RevOps Lead Scoring: Why Most Models Fail and How to Build One That Doesn't
You've spent three weeks building a 40-criteria scoring model. Marketing is proud of it. Sales ignores it. The VP of Sales pulls you into a room and says the last batch of MQLs had a 4% connect rate - half the emails bounced, and the ones that didn't went to people who'd never heard of your product.
RevOps lead scoring isn't broken because the rules are wrong. It's broken because the data underneath is wrong. This is a data quality problem disguised as a process problem, and until you fix the foundation, no amount of point-value tweaking will save your model.
What You Need (Quick Version)
Before you build anything, run through this checklist:
- Audit your CRM data completeness. If key firmographic fields are less than 50% populated, stop. Fix data first.
- Start with 5 criteria, not 50. Company size, job title, pricing page visit, demo request, and email domain gets you 80% of the way there.
- Set an MQL threshold between 60 and 100 points. Validate it against closed-won data every quarter.
- Fix enrichment coverage before scoring. If your enrichment only covers 25% of leads, 75% can never reach MQL regardless of their behavior.
- Build in negative scoring and decay from day one so every lead doesn't eventually drift into MQL territory through accumulated noise.
What Lead Scoring Means in RevOps
Lead scoring assigns numerical values to leads based on two dimensions: fit and intent. Fit scoring uses firmographic and demographic data - company size, industry, job title, geography. Intent scoring tracks behavioral signals like pricing page visits, demo requests, content downloads, and email engagement. The combined score tells sales which leads deserve attention right now.

