Account-Based Targeting at Scale (2026): The Mechanics-First Playbook
Finding "the right accounts" isn't the hard part anymore. The hard part is making your targeting survive contact churn, messy hierarchies, cookie fragmentation, and attribution theater.
Account-based targeting at scale is an operating system problem: identity -> hierarchy -> coverage -> activation -> measurement. Get the mechanics right and "scale" stops being a buzzword and starts being repeatable.
Here's the thing: most ABM programs don't fail because the messaging's bad. They fail because the plumbing's wrong.
What you need (quick version)
- Prioritize 1) hierarchy + dedupe, 2) buying-group coverage, 3) incrementality. Nail these three and everything else gets easier. Skip them and every "ABT win" turns into a reporting argument.

Assume cookies won't save you. EMARKETER (Jan 2026) estimates 34.9% of US browsers block third-party cookies by default; Google reversed course in 2025 and kept cookies on by default in Chrome, and later in 2025 scrapped Privacy Sandbox. Fragmentation persists, so you still need durable identity and account logic.
Define "scale" as throughput, not ambition. If your process needs 2-3 hours per company, it collapses past 50-200 accounts. Scale means your workflow still works at 500, 2,000, or 10,000 accounts.
Build the list like you're going to activate it tomorrow. "Target accounts" that don't map cleanly to CRM accounts, ad platforms, and outreach sequences are just a spreadsheet hobby.
Use a real buying-group coverage standard. Don't personalize for one "persona." Cover the committee: 6-12 stakeholders per account is normal in serious B2B.
Treat IP targeting as a tactic, not a foundation. It's useful for reach. It's not account truth.
Make incrementality your executive dashboard. If you can't answer "what did we cause?" you'll lose budget the moment finance gets curious.
Pick a data foundation that stays fresh.
Why "targeting at scale" breaks in 2026 (and what "scale" really means)
Most teams think "scale" means "more accounts." In practice, scale means you can add accounts without adding headcount, chaos, or measurement lies.

Here's the scenario I've seen a dozen times: you start with 50 named accounts, do heroic research, write custom sequences, and run a few ads. It works because you're basically doing bespoke consulting per account.
Then leadership says, "Cool, let's do 500."
That's where it breaks.
The practitioner reality is brutal: high-touch ABT takes 2-3 hours per company if you're doing real research, mapping stakeholders, and writing anything beyond Mad Libs personalization. That time math collapses somewhere around 50-200 accounts, even with a good team, because the work isn't just "finding contacts" - it's keeping them current, keeping the account model consistent, and keeping plays coordinated across channels.
A simple resourcing heuristic that holds up in the real world:
- 1:1 works when you can afford ~1 marketer per 10-25 accounts (plus SDR/AEs who actually multi-thread).
- 1:few works when clusters are 20-80 accounts with shared pains, shared proof, and shared plays.
- 1:many is where you earn "at scale" - but only if identity, hierarchy, and measurement are already boringly reliable.
Now layer in the 2026 constraint: EMARKETER pegs 34.9% of US browsers blocking third-party cookies by default, and Google's 2025 reversal means Chrome doesn't "solve" the problem for you. You're operating in a mixed world: some environments are cookie-light, some are cookie-friendly, and all of it is harder to reconcile across systems.
And the hidden killer: your systems weren't built for account truth. CRM accounts don't match ad platform accounts. Subsidiaries roll up weird. Contacts duplicate. Opt-outs don't propagate. Your "target list" becomes three different lists depending on which tool you're looking at.
One more thing that quietly wrecks scale: teams try to brute-force research with LLMs and spreadsheet automation. It feels fast at 50 accounts, then turns expensive and inconsistent at 500, especially when you're paying per-enrichment, per-workflow, and per-seat just to recreate the same "who's on the buying committee?" work every quarter.
When people say "ABM doesn't work," they usually mean: our operating system doesn't work.
Scale, in 2026 terms, is:
- You can resolve identity across touchpoints without double-counting people.
- You can govern hierarchy so "the account" means the same thing everywhere.
- You can cover buying groups without relying on one champion.
- You can activate across channels with consistent audiences and plays.
- You can measure incrementality so finance can't dismiss it as attribution fluff.
Hot take: if your average contract value is small and your sales cycle is short, you probably don't need "enterprise ABM." You need clean lists, tight ICP, and ruthless experimentation.
Skip the orchestration suite until the basics stop breaking.
The 5-layer operating system for account-based targeting at scale
Think of account-based targeting at scale as a five-layer stack. Each layer has a job, each layer has a "how it fails," and each failure looks like a marketing problem until you trace it back to mechanics.
