
11 Best Apify Alternatives for 2026
You just watched a $7 compute-unit bill roll in for 1,000 Google Maps listings. The Actor worked - mostly - but 200 results came back malformed, and the maintainer's last commit was four months ago. Apify is a powerful platform, but it's not the only game in town, and for a lot of use cases it's not even the right one.
The global web scraping market is projected to nearly double from $1.03B to $2B by 2030. That growth means more tools, more specialization, and more reasons to pick the right one for your specific workflow instead of defaulting to a general-purpose platform. Apify deserves credit - 10,000+ Actors in the marketplace, a 4.7/5 on G2 across 400+ reviews, and the Crawlee SDK is genuinely excellent for developers. But "powerful and flexible" doesn't mean "right for everyone."
Here are 11 alternatives across every category that matters: API-first scraping, no-code visual tools, enterprise proxy infrastructure, open-source frameworks, and one option that sidesteps scraping entirely.
Quick Picks
| Scenario | Pick | Why |
|---|---|---|
| AI/LLM workflows | Firecrawl | LLM-ready markdown output |
| No-code scraping | Octoparse | Point-and-click visual builder |
| Verified business contacts | Prospeo | 300M+ profiles, 98% email accuracy |
| Open-source framework | Scrapy | Free, massive ecosystem |
| Enterprise scraping API | Zyte | 93% success on protected sites |
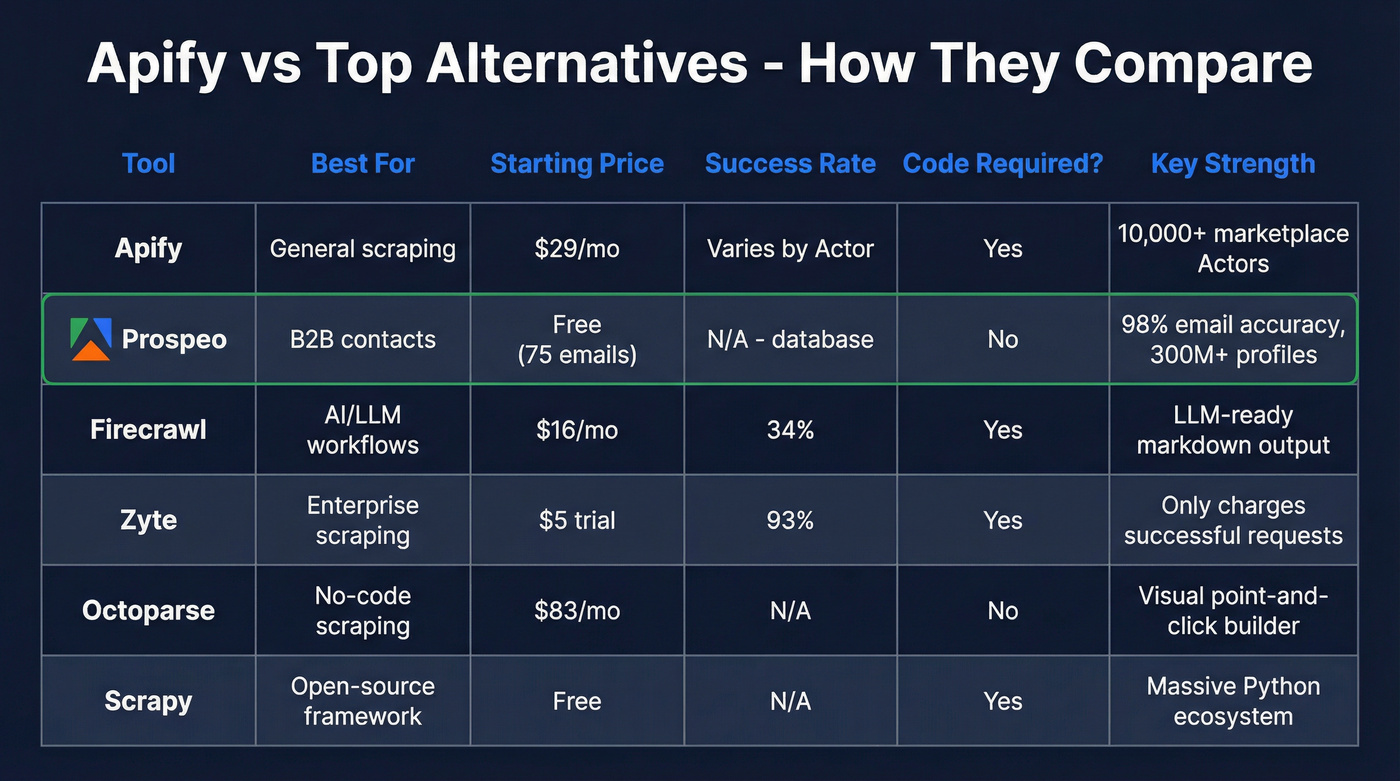
Why Teams Switch From Apify
Apify is good. G2 reviewers consistently praise the concurrency, retry logic, and scheduling. But three friction points push teams elsewhere.
