Data Integrity vs Data Quality: What's Actually Different and Why It Matters
Your VP of Marketing just pulled a customer list for a direct mail campaign. Three weeks later, 30% of the mailers come back undeliverable. She's in Slack at 9am asking why the CRM data is "garbage." The data engineering team says the pipeline is fine. The RevOps lead says the records haven't been tampered with. Everyone's frustrated, nobody agrees on the problem, and the finger-pointing has begun.
They're arguing about two different problems without realizing it. One is data integrity. The other is data quality. Conflating them is how organizations burn $12.9M per year on average - a widely cited Gartner benchmark - and MIT Sloan estimates the revenue impact at 15-25% annually. Over 25% of organizations estimate losses exceeding $5M per year from data issues; 7% report north of $25M. The money is real. The confusion is expensive.
Quick Summary
- Data integrity = data stays uncorrupted and unaltered throughout its lifecycle. Think access controls, audit trails, checksums.
- Data quality = data is accurate, complete, and fit for a specific use. Think profiling, cleansing, verification.
- Most teams conflate the two. The result: wasted engineering cycles fixing the wrong problem.
What Is Data Integrity?
The word "integrity" comes from the Latin integer - whole, complete, undivided. Data integrity means the data hasn't been corrupted, tampered with, or altered in unauthorized ways from the moment it enters your system through every transformation and report.
The concept got its teeth in regulated industries. The FDA cracked down on generic drug manufacturers who'd been fabricating lab data. Able Laboratories was cited in 2005 for false data and failure to review audit trails. Ranbaxy received warning letters in 2006 and 2008 for deliberately altered records. These weren't quality problems - the data wasn't inaccurate by accident. It was corrupted on purpose. That distinction matters.
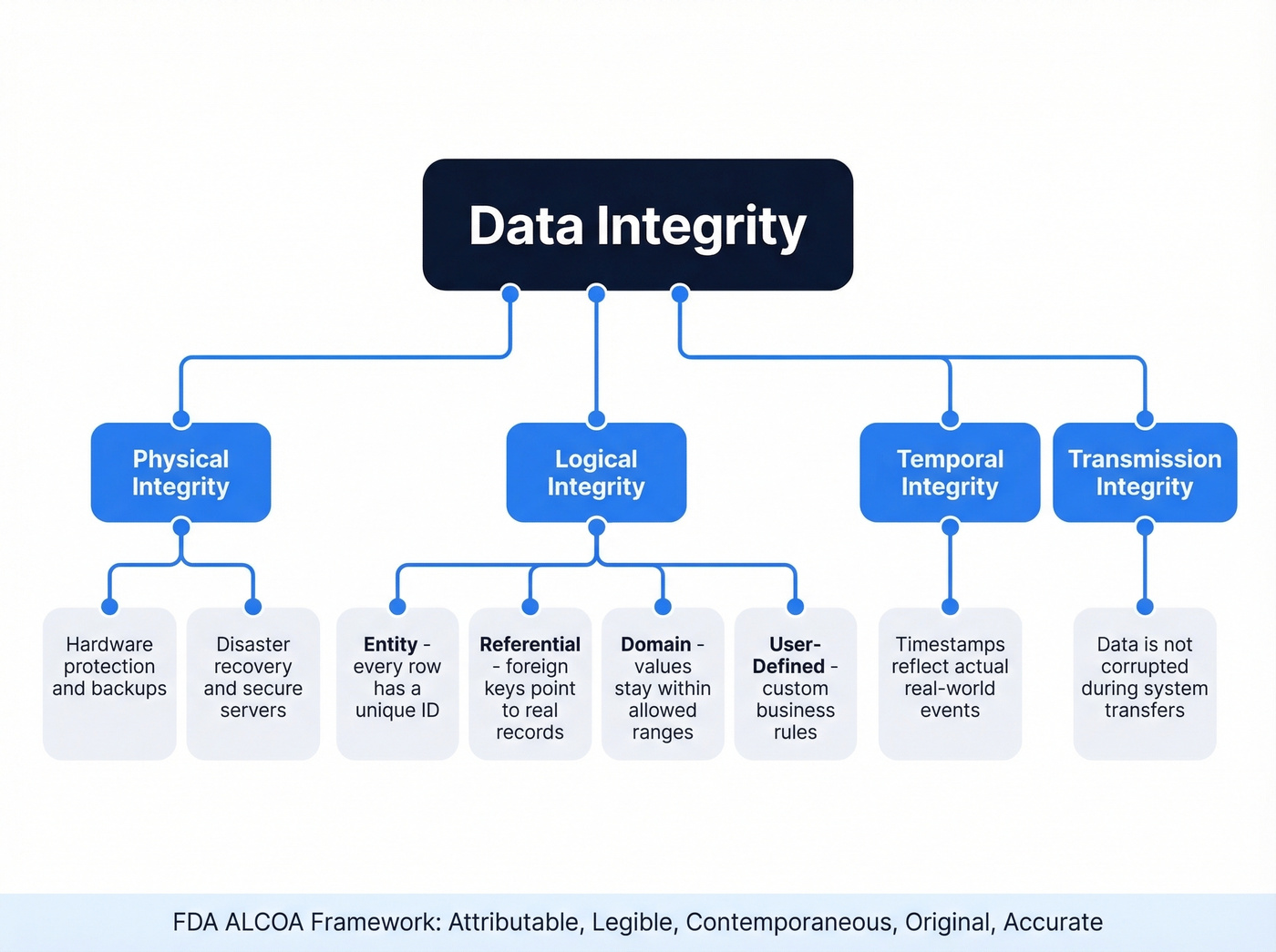
A common compliance-grade integrity checklist breaks integrity into four types. Physical integrity covers hardware protection - backups, secure servers, disaster recovery. Logical integrity lives inside your database: entity integrity (every row has a unique identifier), referential integrity (foreign keys point to real records), domain integrity (values fall within allowed ranges), and user-defined rules specific to your business. Beyond those, temporal integrity ensures timestamps reflect actual events, and transmission integrity means data isn't corrupted during transfers between systems.
