9 Best Firecrawl Alternatives for 2026: Benchmarks, Pricing, and Honest Picks
You just ran your first 10,000-page crawl through Firecrawl and watched a third of your credits vanish into retries and dead ends. The dashboard says "Job not found," your user-agent headers aren't reaching Playwright, and the credit math doesn't add up. A 33.69% success rate on protected sites - per independent testing - means you're burning nearly three credits for every page that actually comes back clean. Here are the tools that fix that.
Why People Switch from Firecrawl
Firecrawl's pitch is compelling: one API for scraping, crawling, mapping, and LLM-ready output. The reality at scale is rougher.

In an independent benchmark run by Proxyway in late 2025 (summarized by Zyte), Firecrawl scored a 33.69% success rate at 2 req/s across 12 providers, 15 protected websites, and 6,000 pages each. At 10 req/s, it dropped to 26.69%. The top performer hit 93.14%. That's nearly a 3x gap.
The self-hosted version has its own headaches. Firecrawl's open-source release uses an AGPL license (not Apache 2.0), and the self-hosted setup doesn't include the same managed cloud infrastructure you get in the hosted product. Developers on GitHub have flagged persistent issues: "Job not found" errors when querying crawl status, scrape headers.user-agent values not being passed to Playwright, and missing mobile proxy support.
Then there's credit unpredictability. Firecrawl bills 1 credit per successful page, which sounds clean until you factor in retries, rendering overhead, and the gap between "pages attempted" and "pages successfully returned." At $83/mo for 100K credits on the annual Standard plan, that math matters - and competition is fierce enough that you've got real options now.
Our Picks (TL;DR)
| Use Case | Pick | Why |
|---|---|---|
| Best open-source / self-hosted | Crawl4AI | Apache 2.0, $0 software |
| Best for verifying scraped contacts | Prospeo | 98% email accuracy, protects sender rep |
| Best for protected sites | Scrapfly | Anti-bot specialist, 98% success rate |
| Best zero-setup / free | Jina AI Reader | Prefix any URL, get markdown |
| Best platform / marketplace | Apify | 4,000+ pre-built Actors |
| Best benchmark performance | Zyte | 93.14% in independent testing |

You're comparing crawlers to get data off pages - but unverified emails will wreck your domain faster than any anti-bot wall. Prospeo's 5-step verification delivers 98% email accuracy on 143M+ contacts, refreshed every 7 days. Plug it in after any Firecrawl alternative and stop burning sender reputation.
Scrape with whatever you want. Verify with Prospeo before you send.
The Best Firecrawl Alternatives for 2026
Crawl4AI - Best Open-Source Crawler
Use this if you want full control over your crawling infrastructure, need Apache 2.0 licensing, and have the engineering capacity to manage Docker deployments.
Crawl4AI (latest stable: v0.8.0) runs on Docker 20.10+ with at least 4GB RAM, exposes a /playground interface on port 11235, and supports Playwright with Virtual Scroll for JavaScript-heavy pages. Adaptive crawling auto-learns selectors, which cut crawl times by roughly 40% on structured sites in third-party testing. LLM extraction works via LiteLLM - plug in OpenAI, Anthropic, Gemini, Groq, or local Ollama models. The software is free. Your real costs are compute and proxies, typically $50-300/mo depending on volume and target site difficulty. The consensus on r/webscraping is that Crawl4AI punches well above its weight for teams willing to handle their own infrastructure, though the "bring your own everything" model isn't for everyone.
Skip this if you don't want to manage infrastructure or need turnkey anti-bot evasion. Crawl4AI gives you the engine but not the armor.
Prospeo - Best for Verifying Scraped Contacts
Here's the thing most scraping guides skip entirely: getting the data off the page is only half the job. If you're scraping contact info for outbound, unverified emails will torch your domain reputation faster than any anti-bot system will block your crawler.
Prospeo runs a 5-step verification process with catch-all handling, spam-trap removal, and honeypot filtering - all on proprietary infrastructure that doesn't rely on third-party email providers. The numbers: 98% email accuracy, 143M+ verified emails, and a 7-day data refresh cycle where the industry average sits at six weeks. One outbound agency (Meritt) went from a 35% bounce rate to under 4% after adding Prospeo's verification to their pipeline, tripling their connect rate to 20-25%.