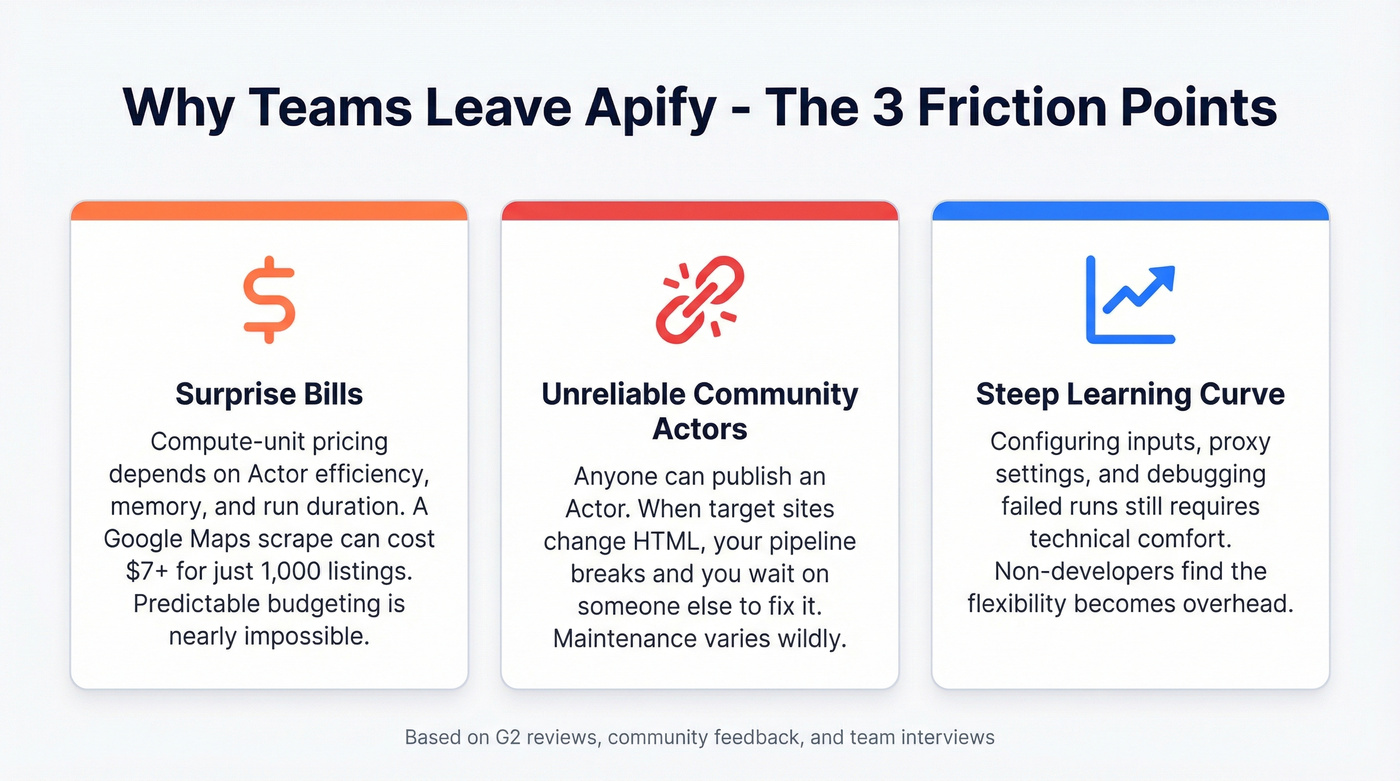
Pricing complexity and surprise bills. Apify's compute-unit model means your actual cost depends on Actor efficiency, memory allocation, and run duration - none of which you fully control when using community-built Actors. The Starter plan is $29/mo with $29 in platform credits; Scale runs $199/mo. But compute-unit billing surprises are the number-one complaint we hear. That Google Maps scrape? It can run $7+ for 1,000 listings when you factor in CU consumption and proxy bandwidth. Predictable budgeting is nearly impossible.