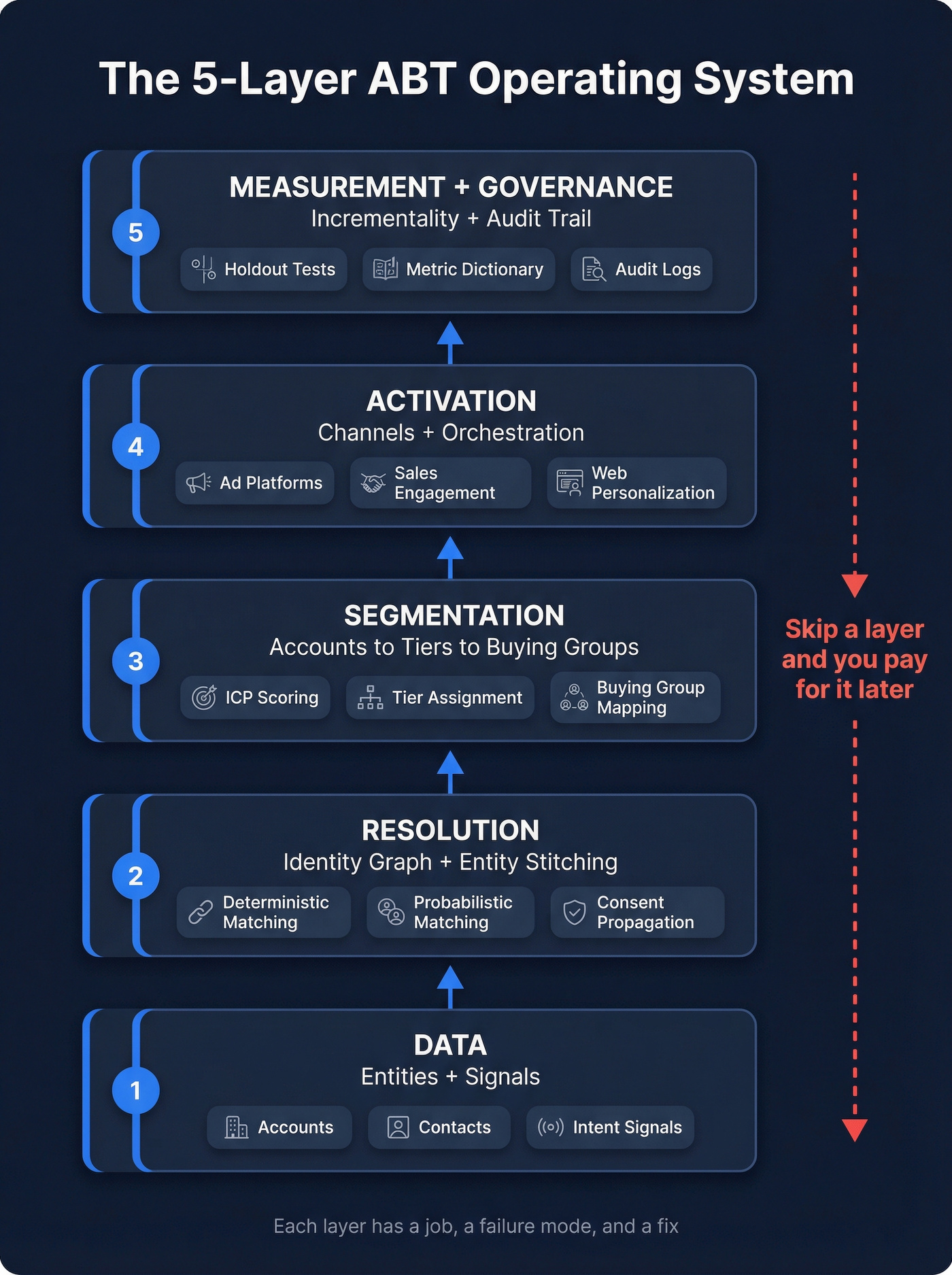
Layer 1: Data (entities + signals)
Job: Provide the raw material - accounts, contacts, intent, engagement, technographics, product usage, event attendance, sales activity.
Failure mode -> symptom -> fix
- Stale contacts -> bounce rates climb, reps stop trusting lists -> verify + refresh on a schedule.
- Inconsistent firmographics -> tiers drift, routing breaks -> standardize fields + define a source of truth.
- Signal soup (too many "intent" sources) -> everything looks in-market -> pick 1-2 primary signals and define thresholds.
Where it lives: CRM + MAP + product analytics + data warehouse (or CDP) + data provider.
Data contract (minimum viable before activation):
- Account: domain, country/region, employee band, industry, parent identifiers (or linkage keys)
- Contact: email/phone (or hashed IDs), role/function, seniority, consent state, last verified date
- Events: timestamp, channel, campaign/play ID, account ID, person ID
Layer 2: Resolution (identity graph + entity stitching)
Job: Link identifiers (email, phone, CRM IDs, device IDs, etc.) into a persistent profile - your identity graph.
