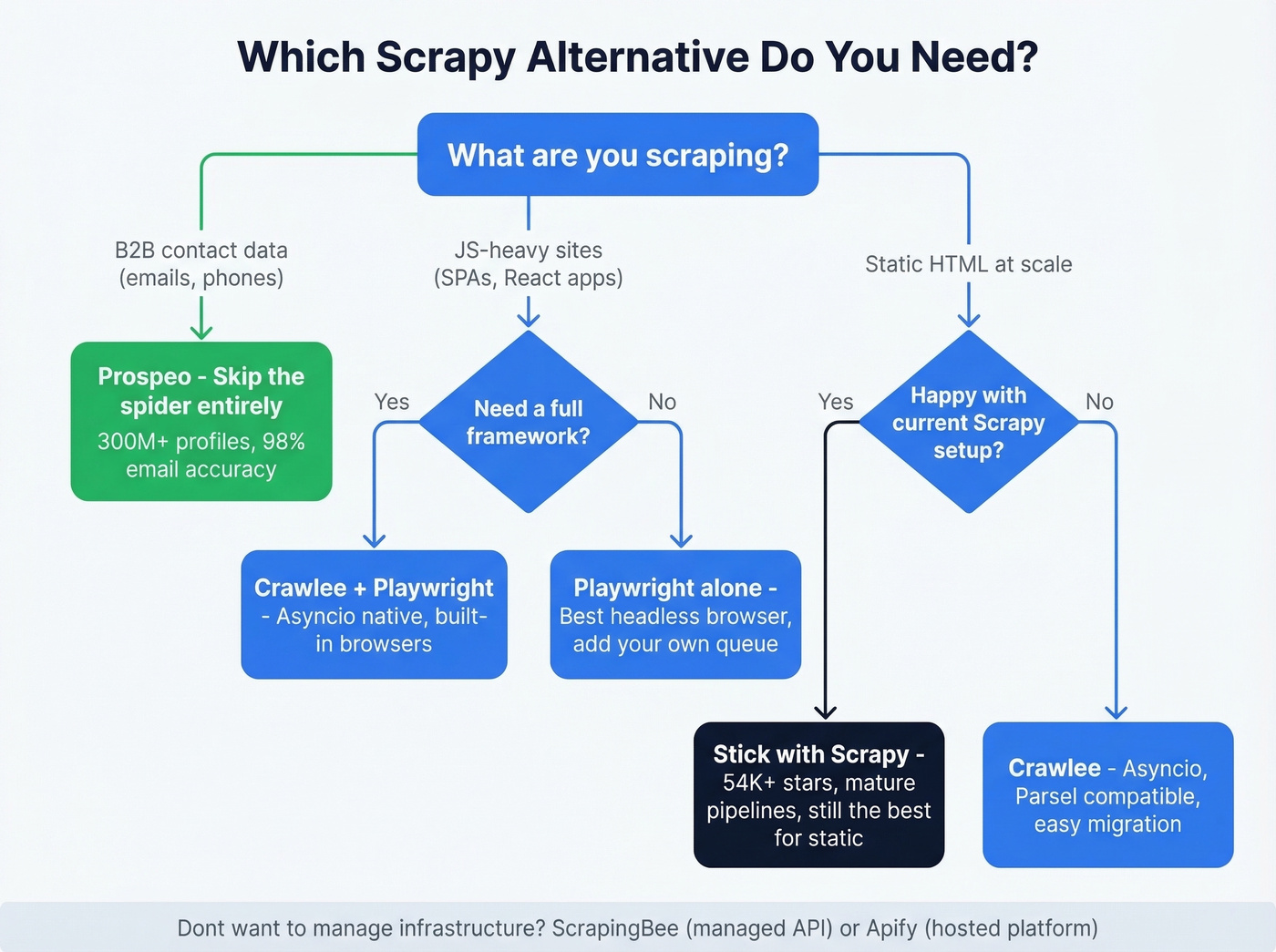
We've built scrapers on most of these frameworks. The right choice depends on which layer of the scraping stack you're actually trying to replace. You don't need ten tools. You need two or three that match your use case.
Why Developers Switch from Scrapy
The core frustration is JavaScript. Scrapy has no native JS rendering. You can bolt on scrapy-playwright, but it's a plugin with platform limitations and it never feels like a first-class citizen. For teams scraping SPAs and React apps, this alone is a dealbreaker.