Community Actor reliability. The marketplace's greatest strength is also its risk. Anyone can publish an Actor, and maintenance varies wildly. When a target site changes its HTML structure, your pipeline breaks and you're waiting on someone else's goodwill to fix it. Lower-tier plans also cap concurrency, which throttles throughput right when you need to scale.
Steep learning curve for non-developers. Despite the no-code promise of prebuilt Actors, configuring inputs, understanding proxy settings, and debugging failed runs still requires technical comfort. If you're a marketer who just needs data in a spreadsheet, Apify's flexibility becomes overhead.
Best Apify Alternatives in 2026
Prospeo - Best for Verified Business Contact Data
If your end goal is contact data for sales outreach, scraping is an unnecessary detour. You'd need a scraping tool, a proxy service, a CAPTCHA solver, and then an email verification step - four tools and four bills to get what Prospeo delivers in a single search.
Prospeo's database covers 300M+ professional profiles with 143M+ verified emails and 125M+ verified mobile numbers. Email accuracy runs 98%, and the data refreshes every 7 days - compared to the 6-week industry average. You get 30+ search filters including buyer intent powered by Bombora, technographics, job changes, and headcount growth signals.
The cost math makes this a no-brainer for lead gen teams. At roughly $0.01 per verified email, you're paying a fraction of what a scraping pipeline costs - and you're not risking your sender reputation on unverified addresses. The free tier gives you 75 verified emails per month to test, no credit card required.
Use this if: Your actual goal is verified emails and phone numbers for outbound. You want data ready to push into Smartlead, Instantly, or HubSpot without a verification step.
Skip this if: You need raw HTML, product pricing data, or SERP results. Prospeo is a B2B contact platform, not a web scraper.
Firecrawl - Best for AI/LLM Workflows
Firecrawl does one thing exceptionally well: it turns web pages into clean, LLM-ready markdown. If you're building AI agents that need to consume web content - or connecting tools via MCP servers for agentic workflows - this is the tool that saves you from writing parsing logic.
The credit model is straightforward: 1 credit per page for scraping and crawling, 2 credits per browser minute. The free plan gives you 500 credits as a one-time allotment. Hobby runs $16/mo for 3,000 credits, Standard is $83/mo for 100,000 credits, and Growth and Scale plans run $333/mo and $599/mo respectively.
The honest tradeoff: on well-protected sites, Firecrawl's success rate is low. In the Proxyway December 2025 benchmark, it hit 33.69% success at 2 rps - the lowest of the four providers in that snapshot. For public, unprotected pages feeding into RAG pipelines or AI agents, it's excellent. For scraping behind Cloudflare or aggressive bot detection, look elsewhere.
Use this if: You're a developer building AI agents or LLM workflows that need structured web content.
Skip this if: Your targets use serious anti-bot protection. A 34% success rate means two-thirds of your credits are wasted.
ScraperAPI - Best Simple Proxy API
ScraperAPI sits in the sweet spot between DIY proxy management and enterprise infrastructure. You send a URL, it handles rotation, CAPTCHAs, and retries, and returns the HTML. Entry plans start around $29/mo.