The FDA's ALCOA framework captures this cleanly: data should be Attributable, Legible, Contemporaneous, Original, and Accurate. If you work in finance, healthcare, or any regulated domain, ALCOA isn't optional - it's the baseline your auditors expect.
What Is Data Quality?
Data quality is about fitness for use. A dataset can be perfectly uncorrupted - nobody tampered with it, the audit trail is clean - and still be useless because it's outdated, incomplete, or full of duplicates.
Six dimensions define quality: accuracy (does the data reflect reality?), completeness (are required fields populated?), consistency (do the same values match across systems?), validity (does data conform to defined formats?), uniqueness (are there duplicates?), and timeliness (is the data current enough for its intended use?). These are the measurable standards that determine whether a dataset can actually support decisions.
In practice, quality problems are mundane and pervasive. 60% of data quality challenges stem from variations in business names, personal names, and addresses. CRM duplication rates hit 20%. That direct mail campaign with 30% returns? Classic quality failure - the records weren't tampered with, they were just stale.
Key Differences at a Glance
Can you have one without the other? Absolutely. A database can be perfectly uncorrupted but filled with outdated phone numbers - integrity pass, quality fail. Conversely, someone could manually "fix" records by overwriting fields without authorization. The data looks more accurate, but you've just introduced an integrity violation.

| Dimension | Data Integrity | Data Quality |
|---|---|---|
| Purpose | Protect truth of data | Maximize value of data |
| Scope | Entire lifecycle | Point-in-time fitness |
| Failure mode | Corruption, tampering | Inaccuracy, staleness |
| Controls | RBAC, encryption, audits | Profiling, cleansing, dedup |
| Example | Unauthorized field edit | Outdated email address |
| Owner | IT / Security / DBA | Data stewards / ops teams |
Integrity is the foundation. If you skip it, every quality initiative you build on top is cosmetic - you can't meaningfully assess whether data is accurate if the underlying records have been corrupted or altered without authorization.
How Does Data Reliability Fit In?
A question that comes up almost as often: what is data reliability? Reliability refers to whether data consistently produces the same results over time and across repeated observations. A dataset can be high-quality at a single point in time but unreliable if it fluctuates unpredictably between refreshes or pipeline runs.
