Hyper-Personalization AI: What It Really Takes (Beyond the Vendor Hype)
Your CMO wants hyper personalization AI by Q3. Your CRM's got 40% duplicate records, a third of your email list bounces, and nobody agrees on what "personalized" means beyond sticking a first name in the subject line. The gap between the pitch deck and the implementation reality is enormous - and it's where most programs die.
We've watched teams buy a shiny "personalization engine," wire up two integrations, and then wonder why results look like the same old campaigns with slightly fancier copy. The problem isn't ambition. It's the foundation.
Let's break this down like practitioners, not like vendors.
What You Need (Quick Version)
- Hyper-personalization isn't "Hi {first_name}". It's real-time, behavioral, and predictive - adapting to each person based on what they're doing now, not which segment they were dropped into last quarter.
- It needs event-driven plumbing and clean first-party data. Without both, you're building on sand.
- Enterprise tools often start around ~$35K/year. A full AWS reference stack runs about $2,117.76/month (default deployment estimate). SMB entry points exist at $75/month.
- Most programs fail because of bad data, not bad models. Fix contact data before you buy a decisioning layer.
- Start with one channel (email), prove ROI in 90 days, then expand. Doing "omnichannel" on day one is how budgets disappear.
What Is Hyper-Personalization AI?
Basic personalization is "Hi {first_name}, check out our new feature." Hyper-personalization AI knows this specific person browsed your pricing page twice this week, downloaded a competitor comparison guide, and their company just raised a Series B - then it surfaces a tailored offer at the moment they're most likely to convert.
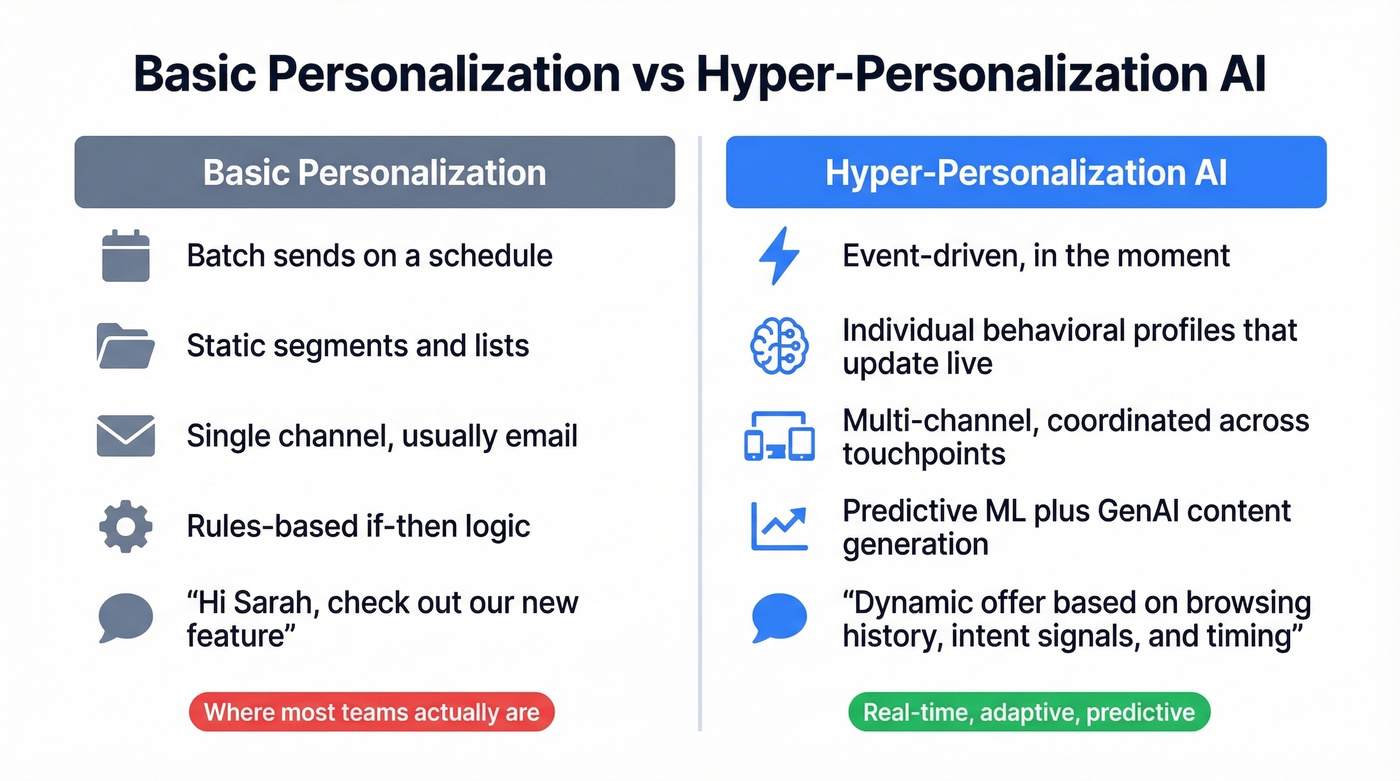
The distinction matters because most teams think they're doing hyper-personalization when they're really doing mail merge with extra steps. True hyper personalization AI uses machine learning to build a profile of each individual that updates as behavior changes. It's not "a segment of one." It's a model of one.