Don't confuse score with grade. A score is a number (0-100) reflecting likelihood to buy. A grade (A-F) often reflects fit alone. The best models use both, but starting with a single composite score is fine.
The predictive lead scoring market grew from $1.4B in 2020 to $5.6B in 2025, a 38% CAGR. Yet only 44% of teams actually use lead scoring in practice. Teams are buying scoring tech faster than they're operationalizing it in a way sales will trust.
Why Most Scoring Models Break
Three pitfalls kill scoring models. We've watched all three play out - sometimes in the same quarter at the same company.
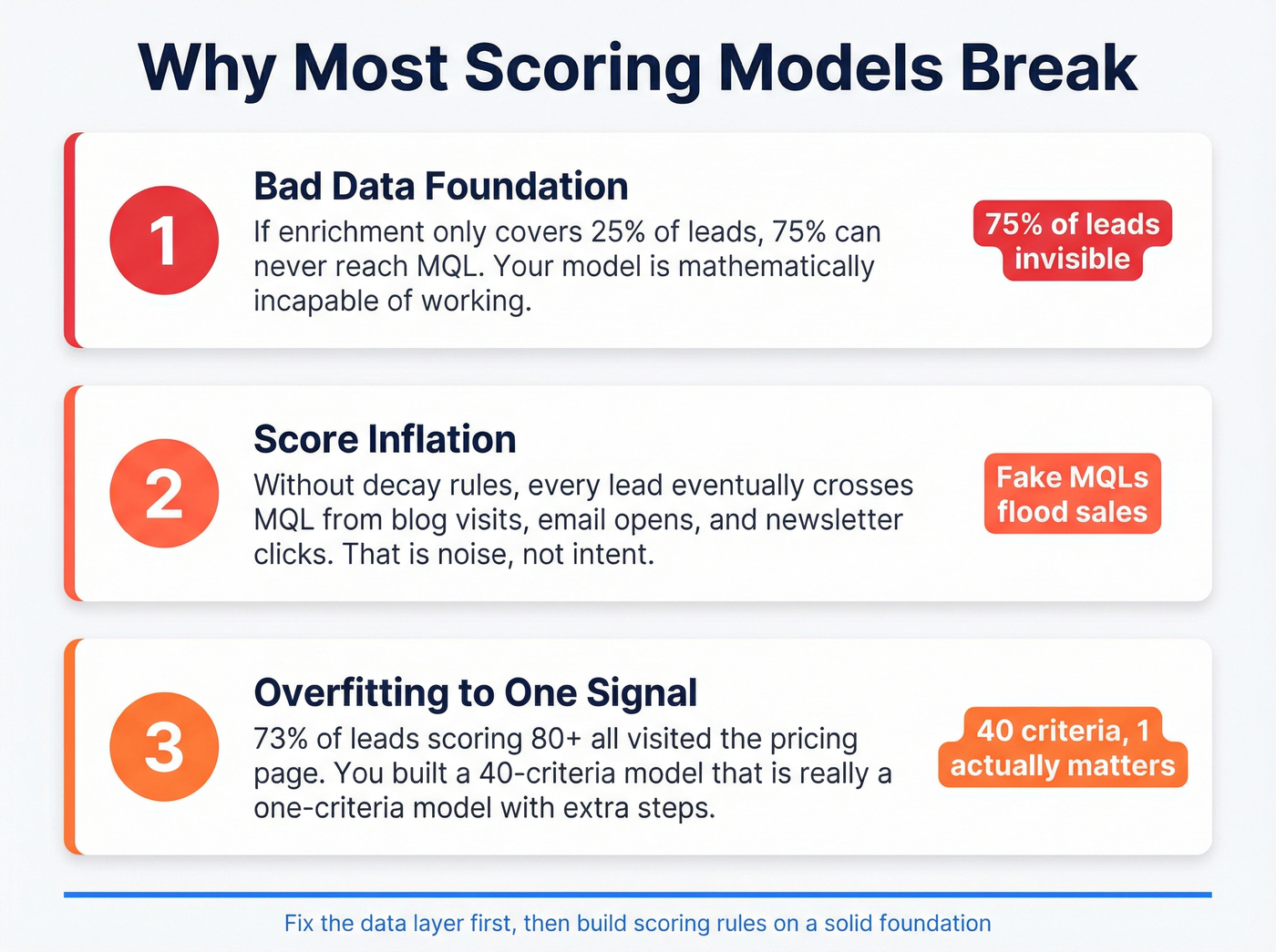
Pitfall 2: Score inflation. Without decay rules, every lead eventually accumulates enough low-value actions - blog visits, email opens, social clicks - to cross the MQL threshold. Your sales team gets a flood of "qualified" leads who opened three newsletters and visited the careers page. That's not intent. That's noise.
Pitfall 3: Overfitting to one signal. Here's a pattern that shows up constantly: 73% of leads scoring 80+ all visited the pricing page. Everything else in the model is decoration. You've built a 40-criteria model that's really a one-criteria model with extra steps. If one signal dominates your high-score band, either re-weight your criteria or accept that you have a single-trigger model and simplify accordingly.
Build Your Scoring Model Step by Step
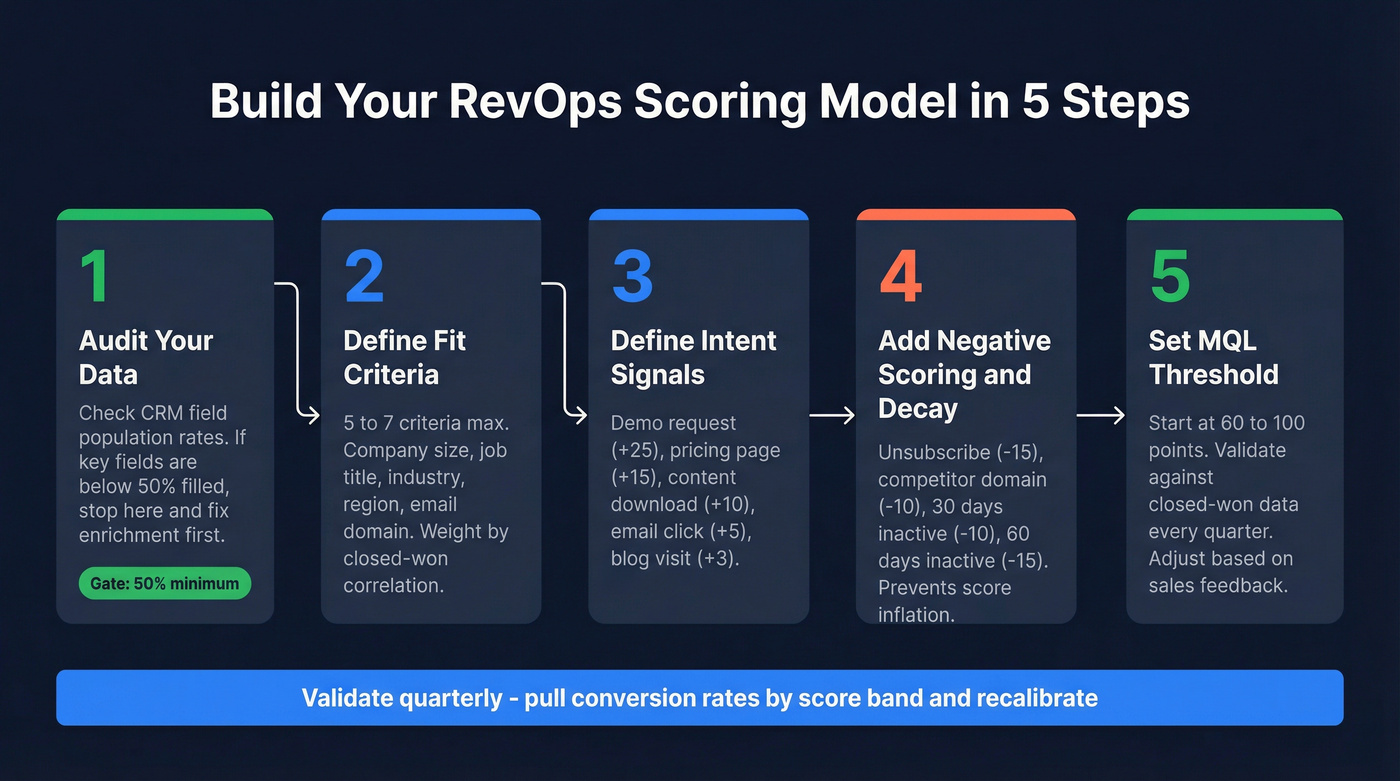
Audit Your Data First
This is the step everyone skips and the reason most models fail. Run a field population rate audit on your CRM. Pull every lead from the last 12 months and check completion rates for company size, industry, job title, email, and phone number.
RevOps practitioners consistently flag this problem: if enrichment only covers 25% of leads, 75% can never reach MQL. Your model isn't underperforming - it's mathematically incapable of working. If key firmographic fields are below 50% populated, stop building scoring rules and fix your CRM hygiene data layer first.