For teams running scrape-to-outbound workflows, Prospeo slots in after your crawler of choice. Scrape with Crawl4AI or Scrapfly, verify with Prospeo, push to your sequencer. The free tier covers 75 emails/month so you can test the pipeline before committing. If you're building a broader B2B sales stack, verification is the piece that keeps deliverability from collapsing.
Scrapfly - Best for Protected Sites
Pros:
- 98% success rate on protected sites
- Dedicated anti-bot infrastructure with residential proxy rotation built in
- MCP server support for agent-based scraping workflows
- Discovery plan at $30/mo for 200K API credits

Cons:
- Credit multipliers add up fast. Browser rendering costs +5 credits per request; residential proxy routing adds +25 more. With a 1-credit base request, that's 31 credits for a protected page when you use both.
- That means your 200K monthly credits cover roughly 6,451 protected pages, not 200,000.
- Concurrency capped at 5 on Discovery; you need Pro ($100/mo) for 20 concurrent requests.
Budget for the real cost per protected page, not the headline credit count.
ScrapeGraphAI - Best for LLM-Native Extraction
ScrapeGraphAI takes a different approach: instead of CSS selectors or XPath, you define extraction tasks as graph-style LLM pipelines. SmartScraper costs 10 credits per page, SearchScraper runs 30 credits for search-augmented extraction, and Markdownify handles simple conversions at just 2 credits per page. The Starter plan is $17/mo for 60K credits/year - about 6,000 SmartScraper pages or 30,000 Markdownify conversions annually. If you're building RAG pipelines and want structured JSON output without writing extraction logic, this is the tool to evaluate.
Apify - Best Platform & Marketplace
Use this if you want a pre-built scraper for a specific site rather than building from scratch. Apify's Actor marketplace has 4,000+ community-built and official Actors - Amazon, Google Maps, Instagram, you name it. The free tier includes $5/mo in usage credits at $0.30 per compute unit. Starter runs $29/mo, Scale $199/mo with CUs dropping to $0.25 each. Residential proxies cost $7-8/GB depending on plan tier.
Skip this if you need raw crawling performance on protected sites. Apify is a platform, not an anti-bot specialist. For heavy unblocking, you'll still need to layer in proxy infrastructure.
Jina AI Reader - Best Zero-Setup Option
Jina Reader is dead simple. Prefix any URL with r.jina.ai/ and get back clean markdown - no API key needed for basic usage. It supports CSS include/exclude selectors for targeting specific page sections, token budgeting to control output size, and an MCP server endpoint at mcp.jina.ai for LLM agent integration. The experimental ReaderLM-v2 mode produces higher-quality markdown at 3x the token cost. Free with rate limits; paid usage is token-metered. For prototyping or low-volume work, it's hard to beat.
Zyte - Best Benchmark Performance
Zyte posted a 93.14% success rate at 2 req/s in the same Proxyway benchmark where Firecrawl scored 33.69%. Providers weren't told the target sites in advance.
Pricing is tiered by website difficulty. PAYG HTTP runs $0.13-$1.27 per 1,000 successful responses, dropping to $0.06-$0.61/1K with a $500 commitment. Browser-rendered pages run $1.01-$16.08/1K on PAYG. There's a $5 free trial credit. The "per successful response" billing model is straightforward - you don't pay for failures, which is a meaningful difference from credit-based systems where retries eat into your balance silently.
Bright Data - Best Enterprise Infrastructure
Bright Data is the infrastructure play: 150M+ IPs across 195 countries. Nobody else matches that coverage.
- Web Scraper API: $4/CPM PAYG, dropping to $3.06/CPM on the Growth plan ($499/mo)
- Residential proxies: $8/GB PAYG, falling to $2.50/GB on Enterprise tiers
- Free trial: $25-50 in credits for new accounts
- MCP server: Available for agent-based workflow integration
The tradeoff is complexity. Bright Data takes significant setup effort, and user reviews mention being billed for unsuccessful requests. Zyte, by contrast, bills per successful response. But for enterprise-scale scraping with global IP coverage, nothing else comes close.