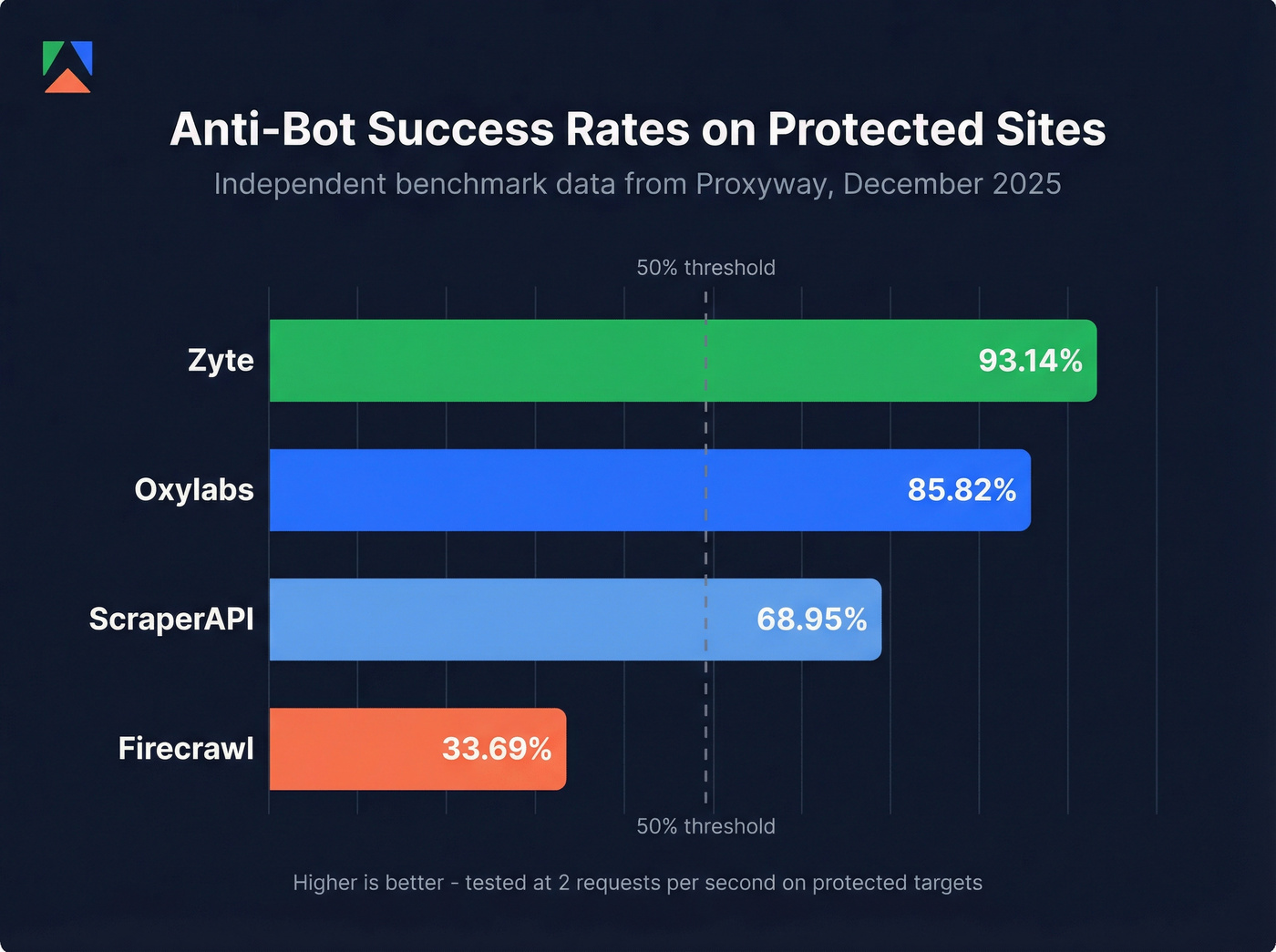
Independent testing puts ScraperAPI at 68.95% success on protected sites - roughly double Firecrawl's rate, though well below Zyte's 93%. For teams that need reliable scraping without managing proxy pools, it's a solid middle ground.
Use this if: You want a simple API that handles proxies and CAPTCHAs without enterprise pricing.
Skip this if: You're scraping heavily protected sites at scale - Zyte's success rate is meaningfully higher.
