Email A/B Testing Best Practices (the Stuff Your ESP Won't Tell You)
A single headline test at Bing produced a 12% revenue lift - worth over $100M per year in the US alone. Most email A/B testing advice you'll find online skips the hard parts: the metrics feeding your tests are broken, sample sizes are too small, and nobody's filtering out the bots. Only 10-30% of email split tests produce a clear winner, which makes test selection and sample size the whole game.
Quick version: Stop using open rate as your test metric. Test triggered emails and CTAs before newsletter subject lines. And if your list is under 2,000, skip testing entirely and fix your data quality first.
Your Metrics Are Lying to You
Open rate used to be the default A/B test metric. It's now the worst one.

Apple Mail Privacy Protection preloads tracking pixels via proxy servers, firing the pixel whether or not anyone actually reads your email. As of early 2025, MPP accounted for 49.29% of all email opens - a figure that's almost certainly higher now - inflating reported open rates by 15-20+ percentage points. A list that genuinely opens at 25% can show 40-45% in your dashboard. You're not measuring engagement. You're measuring Apple's proxy servers doing their job.
Then there's the bot problem. Security scanners from corporate email gateways click every link the instant it arrives. The telltale signs: clicks within one second of delivery, clicks on every single link including your footer, and click spikes that produce zero downstream conversions. In B2B environments, 5-30% of reported clicks are bots. AI bot clicks hit 3+ million per day in early 2025. A common question on r/Emailmarketing is whether A/B testing is even worth it when the data feels this unreliable.
It is worth it. You just need to measure the right things and filter the noise.
Best Practices for A/B Testing Emails
Start With a Hypothesis
Write a hypothesis before you touch your ESP: "If we change [variable], then [metric] will [direction] because [reason]." Prioritize tests using an ICE framework - Impact, Confidence, Ease - so you're not burning sends on low-value experiments.

"Let's try a different subject line and see what happens" isn't a test. That's a coin flip with extra steps.
Test One Variable at a Time
Changing the subject line, the CTA, and the send time simultaneously tells you nothing about which change drove the result. Isolate a single element so you can attribute any lift with confidence. True multivariate testing exists, but it requires far more traffic than most email programs can spare because you need enough observations to measure interaction effects between variables. For most programs, single-variable tests are the only honest option.
Measure Clicks and Conversions
Replace open rate with metrics that reflect intentional human behavior. Campaign CTR runs 1.7-2.1%, while triggered flows hit 5.58%. Revenue per recipient averages $0.11 for campaigns and $1.94 for flows. Click-to-conversion rate sits around 9%.
Those are the numbers your tests should move. HubSpot found that a personalized sender name lifted CTR by just +0.23% - small, but compounding across millions of sends, that's real money.
If you want to sanity-check your KPI math, start with the CTR you’re optimizing for.
Test Triggered Emails First
65%+ of brands never A/B test their transactional or triggered emails. That's backwards.

Welcome sequences and cart abandonment emails have the highest engagement rates in your entire program - flows generate nearly 18x the revenue per recipient of campaigns. We've consistently seen the biggest wins come from emails teams never think to test: welcome sequences, post-purchase flows, and onboarding drips. Test your welcome email CTA before you test your newsletter subject line.
Here's our hot take: if your average deal size is under $10K and your list is under 5,000, you'll get more revenue from rewriting one welcome email than from a year of newsletter subject line tests. Stop optimizing the wrong thing.
Know Your Sample Size
Here's the thing: if your list is under 2,000, most A/B tests are theater. A 1 percentage point lift on a 2% baseline is a 50% relative improvement - that's a big effect to detect, and it still requires around 15,000 total recipients. Check the sample size table below before you launch. The core principle: test on the smallest segment that still reaches significance, then send the winner to the remainder.
If you’re doing this in outbound, your email velocity can become the real constraint.
Wait Before Declaring a Winner
Don't peek at results after four hours. Early peeking inflates false positives because you're running multiple significance tests on accumulating data.
Litmus recommends waiting 48-72 hours before calling a result. Mailchimp's analysis of almost 500,000 A/B tests found that open-based tests can often predict the eventual winner in a few hours, while click- and revenue-based outcomes generally need more time to settle. Give your full audience time to engage across time zones, and avoid testing during holidays or major news events - behavior during those periods won't replicate.