Prospeo's CRM enrichment fills those gaps - 50+ data points per contact at an 83% match rate with 98% email accuracy. It plugs natively into HubSpot and Salesforce, so there's no CSV export dance. The 7-day refresh cycle keeps job titles, company sizes, and seniority levels current between quarterly reviews, which means your scoring rules don't silently degrade as records go stale.
Define Fit Criteria
Keep this simple. Five to seven criteria, weighted by their correlation with closed-won deals. Here's a starting matrix based on the CMO Alliance framework:
| Fit Criterion | Condition | Points |
|---|---|---|
| Job Title | VP / C-suite | +15 |
| Job Title | Director | +10 |
| Job Title | Manager | +5 |
| Company Size | 50-500 employees (ICP) | +15 |
| Industry | Target industry | +10 |
| Region | Target geography | +5 |
| Email Domain | Free email (Gmail, etc.) | -5 |
The point values aren't sacred - what matters is that they reflect your actual win patterns. Pull your last 50 closed-won deals, see which criteria show up most, and weight accordingly. In our experience, the 5-criteria model outperforms the 40-criteria model every time because it's simple enough that the whole team actually understands and trusts it.
Define Intent Criteria
Behavioral signals tell you when a lead is actively evaluating. Weight high-intent actions heavily and low-intent actions lightly:
| Intent Signal | Points |
|---|---|
| Demo request | +25 |
| Pricing page visit | +15 |
| High-intent content download | +10 |
| Email open + click | +5 |
| Blog visit | +3 |
| Webinar attendance | +10 |
The demo request at +25 should be your strongest signal. If it isn't driving the most conversions in your model, something's wrong with your routing, not your scoring.
