Pipeline Data Quality: From Vague Complaints to Measurable SLOs
Your ML team just told you model accuracy dropped 12% overnight - and pipeline data quality is the first suspect. The dashboard everyone trusts is showing revenue numbers that don't match finance. The Slack channel is filling up with "is this data right?" messages nobody can answer.
Poor data quality costs organizations an average of $12.9M per year, per Gartner. Over a quarter of organizations lose more than $5M annually from bad data alone. The problem isn't that teams don't care. It's that they don't measure it.
What You Need (Quick Version)
Before you touch any tooling, set three SLOs:
- 99.5% pipeline uptime - that's a 3.6-hour monthly error budget, not zero
- Data refreshed by 9 AM daily (measure your baseline first)
- Accuracy within 0.1% of source systems
Start with dbt tests if you're already in dbt. Add Soda Core or Great Expectations for ingestion-layer validation. Don't buy an observability platform just because it exists - a spreadsheet tracking your SLOs is enough early on.
Setting Data Quality SLOs for Your Pipeline
Every guide tells you to "implement data quality checks." None tell you what thresholds to set. "Check for nulls" isn't a strategy. "99.5% completeness with a 3.6-hour monthly error budget" is a strategy.
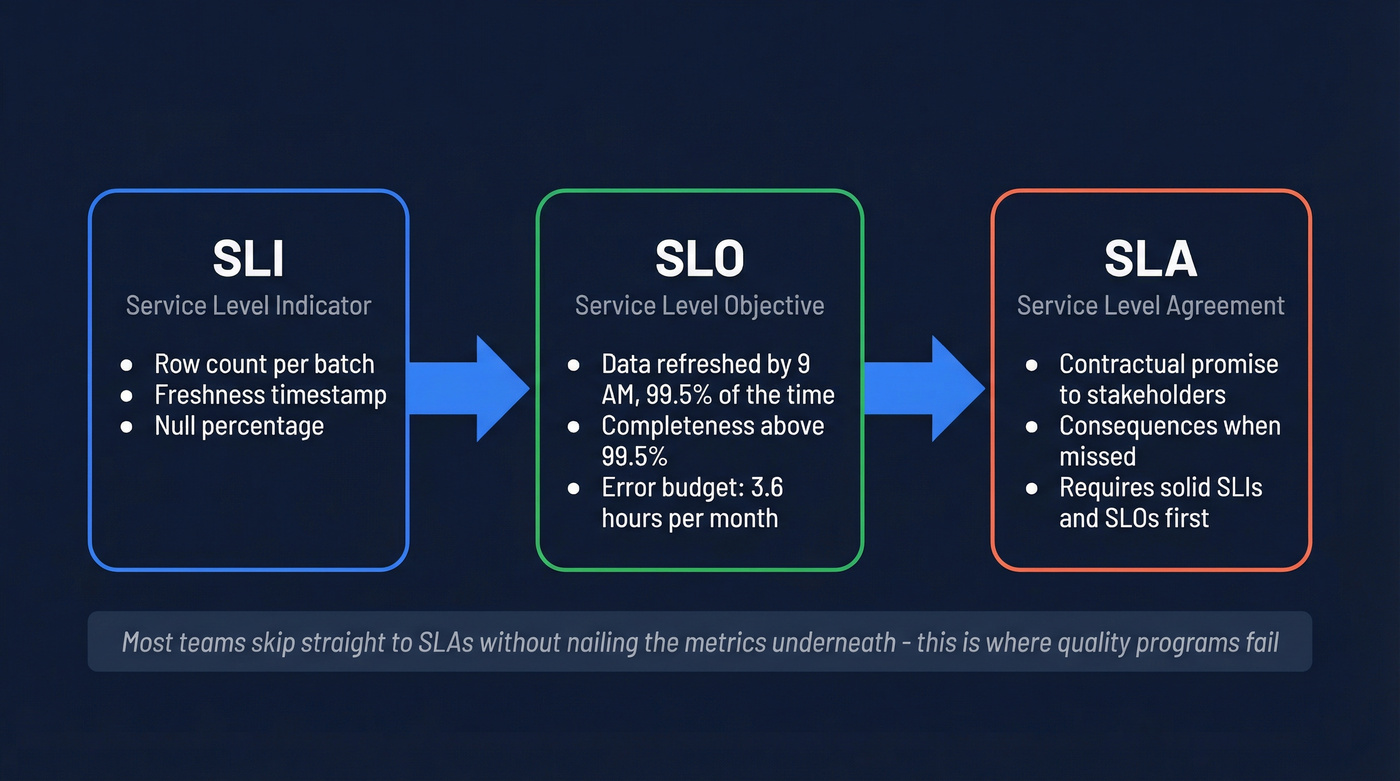
An SLI (Service Level Indicator) is the raw metric - row count, freshness timestamp, null percentage. An SLO (Service Level Objective) is the target: "data refreshed by 9 AM, 99.5% of the time." An SLA (Service Level Agreement) is the contractual promise to stakeholders, with consequences when you miss it. Teams that jump to stakeholder promises without nailing the underlying metrics usually end up arguing about definitions instead of fixing anything.