Filter Bots Before Analyzing
Before you analyze any result, clean the data:
- Time-to-click filtering: Flag any click under 1 second as a bot
- Honeypot links: Add an invisible link; any "click" on it is automated
- User agent filtering: Block known scanner signatures
- ESP bot-filtering features: Major ESPs began filtering known bot clicks by late 2025 - turn this on
If you're running B2B email and you haven't enabled bot filtering, your click data is probably 10-20% noise. That's enough to flip a test result entirely.
Validate With an A/A Test
Before investing in real tests, run an A/A test - send the identical email to both groups. If you see a "winner," your measurement setup has a problem. This catches deliverability skew between sending IPs, broken tracking, and random noise masquerading as signal. One A/A test can save you months of acting on bad data.
If you suspect deliverability is skewing results, start with an email deliverability audit before you run more experiments.
Your A/B test results are only as good as the data underneath them. If emails bounce, land in spam traps, or hit honeypot addresses, your metrics are corrupted before the test even starts. Prospeo's 5-step verification delivers 98% email accuracy - so every split test measures real human behavior, not delivery failures.
Stop A/B testing on dirty data. Start with emails that actually arrive.
Sample Size Quick Reference
All figures assume 95% confidence and 80% power. "Per variant" means each version needs this many recipients - double it for total test size.
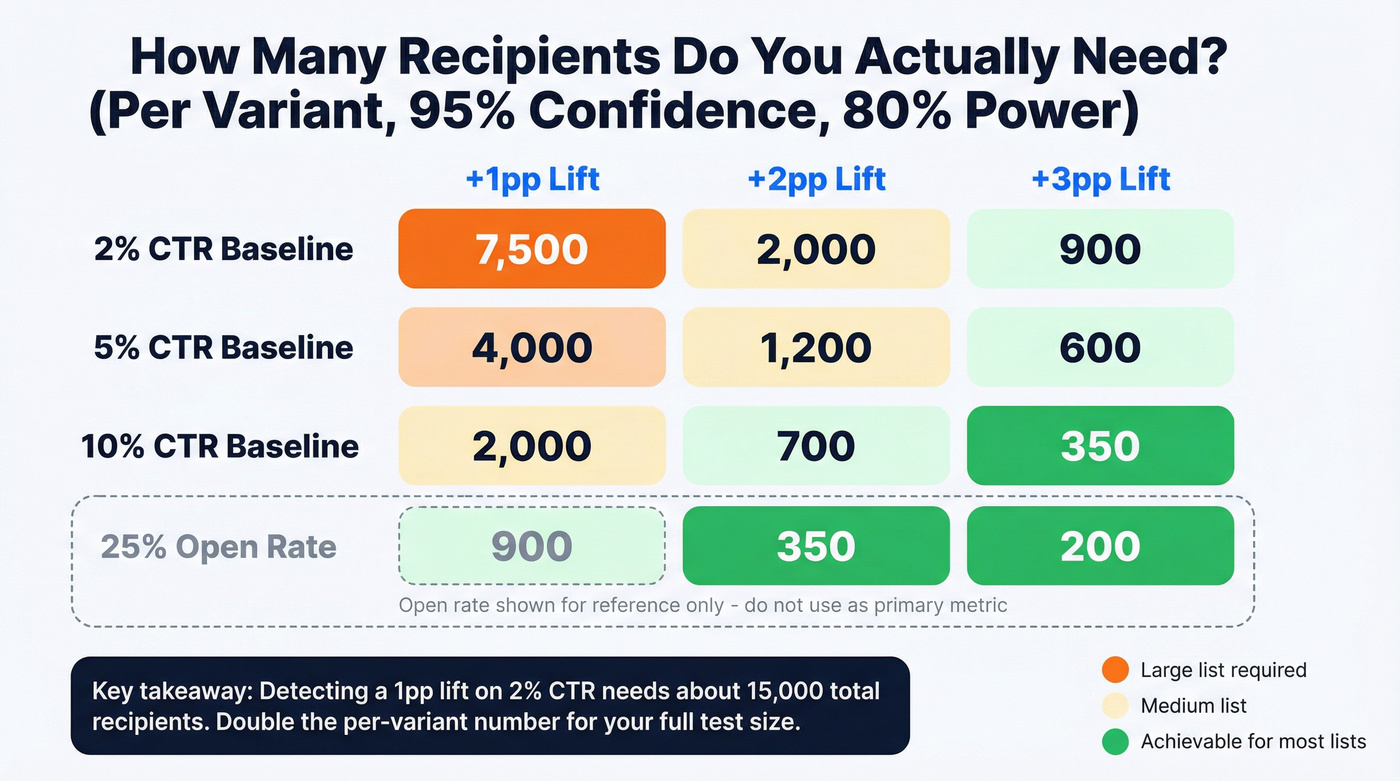
| Baseline Rate | +1pp Lift | +2pp Lift | +3pp Lift |
|---|---|---|---|
| 2% CTR | ~7,500/var | ~2,000/var | ~900/var |
| 5% CTR | ~4,000/var | ~1,200/var | ~600/var |
| 10% CTR | ~2,000/var | ~700/var | ~350/var |
| 25% open* | ~900/var | ~350/var | ~200/var |
*Open rate included for reference only - don't use it as your primary metric.