| Dimension | Basic Personalization | Hyper-Personalization AI |
|---|---|---|
| Data type | Demographics, segments | Real-time behavioral + contextual (device, location, time of day) |
| Timing | Batch/campaign-based | Event-driven, in-the-moment |
| Channel | Single (usually email) | Multi-channel, coordinated |
| AI role | Rules-based logic | Predictive ML + GenAI |
| Example | "Hi Sarah" in subject | Dynamic offer based on browsing + intent signals |
If your "personalization" runs on static lists and scheduled sends, you're in the left column. That's fine - it's where most teams are. Just don't call it hyper-personalization, because the build, the cost, and the failure modes are completely different.
And yes, this goes beyond email. Recommendation systems reshape storefronts per visitor. Support platforms route tickets based on sentiment and predicted complexity. Product onboarding changes based on in-app behavior. Even pricing can shift based on demand signals and customer lifetime value. Same idea, different surface area.
How the Architecture Works
The 5-Layer Stack
Any serious hyper-personalization engine ends up with five layers. Skip one and you'll feel it later, usually in the form of "Why are we sending the right message to the wrong person?"
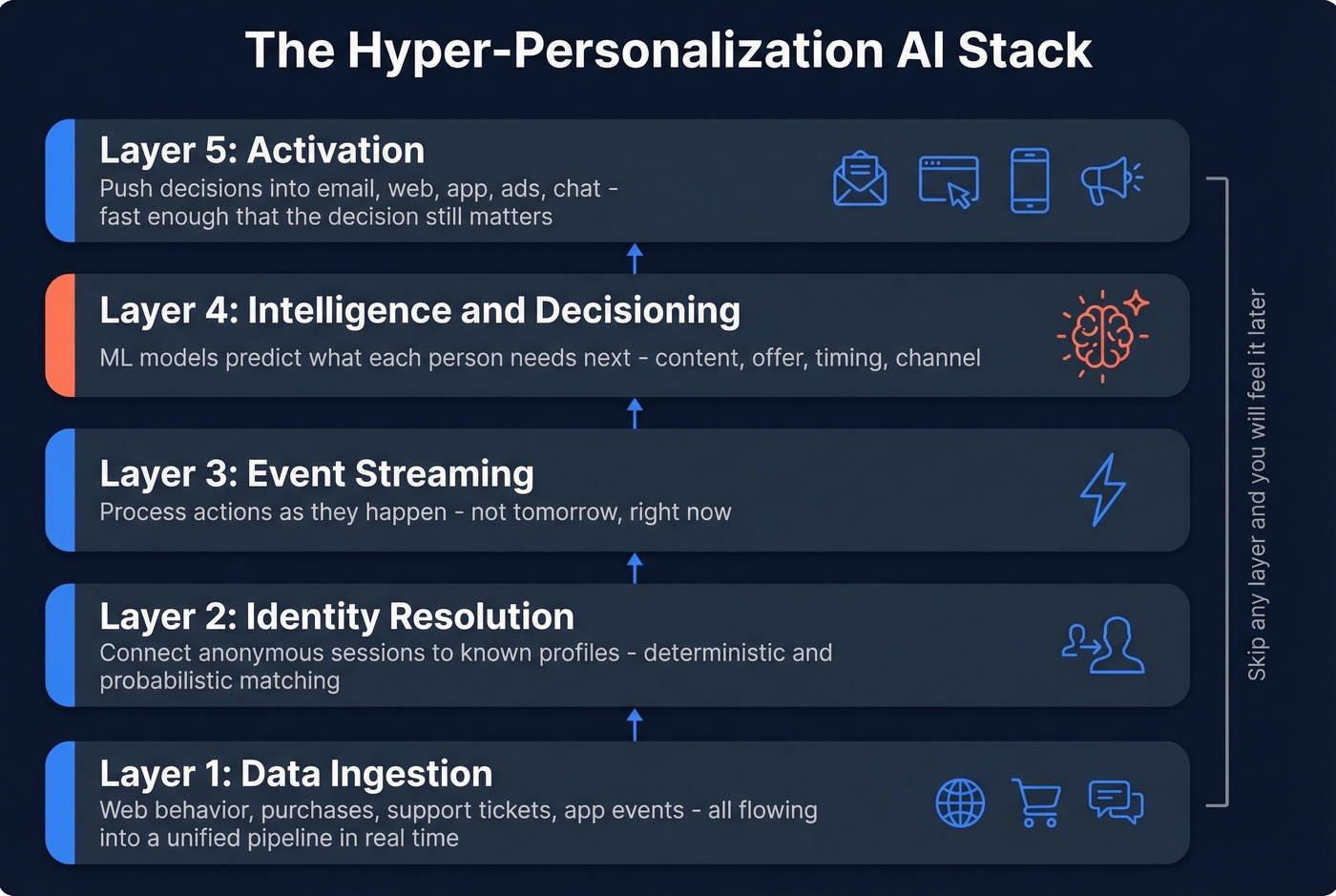
Layer 1: Data ingestion
Every touchpoint - web behavior, purchases, support tickets, app events - flows into a unified pipeline. This can't be a nightly batch job if you want real-time outcomes.