Think of it this way: quality asks "is this data good right now?" while reliability asks "can I trust this data to stay good tomorrow?" A CRM that shows accurate revenue figures on Monday but wildly different numbers on Tuesday - with no underlying business change - has a reliability problem. In practice, reliability depends on both integrity controls and quality practices working together. Teams that ignore reliability end up re-validating the same datasets before every analysis, which is a massive time sink that nobody budgets for.
Stale CRM data is the #1 quality failure in B2B. Prospeo's 7-day refresh cycle keeps 300M+ profiles current - not the 6-week industry average that causes 30% bounce rates. Every email passes 5-step verification including catch-all handling, spam-trap removal, and honeypot filtering.
Fix the data quality problem at the source - 98% accuracy, verified weekly.
Why This Feels Harder Now
A practitioner on r/SQL put it bluntly: cloud applications are "built with flexibility not data integrity in mind," producing "vomited JSON messes and massive non-normalized event tables" instead of pristine relational tables.
They're not wrong. The shift from monolithic databases to hundreds of SaaS apps connected by APIs has fundamentally changed how integrity works. When your data lived in one PostgreSQL instance with foreign key constraints, referential integrity was enforced by the database engine itself. Now your "database" is Salesforce + HubSpot + Stripe + a data warehouse stitched together with Fivetran, and nobody's enforcing constraints across those boundaries.
Semi-structured data makes it worse. JSON exports don't have schemas. Event tables don't have normalization. The traditional relational guardrails that kept integrity problems in check simply don't exist in modern data stacks. It's getting worse, not better - and most teams haven't updated their mental models to match.
Common Misdiagnosis Patterns
Here's the thing: most organizations don't have a data quality problem. They have a definitions and ownership problem. We've seen this pattern play out dozens of times, and it almost always starts the same way.
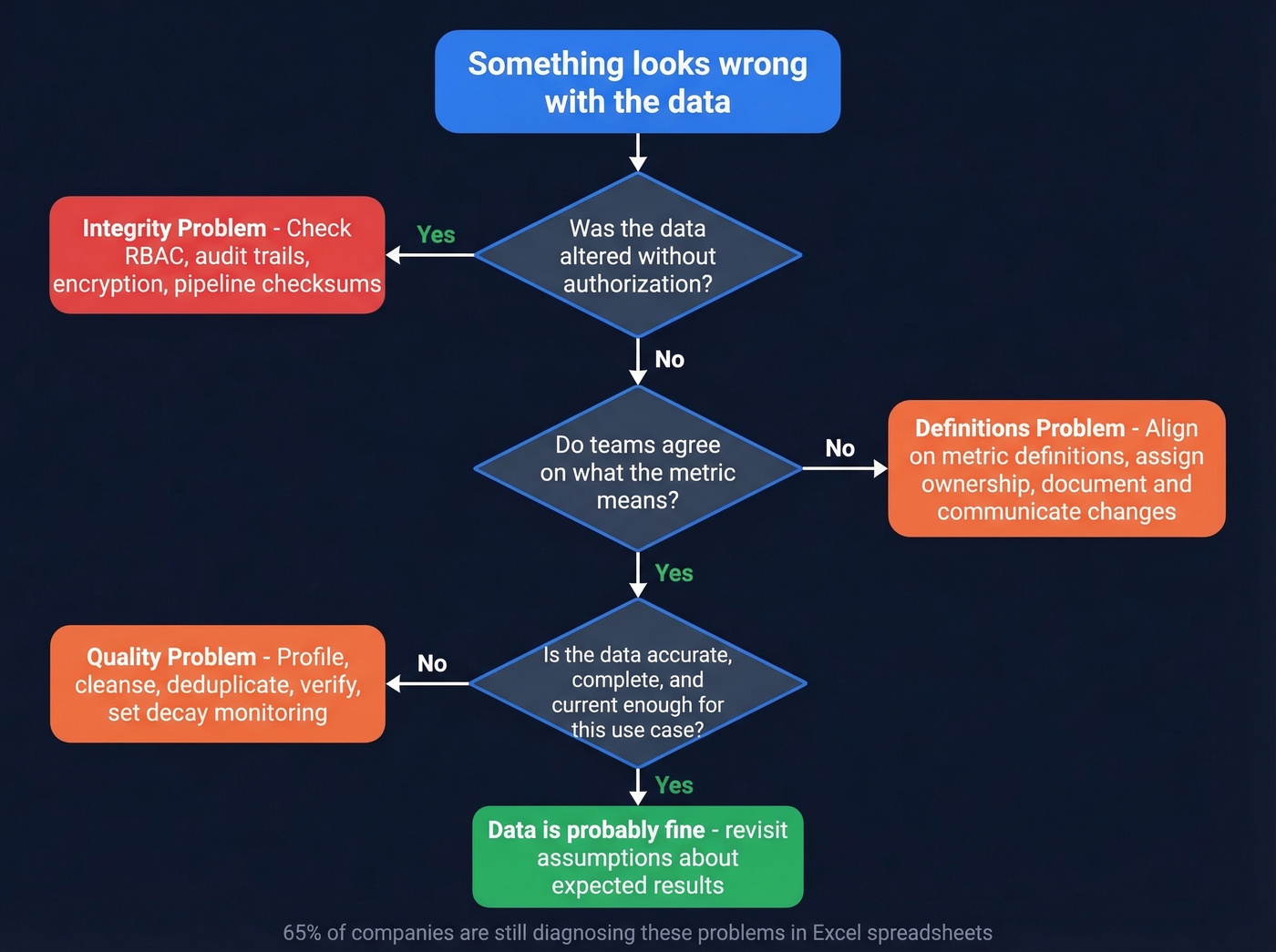
Consider this scenario from r/dataengineering: a senior manager sees a 50% drop in customer usage metrics in Looker and immediately assumes "something's broken in the ETL." The data engineering team spends two days investigating. Turns out the BI tool's metric definition had been changed - or the product itself had changed and the drop was real. The data was fine. The pipeline was fine. Nobody owned the definition of "customer usage" and nobody communicated when it changed. Two days of engineering time, burned.