Spider - Best for Raw Speed
Spider claims 50,000 core API requests per second, and Roundproxies clocked it at 47 seconds for 10,000 pages versus Firecrawl's 168 seconds. That's 3.5x faster. Pricing is bandwidth-based: $1/GB plus $0.001/min compute, with add-ons averaging $0.002-$0.0035 per feature depending on mode. Outputs in markdown, HTML, or JSON. Good for bulk jobs where speed matters more than anti-bot sophistication.
Pricing Comparison
In our experience, credit-based pricing rarely matches the headline numbers. "1 credit = 1 page" hides retries, rendering multipliers, and add-on costs. Here's what you'll actually pay.

| Tool | Free Tier | Entry Paid | Est. Cost/1K Pages | Model |
|---|---|---|---|---|
| Firecrawl | 500 credits (one-time) | $16/mo (3K credits) | ~$5.33 per 1K successful pages | Credits/page |
| Crawl4AI | Unlimited | $0 (+ infra) | $0 software + infra | Self-hosted |
| Prospeo | 75 emails/mo | ~$0.01/email | ~$10 per 1K verified emails | Credits/email |
| Scrapfly | 1K credits | $30/mo (200K) | $0.15-$4.65* | Credits + multipliers |
| ScrapeGraphAI | 50 credits (one-time) | $17/mo | ~$34 (SmartScraper) | Credits/page |
| Apify | $5/mo usage | $29/mo | Varies by Actor | Compute units |
| Jina AI Reader | Yes (rate-limited) | Token-metered | Varies by tokens | Tokens |
| Zyte | $5 trial credit | PAYG from $0.13/1K (HTTP) | $0.06-$16.08 | Per success |
| Bright Data | $25-50 trial | $499/mo (Growth) | $3.06-$4.00/CPM | CPM + bandwidth |
| Spider | Not public | PAYG | Varies by bandwidth + compute | Bandwidth + compute |
*Scrapfly range reflects simple pages (~$0.15) vs protected pages with browser + residential proxy multipliers (~$4.65).
How to Choose the Right Tool
Let's be honest: most teams don't need a single all-in-one scraping tool. They need a pipeline. The smartest setups we've seen chain tools by URL type - Jina for simple pages, Scrapfly or Zyte for protected targets, and a verification layer before anything hits the outbound stack.
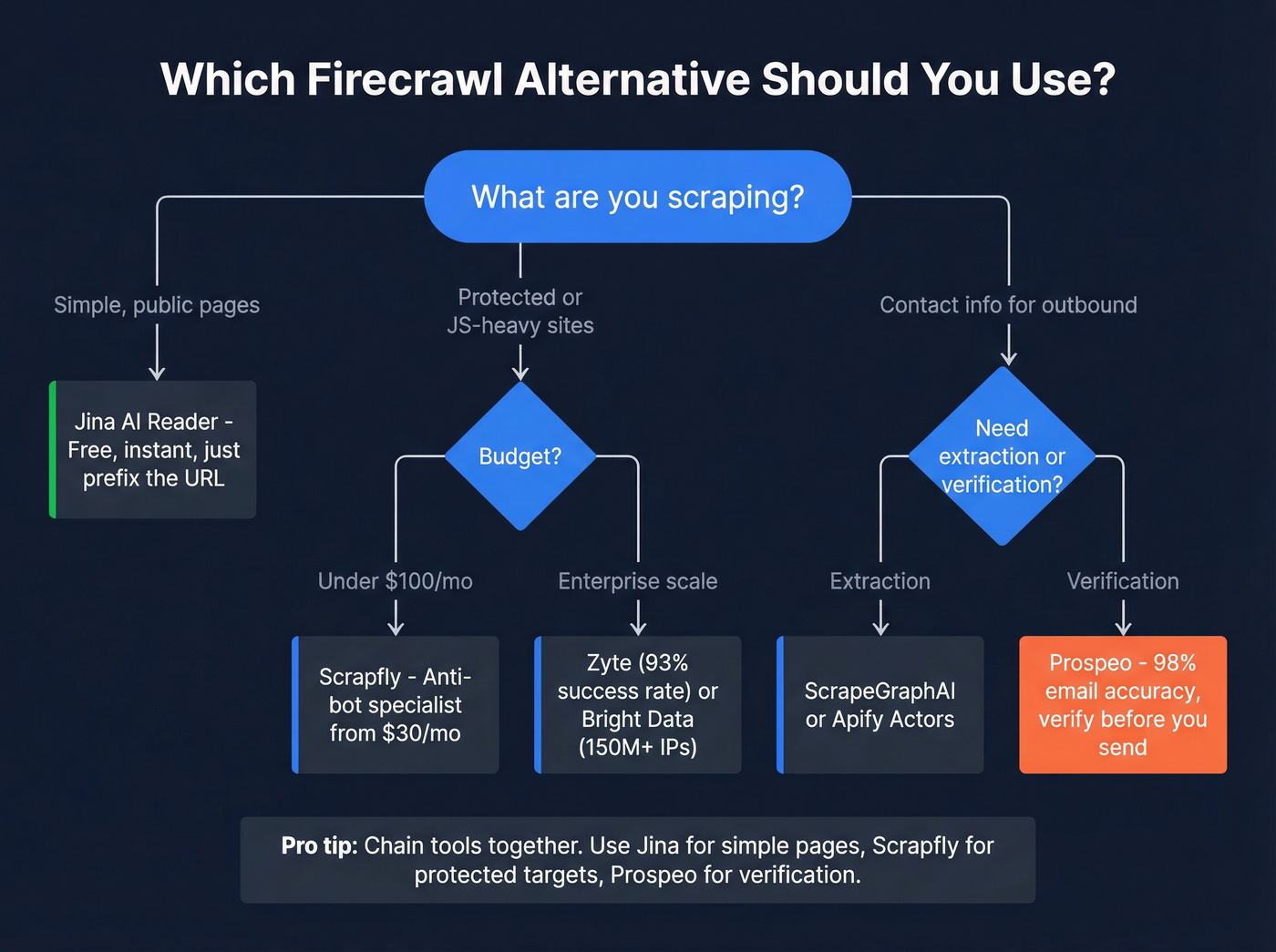
Here's the decision tree:
- Scraping protected sites? Zyte has the independent benchmarks; Scrapfly has simpler pricing at lower volumes.