You'll use two matching modes:
- Deterministic matching: exact matches like email, phone, CRM ID, hashed identifiers.
- Probabilistic matching: inferred matches using signals like IP/device/behavior patterns.
Failure mode -> symptom -> fix
- Duplicate identities -> inflated reach + "amazing" attribution -> define merge rules and enforce them centrally.
- Consent doesn't travel -> you keep targeting opt-outs -> attach consent to the identity record, not a single tool.
- Probabilistic treated as truth -> over-targeting + over-credit -> label match confidence and restrict usage.
Where it lives: CDP/warehouse identity tables + audience builder + server-side event pipeline (Conversions API style).
Layer 3: Segmentation (accounts -> tiers -> buying groups)
Job: Decide which accounts matter, what tier they're in (1:1 / 1:few / 1:many), and which roles you need to influence.
Failure mode -> symptom -> fix
- Tiering by vibes -> random acts of targeting -> score with explicit fields and lock tier rules for a quarter.
- Persona-of-one -> deals stall in procurement/security/finance -> define buying-group coverage SLAs per tier.
- No suppression logic -> you target customers like prospects -> build lifecycle-based suppression at the account family level.
Where it lives: CRM (fields + views) + warehouse (scoring) + ABM suite/DSP audiences.
Layer 4: Activation (channels + orchestration)
Job: Push audiences into ad platforms, email tools, sales engagement, website personalization, SDR call lists, events - then run plays consistently.
Failure mode -> symptom -> fix
- Audiences don't match across tools -> spend waste + rep confusion -> standardize IDs and sync from one audience source.
- Plays aren't triggered -> "ABM" becomes a calendar of campaigns -> define triggers, owners, and logging.
- Creative doesn't map to buying group -> engagement spikes but pipeline doesn't -> build role-based proof packs.
Where it lives: DSPs, paid social, sales engagement, web personalization, event platforms, and the workflow layer (automation + routing).
Layer 5: Measurement + governance (incrementality + audit trail)
Job: Prove lift, not just correlation - and keep definitions stable enough to trust.
Failure mode -> symptom -> fix
- Attribution theater -> finance cuts budget -> run holdouts and report incremental lift.
- Definitions drift -> every QBR is a debate -> publish a metric dictionary and lock it for the test window.
- No audit trail -> privacy and ops risk -> log identity merges, hierarchy changes, and suppression propagation.
Where it lives: Warehouse + BI + experiment logs + governance docs (and yes, tickets).
If you want the simplest mental model: Data -> Resolution -> Segmentation -> Activation -> Measurement/Governance. Skip a layer and you'll pay for it later, usually in duplicate targeting and fake attribution.
Data foundation: build a target list you can actually activate
Most ABT programs fail before they start because the "target list" is built like a strategy deck, not like an operational asset.
A list you can activate has three properties:
- It maps cleanly to real accounts in your CRM/MAP/ad platforms.
- It has enough contacts to reach the buying group.
- It's refreshed often enough that it doesn't decay between quarters.
Demand Gen Report's ABM benchmark calls out the same pain points you hear in every QBR: proving ROI, sales/marketing alignment, and scaling programs. Those are symptoms of a shaky data foundation, not a lack of creativity.
If you want the benchmark context, the cleanest write-up is the Demand Gen Report ABM benchmark summary.
The four prioritization pillars (the only ones that hold up)
I like the "fit + reality" model for account selection. It's simple enough to govern and specific enough to execute.

Use these four pillars to score accounts:
- Revenue potential: size, spend capacity, expansion potential, multi-product fit.
- Awareness: do they already know you? have they engaged with content, events, PR?
- Relationship: existing champions, past opps, partner ties, alumni, open conversations.
- Need evidence: intent topics, hiring, tech stack shifts, compliance deadlines, product usage signals.
If you can't point to at least two pillars per account, you're doing wish-list ABT.
Template: account scoring fields (copy/paste)
Account scorecard (minimum viable):
- ICP cluster (A/B/C)
- Revenue potential (1-5)
- Awareness (1-5)
- Relationship (1-5)
- Need evidence (1-5)
- Tier (1:1 / 1:few / 1:many)
- Primary buying group (functions + roles)
- Activation readiness (Yes/No)
Template: "activation readiness" definition
An account's activation-ready when:
- It matches to a CRM Account ID (or you can create one cleanly)
- It's got a domain you trust
- It's got at least 6 contacts across the buying group (or a plan to get them)
- Consent/opt-out status is trackable
- You can route it into at least two channels (ads + outbound, or email + web personalization)
Turning accounts into verified buying-committee contacts (the practical step)
This is where teams waste weeks: they pick accounts, then realize they can't actually reach the committee without burning deliverability or paying for junk data.
