Data Intelligence: What It Actually Means (and What to Do About It)
Your CEO just came back from a conference and dropped "we need a data intelligence strategy" into the Monday standup. Nobody in the room knows exactly what that means, but everyone nodded. Now it's your problem to figure out whether data intelligence is a real discipline with real tools - or another enterprise buzzword that'll burn six figures before anyone admits it didn't work.
The honest answer, as one practitioner on r/analytics put it, is that it "sounds sexy" and might be "bullshit." The truth is somewhere in between. Let's sort it out.
What data intelligence means in practice
Data intelligence is the set of practices (and, sometimes, platforms) that help you understand your data well enough to trust it: where it came from, how it changed, who owns it, who uses it, how fresh it is, and whether it's fit for the decision you're about to make.
That sounds abstract until you see the failure mode: a dashboard number is off, a model drifts, or a GenAI app starts confidently answering with stale policy docs from last quarter. Everyone argues about the output. Data intelligence forces the conversation back to inputs, ownership, and traceability.
Oracle describes data intelligence as both the intelligence you get from analyzing data and the intelligence you have about the data itself (origin, ownership, trust, storage, and sharing): https://www.oracle.com/artificial-intelligence/data-intelligence/
IBM frames it as the intersection of data management, metadata management, and AI/ML - answering "what data do we have, where is it, who uses it, and how is it related?": https://www.ibm.com/think/topics/data-intelligence
In our experience, the second definition ("intelligence about the data") is the one that actually changes outcomes. The first definition is just analytics with a new label.
Data intelligence vs. BI vs. analytics
BI tells you what happened. Analytics tells you why it happened and what might happen next.
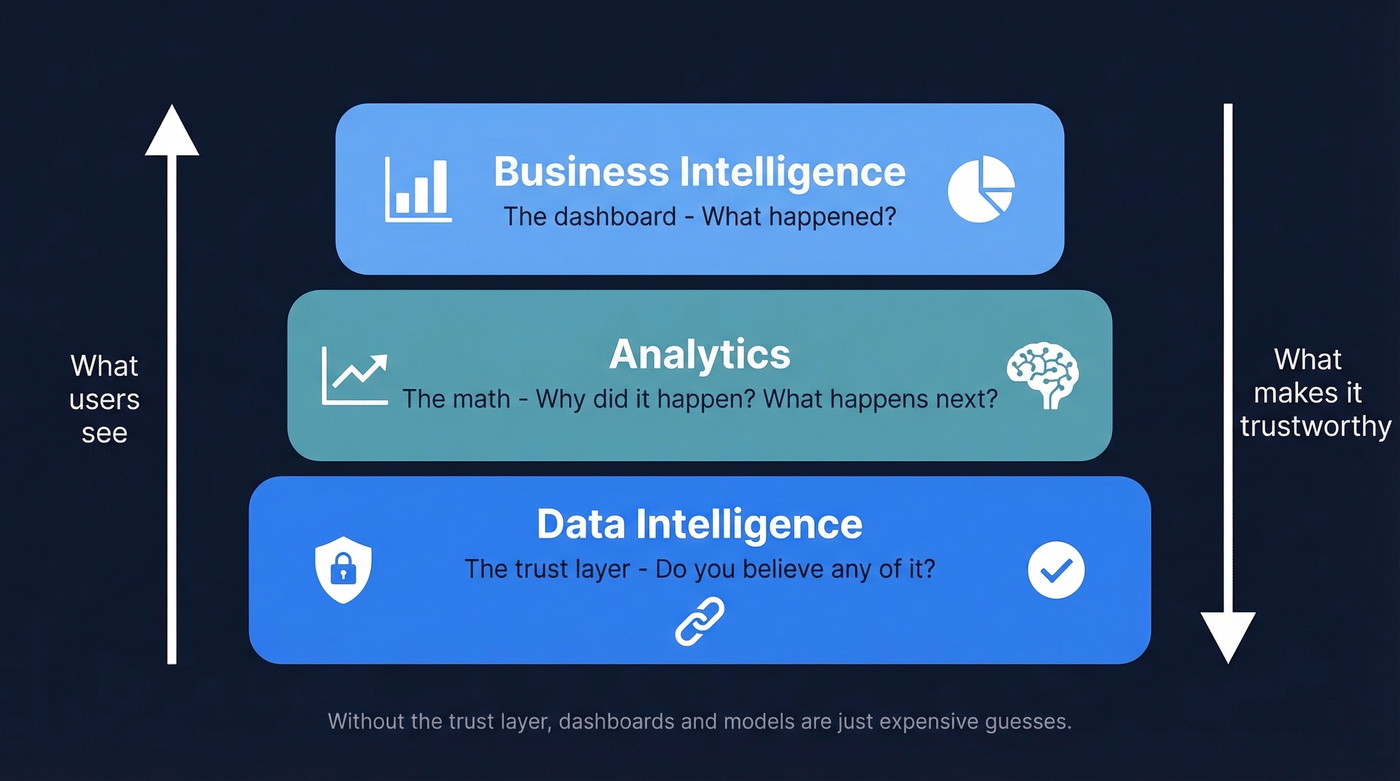
Data intelligence tells you whether you should believe any of it.