Zyte - Best Enterprise Scraping API
Zyte leads independent benchmarks at 93.14% success on protected sites, and it only charges for successful responses. Failed requests don't eat your budget - a meaningful differentiator when you're running millions of requests.
Pricing is tiered by site difficulty and rendering type. Simple HTTP responses run $0.13-$1.27 per 1,000 depending on the target. Browser-rendered pages jump to $1.01-$16.08 per 1,000. There's a $5 free trial credit to test.
Use this if: Anti-bot bypass is your primary concern and you need enterprise-grade reliability.
Skip this if: You want simple, predictable pricing. Zyte's tiered model rivals Apify's complexity.
Octoparse - Best Visual Scraper
Octoparse is the tool you hand to a marketing analyst who needs to scrape competitor pricing from 50 product pages. The point-and-click interface lets non-developers build extraction workflows visually, and cloud scheduling automates recurring runs.

The free plan covers 10 tasks with local-only execution. Paid plans start around $83-$119/mo depending on tier and billing, with cloud access and more concurrency on higher plans. But here's what catches people off guard: the add-on costs. Residential proxies run $3/GB, CAPTCHA solving is $1-$1.50 per thousand, and setup help starts at $399. A base plan can quietly become $200+ once you're scraping anything with bot protection.
Use this if: You're a non-developer who needs structured data from specific websites and you're comfortable with the real total cost.
Skip this if: You need to scrape at scale across hundreds of domains. The per-GB proxy costs add up fast.
Browse AI - Best for Change Detection
Browse AI's strength isn't one-time bulk extraction - it's automated monitoring. Set up a "robot" to watch a page, and it alerts you when prices change, inventory shifts, or content updates.
The free plan gives 50 credits/mo, roughly 500 rows of data. The pricing gap between annual and monthly is steep: Personal plans run $19/mo annually versus $48/mo monthly - about a 2.5x difference. Professional plans start at $69/mo on annual billing. Credits don't stretch far for large-scale work, so this is best for targeted monitoring of specific pages rather than broad data collection.
Use this if: You need ongoing change detection on a handful of key pages - competitor pricing, job boards, inventory.
Skip this if: You need to extract thousands of records in a single run.
Bright Data - Best Raw Proxy Network
Bright Data is the heavy artillery of the proxy world. Residential proxy plans start at $499/mo - that's 10x+ most tools on this list. You get access to a massive global proxy network with granular geotargeting and rotation controls.

This only makes sense if you're scraping millions of pages monthly and need IP diversity that smaller providers can't match. For a team running 10,000 pages a week, Bright Data is overkill and overpriced. For an enterprise data team running 10 million pages a month across protected targets, it's table stakes.
Oxylabs - Enterprise Scraping at Scale
Oxylabs occupies similar enterprise territory but with a more accessible entry point. Their Web Scraper API starts around $49/mo for 17,500 results, with enterprise plans scaling by volume. Third-party testing puts them at 85.82% success - solid, though below Zyte's 93%. Think of Oxylabs as Bright Data's slightly more approachable sibling: same enterprise DNA, lower barrier to entry.
Scrapy - Best Free Python Framework
Scrapy is free, open-source, and backed by a massive ecosystem. It's been the default Python scraping framework for over a decade, and the community support reflects that - you'll find a StackOverflow answer for almost any edge case you hit.
The tradeoff is real engineering investment. Scrapy can't handle JavaScript-heavy sites natively (you'll need Playwright or Selenium middleware), and it runs on Twisted rather than Asyncio, which complicates integration with modern Python async applications. Worth knowing: Crawlee, built by the Apify team, offers a more modern alternative with a unified interface for HTTP and headless browser crawling. It's primarily TypeScript/Node.js with a Python port available. Both are free, both demand developer time. Scrapy has the larger community; Crawlee has the cleaner architecture.
Crawl4AI - Open-Source LLM Scraping
If Firecrawl's approach appeals to you but you want zero vendor lock-in, Crawl4AI is the open-source alternative gaining traction fast. It's purpose-built for extracting web content in formats LLMs can consume - markdown, structured JSON, cleaned text. No API keys, no credits, no monthly bills. You run it locally or on your own infrastructure.