Negative Scoring and Decay
This is where most teams get lazy. It's exactly where score inflation creeps in.
| Negative Signal | Points |
|---|---|
| Unsubscribe | -15 |
| Competitor domain | -10 |
| Free email domain | -5 |
| 30 days inactive | -10 |
| 60 days inactive | -15 |
The Default team's Marketo guide recommends -10 after 30 days with no engagement, and that's a solid starting point. Without decay, a lead who visited your pricing page eight months ago and never came back still looks "hot." That's how you erode sales trust in the model permanently.
Sales and Marketing Alignment
One of the most common questions RevOps teams face is whether to score individual leads or entire accounts. This isn't an either/or decision - it's a sequencing question.
| Factor | Lead Scoring | Account Scoring |
|---|---|---|
| Best for | ACV under $25K | ACV over $50K |
| Decision-makers | 1-3 contacts | 5+ stakeholders |
| Motion | PLG, high volume | ABM, enterprise |
| Complexity | Lower | Higher |
Average B2B deals involve 6-10 stakeholders. When you're selling into buying committees that large, scoring individual leads misses the forest for the trees. A junior researcher scores low individually while the account they belong to is deep in an evaluation cycle.
Organizations using lead scoring report 77% higher lead generation ROI, while ABM with proper account prioritization reports 21-50% higher overall ROI. Let's be honest: if your average deal is under $25K with one or two decision-makers, lead scoring is the right starting point. Build account scoring when your ACV and buying committee complexity demand it.
If 75% of your leads can't reach MQL because firmographic fields are empty, your scoring model is dead on arrival. Prospeo's CRM enrichment fills those gaps - 50+ data points per contact, 83% match rate, 98% email accuracy, refreshed every 7 days so scores never silently decay.
Stop tuning a scoring model built on broken data. Fix the foundation.
Manual Rules vs. Predictive AI
| Dimension | Manual/Rules-Based | Predictive AI |
|---|---|---|
| Data inputs | Fields you select | All available signals |
| Scoring logic | If/then rules | ML-weighted patterns |
| Scalability | Breaks at volume | Scales with data |
| Accuracy | Prone to bias | Improves over time |
| Maintenance | Constant tuning | Self-recalibrating |
| Setup time | Days | Weeks to months |