If you want a simple mental model: BI is the dashboard, analytics is the math, and data intelligence is the trust layer underneath both.
Why it matters in 2026 (AI made the cracks impossible to ignore)
Enterprise AI budgets are rising fast while the data underneath stays messy. The result is predictable: teams ship impressive demos, then spend months explaining why the system can't be trusted in production.
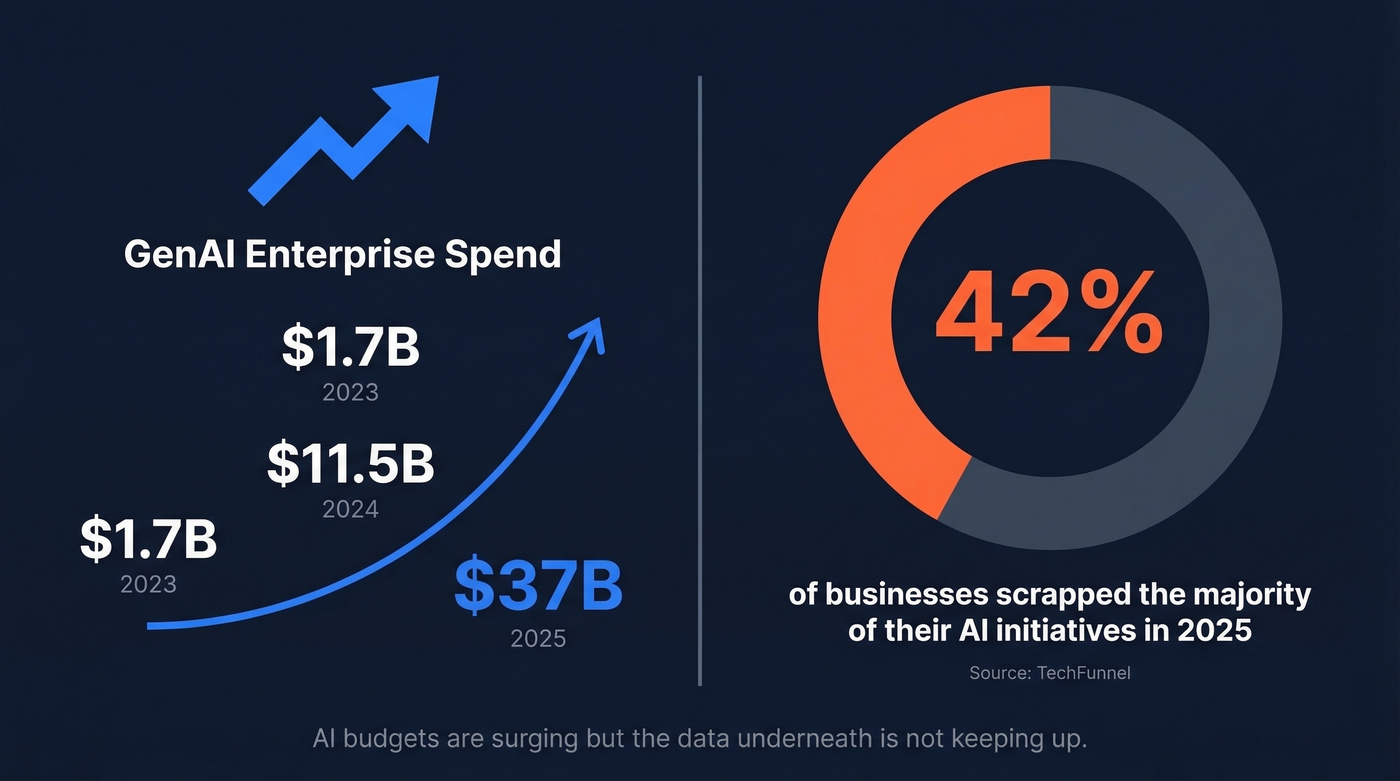
GenAI spend surged from $1.7B in 2023 to $11.5B in 2024 to $37B in 2025: https://menlovc.com/perspective/2025-the-state-of-generative-ai-in-the-enterprise/
And a big chunk of AI work still gets abandoned. TechFunnel reported that 42% of businesses scrapped the majority of their AI initiatives in 2025: https://www.techfunnel.com/information-technology/why-ai-fails-2025-lessons/
CDOs have been blunt about what's missing. Informatica's CDO Insights Survey lists "reliable and consistent data fit for generative AI" and governance as top priorities: https://www.informatica.com/resources/articles/cdo-insights.html
Here's the frustrating part: none of that is new. What's new is that GenAI (especially RAG) turns "slightly wrong" data into "confidently wrong" answers at scale. That forces a higher bar for freshness, lineage, access controls, and quality checks.
The five pillars (what DI platforms actually do)