In our experience, the fastest way to kill an ABT motion is letting bad emails into sequences. Your bounce rate jumps, your domain reputation tanks, and suddenly every "play" underperforms for reasons nobody wants to admit.
A workflow that actually scales:
- Search companies by ICP filters (industry, headcount, revenue, technographics, growth signals). Start with the B2B leads database so you're building from accounts, not random leads.
- Add intent filters to prioritize accounts showing relevant topic spikes via intent data.
- Enrich/export into CRM or sequences using data enrichment so only valid emails go into outreach and mobiles are attached where needed.
That's how you get buying-group coverage without turning your SDR team into part-time researchers.
You just read that high-touch ABT takes 2-3 hours per company and collapses past 200 accounts. Prospeo's 300M+ profiles with 30+ filters - intent, technographics, headcount growth, funding - let you map 6-12 buying group members per account in minutes, not hours. 98% email accuracy. 7-day refresh. Your Layer 1 data problem, solved.
Stop rebuilding your target list every quarter. Build it once on data that stays fresh.
Identity resolution & deduplication: the non-negotiable mechanics
Identity resolution sounds like martech jargon until you see what happens without it: duplicated targeting, inflated reach, and attribution that's basically fan fiction.
At a practical level, identity resolution links identifiers (email, phone, CRM IDs, device IDs, etc.) into a persistent profile. That profile lives in an identity graph so your systems can agree that "this person" is the same person across touchpoints.
You need both matching types:
- Deterministic matching for accuracy (email/phone/user IDs).
- Probabilistic matching for coverage (behavioral patterns, device/IP signals).
Here's the rule we enforce: deterministic is "truth," probabilistic is "reach." Mix them and you'll over-target and over-credit.
Implementation steps (what to do, in order)
Choose your primary keys
- Person: CRM Contact ID (if present), hashed email, phone
- Account: CRM Account ID, domain, and a stable parent identifier (D-U-N-S style linkage if you've got it)
Define merge rules (and make them boring)
- One person record per unique email (or hashed email)
- Phone can attach to a person, but never creates a new person by itself if email exists
- If two records share a CRM Contact ID, they're the same person. Period.
Set match confidence labels
- Deterministic: eligible for suppression, frequency capping, and measurement
- Probabilistic: eligible for awareness targeting only (no penetration reporting, no ROI claims)
Centralize suppression propagation
- Opt-out must update: email tools, sales engagement, ad audiences, enrichment, analytics
- Store consent state on the identity record so it survives tool changes
Log identity changes
- Every merge/split should write an audit event (who/when/why)
- If you can't explain why a person disappeared from an audience, you don't have governance
Do / don't (the rules that prevent chaos)
Do:
- Use deterministic IDs as your primary keys wherever possible (CRM Contact ID, hashed email, phone).
- Build a dedupe rule set before you activate audiences (one person -> one profile).
- Centralize opt-outs at the identity level so consent travels with the profile.
Don't:
- Don't let every tool create its own "person" record. That's how you get three versions of the same VP in three systems.
- Don't measure "unique reach" without deduping identities first. You're just counting duplicates with confidence.
- Don't ignore consent propagation. In 2026, regulators care whether opt-outs actually stop downstream targeting and analytics.
If you can't keep identity clean, don't claim ROI. Call it engagement reporting.
Account matching & hierarchy governance (what breaks first)
If identity resolution is the "person" problem, hierarchy is the "account" problem. And hierarchy's usually what breaks first when you scale.
Salesforce's native model is a big part of why: the standard Account hierarchy uses a single Parent Account field. Each account can have only one parent. That's not how the real world works.
In real B2B, you've got legal parent vs operating parent, regional HQ vs global HQ, brand families, PE roll-ups, shared services entities, and the classic "we sell to the subsidiary, but procurement sits at the parent" situation.
So what happens? Teams hack it:
- Manual linking (slow, inconsistent)
- Flows/Apex matching on names/domains (brittle)
- Spreadsheet "truth" that never syncs back
And then your targeting fractures:
- Ads target the parent, sales works the subsidiary
- Measurement rolls up weird
- Suppression lists miss parts of the family
- You double-count pipeline because opps sit on different nodes
Example model: legal vs operating vs GTM (use all three)
You need a hierarchy model that supports multiple relationship types, not just "parent." The cleanest approach is to maintain three parallel views:
| Hierarchy view | What it answers | Used for | Common owner |
|---|---|---|---|
| Legal | "Who ultimately owns this entity?" | compliance, reporting rollups | RevOps + Finance |
| Operating | "How do they actually run?" | territory planning, org mapping | RevOps |
| GTM | "How do we sell and suppress?" | targeting, routing, ABT reporting | RevOps + Sales leadership |
Relationship types worth modeling explicitly (even if you store them as a simple relationship table):
- Ultimate parent (legal ownership)
- Subsidiary / branch
- Brand family (shared brand, separate legal)
- Shared services (procurement/security centralized)
- PE portfolio (not always suppress-worthy, but often relevant)
- Strategic account group (your internal grouping for plays)
Most teams should drive activation and suppression from the GTM hierarchy (because it matches how you sell), while using legal hierarchy for rollups and governance.