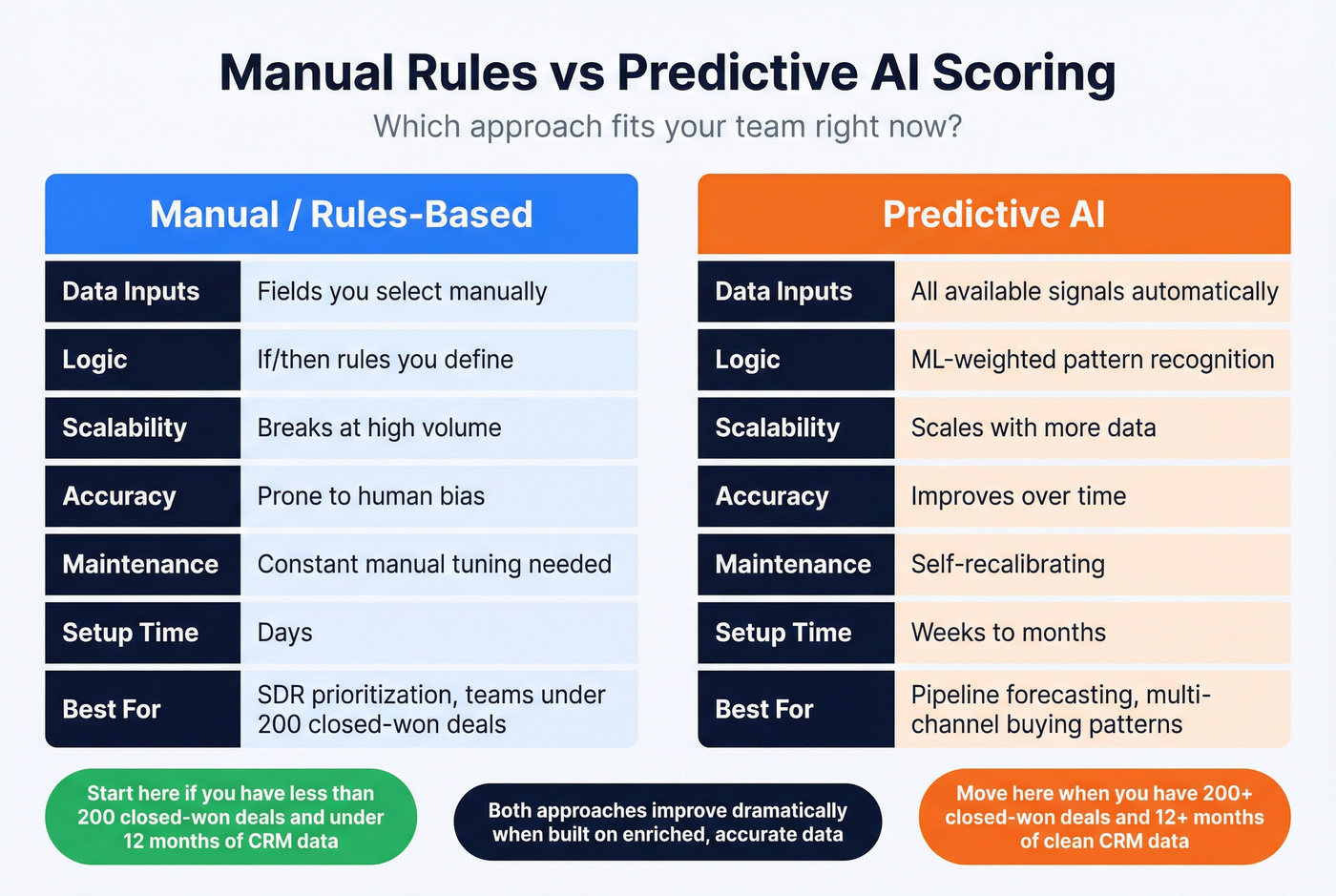
Static scoring works for SDR prioritization. It breaks for pipeline forecasting. Static models are reactive, gameable, and blind to multi-channel buying patterns. Predictive models produce probabilities, not points, and they incorporate funnel velocity and buying group dynamics that no human-built rule set can capture.
But predictive scoring requires at least 12 months of CRM data and 200+ closed-won opportunities to train a model worth trusting. If you don't have that volume, manual rules are the right starting point - just don't pretend they're predictive. Either approach improves when you layer in intent data, which is why platforms tracking buyer-intent topics are increasingly standard in modern scoring stacks. The RevEngine newsletter has a solid breakdown of how to validate model assumptions against actual revenue data.
Platform Implementation
HubSpot
HubSpot's native scoring lives in Marketing Hub Professional and starts at $800/month. You get basic score properties and can build rules using contact properties and behavioral triggers. For predictive scoring, you'll need Enterprise tier, where Breeze Intelligence is available. Map your scoring thresholds to lifecycle stages - MQL at 60 points triggers a stage change and routes to the SDR queue.
Salesforce
Einstein Lead Scoring is available for Sales Cloud Enterprise and above. Einstein analyzes your historical conversion data and assigns a probability score automatically. Pair it with Einstein Activity Capture to pull email and calendar signals into the model, and use Flows to route high-scoring leads. The catch: predictive scoring works best when you have enough history and outcomes - 12+ months of CRM data and a few hundred closed-won opportunities makes a real difference.
Marketo
Marketo uses a dual-field approach - Behavior Score and Demographic Score - that you combine for routing decisions. Smart Campaigns with "Change Score" steps run continuously for real-time updates. Marketo gives you extremely granular control over scoring logic thanks to its dual-field architecture. It's also one of the most complex platforms to set up correctly, so skip it if your team doesn't have a dedicated Marketo admin or the budget to hire one.
Scoring Tools and What They Cost
The market splits into three tiers. Match your budget and complexity to the right one.