Most "data intelligence platforms" are a bundle of capabilities that used to live in separate tools. The exact packaging varies, but the pillars don't.
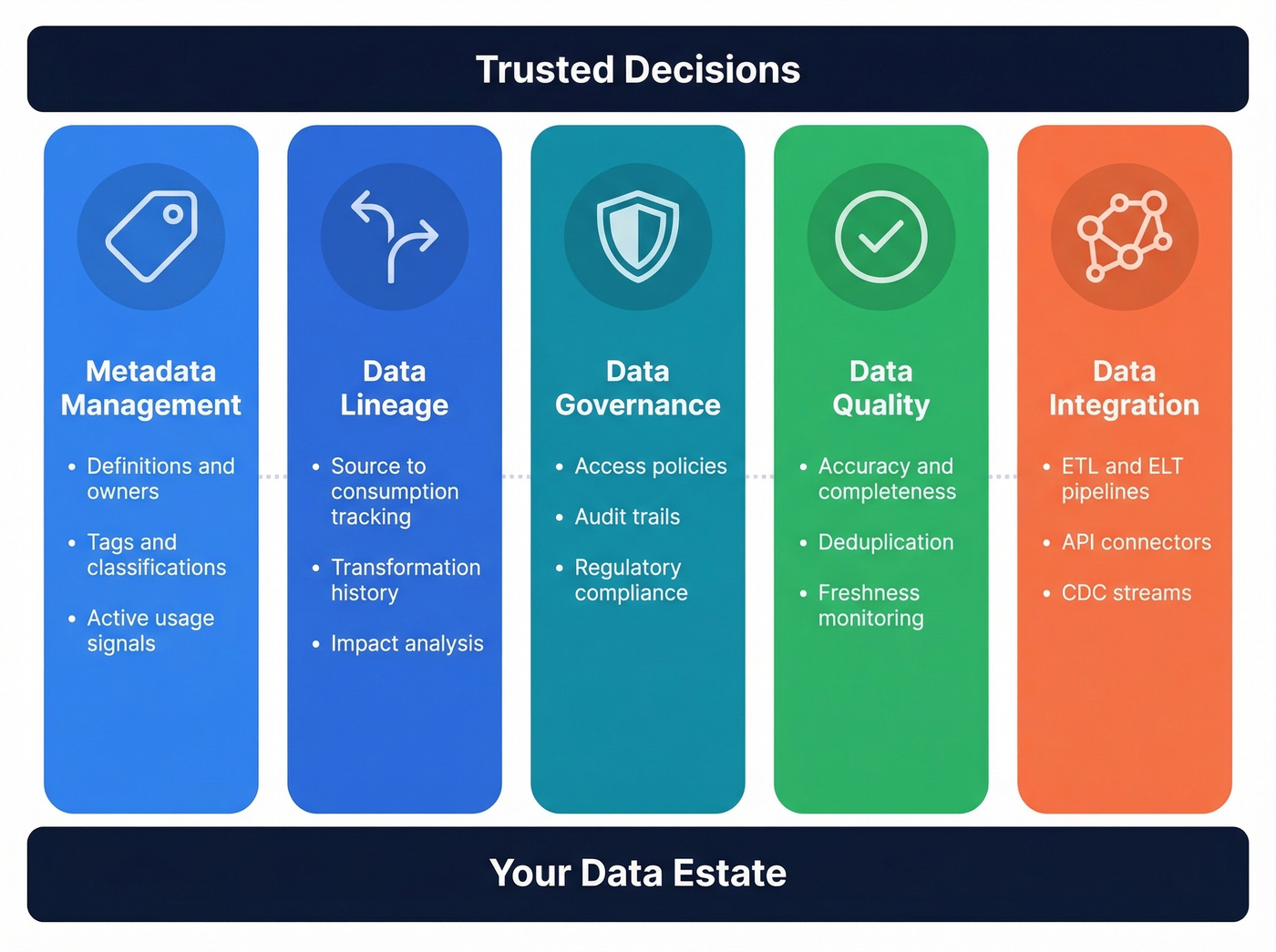
1) Metadata management
Metadata is the context around data: definitions, owners, tags, classifications, and how datasets relate.
The useful shift in the last few years is active metadata: usage signals like query logs, access frequency, and which datasets people actually rely on. A catalog that knows "this table is popular and trusted" is more valuable than a catalog that just knows "this table exists."
2) Data lineage
Lineage tracks data from source to consumption: every transformation, join, and aggregation along the way.
When a metric breaks, lineage tells you where to look. Without it, debugging turns into archaeology: Slack threads, tribal knowledge, and someone saying "I think that field comes from the old pipeline, not the new one."
3) Data governance
Governance is the policy layer: who can access what, under what conditions, with what audit trail.
In regulated environments, governance isn't a "nice to have." It's how you survive audits and avoid accidental exposure. In normal environments, it's how you stop sensitive fields from showing up in places they shouldn't, and how you make sure the right people can still do their jobs without filing tickets for everything.
4) Data quality
Data quality is accuracy, completeness, deduplication, consistency, and freshness.
This is where most teams should start because everything downstream depends on it. And yes, it's boring. It's also the part that saves you from building expensive systems on top of garbage.
For B2B teams, data quality often starts with contact data. If 15% of your emails bounce, your outbound performance, attribution reporting, and pipeline forecasting all get distorted. Prospeo is built for this layer: 300M+ professional profiles, 143M+ verified emails, 125M+ verified mobile numbers, and 98% email accuracy with a 7-day refresh cycle. If you're evaluating providers, start with the B2B database and verified emails basics.
5) Data integration
Integration is the plumbing: ETL/ELT pipelines, connectors, APIs, and CDC streams that move data where it needs to go.
A DI platform without integration is a catalog of things you can see but can't reliably use. In practice, integration means your CRM, product analytics, billing, and support data land in the same warehouse on a predictable schedule, with consistent definitions and ownership. If you're trying to reduce manual work, CRM automation is often the fastest win.
Data intelligence for GenAI and RAG (where it breaks first)
Every enterprise AI conversation in 2026 ends up at RAG - retrieval-augmented generation. And every RAG pipeline depends on DI capabilities, whether you call them that or not.