The tradeoff is obvious: you manage everything yourself. No managed proxies, no anti-bot bypass, no cloud scheduling. But for teams already running their own infrastructure who need LLM-ready web content, Crawl4AI eliminates a recurring cost entirely.
n8n - Best for Automation Pipelines
n8n isn't a scraping tool - it's a workflow automation platform where scraping can be one node in a larger pipeline. Starter plans run EUR20/mo for 2,500 executions. Only relevant if you need scraping as a step inside a broader automated workflow, not as a standalone capability.
Lobstr.io - Best for Google Maps Data
Lobstr.io does one thing well: Google Maps extraction. Free plan includes 10,000 credits, paid starts at $56.70/mo. The value proposition is sharp - 1,000 Google Maps listings for roughly $0.60 versus Apify's $7+. That's more than a 10x cost difference for the same data. Narrow focus, excellent unit economics for that specific use case.
Pricing Comparison
The range here is enormous - from $0 for open-source frameworks to $499+/mo for enterprise proxy infrastructure.
| Tool | Free Plan | Starting Price | Model | Best For |
|---|---|---|---|---|
| Prospeo | 75 emails/mo | ~$0.01/email | Per verified email | Business contacts |
| Firecrawl | 500 credits (once) | $16/mo | Credits per page | AI/LLM content |
| ScraperAPI | Trial credits | ~$29/mo | API calls | Simple proxy API |
| Zyte | $5 trial credit | ~$0.13/1K responses | Per success | Protected sites |
| Octoparse | 10 tasks (local) | ~$83-$119/mo | Subscription + add-ons | No-code scraping |
| Browse AI | 50 credits/mo | $19/mo (annual) | Credits per row | Change monitoring |
| Bright Data | $25 trial credit | $499/mo | Per GB / per IP | Enterprise proxy |
| Oxylabs | Trial available | ~$49/mo | Per result | Enterprise scraping |
| Scrapy | Unlimited (OSS) | $0 | Dev time | Full control |
| Crawl4AI | Unlimited (OSS) | $0 | Dev time | LLM extraction |
| n8n | Community edition | EUR20/mo | Per execution | Workflow automation |
| Lobstr.io | 10K credits | $56.70/mo | Credits | Google Maps |
The tools with the lowest sticker prices often carry the highest hidden costs. Octoparse sounds reasonable until proxy and CAPTCHA add-ons push it past $200. Apify's $29/mo Starter plan sounds cheap until compute units eat through your prepaid balance in a week. Credit-based models in general punish you for failed requests - which is why Zyte's "pay only for successes" approach stands out.
You don't need a scraper, a proxy service, a CAPTCHA solver, and an email verifier to build a lead list. Prospeo replaces that entire stack with 300M+ profiles, 98% email accuracy, and a 7-day refresh cycle - at roughly $0.01 per verified email.
Ditch four tools and four bills. Get verified contacts in one search.
Performance Benchmarks
If anti-bot bypass matters to your use case, independent testing tells a clearer story than marketing pages. The Proxyway December 2025 benchmark tested 12 providers across 15 well-protected websites, running 6,000 pages each.
| Provider | Success (2 rps) | Success (10 rps) | Avg Response | Results/Hour |
|---|---|---|---|---|
| Zyte API | 93.14% | 85.89% | 11.15s | 15,422 |
| Oxylabs | 85.82% | 79.10% | 16.76s | 10,174 |
| ScraperAPI | 68.95% | 62.20% | 13.92s | 6,600 |
| Firecrawl | 33.69% | 26.69% | 7.92s | 2,276 |
Zyte's lead is significant - nearly 25 percentage points above ScraperAPI and almost triple Firecrawl's rate. If you're scraping protected e-commerce sites or platforms with aggressive bot detection, these numbers should drive your decision more than pricing does.
Let's be honest: most teams obsess over scraping tool features when their actual bottleneck is anti-bot success rate. A tool with a beautiful UI and a 34% success rate costs you more than an ugly API with 93% success. Pick boring and reliable over slick and fragile every time.