Field checklist (use D&B-style linkage identifiers)
If you want hierarchy that survives naming changes and domain weirdness, use stable linkage fields. The cleanest set is the D&B family tree identifiers:
- HQ D-U-N-S
- Domestic Ultimate D-U-N-S
- Global Ultimate D-U-N-S
Those three fields let you build roll-ups that don't depend on fuzzy name matching. They also let you answer basic questions like: "Are we already in this family?" and "Should this subsidiary be suppressed because the parent is in a deal?"
Preview + rollback: the part everyone skips (and then regrets)
Hierarchy changes are high-blast-radius. A bad update doesn't just "look wrong" - it breaks routing, suppression, reporting, and sometimes comp plans.
Run hierarchy updates like a release:
- Preview: show the before/after rollups for top families and top pipeline accounts.
- Approval: RevOps owns the logic; Sales leadership signs off on GTM rollups.
- Publish: write changes in a controlled job, not ad-hoc edits.
- Rollback: keep a snapshot so you can revert within hours, not weeks.
If hierarchy isn't governed by RevOps with rollback, you don't have "account-based" anything. You've got a naming convention.
What must cascade when hierarchy changes (mini checklist)
When an account moves in/out of a family, these objects and rules must update or you'll get silent breakage:
- Opportunities: rollup reporting, account team visibility, forecast grouping
- Contacts/Leads: account association, buying-group coverage reporting
- Suppression lists: customers, open opps, competitors, do-not-target families
- Routing: SDR ownership, territory rules, partner assignment
- Audiences: matched audiences/onboarding segments, exclusions, frequency caps
- Attribution/BI: account family keys used in dashboards and experiments
Buying-group targeting at scale (stop "persona-of-one" personalization)
Most personalization advice is stuck in a 2018 mindset: "Pick a persona, write a message, personalize the first line."
That's not how enterprise buying works. It's not even how mid-market buying works anymore.
Gartner's buyer research is the clearest reality check: buying groups are 5-16 people across up to four functions. And the consensus dynamics are counterintuitive:
- Tailoring for individual-level relevance has a 59% negative impact on consensus.
- Tailoring for buying-group relevance increases consensus 20%.
So the goal isn't "make the VP of IT feel seen." The goal is "make the group agree this is worth doing." If you need a cleaner way to define roles, start with account-based marketing personas instead of one-person caricatures.
Role-coverage checklist (minimum viable buying group)
For most B2B software/services motions, you want coverage across:
- Economic buyer: budget owner (CFO/VP Finance/GM)
- Champion: day-to-day owner (Director/Manager in function)
- Technical buyer: IT/Security/Data/Architecture
- Procurement / vendor management: especially in larger orgs
- Executive sponsor: the person who cares about strategic outcomes
- Users/influencers: the people who'll live with the change
Coverage rule of thumb:
- Tier 1 (1:1): 10-16 stakeholders
- Tier 2 (1:few): 6-10 stakeholders
- Tier 3 (1:many): 3-6 stakeholders
Template: buying-group coverage SLA (simple and enforceable)
Set an SLA that forces action instead of wishful thinking:
- Tier 1: within 10 business days of tier assignment, reach 10+ contacts across 4+ functions; refresh any contact older than 90 days.
- Tier 2: within 15 business days, reach 6+ contacts across 3+ functions; refresh any contact older than 120 days.
- Tier 3: within 20 business days, reach 3+ contacts across 2 functions; refresh any contact older than 180 days.
Owner: RevOps (coverage reporting) + SDR manager (coverage execution). If the SLA fails, the account drops a tier or gets removed. Harsh? Yes. Effective? Also yes.
I've watched teams obsess over a perfect message to one person while ignoring the two functions that can veto the deal. That's not personalization. That's self-sabotage.

Targeting methods reality check: IP targeting isn't account targeting at scale
IP targeting gets marketed as "account-based" because it's convenient: no cookies required, easy to buy, easy to explain.
But it's not account truth. It's a reach tactic with a lot of noise.