Layer 2: Identity resolution
You connect anonymous sessions to known profiles. Deterministic matching uses exact identifiers like email or logins. Probabilistic matching uses statistical inference when exact IDs aren't available. Most teams underinvest here and end up with three "different" customers who are actually the same person.
Layer 3: Event streaming
You process actions as they happen. This is the difference between "we'll email them tomorrow" and "we'll adjust the homepage right now."
Layer 4: Intelligence and decisioning
Models predict what each person needs next: content, offer, timing, channel. This is where the real value sits, and it's the part vendors love to demo while quietly glossing over the data work.
Layer 5: Activation
You push decisions into channels - email, web, app, ads, chat - fast enough that the decision still matters. Activation is often the most neglected layer because it's "just integrations" until it's 14 integrations and none of them behave the same way.
A lot of leaders talk about moving from reactive to predictive personalization. This stack is how you actually do it, and it's why "just add AI" doesn't work.
Where GenAI Fits (and Where It Doesn't)
GenAI didn't invent hyper-personalization. It removed the content bottleneck.
Traditional ML handles prediction and decisioning: what to show, when to show it, and to whom. Before GenAI, you still needed humans to write endless variants of emails, landing pages, and chatbot responses. That doesn't scale past a handful of segments.
GenAI generates the variants. It's the production layer, not the brain. Teams that confuse the two end up with beautifully written messages sent to the wrong people at the wrong time, which is honestly worse than generic copy because it burns trust faster.
The "agentic AI" trend pushes this further: systems that close the loop from signal to decision to content to activation with less human hand-holding. It's early, and it's messy in the real world, but that's the direction.
Real Results: Campaign Benchmarks
Vendor pages love phrases like "improved engagement." Numbers are better.
| Campaign | Result |
|---|---|
| Coca-Cola "Share a Coke" | +2% sales, +870% social engagement |
| JP Morgan + Persado AI copy | +450% CTR on ads |
| Cosabella holiday campaign | +40-60% sales (no discounts) |
| Heinz DALL-E campaign | 800M+ earned impressions, 2500% ROI on media spend |
| Nutella unique labels | 7M unique jars, sold out |
| Phrasee + Novo Nordisk | +14% CTR, +24% open rates |
Two quick notes from our side.
First, Persado and Phrasee are closer to AI copy optimization than full-stack personalization. That's not a knock - it's a useful reminder that you can get meaningful lift without rebuilding your entire data architecture.
Second, "CTR up 450%" is a headline, not a business case. If you optimize for clicks, you'll get clicks. If you optimize for pipeline, retention, or LTV, you'll make different decisions about what "personalized" should even mean.
For market context, industry estimates put the personalization engines market at $1.2B in 2026, projected to reach $31.6B by 2030 at a 20.9% CAGR. That's real budget movement, not just hype.
You just read it: most hyper-personalization programs fail because of bad data, not bad models. Prospeo's 5-step verification delivers 98% email accuracy, 7-day data refresh, and 83% enrichment match rates - so your decisioning layer actually has something clean to work with.
Fix Layer 1 before you buy Layer 4.
Why AI-Powered Personalization Fails
The 6 Failure Modes
The failure patterns are boring because they're the same ones, over and over.

Siloed or low-quality data kills more projects than anything else. If marketing, sales, and product data live in separate systems, your models are working with fragments and your "personalization" becomes inconsistent across channels.