The error budget math matters more than most teams realize. A 99.5% uptime SLO gives you 3.6 hours of downtime per month. That's tight, but it's not zero - and that distinction changes how you alert. Borrow burn-rate alerting from SRE: fire a page if you're burning at 14x rate over 5 minutes, or at 2x rate over an hour. This kills the 2 AM false-positive pages that make on-call engineers quit.
45% of business leaders cite data accuracy concerns as the leading barrier to scaling AI. Without quantitative SLOs, "data quality" is just hand-waving that blocks every initiative.
Where to Place Checks
Checks belong at four stages, and the order matters:
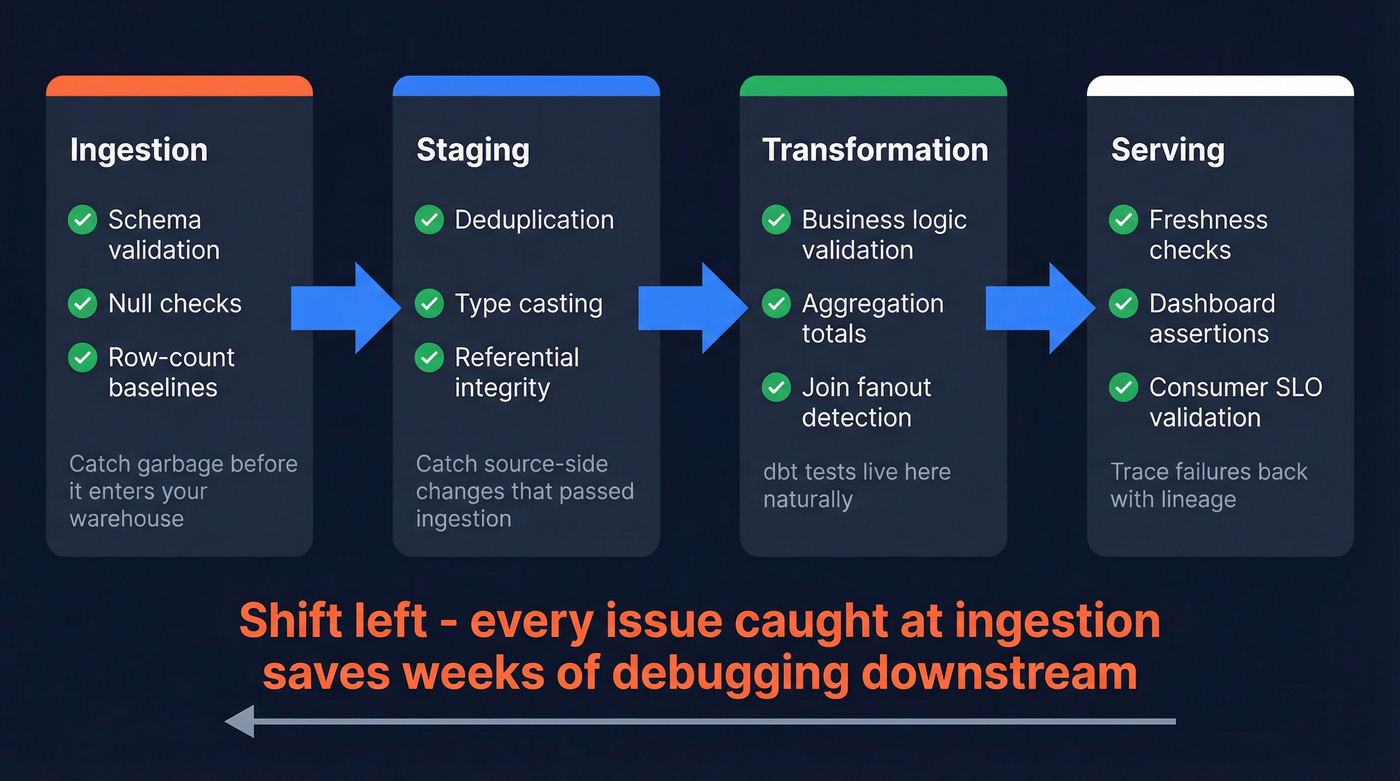
- Ingestion: Schema validation, null checks, row-count baselines. Catch garbage before it enters your warehouse. For streaming pipelines on Kafka or Flink, a schema registry plus dead-letter queues is a common foundation - you'll still layer on volume, freshness, and anomaly checks that make sense for streaming.
- Staging: Deduplication, type casting, referential integrity. This is where you catch source-side changes that passed ingestion. Data contracts between producers and consumers formalize these expectations.
- Transformation: Business logic validation - margin calculations, aggregation totals, join fanout detection. dbt tests live here naturally. Revenue data accuracy depends heavily on getting these calculations right, since even small rounding errors compound across millions of rows.
- Serving: Final freshness checks, dashboard-level assertions, consumer SLO validation. Data lineage helps you trace failures back to their origin when something breaks at this layer.
A minimal dbt test for the transformation layer:
# models/staging/schema.yml
models:
- name: stg_orders
columns:
- name: order_id
tests: [unique, not_null]
- name: revenue_cents
tests:
- dbt_utils.accepted_range:
min_value: 0
max_value: 10000000
Shift left. Every issue you catch at ingestion is one that doesn't propagate through four transformation layers and surface as a wrong number in a board deck.
You're building SLOs to catch bad data downstream. What if the data was accurate at the source? Prospeo's 5-step verification and 7-day refresh cycle means 98% email accuracy - so your pipeline ingests clean records from day one.
Stop debugging dirty data. Start with records you can trust.
Anti-Patterns That Tank Quality
Silent record dropping. Your pipeline filters out "invalid" rows and nobody notices. We've seen a team trace a ~10% revenue drop in reporting back to a single WHERE clause that silently discarded records with unexpected formats. The fix: route bad records to an error table and alert. Never silently filter.

Hard-coded thresholds. You set a row-count check at 10,000 minimum. Saturday volume naturally drops to 8,000. Your on-call gets paged at 2 AM every weekend. This kind of alert fatigue - alongside checks placed too late and unclear ownership - is one of the fastest ways to kill a quality program. The fix: compare against historical baselines for the same day-of-week, not absolute numbers.
Semantic changes passing validation. A source system renames a status enum or switches units. Every schema check passes. Every null check passes. Your downstream logic quietly breaks. The fix: distribution monitoring with day-over-day change alerts - flag anything where the average shifts more than 50%.
Here's the thing: each of these costs weeks of debugging and real revenue. All preventable with the right checks at the right layer.