The hard numbers are ugly:
- IP-to-postal accuracy is ~13%
- IP-to-email accuracy is ~16%
- Provider agreement is 6.4% (postal) and 2.8% (email)
- IPv6 is under-represented by 72%
Truthset benchmarked nearly 1B IP records across six providers over a 90-day window. These aren't edge cases; they're structural limits of the method.
Contrarian pro/con (the honest take)
Where IP targeting is useful
- Broad awareness plays when you need reach
- Supplementing other identity methods
- Certain office-heavy industries (less remote work)
Where it breaks
- Remote/hybrid work (the "account IP" isn't the account)
- Household/shared networks
- Any measurement that assumes precision
- Frequency capping and suppression (you'll miss and over-hit people)
Use / skip rules (so you don't fool yourself)
Use IP targeting if:
- You treat it as top-of-funnel reach
- You measure lift with holdouts (not platform attribution)
- You combine it with deterministic identity where possible
Skip IP targeting if:
- You need precise account penetration reporting
- You're trying to prove ROI to finance with shaky attribution
- Your audience is heavily remote or distributed
Skip IP targeting for penetration reporting. Period.
Activation: signals -> plays matrix (by tier, by channel)
Activation's where strategy meets physics. You can have perfect segmentation and still fail if you don't translate signals into plays that match the tier and the channel.
Also: programmatic's fast, but your decisions need to be made before the auction.
A plain-English RTB flow looks like this:
- A user loads a page.
- The publisher sends an ad request to an exchange.
- Your DSP evaluates the user/account signals and bids.
- The auction completes in under 100ms.
- The winning ad renders.
That's why your audiences and identity logic need to be pre-built. You don't get to "think" during the auction.
The matrix (10 plays you can actually run)
Each "Play" below includes the trigger so it's operational, not inspirational.
| Signal | Tier | Channel | Play (trigger -> action) | Example |
|---|---|---|---|---|
| Intent spike on core topic | 1:few | Ads + SDR | >=2-week spike -> 3-touch surge + proof pack | SDR sends "2-slide POV" + books 15-min triage |
| New exec hire | 1:1 | Email + call | New VP/Director -> re-intro + exec sponsor ask | AE sends "first 90 days" note + asks for sponsor |
| Pricing page + security page | 1:1 | Web + email | 2 high-intent pages -> security/ROI bundle | Auto-send ROI calc + security one-pager; CSM joins |
| Competitor tech detected | 1:many | Ads | Competitor present -> displace ads + landing page CTA | "Switch checklist" ad -> comparison page CTA |
| Job postings in target function | 1:few | Email + ads | Hiring surge -> capacity/efficiency angle | Sequence: "reduce time-to-value" + webinar invite |
| Product usage expansion signal | 1:1 | In-app + exec email | Usage threshold -> expansion committee play | Exec email + invite to roadmap session |
| Event attendance (2+ people) | 1:few | Email + event | Multi-attendee -> roundtable + SDR follow-up | Invite to peer dinner; SDR books debrief |
| Stalled opp (no activity 21 days) | 1:1 | Exec email | Stall threshold -> sponsor re-open | VP Sales emails sponsor with 3-option next step |
| Website revisit from new function | 1:few | Ads + SDR | New function engaged -> add role + tailor proof | Add Security contact; send security case study |
| Customer in same parent family | 1:many | Ads + outbound | Family adjacency -> "land-and-expand" narrative | Ads: parent-level outcomes; SDR references sibling |
Minimum viable orchestration (so plays don't die in Slack)
A play's only real if it's got:
- Trigger threshold: what event count/time window fires it (and what doesn't).
- Owner: marketing owns audiences/ads; SDR manager owns tasks; RevOps owns routing.
- Logging: every play writes a play ID to CRM (campaign member, task, or custom object).
- Stop rules: suppression when an opp opens, when a meeting's set, or when consent changes.
If you can't log plays, you can't learn. If you can't learn, you can't scale.
Channel constraints (the part teams ignore)
- Ads = reach and reminders. Great for coverage, terrible for coordination.
- Email + outbound = coordination. This is where buying groups align on next steps.
- Events = consensus acceleration. Nothing moves a committee faster than a shared experience and a reason to talk internally.
30/60/90-day SLA (time-phased alignment that prevents "ABM theater")
This is how we keep sales and marketing aligned without weekly debates:
- Days 0-30 (Coverage): hit buying-group coverage SLA; launch baseline ads; SDR starts multi-threading.
- Days 31-60 (Progression): target meetings with at least 2 functions per account; run 1 event touch (virtual or in-person).
- Days 61-90 (Conversion): focus on opp creation and stage movement; exec sponsor outreach for Tier 1; tighten suppression to avoid waste.
If you can't agree on this SLA, you're not running account-based targeting. You're running parallel motions and hoping they collide.