Then there's the boilerplate. Spiders, items, pipelines, middlewares, settings - you're writing serious scaffolding before extracting a single field. For a quick scrape of 50 pages, that's overkill, and newer frameworks get you to working code faster. Scrapy's Twisted dependency means reactor conflicts and event loop mismatches whenever you try to integrate modern Asyncio libraries. It's not that Twisted is bad. The rest of Python simply moved on.
The Scraping Stack Mental Model
Stop thinking about replacements as a 1:1 swap. Scraping is a stack, and Scrapy covers multiple layers at once. When you want an alternative, you're really asking which layer needs replacing.
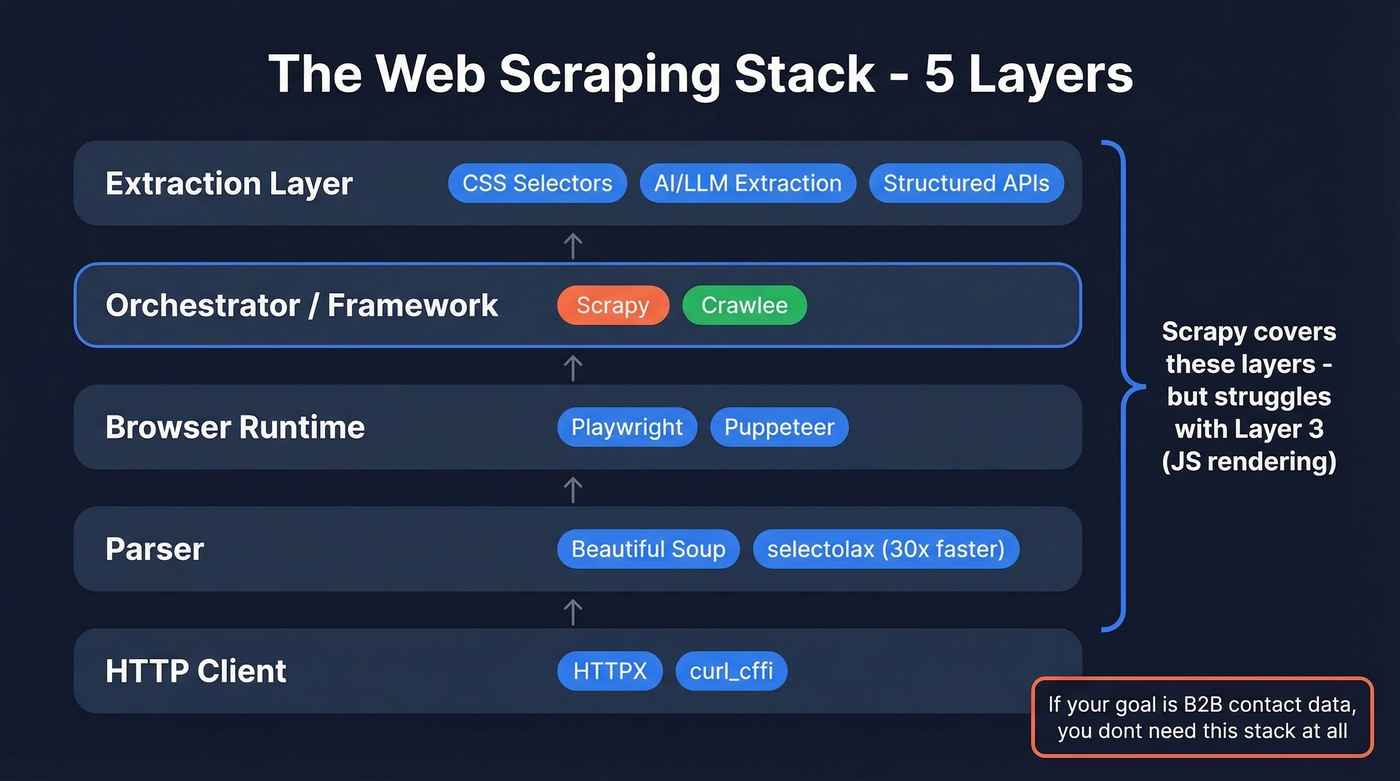
The five layers: HTTP client (HTTPX, curl_cffi) -> Parser (Beautiful Soup, selectolax) -> Browser runtime (Playwright, Puppeteer) -> Orchestrator/framework (Scrapy, Crawlee) -> Extraction layer (CSS selectors, AI/LLM extraction, structured APIs). If you need JS rendering, you're replacing the browser runtime. If you need faster parsing, swap the parser - selectolax parses HTML up to 30x faster than Beautiful Soup. And if you need B2B contact data, you don't need a scraping stack at all - see web scraping lead generation for when scraping is actually the right approach.