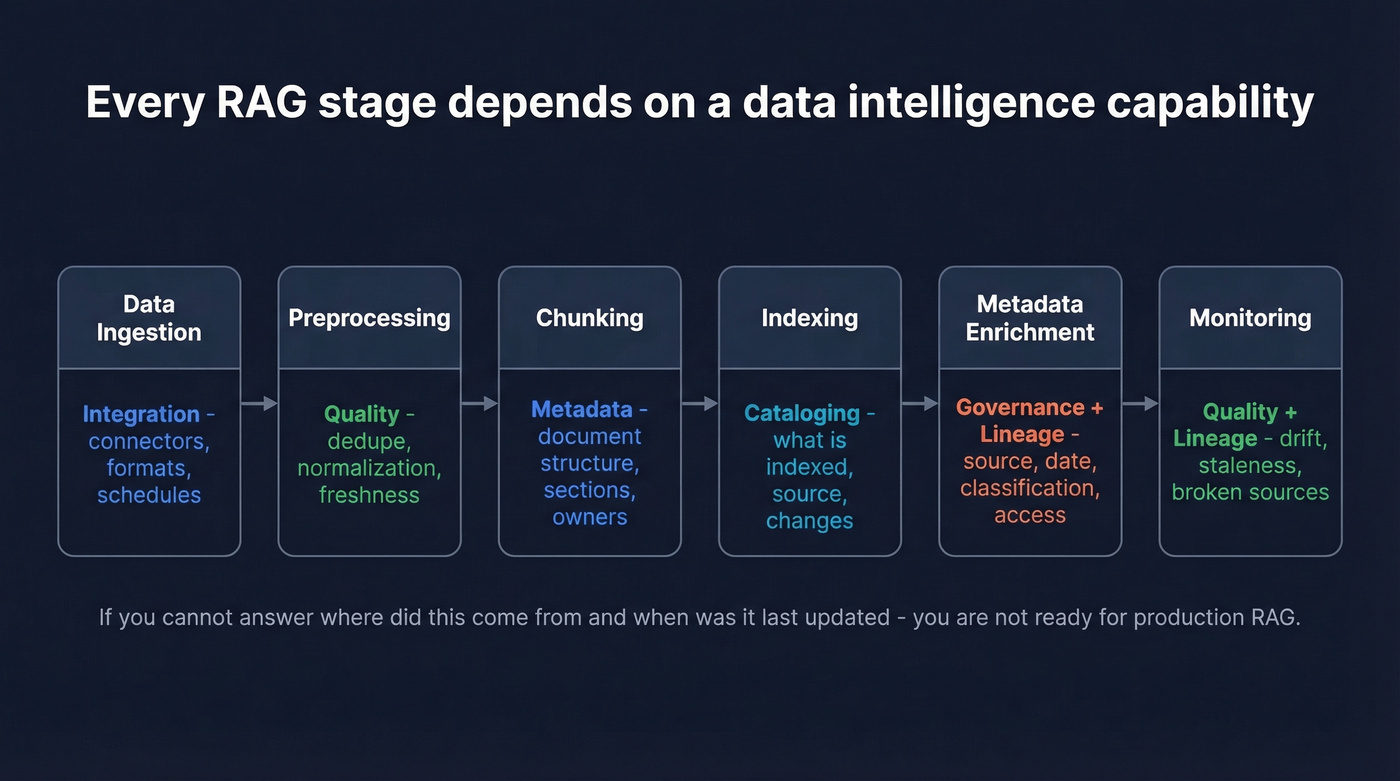
A typical RAG flow maps cleanly:
- Data ingestion -> integration (connectors, formats, schedules)
- Preprocessing -> quality (dedupe, normalization, freshness checks)
- Chunking -> metadata (document structure, sections, owners)
- Indexing -> cataloging (what's indexed, where it came from, what changed)
- Metadata enrichment -> governance + lineage (source, date, classification, access controls)
- Monitoring -> quality + lineage (drift, staleness, broken sources)
GraphRAG is the next step for complex, multi-source questions because it captures relationships between entities, not just similarity between chunks. It can be excellent. It's also unforgiving.
If your org can't answer "where did this come from?" and "when was it last updated?" for core datasets, you're not ready for RAG in production. You'll ship something that looks smart and behaves like a liability.