Do You Actually Need to Scrape?
Here's the contrarian take most comparison articles won't give you: if your end goal is business contact data for outbound sales, scraping is the most expensive and fragile way to get it.
Walk through the real pipeline. You scraped 5,000 leads from Google Maps. The run cost $35 in compute units, plus $12 in proxy bandwidth, plus the Actor's per-result fee. Total: roughly $55. Now you've got names and business addresses, but no verified emails. So you run them through a verification tool - another $15-25. And after all that, 40% of the emails bounce because the scraping pulled outdated or generic addresses. Your sender reputation takes a hit, deliverability drops across your entire domain, and your SDRs are wondering why reply rates cratered. We've watched this exact scenario play out with teams who came to us after burning through two or three scraping setups.
Contrast that with pulling the same 5,000 contacts from a B2B database with pre-verified emails. You search by industry, location, job title, and buyer intent. The emails come verified at 98% accuracy. The data was refreshed within the last 7 days. Total cost: roughly $50 - and zero risk to your domain reputation.
Scraping makes sense for product data, pricing intelligence, SERP monitoring, and content extraction. For business contact data, it's a Rube Goldberg machine when a direct database exists.
Every failed scrape burns credits and time. Prospeo's 143M+ verified emails and 125M+ mobile numbers are ready to export - no parsing, no broken Actors, no surprise compute bills. Push directly to HubSpot, Smartlead, or Instantly.
Zero proxies. Zero CAPTCHAs. 75 free verified emails to prove it.
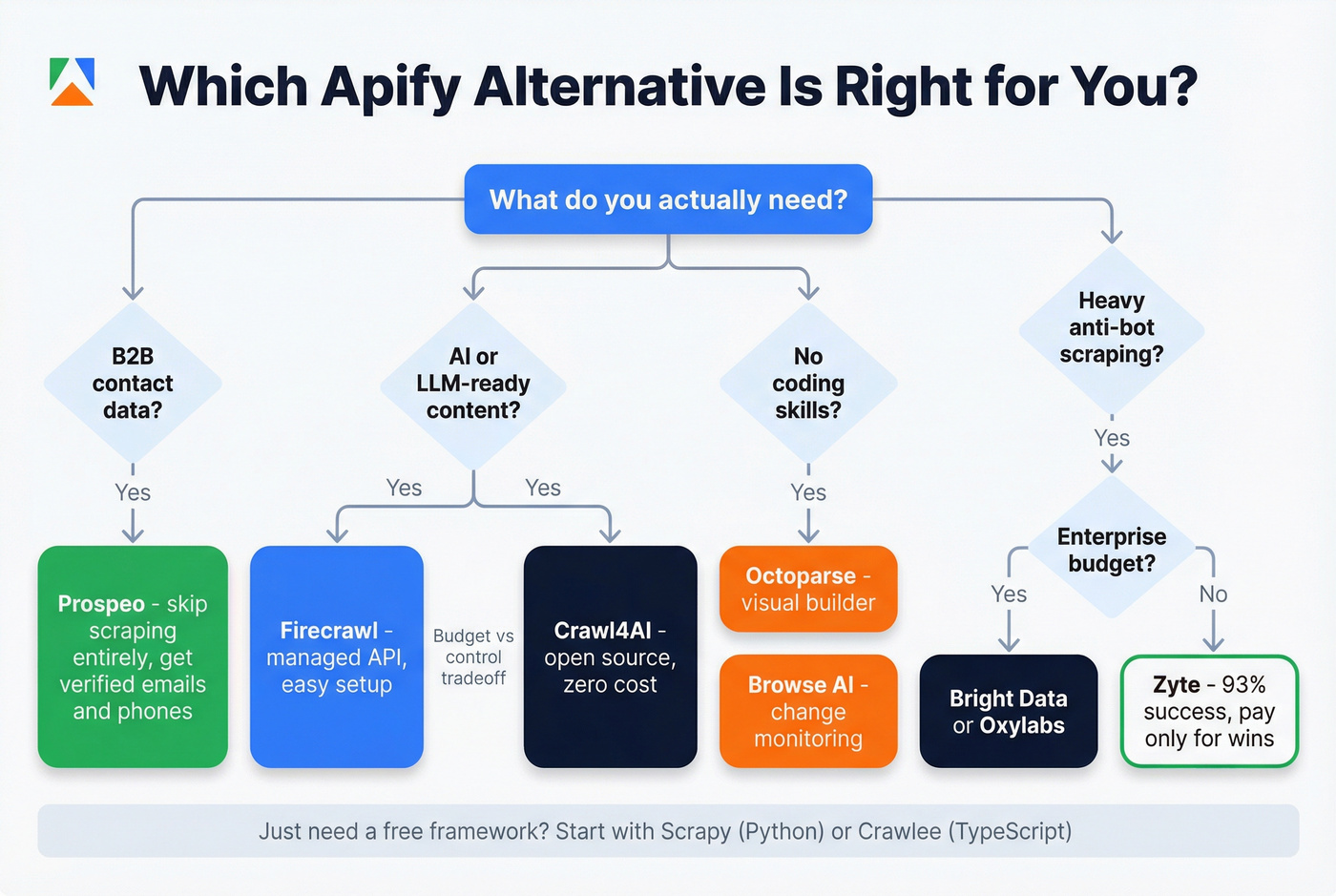
How to Choose the Right Tool
Match your actual need to the right category:
Raw HTML from protected sites - Zyte for maximum success rate, ScraperAPI for simpler pricing. If your targets include e-commerce giants or sites behind Cloudflare, success rate matters more than anything else on the feature list.
No-code visual scraper - Octoparse. Budget for add-ons beyond the base subscription, and test the free tier before committing.
AI agents consuming web content - Firecrawl for managed infrastructure, Crawl4AI for self-hosted. Evaluate MCP server compatibility if you're building agentic workflows.
Massive proxy infrastructure at scale - Bright Data or Oxylabs. Only if you're scraping millions of pages monthly.