Choosing the Right Framework
| Tool | Best For | Strengths | Weakness | Pricing |
|---|---|---|---|---|
| dbt | Already in dbt | Built-in, warehouse-native | Transform layer only | Core free; Cloud plans vary |
| Soda Core | SQL-first teams | Simple syntax, fast setup | SQL-style checks only | Core free; Cloud paid |
| Great Expectations | Python-heavy teams | Expressive, CI-friendly | Config overhead | OSS free; GX Cloud: contact vendor |
| Deequ | Spark-scale jobs | Massive dataset scale | Requires Spark infra | Free (Apache 2.0) |

If you're already running dbt, add dbt tests first - they're built in and warehouse-native. Need fast ingestion-layer checks? Soda Core gets you running in an afternoon. Great Expectations wins when you need complex Python-based validation or tight CI/CD integration. Skip Deequ unless you're actually running Spark at scale - it's overkill otherwise.
In our experience, most teams start with dbt tests and later add Soda Core. That combination covers the majority of use cases without buying anything.
The Shift to Observability
By 2026, 50% of enterprises with distributed data architectures will have adopted data observability tools - up from under 20% in 2024. The category splits into metadata-level monitoring (freshness, volume, schema drift) and deep content analysis that inspects actual values and distributions to find unknown unknowns. The next wave is AI-native profiling that replaces manual thresholds with learned baselines and self-healing pipelines with automated retries, but the tooling is early and the ROI is unproven for most teams.
Let's be honest: you don't need an observability platform just to feel "mature." Many teams run a long way on dbt tests plus Airflow alerts plus a spreadsheet tracking three SLOs. Meanwhile, 30% of GenAI projects get abandoned after proof-of-concept due to data quality issues. The problem isn't missing tooling - it's missing thresholds.
Where Pipeline Quality Meets Revenue
The same principles apply when your pipeline outputs feed sales and marketing systems. Bad email addresses in your CRM are a data quality failure with direct revenue impact - bounced sequences burn sender reputation, waste rep time, and tank deliverability for every campaign that follows. When contact data accuracy degrades, reps spend more time cleaning records than closing deals.
Prospeo applies the same verification-first approach to contact data, with a 98% email accuracy rate and a 7-day refresh cycle that maps cleanly to the freshness and accuracy SLO thinking you'd use for any pipeline output. Your pipeline outputs are only as good as the verification at the end.
Silent record drops and semantic drift cost weeks of debugging. Prospeo eliminates the biggest input-layer risk: bad contact data. 143M+ verified emails, 92% API match rate, and catch-all handling built in - no extra validation layer needed.
Fix pipeline quality at the source for $0.01 per verified email.
FAQ
What are the six data quality dimensions?
Accuracy, completeness, consistency, freshness, uniqueness, and validity. These form the measurement vocabulary for any pipeline quality program. Map each to an SLI before setting targets - you can't improve what you haven't defined.
When should I add quality checks to my pipeline?
At every stage - ingestion, staging, transformation, and serving. Shift left: catch issues at ingestion before they propagate through four layers and surface as wrong numbers in dashboards or downstream models.
What's a good starting SLO for data freshness?
"Data refreshed by 9 AM daily" is a solid first target. Measure your actual baseline for 30 days before committing. If your pipeline already hits 8:30 AM consistently, a 9 AM SLO gives you a reasonable error budget without being aspirational fiction.
Do I need a data observability platform?
Not until you've defined what "good" means. dbt tests plus Airflow alerts plus a spreadsheet tracking three SLOs is enough for most teams. Vendors would rather sell you a $50-150k/year platform before you've established measurable thresholds.
How do I verify contact data quality before it hits the CRM?
Add a verification gate before data enters the CRM. Route unverified or invalid contacts to a quarantine table, just like you would with any other bad records. Tools like Prospeo's enrichment API handle this with a 92% match rate and a 7-day refresh cycle - treat it like any other pipeline quality check.