- Want open-source with full control? Crawl4AI. Budget for your own proxy and compute costs.
- Just need clean markdown fast? Jina AI Reader. Free, instant, zero setup.
- Need a pre-built scraper for a specific site? Apify's marketplace has 4,000+ options.
- Running enterprise-scale operations across geographies? Bright Data's proxy infrastructure is unmatched.
- Building agent-based scraping workflows? Look for MCP server support - Jina, Scrapfly, and Bright Data all offer it.
If your end goal is outreach, treat verification as non-negotiable: it’s the difference between scaling safely and getting a blacklist alert after one bad send. For a deeper playbook, follow an email deliverability checklist and align your process with email verification for outreach.
Meritt ran scraped contacts through Prospeo and dropped their bounce rate from 35% to under 4% - tripling their connect rate overnight. At $0.01 per verified email, the cost of verification is a rounding error compared to the cost of a burned domain.
One bad list costs more than a year of verified data. Fix that now.
FAQ
Is there a free open-source alternative to Firecrawl?
Crawl4AI is the strongest option - Apache 2.0 licensed, self-hosted via Docker, with zero per-page software cost. You'll pay only for compute and proxies, typically $50-300/mo depending on volume.
Why is Firecrawl's success rate low on protected sites?
The Proxyway benchmark measured 33.69% at 2 req/s across 15 protected sites. Dedicated unblocking APIs like Zyte (93.14%) and Scrapfly (98%) use specialized anti-bot infrastructure that Firecrawl's general-purpose crawler doesn't have.
Can I self-host Firecrawl for free?
Yes, under AGPL. But self-hosting doesn't include the same managed cloud infrastructure as the hosted product, and GitHub issues show ongoing gaps including "Job not found" errors and Playwright header handling problems.
What's the cheapest web scraping API for LLM-ready data?
Jina AI Reader is free for low-volume use - just prefix a URL and get markdown. For complex crawls at scale, Crawl4AI is free software with bring-your-own infrastructure. Both output LLM-friendly formats out of the box.