Full control with zero cost - Scrapy for Python developers. Crawlee if you prefer TypeScript or want a more modern async architecture.
Scraping as one step in a larger automation - n8n, with a scraping node feeding downstream workflows.
Google Maps specifically - Lobstr.io. The unit economics crush Apify for this use case. (If that's your focus, see our breakdown of Google Maps scraping tools.)
The biggest mistake we see teams make is picking a tool based on Apify feature parity rather than their actual use case. A team that needs 10,000 verified emails doesn't need a scraping platform - they need a data platform. A team that needs to monitor competitor pricing doesn't need enterprise proxies - they need Browse AI. Start with the output you need and work backward.
Apify Alternatives FAQ
Is Apify free?
Apify offers a free plan with $5 in monthly platform credits - enough for light testing but not production workloads. Paid plans start at $29/mo (Starter) with $29 in platform credits, scaling to $199/mo for Scale. Compute-unit costs add up quickly once you're running Actors regularly, especially those requiring residential proxies or browser rendering.
What's the cheapest alternative?
Scrapy and Crawl4AI are completely free and open-source, though both require development skills. For no-code users, Octoparse and Browse AI offer free tiers. For business contact data, Prospeo's free plan delivers 75 verified emails monthly with no credit card required - far cheaper than building a scraping-plus-verification pipeline.
Can I scrape without coding?
Yes. Octoparse, Browse AI, and Lobstr.io all offer visual, no-code interfaces for building extraction workflows. Apify's Actor marketplace also works without code for prebuilt scrapers, though configuring inputs and debugging runs still requires some technical comfort.
Which scraping API has the highest success rate?
Zyte API leads the Proxyway benchmark at 93.14% success on well-protected sites, followed by Oxylabs at 85.82% and ScraperAPI at 68.95%. These numbers come from testing across 15 protected websites with 6,000 pages each - the most rigorous third-party benchmark available.
Do I need a scraper to get business contact data?
No. If your goal is verified emails and phone numbers for sales outreach, a B2B data platform is faster, cheaper, and more reliable than building a scraping-plus-verification pipeline. Scraping makes sense for product data, pricing intelligence, and content extraction - not for contact data that's already available in structured databases.