Misaligned metrics comes next. Teams celebrate a huge CTR lift and ignore that none of those clicks convert because they optimized for the easiest metric to move, not the one that pays the bills.
Generic off-the-shelf models work for demos, not for your brand voice and customer nuance. No real-time feedback loop means models go stale fast. Poor UX integration buries good recommendations in places nobody sees. And lack of cross-functional alignment - marketing wants better emails, engineering wants clean architecture, data science wants model accuracy, legal wants risk controls - kills the project in committee.
Here's the thing: none of these are "AI problems." They're operating problems.
The Creepy Line (and How Teams Cross It)
There's a spectrum between relevant and creepy, and most teams don't know where they are on it until customers tell them.
Retargeting the same product for weeks after someone already bought it is the classic. Emails referencing hyper-specific actions users don't remember taking is another. Ads that feel less like marketing and more like surveillance are the fastest way to train people to ignore you.
Reddit practitioners are even harsher about AI-personalized outreach. The consensus in threads on r/b2bmarketing and r/DigitalMarketing is pretty consistent: "personalized" first lines that read like a scraped profile summary don't feel thoughtful, they feel automated - even when the facts are accurate. Real talk: people aren't mad that you know something about them. They're mad that you used that knowledge to send a message that still sounds like a template.
The fix isn't "less personalization." It's smarter personalization:
- Use behavior clusters ("exploring" vs "comparing" vs "ready to buy") instead of quoting one-off micro-actions.
- Add suppression and pacing rules so you don't stalk people across channels.
- Give users control over preferences, and honor it.
- Measure long-term outcomes (retention, repeat purchase, churn) alongside short-term engagement.
The Data Quality Problem
Here's the uncomfortable truth vendors don't lead with: hyper personalization AI without clean data is just expensive guessing.

Hot take: if your average deal size is under $10K, you probably don't need a $50K personalization engine. But you absolutely need clean data, because the fanciest decisioning layer on the market can't help you if your CRM is full of duplicates and your emails are bouncing to dead addresses.
A scenario we see a lot: a team rolls out "AI-powered personalization" for outbound, starts sending more variants, and deliverability tanks within two weeks because the list quality wasn't fixed first. Now the model gets blamed, the ESP gets blamed, and the real culprit - bad contact data - stays untouched because it's not as exciting as "AI."
If you're doing email as your first channel (and you should), verified contact data is non-negotiable. Prospeo is a practical way to handle that foundation: 300M+ professional profiles, 143M+ verified emails, 125M+ verified mobile numbers, and 98% email accuracy, with records refreshed every 7 days. That freshness matters when you're trying to personalize based on current reality, not a job title from last quarter.
Prospeo's verification also filters spam traps and honeypots, which is exactly the kind of unsexy work that keeps your domains alive while you experiment with more aggressive personalization. If you're evaluating providers, start with a quick scan of the best B2B databases and the best data enrichment tools to see what "clean" can realistically look like.
Real-time personalization needs real-time signals. Prospeo tracks buyer intent across 15,000 topics, detects job changes, and enriches contacts with 50+ data points - the behavioral and contextual foundation your AI stack is starving for.
Feed your personalization engine data it can actually trust.
Tools and What They Cost
Most personalization vendors don't publish pricing. That tells you a lot about how the buying process is going to feel.
Here's a grounded view of common options and typical starting points.
| Tool | Best For | Starting Price | Free Trial? |
|---|---|---|---|
| Prospeo | B2B data quality layer (verification + enrichment) | ~$0.01/email; free tier | Free (75 emails/mo) |
| CleverTap | SMB entry point | $75/mo | 30-day |
| Personyze | Budget-friendly starter | $250/mo | Free plan (5K views) |
| AWS reference stack | Build-your-own | ~$2,117.76/mo | N/A |
| Bloomreach | Search + personalization | ~$19K/yr per module + $4K+ setup | Demo |
| Insider | Mid-market growth | ~$30-100K/yr | Demo |
| Dynamic Yield | E-commerce real-time recs | ~$35K/yr | 14-day |
| Optimizely | Experimentation teams | ~$36K/yr (DXP: $120-200K+) | Demo |
| Braze | Cross-channel engagement | Not public (custom) | 14-day |
| Adobe Target | Enterprise omnichannel | ~$50-150K+/yr | Demo |
A few opinions, based on what tends to work in practice:
For e-commerce teams that need real-time recommendations, Dynamic Yield is a common default. It's not cheap, but it's purpose-built for the job and tends to show value quickly if you've already got solid event tracking.
For teams that live and die by experimentation, Optimizely's experimentation layer is excellent. Skip the full DXP unless you know you'll use it; otherwise you're paying for a lot of surface area you won't touch for months.