I once watched a team spend six figures on web personalization while their "Tier 1 audience" was 30% duplicates and 20% customers. The tool didn't fail. The inputs did.
Measurement integrity + incrementality (the part that keeps budget alive)
This is where ABT either becomes a growth engine or becomes a budget line item that gets cut.
The #1 measurement failure is using lead-centric KPIs (MQLs, form fills) to judge account-centric work. A 6sense survey of 600+ marketers found ~80% run ABM, but only ~30% consider their programs mature. That maturity gap is mostly measurement and governance, not "we need better ads."
The only dashboard that matters (spec)
If your dashboard doesn't answer these questions, it's not an ABT dashboard. It's a reporting artifact.
Use Mutiny's four-metric model as the spine:
- Engagement (account-level, not lead-level)
- Pipeline contribution (sourced + influenced, with definitions)
- Velocity (time between stages, time-to-meeting, time-to-close)
- Revenue impact (wins, expansion, retention where relevant)
Dashboard sections (minimum viable):
A) Target coverage
target accounts by tier
- % accounts with buying group coverage (by role/function)
- Contact freshness (last verified date)
B) Account engagement
- Engaged accounts (by tier)
- Engagement depth (multi-session, multi-stakeholder)
- Key page engagement (pricing, security, integration docs)
C) Pipeline
- Meetings held (by tier, by play)
- Pipeline sourced vs influenced (define both)
- Stage conversion rates for target vs non-target
D) Velocity
- Median days: first touch -> meeting
- Meeting -> SQL/opportunity
- Opportunity -> close
E) Revenue
- Closed-won revenue from target accounts
- Expansion revenue (if applicable)
- CAC/payback proxy (even if rough)
The finance conversation (incrementality is the answer)
The moment you scale spend, finance asks: "How do we know this caused anything?"
If your answer is "multi-touch attribution," you're going to lose. Platform attribution is inflated, and everyone knows it.
Holdout tests routinely show 60-70% attribution inflation when you compare what platforms take credit for versus what actually changes in a control group. That's not a rounding error. That's the difference between "ABT works" and "ABT is a tax."
Step-by-step incrementality plan (practical, not academic)
Step 1: Pick one primary outcome
- Early-stage: meetings held with target accounts
- Later-stage: pipeline created
- Mature: revenue (expect longer cycles)
Step 2: Choose the simplest holdout you can run
- Account holdout: randomly hold out 10-20% of target accounts from ads (and/or specific plays)
- Channel holdout: hold out one channel for a subset (ex: no paid social for group B)
- Geo holdout: only if you're big enough and your geo split is clean
Step 3: Lock the rules
- Same tiers, same ICP, same time window
- Same sales coverage model (no "extra love" for treatment)
- Pre-register success metrics (so you don't move goalposts)
Step 4: Run long enough
- Minimum 4-6 weeks for engagement/pipeline signals
- Longer if you're measuring revenue
Step 5: Read the result like an operator
- Lift in meetings/pipeline vs control
- Cost per incremental meeting/opportunity
- Downstream quality (stage progression, win rate)
Step 6: Only then scale budget If you can't show lift, don't scale. Fix the operating system.
Common ways teams accidentally invalidate holdouts
This is where most "experiments" die:
- SDRs still work holdout accounts. If holdout means "no ads," fine. Then don't claim "full-funnel lift." If holdout means "no plays," enforce it.
- Retargeting leakage via lookalikes and expansions. Your holdout still gets hit through modeled audiences.
- Cross-channel contamination. You hold out paid social, but email and events spike only in treatment because reps prioritize those accounts.
- Changing tiers mid-test. If you re-tier accounts during the window, you changed the treatment.
- Measuring too early. Long-cycle deals don't show revenue lift in two weeks; you'll declare "no impact" and kill a working program.
- Family-tree leakage. You hold out a subsidiary but still target the parent, then act surprised when the holdout moves.
If you can't run account holdouts, don't claim ROI. Call it engagement reporting. That honesty buys you credibility and keeps the program alive long enough to mature.
Server-side capture and clean-room style overlap (keep it practical)
Two mechanics make measurement sturdier in 2026:
- Server-side event capture (Conversions API style): send key events (meeting held, opp created, stage change) from your backend/warehouse to ad platforms for optimization, without pretending it's perfect attribution.
- Clean-room style overlap checks: when you need to compare exposure vs outcomes without moving raw identifiers around, use privacy-safe matching workflows to validate reach and frequency at the account level.
Governance & privacy ops: consent must travel with the identity
Privacy enforcement is operational now. Regulators don't just ask "do you have a banner?" They test whether opt-outs actually stop downstream use: audience creation, targeting, analytics, the whole chain.