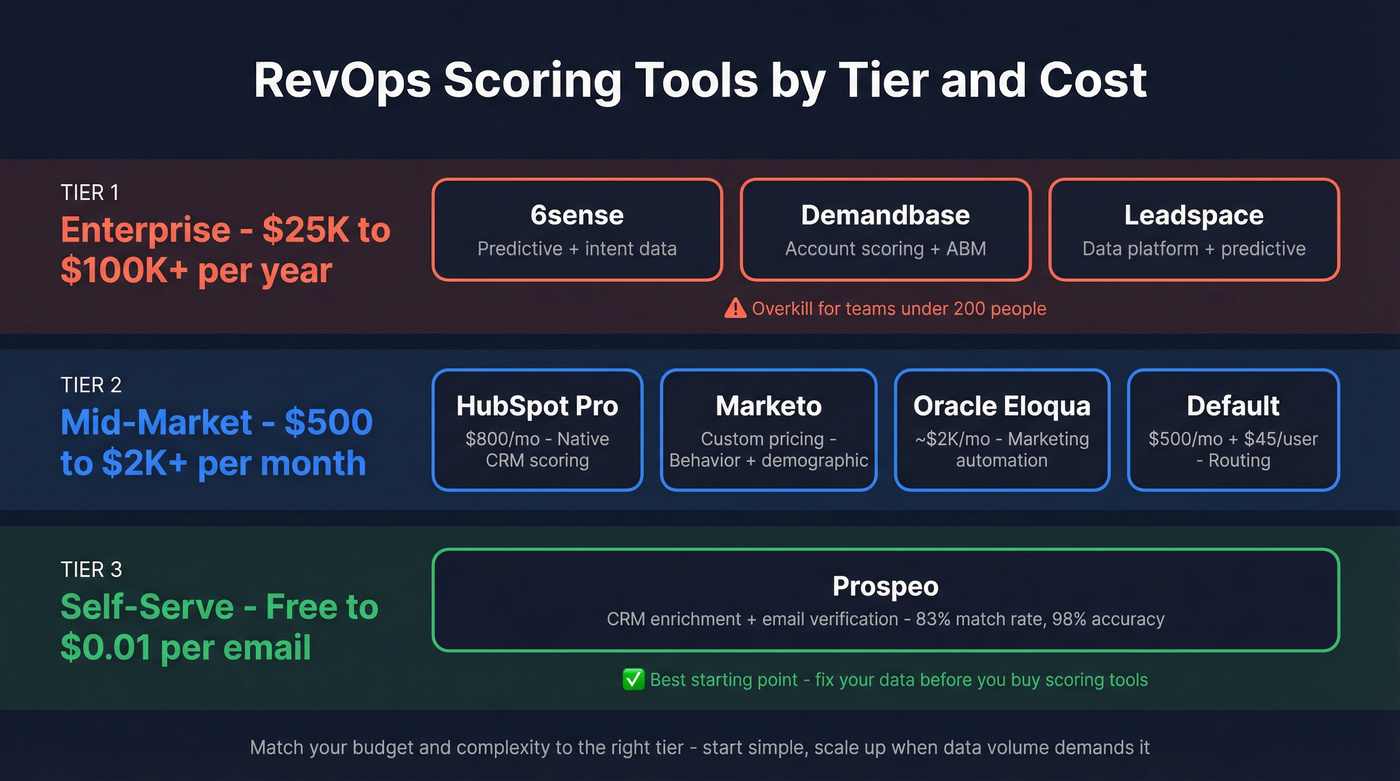
| Tool | Tier | Price | Best For |
|---|---|---|---|
| 6sense | Enterprise | $25K-$100K+/yr | Predictive + intent |
| Demandbase | Enterprise | $30K-$100K+/yr | Account scoring + ABM |
| Leadspace | Enterprise | $25K+/yr | Data platform + predictive |
| Oracle Eloqua | Mid-Market | ~$2K/mo | Marketing automation |
| HubSpot (Pro) | Mid-Market | $800/mo | Native CRM scoring |
| Marketo | Mid-Market | Custom | Behavior + demographic |
| Default | Mid-Market | $500/mo + $45/user | Routing + scheduling |
| Prospeo | Self-Serve | Free; ~$0.01/email | CRM enrichment + verification |
Look, 6sense and Demandbase are powerful platforms, but they're overpriced for teams under 200 people. If you're a 30-person company spending $60K/year on predictive scoring, you're almost certainly better off with HubSpot's native scoring plus a solid enrichment layer. For teams under 50, HubSpot Pro paired with a self-serve enrichment tool is the best combination we've found. For enterprise ABM with 5+ stakeholders per deal, 6sense or Demandbase earns its price tag.