The takeaway: detecting a 1 percentage point lift on a 2% CTR baseline requires around 15,000 total recipients. If you don't have that volume, aim for bigger changes or pick higher-engagement emails to test.
When NOT to A/B Test
Skip it when your list is under 2,000, you send less than twice a month, the email is low-stakes, or your list hygiene is questionable.

That last point matters more than most teams realize. If 8% of your list bounces, your "winning" variant might just be the one that hit more valid inboxes. Also check authentication - if SPF, DKIM, or DMARC aren't aligned, variants can land in different inbox placements, and your test is measuring deliverability, not content. We've seen teams spend weeks debating subject line results when the real problem was a 12% bounce rate poisoning both variants equally.
Verify your list with a tool like Prospeo before investing time in test design. At 98% email accuracy with real-time verification, you're at least starting from clean data. Your time is better spent on list quality than on running tests that can't produce reliable results.
If you’re seeing persistent bounces, use an email bounce rate checklist to isolate the cause.
You just read that lists under 2,000 make most A/B tests statistical theater. The fix isn't skipping tests - it's building a bigger, cleaner list fast. Prospeo gives you 300M+ verified profiles with 30+ filters so you can scale your test audience without sacrificing data quality. At $0.01 per email, scaling your sample size costs less than one bad test decision.
Hit real sample sizes with real contact data for a penny per lead.
Document Everything
We've seen teams run the same subject line test three quarters in a row because nobody wrote down the first result. Build a simple test log: date, hypothesis, variable tested, primary metric, sample size, result with confidence level, and action taken. Each test builds on the last - but only if you can reference what you've already tried.
One more thing: AI-assisted variant generation is getting good enough to use as a brainstorming tool for test hypotheses. But the fundamentals - clean data, proper sample sizes, honest metrics - still matter more than any AI feature your ESP is selling you. Follow these email A/B testing best practices consistently, and you'll outperform teams with ten times your send volume.
If you need ideas for what to test next, pull from proven email subject line examples (then measure clicks, not opens).
FAQ
How long should an email A/B test run?
At least 48-72 hours. Click data stabilizes faster than opens, but your full audience needs time to engage across time zones. Peeking early inflates false positives - wait for the full window before declaring a winner.
Can I A/B test with a small email list?
Below ~2,000 subscribers, most tests won't reach statistical significance. Focus on list growth and data quality first, then start with high-engagement triggered emails where smaller samples can still produce meaningful results.
What should you A/B test first?
Start with CTAs in triggered emails - welcome sequences and cart abandonment flows. They have the highest engagement rates and produce the cleanest signal. Subject line tests require much larger samples (7,500+ per variant at a 2% CTR baseline), so save those until your list supports the volume.
What are the most common A/B test mistakes?
Testing multiple variables at once, relying on open rate as the primary metric, and declaring winners before reaching statistical significance. Nail the fundamentals - clean data, sufficient sample sizes, a single isolated variable - and you'll outperform most programs without any clever tricks.