Quick Reference
| Your Goal | Pick | Why |
|---|---|---|
| Full framework replacement | Crawlee | Asyncio, built-in browsers, autoscaling |
| JS-heavy site scraping | Playwright | Best headless browser, any JS |
| B2B contact data | Prospeo | 300M+ verified profiles, no code |
Building scrapers for B2B contact data is solving the wrong problem. Prospeo gives you 300M+ profiles, 143M+ verified emails at 98% accuracy, and 125M+ mobile numbers - all searchable with 30+ filters including buyer intent and technographics. Data refreshes every 7 days, not whenever your spider runs.
Skip the spider. Get verified contacts at $0.01 per email.
Best Web Scraping Frameworks and Tools
Crawlee
Use this if you want a true framework replacement that solves Scrapy's architectural problems without abandoning the crawler paradigm. Crawlee runs on Asyncio, has built-in Playwright and Puppeteer support for JS rendering, and includes autoscaling via AutoscaledPool. The breadth-first default is often a better starting point for common crawling patterns, and Parsel compatibility means migrating your selectors is nearly seamless - existing Scrapy extraction logic can usually transfer with minimal changes.
We've found the Python version mature enough for production use, though the TypeScript version has a longer track record. It's free and open-source. If you want managed hosting, Apify hosts Crawlee projects starting at $29/mo.
Skip this if you have a large, stable Scrapy codebase that works. Migration for migration's sake isn't worth it.
Prospeo
Use this if your scraping goal is B2B contact data - emails, phone numbers, company information. Building a spider to crawl company websites and guess email formats is solving the wrong problem.
Here's the scenario: your manager asks for 5,000 contacts at VP+ level in SaaS companies with 50-500 employees. You could spend a week building scrapers, handling anti-bot measures, and verifying emails. Or you could search Prospeo's database of 300M+ professional profiles using 30+ filters - buyer intent, technographics, job changes, funding - and export verified contacts in minutes. The numbers: 143M+ verified emails at 98% accuracy, 125M+ verified mobile numbers, all refreshed on a 7-day cycle. At roughly $0.01 per email with a free tier of 75 emails/month, it's cheaper than the compute costs of running scrapers. If you’re comparing data providers, start with best sales prospecting databases and best B2B company data providers.
Playwright
Playwright is the best headless browser library available. Period. It supports Chromium, Firefox, and WebKit, handles auto-waiting for elements, and offers network interception to block unnecessary assets and speed up loads. With 71K+ GitHub stars, it's the dominant browser automation tool, operating at the browser runtime layer of the stack.
Skip this if you're scraping static HTML at scale. Playwright isn't a crawler framework - you'll need your own request queue, retry logic, and rate limiting. Each parallel browser context eats roughly 1-2GB of RAM, so scaling gets expensive fast. For most teams, pairing Playwright with Crawlee (which wraps it) is the practical move.
Free and open-source. The cost is infrastructure.
Firecrawl
Firecrawl converts web pages into clean Markdown optimized for LLM pipelines, operating at the extraction layer of the stack. Markdown uses roughly 67% fewer tokens than raw HTML, directly cutting your API costs when feeding data into GPT-4 or Claude. It claims 96% web coverage versus 79% for Puppeteer and 75% for cURL, and it has 77K+ GitHub stars.
Pricing is credit-based: free tier gives 500 one-time credits, Hobby runs $16/mo for 3,000 credits, Standard is $83/mo for 100,000 credits. One page scrape costs one credit.
ScrapingBee
ScrapingBee is the "I don't want to manage infrastructure" option. Send a URL via API, get back rendered HTML. No proxy rotation, no headless browsers, no Chromium crashes at 3 AM. JavaScript rendering, residential proxies, and CAPTCHA solving all happen behind the scenes.
Pricing starts at $49.99/mo for 250K API credits and scales to $99.99/mo for 1M credits. For teams that need scraping as a utility rather than a core competency, it eliminates the ops burden entirely. If you’re evaluating similar services, see ScrapingBee alternatives.
Apify
Apify is a platform, not a library. It hosts Crawlee in the cloud, offers 200+ pre-built scrapers (Actors), and handles scheduling, storage, and monitoring. Think of it as Crawlee plus managed infrastructure plus an app store.