The second pattern comes from r/analytics: teams declare "our data quality is terrible" when what's actually broken is that nobody knows what anything means, no one owns anything, and the organization never defined what "good enough" looks like. The data might be perfectly adequate - but without agreed definitions and ownership, every anomaly feels like a crisis. And 65% of companies are still trying to fix these problems in Excel spreadsheets.
Why AI Makes This Urgent
Every AI initiative runs on data. Right now, most of those initiatives are failing. 95% of generative AI pilots don't make it past experimentation. Only 16% of AI initiatives have scaled enterprise-wide. The top barrier? 45% of business leaders cite data accuracy and bias.

Gartner forecasts AI spending will surpass $2T in 2026 with 37% year-over-year growth - all of it dependent on data that's both intact and fit for purpose.
The numbers aren't coincidental. A 2026 ScienceDirect study tested all six data quality dimensions against 19 ML algorithms across classification, regression, and clustering tasks. Every dimension measurably impacted model performance. Garbage in, garbage out isn't a cliche - it's an empirical finding backed by controlled experiments.
Organizations that get this right have a structural advantage. 68% of AI-first organizations report mature data governance frameworks, compared to just 32% of everyone else. If you're planning to feed your CRM data into an AI model for lead scoring or forecasting, both integrity and quality need to be solved first. The model doesn't care which one you neglected.
How to Maintain Each
92% of executives worry inaccurate data undermines their ability to use it. In our experience, the teams that solve this fastest start with definitions, not tools.

Integrity Controls
Implement RBAC and MFA across every system that touches production data - MFA alone reduces account compromise by up to 99.9%. Use checksum validation to verify data hasn't been altered during transfers. Maintain audit trails so every change to a record is attributable to a person or process with timestamps. Encrypt data at rest and in transit. And test your recovery procedures quarterly, not annually - a backup you can't restore from isn't a backup.
Quality Practices
Profile before you fix. Run data profiling across your key tables before touching anything - completeness rates, format consistency, duplicate percentages. Then cleanse and deduplicate: standardize formats, merge duplicates, establish matching rules. Define canonical formats for names, addresses, phone numbers, and job titles, and enforce them at the point of entry.