Benchmarks Every Team Should Track
These numbers tell you whether your model is working or just generating noise:
| Metric | Benchmark |
|---|---|
| Lead to MQL conversion | 31% overall; 39% B2B SaaS |
| MQL to SQL conversion | 13% average |
| Speed-to-lead impact | 7x qualification odds within 1 hour |
| AI scoring accuracy lift | ~40% improvement over static |
| Nurturing ROI | 50% more sales-ready leads at 33% lower cost |
If leads scoring 80+ aren't converting 3x better than leads scoring 40, your model is broken. That's the simplest diagnostic test you can run. Pull your scored leads from last quarter, segment by score band, and compare SQL conversion rates. When the high-score band isn't dramatically outperforming, your criteria don't reflect actual buying behavior - and no amount of threshold adjustment will fix that. You need to go back to your closed-won analysis and rebuild the weights.
Governance and Quarterly Reviews
Quarterly reviews aren't optional - they're the difference between a scoring model and a random number generator.
Start by pulling closed-won data from the last 90 days and checking what scores those leads had when they became MQLs. Compare score bands to conversion rates, and collect structured feedback from reps about which MQLs were garbage and which were gold. Then recalibrate. If 80% of MQLs aren't converting, raise the threshold. If sales is starved for leads, lower it. Check for score inflation - if MQL volume is up but conversion is flat or down, your decay rules need tightening. Validate data freshness too, because stale records accumulate fast and re-enriching quarterly is the bare minimum.
We've seen teams build a model once and never touch it again. Twelve months later, the model reflects a buyer profile that no longer exists. Markets shift, ICPs evolve, and scoring models that don't evolve with them become actively harmful. A common frustration across RevOps communities on r/RevOps and Slack groups is exactly this: teams invest heavily in the initial build and then let the model rot because nobody owns the review cadence. A well-governed revops lead scoring process treats the model as a living system, not a one-time project.
Score inflation kills sales trust. Stale job titles, outdated company sizes, and bounced emails turn your MQL threshold into a joke. Prospeo refreshes every record on a 7-day cycle - 6x faster than the industry average - so your fit criteria actually reflect reality.
Your scoring rules are only as current as your last data refresh.
FAQ
How many scoring criteria should a RevOps team start with?
Start with 5-7 criteria maximum. Company size, job title, pricing page visit, demo request, and email domain gets you 80% of the way there. Teams that build 30+ criteria models before validating against conversion data almost always end up simplifying later.
What's a good MQL threshold?
Most B2B teams set their MQL threshold between 60 and 100 points. Compare your threshold against SQL conversion rates quarterly and adjust. If fewer than 15% of MQLs convert to SQL, your threshold is too low.
When should we switch from manual to predictive scoring?
Switch when you have 12+ months of CRM data and 200+ closed-won opportunities to train a model. Below that volume, predictive models don't outperform well-tuned manual rules. Start with rules-based scoring and graduate when your data supports it.
How do you fix bad data before scoring?
Run a field population audit on your CRM - check completion rates for title, company size, industry, email, and phone. If key fields are below 50% populated, enrich before scoring. Prospeo's CRM enrichment returns 50+ data points per contact at an 83% match rate, with native HubSpot and Salesforce integrations.
How often should scoring models be reviewed?
Quarterly at minimum. Compare scores against conversion rates, collect sales feedback, and adjust weights and thresholds. Annual reviews aren't enough - buyer behavior shifts faster than that, and stale models erode sales trust quickly.