The pricing deserves scrutiny. The Starter plan is $29/mo, but compute units run $0.30/CU, residential proxies cost $8/GB, and extras like $5 per concurrent run and $2/GB Actor RAM add up. In our experience, moderate scraping operations land at $100-300/mo. The $29 sticker price is the door - not the room.
Lighter Options Worth Knowing
Beautiful Soup + HTTPX is the knife, not the kitchen. Beautiful Soup parses; HTTPX fetches asynchronously. Under 20 lines of code for basic static scraping. But the moment you need JS rendering, retries, or proxy rotation, you've outgrown it.
Puppeteer (90K+ GitHub stars) is Playwright's predecessor - Node.js only, Chromium only. It still works, but Playwright has largely superseded it with multi-browser support and a better API. For new projects, pick Playwright.
Selenium is a testing tool that people use for scraping. It's slow, resource-heavy, and not designed for data extraction. We wouldn't start a new scraping project with Selenium in 2026.
Pricing Comparison
Open-source tools cost nothing to download but require infrastructure. Managed platforms charge per credit or compute unit.

| Tool | Free Tier | Starting Price | Model | Best For |
|---|---|---|---|---|
| Crawlee | Yes (OSS) | Free / $29/mo on Apify | Open-source + hosted | Framework replacement |
| Prospeo | 75 emails/mo | ~$0.01/email | Credit-based | B2B contact data |
| Playwright | Yes (OSS) | Free | Open-source | JS rendering |
| Firecrawl | 500 credits | $16/mo | Credit-per-page | LLM/AI pipelines |
| ScrapingBee | No | $49.99/mo | API credits | Managed scraping |
| Apify | $5 usage credit | $29/mo + usage | Platform + CU | Hosted crawling |
| Beautiful Soup | Yes (OSS) | Free | Open-source | Simple parsing |
| Puppeteer | Yes (OSS) | Free | Open-source | Node.js browser automation |
| Selenium | Yes (OSS) | Free | Open-source | Legacy browser automation |
| ScrapeGraphAI | 50 credits | $20/mo | Credit-based | AI extraction* |
\Limited independent reviews; no G2 rating available as of early 2026.*
When to Stick with Scrapy
Scrapy isn't dead. It powers an estimated 34% of production scraping projects, has 54K+ GitHub stars, and Scrapy 2.11 delivers 40% better performance than previous versions. Serverless and containerized scraping solutions grew 156% year-over-year, but that doesn't make Scrapy obsolete - it makes the ecosystem bigger.
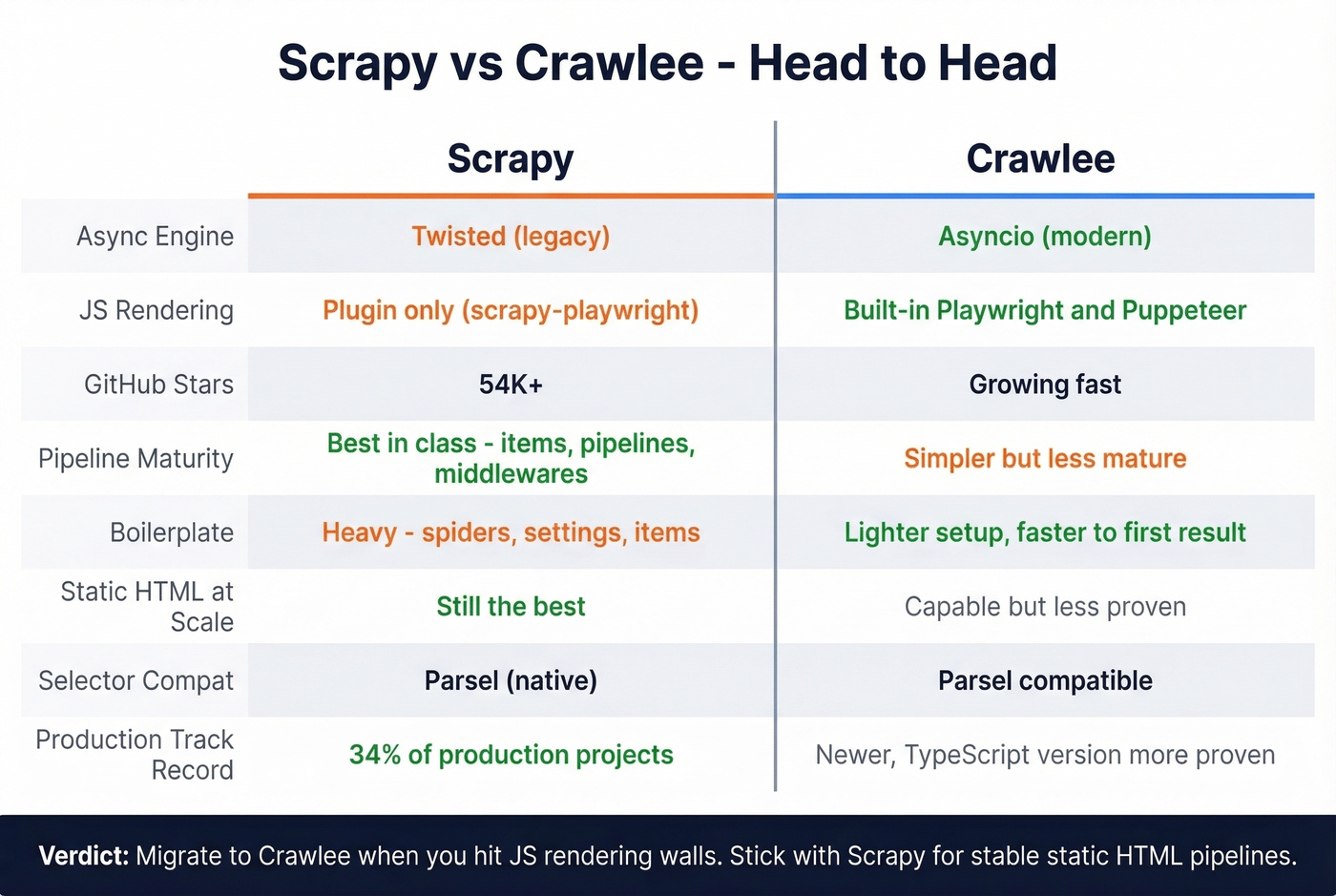