You just read that data quality is where most teams should start - because everything downstream depends on it. Prospeo delivers 98% email accuracy across 300M+ profiles with a 7-day refresh cycle, while the industry average sits at 6 weeks. If your data intelligence strategy starts at the contact layer, start with data you can actually trust.
Fix your foundation before you build the trust layer on top.
A maturity model that doesn't lie to you
Most orgs are at stage 1 or 2 and don't realize it. We've seen teams sign a ~$150k catalog contract while governance still lives in a spreadsheet and "ownership" means "ask Dave." That's stage 1 behavior with stage 4 tooling, and it usually ends with a quiet renewal cancellation a year later.
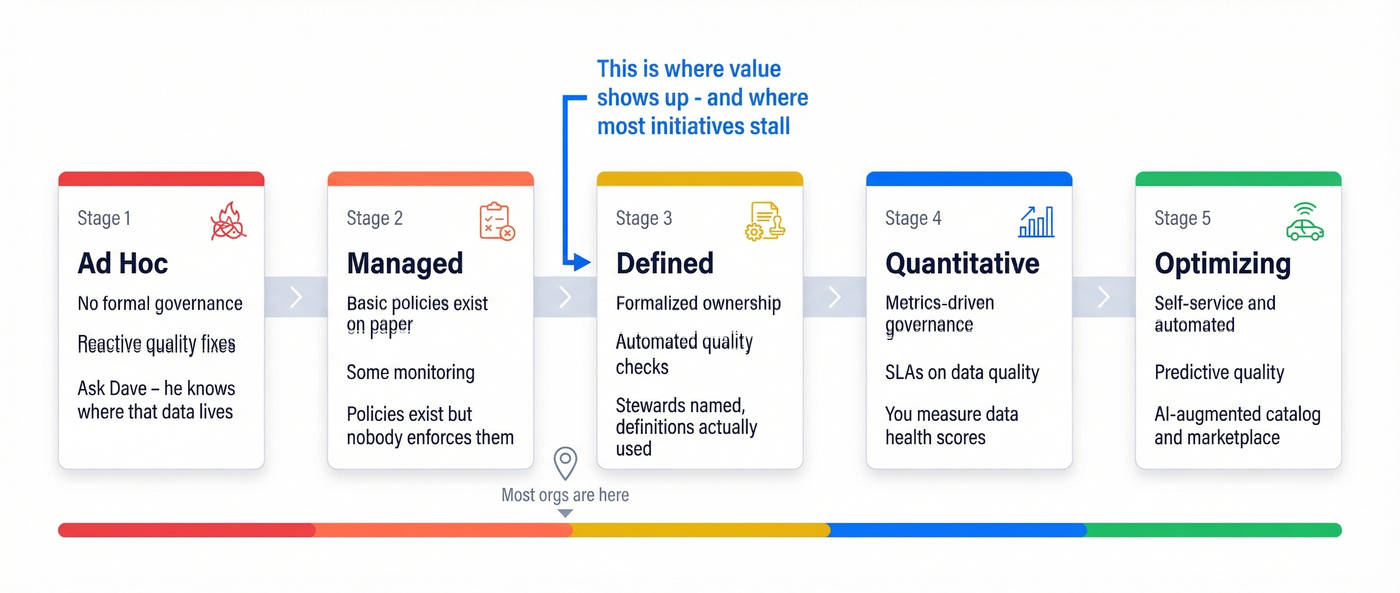
| Stage | Name | Governance | Quality | Typical tooling | Signal you're here |
|---|---|---|---|---|---|
| 1 | Ad hoc | None formal | Reactive fixes | Spreadsheets, tribal knowledge | "Ask Dave, he knows where that data lives" |
| 2 | Managed | Basic policies exist | Some monitoring | BI tools, docs | Policies exist but aren't enforced |
| 3 | Defined | Formalized, assigned owners | Automated checks | Catalog + glossary | Stewards named, definitions used |
| 4 | Quantitative | Metrics-driven | SLAs on data quality | Full DI platform | You measure data health scores |
| 5 | Optimizing | Self-service, automated | Predictive quality | AI-augmented catalog | Marketplace + automated lineage |
This is adapted from Actian's maturity framing: https://www.actian.com/blog/data-governance/data-maturity-model/
The jump from stage 2 to stage 3 is where value shows up. It's also where initiatives stall, because it requires behavior change: naming owners, enforcing definitions, and making "data stewardship" a real job, not a side quest.