By 2026, 20 US states have comprehensive privacy laws; eight went live in 2025 (DE, IA, NE, NH, TN, MN, MD, NJ). IN/KY/RI go live Jan 1, 2026, on top of that wave. If you're targeting at scale across the US, you're in privacy ops whether you like it or not.
That changes how you run ABT: consent can't live in one system. It's got to travel with the identity.
Governance checklist (minimum viable)
- Consent state attached to identity (not just a cookie)
- Suppression lists synced to every activation endpoint (ads, email, enrichment, analytics)
- Data lineage documented: where identifiers came from, when they were refreshed
- Role-based access controls for who can export/activate audiences
- Change control for hierarchy and identity rules (preview + rollback)
Audit trail requirements (what you need to prove)
If someone opts out, you need to show:
- When the opt-out was captured
- Which identifiers it applied to (email, phone, device IDs)
- Which systems received the suppression
- That downstream audiences were updated
- That reporting excludes suppressed identities where required
This sounds heavy until you've lived through a "prove it" request. Then it becomes non-negotiable.
The operating system recap (and what to do this week)
Account-based targeting at scale isn't a campaign. It's five layers that either work together, or quietly sabotage each other:
- Data you can trust and refresh
- Identity resolution that dedupes people and carries consent
- Hierarchy governance that defines "the account" consistently
- Buying-group segmentation + activation plays that run on triggers
- Incrementality measurement that proves lift, not vibes
If you want momentum fast, do this this week:
- Pick one tier (usually 1:few) and lock the tier rules for 90 days.
- Set a buying-group coverage SLA and publish it.
- Build one audience source of truth and sync it everywhere.
- Run one account holdout (10-20%) and commit to reading the result honestly.
Do those four things and you'll feel the program click. Skip them and you'll be stuck in reconciliation meetings.
Tooling reality (so you don't buy the wrong stack)
Tool sprawl is the fastest way to kill ABT. Suites look tempting because they promise "one platform," but you still need clean data, clean identity, and clean governance.
Pricing is where teams get burned. Typical market ranges: mid-market ABM suites often run ~$30-50k/year; enterprise stacks commonly hit $100k+/year once data onboarding and services are included. Implementation isn't "turn it on" - plan for 6-12+ weeks if you're doing it properly.
| Layer | What it does | Best for | Typical cost | Time to value |
|---|---|---|---|---|
| ABM suites | Orchestration | ABM ops | $30-50k/yr | 6-12+ wks |
| CRM/MAP | System of record | Lifecycle | $1-5k/mo | 2-8 wks |
| Data/verify | Contacts + refresh | Coverage | Free tier available to ~$20k/yr | Days-2 wks |
| Intent | Topic signals | Prioritization | $10-40k/yr | 2-6 wks |
| Personalization | Web experiences | Tier 1/2 | $10-30k/yr | 2-6 wks |
Notes that matter more than the table:
- Matched audiences/onboarding is where identity quality shows up immediately (good = clean reach; bad = waste).
- CDP/warehouse becomes your control point once you're syncing audiences and running experiments.
- If you're buying an ABM suite to fix data, you're buying the wrong thing. Start with the ABM without expensive tools approach, then add software once the mechanics are stable.
Buying-group coverage dies when contacts bounce and reps lose trust. Prospeo's 5-step verification, catch-all handling, and weekly data refresh keep your coverage map current across every tier - 1:1, 1:few, or 1:many. At $0.01 per email, scaling from 200 to 2,000 accounts doesn't break your budget or your plumbing.
Cover the full buying committee with verified contacts that actually connect.
FAQ
What's the difference between ABM and account-based targeting at scale?
ABM is the strategy of focusing sales and marketing on a defined set of accounts. Account-based targeting at scale is the operating system that makes it repeatable across hundreds or thousands of accounts: identity, hierarchy, buying-group coverage, activation, and incrementality.
Why is IP targeting unreliable for account targeting?
IP targeting is noisy at the entity level: IP-to-postal accuracy averages ~13% and IP-to-email ~16%, and providers often disagree. Use it for reach and awareness, then validate performance with 10-20% account holdouts instead of penetration reporting or ROI claims.
How many stakeholders should you target per account in B2B?
Plan for 6-12 stakeholders per account, and up to 16 for Tier 1. Buying groups commonly span 5-16 people across multiple functions, so single-person targeting increases the odds you'll miss procurement, security, or finance veto power.
What incrementality lift is "good enough" to scale budget?
Scale when a holdout test shows measurable lift in your primary outcome (usually meetings or pipeline) and your cost per incremental meeting/opportunity fits your payback model. If lift is flat after 4-6 weeks, fix identity/hierarchy or play execution before adding spend.