Set monitoring thresholds for quality metrics and alert when they degrade. A 5% bounce rate that creeps to 15% over three months is a decay problem you should catch early. For B2B contact data specifically, tools like Prospeo verify emails in real-time and enrich records with 50+ data points, taking one more manual task off your ops team's plate.
B2B Data Quality in Practice
Contact data decay is the most tangible quality problem in B2B. People change jobs, companies rebrand, email domains switch. A list that was 95% accurate six months ago is probably 70% accurate today. That's not an integrity failure - nobody tampered with the data. It's a quality failure: the data is no longer fit for use.
Enterprise data governance platforms address this at scale, but they run $50K-$200K/year and take months to implement. For B2B contact data, the math is different. Prospeo maintains 300M+ professional profiles on a 7-day refresh cycle and verifies emails through a 5-step process including catch-all handling, spam-trap removal, and honeypot filtering - delivering 98% email accuracy with automatic duplicate removal across searches. That weekly refresh matters: the industry average is six weeks, and a lot of data can decay in six weeks.
If you're building lists for outbound, it helps to understand contact data decay mechanics and how verified email addresses are actually validated.
You can't solve data quality by re-validating the same stale records before every campaign. Prospeo's proprietary email infrastructure delivers 98% accuracy with 92% API match rates - so your team stops firefighting bounces and starts booking meetings.
Teams using Prospeo cut bounce rates from 35% to under 4%. Yours can too.
Tools Worth Knowing
Let's be honest: if you're starting from zero, Great Expectations plus your warehouse's built-in constraints will get you further than any $100K governance platform. We've seen organizations spend six figures on governance tools before agreeing on what "accurate" means. Don't be that team.
| Category | Tool | Open-Source? | Starting Price |
|---|---|---|---|
| Data Validation | Great Expectations | Yes | Free |
| Data Validation | Soda | Core: yes | ~$500-$2,500/mo (cloud) |
| Data Validation | Deequ | Yes | Free |
| Data Observability | Monte Carlo | No | ~$30K-$100K+/yr |
| Data Observability | Bigeye | No | ~$30K-$100K+/yr |
| Data Observability | Anomalo | No | ~$30K-$100K+/yr |
| Data Governance | Collibra | No | ~$50K-$250K+/yr |
| Data Governance | Atlan | No | ~$30K-$150K+/yr |
| Data Governance | Alation | No | ~$50K-$250K+/yr |
| Basic Quality Checks | dbt | Core: yes | ~$100-$1,000/mo (cloud) |
| B2B Data Quality | Prospeo | Free tier | ~$0.01/email |
Skip the observability platforms if your team is under 10 people - they're built for organizations with hundreds of data pipelines and dedicated data engineering staff. For smaller teams, data quality tools like dbt tests and Great Expectations cover 80% of what you need.
Every vendor will sell you a dashboard that scores your data 0-100. None will tell you the score is meaningless if your team hasn't agreed on what "accurate" means for your use case. Start with definitions and ownership. Then pick tools.
If you need to go deeper on remediation, data cleansing and data deduplication are usually the highest-ROI first steps.
FAQ
Is data integrity more important than data quality?
Integrity is foundational - without it, quality improvements are cosmetic. You need uncorrupted data before you can assess whether it's accurate, complete, or timely. Prioritize integrity controls first, then layer quality practices on top.
Can you have data integrity without data quality?
Yes. A database can be perfectly uncorrupted with a full audit trail and still contain outdated, incomplete, or inaccurate records. Integrity means the data wasn't tampered with - not that it's useful for your specific purpose.
What causes most data quality problems?
Organizational issues, not technical ones. Missing definitions, unclear ownership, and no agreed threshold for "good enough" account for more perceived quality failures than actual pipeline bugs. 60% of challenges trace to name and address variations alone.
How does poor data quality affect AI models?
Directly and measurably. A 2026 ScienceDirect study found all six quality dimensions impact ML performance across 19 algorithms. 95% of GenAI pilots fail to scale, and 45% of leaders blame data accuracy as the top barrier.
How do you keep B2B contact data accurate?
Automate verification and enrichment on a recurring cycle. CRM data decays fast - job changes, rebrands, domain switches. Weekly refresh cycles and multi-step verification prevent decay without manual effort, and real-time email verification catches bad addresses before they hit your outbound sequences.