One more blunt point: don't skip stages. Buying enterprise governance software doesn't magically create governance.
What a DI stack costs (and how long it takes)
Pricing is messy because most enterprise vendors sell custom packages. Still, the ranges below are realistic enough for planning and for sanity-checking a proposal.
| Tool | Category | Price range | Typical deploy time |
|---|---|---|---|
| Collibra | Enterprise governance | $100k+/yr | 3-9 months |
| Alation | Catalog + behavioral metadata | $75k-$200k+/yr | 6-12 weeks |
| Atlan | Modern data catalog | $30k-$100k/yr | 4-6 weeks |
| Informatica IDMC | Integration + governance | $100k-$300k/yr | 3-9 months |
| Databricks Unity Catalog | Lakehouse-native catalog | Included with Databricks spend | Varies |
| Secoda | Lightweight catalog | Starts around $500/mo | 1-2 weeks |
| OvalEdge | Mid-market catalog | $25k-$100k/yr | 4-8 weeks |
| DataHub | Open-source catalog | Free (self-hosted) | Engineering-dependent |
| OpenMetadata | Open-source catalog | Free (self-hosted) | Engineering-dependent |
Enterprise platforms (where the category is most mature)
Alation is strong on behavioral metadata: it learns from how people use data (query patterns, popularity, access frequency) and surfaces that back to users. If adoption and "what do people actually trust?" are your biggest problems, Alation tends to perform well. One published case study describes scaling from 200 to 4,000+ users and saving 414,000 hours over six years.
Collibra is the compliance-first choice. If your driver is regulatory workflow and auditability, Collibra is often the default shortlist item. The tradeoff is time and complexity: plan for months, not weeks.
Atlan is the fastest to get live for many teams, and the UX is a big reason it spreads internally. It's also positioned as a leader in recent analyst coverage. If you're trying to get from "we should have a catalog" to "people actually use the catalog" without a year-long rollout, Atlan's usually the first demo that makes stakeholders stop scrolling their phones. Kiwi.com has shared results around reducing engineering documentation workload after deployment.
Mid-market and lightweight options (good enough beats perfect)
Informatica IDMC is an integration powerhouse with a huge connector ecosystem and automation features. It's not cheap, and it isn't simple, but for orgs already standardized on Informatica, it's the obvious extension.
Databricks Unity Catalog makes sense if you're already running a Databricks lakehouse. Skip it if you're not. Buying a lakehouse platform "for the catalog" is like buying a truck because you like the cup holders.
Secoda is the scrappy option for teams that want something working in days, not quarters. For many startups, that matters more than having every governance workflow under the sun.
Open-source (skip this if you don't have real engineering time)
DataHub and OpenMetadata are legitimate, widely used open-source catalogs. They're also not "install and forget." If you don't have someone who can own upgrades, connectors, and reliability, you'll end up with a half-working internal tool that everyone avoids.
Open-source is a great fit when you want control and you can staff it. It's a bad fit when you're trying to avoid staffing.
Why DI initiatives fail (the patterns are consistent)
RAND's analysis of AI project failures calls out leadership misunderstanding, unrealistic timelines, and trend-chasing without a clear business case: https://www.rand.org/pubs/research_reports/RRA2680-1.html
Those show up in DI work too, but the most expensive failure mode is simpler: teams buy a big platform before fixing foundations. The catalog gets deployed. The UI looks great. Then users open it, find stale definitions and broken links, and never come back.
Here's a scenario we've watched play out: a RevOps team builds a "single source of truth" dashboard for pipeline, then the sales org loses trust because the numbers don't match what reps see in the CRM. The root cause ends up being duplicates, inconsistent stage definitions, and enrichment that pulled in outdated contacts. Everyone blames the dashboard. The dashboard wasn't the problem. If you're building around pipeline, a tighter RevOps tech stack and clearer pipeline management usually fix more than another dashboard.