For SMBs testing the waters, CleverTap is a low-risk starting point. Personyze is also fine for early experiments. If your data is messy, spend the first chunk of your budget on cleanup and verification instead of buying a bigger platform.
For engineering-led orgs, the AWS reference stack can be a good deal because you can tailor it to your business and avoid long-term platform lock-in. Skip this if you don't have someone who can own it end-to-end, because "we'll just build it" turns into "nobody maintains it" surprisingly fast.
If you're starting with email, it helps to have a clear view of AI email personalization and the deliverability basics behind email blast templates that don't get you flagged.
Privacy and Compliance in 2026
Privacy compliance isn't a checkbox. It's a workload.
GDPR fines have exceeded €1.7B since inception. In the US, California's CPPA approved new rules in July 2026 covering automated decision-making technology, requiring risk assessments and human oversight when using AI for significant decisions or processing sensitive data. Tennessee, Minnesota, and Virginia also updated privacy laws with opt-out requirements for profiling and targeted advertising.
And the post-cookie shift makes everything more first-party. That's good for privacy in theory - customers knowingly share data - but it also means your personalization is only as good as your consent and preference infrastructure.
If you're running AI-powered personalization in 2026 without a dedicated compliance function (or at least a named owner who can say "no"), you're taking on more risk than most boards realize.
Useful references:
- GDPR enforcement tracker and fines: https://www.enforcementtracker.com/
- European Data Protection Board (guidance and decisions): https://edpb.europa.eu/
- California Privacy Protection Agency (rulemaking and regs): https://cppa.ca.gov/
If you need a practical framework for this, map your requirements against B2B compliance and a GDPR compliant database checklist before you scale targeting.
Implementation Roadmap
You don't need a $200K engine to start. You need clean data, one channel to test on, and 90 days of patience.
Phase 1 (Weeks 1-4): Fix your foundation Audit data quality across CRM, email lists, and customer records. Fix bounce rates - anything above 5% means your data's actively hurting you. Unify customer records, resolve duplicates, and get consent and preference management into a state you can defend. If your data's a mess, budget 4-8 weeks and don't pretend it'll be done in a sprint.
Phase 2 (Months 2-3): Prove it on one channel Pick email because it's measurable and cheap to iterate. Use an SMB tool, a mid-market platform, or your own stack. Run A/B tests comparing personalized vs generic content, but measure conversion and revenue, not just opens and clicks. If you can't tie it to money here, adding channels won't magically fix it.
Phase 3 (Months 4-6): Expand with evidence Add a second channel (web, app, or ads). Layer in real-time decisioning as your data pipeline matures. Start tracking retention and LTV alongside campaign metrics. At this stage, you'll have real numbers to justify enterprise tooling, and you'll know what features you actually need instead of buying a platform because the demo looked slick.
Skip this if you're tempted to start with "omnichannel personalization" as your first milestone. It's the fastest way to create a sprawling system nobody trusts, and once trust is gone, adoption dies.
The teams that win follow the same pattern: data first, one channel, prove ROI, then scale. The teams that lose try to boil the ocean on day one. If you want a tighter ops lens on the stack, align this plan with your RevOps tech stack so data, routing, and activation don't drift.
FAQ
What's the difference between personalization and hyper-personalization?
Basic personalization uses static segments and demographic data like name and location. Hyper personalization AI uses real-time behavioral data, ML models, and predictive analytics to adapt in the moment based on live actions, not pre-built cohorts. The key difference is event-driven decisioning versus batch-scheduled campaigns.
How much does implementation cost?
Enterprise personalization engines often start at $35-50K/year. A full AWS reference stack runs about $2,117.76/month. SMB tools like CleverTap start at $75/month. Budget at least 30% of your total spend for data cleanup and integration because that's the hidden cost that sinks most projects.
Can small businesses use AI-powered personalization?
Yes, but start small and stay honest about your data. CleverTap ($75/month) and Personyze (free starter plan with 5,000 views) make entry affordable. Verified contact data matters more than fancy decisioning early on, because deliverability problems will erase any gains from better copy.
What data do you need to get started?
At minimum: behavioral data (clicks, purchases, browsing patterns), transactional history, and verified contact information. First-party data from authenticated accounts and loyalty programs is increasingly important as third-party cookies fade out. Quality beats quantity every time.
Is hyper-personalization creepy?
It can be. Retargeting the same product for weeks or referencing actions users don't remember crosses the line from relevant to surveillance. Use behavior clusters, give users control over preferences, add suppression and pacing rules, and measure trust signals alongside engagement.