If you're crawling large volumes of static HTML with complex pipeline logic - e-commerce catalogs, news archives, government data - Scrapy is still the best tool for the job. Its pipeline architecture for cleaning, validating, and storing data is more mature than anything Crawlee offers today. Migrate when you hit a wall, not because a blog post told you to.
Let's be honest: most teams don't need a full framework at all. If your average deal size is small and you're scraping for lead data, you're over-engineering the problem. A data platform gets you there faster than any spider ever will - especially if your workflow includes email crawlers and downstream data enrichment services.
In 2026, the standard production pattern is still a hybrid stack - an HTTP crawler like Scrapy or Crawlee for throughput, Playwright for JS-heavy pages, and a proxy layer when you're dealing with bot protection. The best scrapy alternatives aren't about replacing everything. They're about picking the right tool for each layer.
You're debugging Twisted reactor conflicts and proxy rotation to find email addresses. Meanwhile, 15,000+ companies pull verified B2B contacts from Prospeo in minutes - no code, no anti-bot headaches, no infrastructure costs. 75 free emails/month to prove it.
Replace your contact scraping pipeline with one search.
FAQ
Can Scrapy handle JavaScript-rendered websites?
Not natively. You need scrapy-playwright or Splash, both adding complexity and platform-specific limitations. Playwright or Crawlee handle JS rendering out of the box with first-class browser support - no plugins required.
What's the easiest alternative for beginners?
Beautiful Soup + HTTPX for simple static tasks - under 20 lines of code to get results. For a full framework with a gentler learning curve, Crawlee offers project templates, built-in autoscaling, and better onboarding docs than Scrapy.
Which tool is best for large-scale crawling?
Crawlee matches Scrapy's scale with native Asyncio architecture and built-in autoscaling via AutoscaledPool. For managed infrastructure, Apify hosts Crawlee in the cloud. Budget 1-2GB RAM per browser context when running headless browsers at scale.
Are there free open-source options?
Yes - most are free. Crawlee, Playwright, Beautiful Soup, Puppeteer, and Selenium are all open-source. Managed platforms like Firecrawl (500 credits) and Apify ($5 usage credit) offer limited free tiers for testing.
What if I need B2B contact data, not web scraping?
Skip building scrapers entirely. Prospeo gives you 300M+ verified professional profiles with 98% email accuracy, searchable with 30+ filters including buyer intent and technographics. The free tier includes 75 emails/month - no code or infrastructure required.