For B2B teams, contact data is often the first domino. If your enrichment pipeline is feeding bad emails and disconnected numbers into your CRM, your analytics layer will faithfully report nonsense. Prospeo's enrichment and API workflows are designed to prevent that: 50+ data points per contact, 92% API match rate, and an 83% enrichment match rate on leads returning contact data. If you're comparing vendors, see the best data enrichment tools and the practical benefits of data enrichment.
Look, the fix isn't complicated. It's just unglamorous: audit, clean, verify, assign ownership, enforce definitions. Then buy the platform.
How to measure ROI without lying to yourself
ISACA's three-bucket model is one of the few ROI frameworks that holds up in executive reviews because it separates quick wins from compounding value: https://www.isaca.org/resources/isaca-journal/issues/2023/volume-1/measuring-the-roi-of-data-governance
| ROI category | Timeframe | What to measure |
|---|---|---|
| Measurable ROI | 6-12 months | Fewer data incident tickets, reduced rework, faster onboarding, fewer compliance exceptions |
| Strategic ROI | 3-5 years | Process efficiency, model accuracy, reduced audit risk, faster product decisions |
| Capability ROI | Ongoing | Catalog adoption, steward participation, data literacy, time-to-find-and-trust |
The trap is only measuring the first bucket. It's the easiest to count, and it's usually the smallest slice of the long-term value.
One more opinionated take: most companies under ~500 employees don't need a DI platform. They need clean data, a documented dictionary in a tool people already use, and one accountable owner. Buying a platform too early is a great way to spend a lot of money and still have the same arguments in six months.
Where data intelligence is heading in 2026
Three shifts are changing what "good" looks like.
1) GraphRAG and knowledge graphs are moving from experiments to real workloads. That raises the bar for metadata, lineage, and governance because relationship-based retrieval breaks badly when entities are inconsistent or stale.
2) Consolidation is accelerating. Catalog, governance, quality, and marketplace features are merging into fewer platforms. That's convenient, and it increases lock-in. Choose like you're picking an operating system, not a plugin.
3) Agentic workflows demand stronger controls. An agent that can research a prospect, enrich a record, draft an email, and trigger actions is only safe if it can verify provenance, respect permissions, and avoid using restricted data. DI isn't the "data team project" anymore; it's the prerequisite for automation you can trust. If you're operationalizing this in GTM, GTM AI is where the tooling decisions start to matter.
Stale, bouncing contact data doesn't just kill outbound - it distorts your pipeline reporting, breaks attribution, and poisons every downstream system that touches it. Prospeo's 5-step verification, catch-all handling, and weekly refresh cycle mean your CRM stays clean without manual intervention. At $0.01 per email, it costs less than one bad decision made on dirty data.
Stop debugging garbage. Start with verified data at the source.
FAQ
What is data intelligence vs. business intelligence?
BI analyzes data to produce reports and dashboards showing what happened. Data intelligence focuses on the data itself - its origin, quality, lineage, and governance - so BI outputs are reliable.
How much does a data intelligence platform cost?
Enterprise platforms like Collibra and Alation often run $75k-$200k+ per year, and deployments can take months depending on scope and governance maturity. Mid-market tools like Secoda start around $500/month and can be live in 1-2 weeks. Open-source options like DataHub and OpenMetadata are free to self-host but require engineering time to run well.
Do you need a DI platform before deploying GenAI?
You need the capabilities (quality checks, metadata, lineage, access controls), but you don't always need a big platform on day one. Without those foundations, RAG systems return unreliable results and create security and compliance risk.
How do you start with data intelligence on a small budget?
Start with data quality and ownership. Clean and verify the data you already have, especially CRM contacts, then document definitions and assign stewards for the datasets that drive revenue and reporting. Tools help, but discipline comes first.
What's the biggest reason DI initiatives fail?
Buying enterprise tooling before fixing foundations and changing behavior. If ownership is unclear, definitions aren't enforced, and quality isn't measured, the platform becomes an expensive directory that nobody trusts.