Data Standardization: What It Is, Why It Matters, and How to Do It Right
Your CEO just asked why the AI pilot failed. The answer isn't in your model architecture or your training pipeline - it's in your date columns. One system stores dates as MM/DD/YYYY, another as DD-Mon-YY, and a third as Unix timestamps. The model never stood a chance.
That's a data standardization failure, and it's costing more than most executives realize.
43% of chief operations officers identify data quality as their most significant data priority, and 45% of business leaders say concerns about data accuracy and bias are the leading barrier to scaling AI. With Gartner forecasting AI spending to surpass $2T in 2026, the gap between "we have data" and "we have usable data" has never been more expensive.
The Quick Version
Data standardization means two different things depending on who you are. If you're on a data or analytics team, it's about converting messy, multi-source data into uniform formats - consistent naming, date conventions, units, taxonomies. If you're an ML practitioner, it's about z-score scaling: transforming features to have mean 0 and standard deviation 1 so your algorithms don't choke on magnitude differences.
Most guides on this topic are useless because they mash these two concepts together. This one covers both. The short version of the enterprise playbook: audit your data, define your standards, transform, validate, govern. The cost of skipping this? $12.9M per year on average.
What Does Standardizing Data Actually Mean?
At its core, the process involves converting data from disparate sources into a consistent, uniform format. Think of it as establishing a single dialect across an organization that speaks dozens of data languages.
In enterprise data management, this means enforcing common naming conventions (revenue_usd, not rev_1), uniform date formats (YYYY-MM-DD everywhere), consistent units of measurement, and shared taxonomies. It's the foundation that makes integration, analytics, and reporting actually work.
In machine learning, standardization has a narrower, mathematical meaning: rescaling numerical features so they share a common distribution - typically mean = 0, standard deviation = 1. This is critical for algorithms sensitive to feature magnitude. Understanding both standardization and normalization matters, since the two serve different purposes but get confused constantly.
Both meanings share the same underlying principle - making data comparable and consistent - but the techniques, tools, and contexts are completely different.
Why Standardizing Data Matters
The financial case is blunt. Over a quarter of organizations lose more than $5M annually due to poor data quality, with 7% reporting losses north of $25M. Improvado puts the average cost at $12.9M per year. That's headcount, pipeline, and competitive advantage bleeding out through inconsistent records.

The time cost is equally brutal. McKinsey estimates that data processing and cleanup consume 30%+ of analytics teams' time. That's your most expensive people doing janitorial work instead of generating insights. A large footwear retailer cut their average change implementation time from roughly three months to under one week simply by standardizing KPIs and using lineage to assess downstream impact. Booyah Advertising achieved 99.9% data accuracy after standardizing their marketing data, reducing budget pacing from hours of manual work to 10-30 minutes.
Then there's compliance. GDPR, CCPA, HIPAA - every major regulatory framework assumes you can locate, classify, and report on your data consistently. If your customer records live in three formats across five systems, responding to a data subject access request becomes an archaeological expedition. The average data breach costs $4.44M worldwide, and standardized formats won't prevent every breach, but they make your data auditable and governable. With 57% of organizations now prioritizing data governance to improve data integrity, the industry is waking up to this reality - slowly.
Here's the thing: most companies don't have an AI problem. They have a data quality problem wearing an AI costume. Organizations that treat standardization as a one-time migration inevitably drift back into chaos within 18 months. The ones that build it into their operational rhythm - like code review or sprint planning - are the ones whose AI initiatives actually scale.
Standardization vs. Normalization vs. Harmonization
These three terms get used interchangeably, and it drives practitioners crazy. Spend five minutes on r/dataengineering and you'll see "people confusing standardization with normalization" near the top of every frustration thread, right next to date format inconsistencies.

| Term | Enterprise Context | ML Context |
|---|---|---|
| Standardization | Uniform formats, naming, units across org | Z-score scaling (mean=0, SD=1) |
| Normalization | Eliminate redundancy in DB schemas (1NF-3NF) | Min-max scaling (0-1 range) |
| Harmonization | Make disparate datasets interoperable | - |
The analogy that works best: standardization is getting everyone to speak the same language. Harmonization is translating multiple languages so they make sense together. Normalization is adjusting the volume so every speaker is equally audible.
In practice, standardization usually comes first. You can't harmonize datasets that don't follow internal conventions, and you can't normalize features that aren't consistently defined. If you're building a data strategy from scratch, start here.
Data standardization failures cost $12.9M/year on average - and bad contact data is one of the worst offenders. Prospeo's 5-step verification process and 7-day refresh cycle deliver 98% email accuracy out of the box, so your CRM stays clean without the janitorial work.
Skip the cleanup. Start with data that's already standardized and verified.
How to Standardize Data (6 Steps)
This isn't a project you finish. It's a cycle. Step 6 feeds back into Step 1.
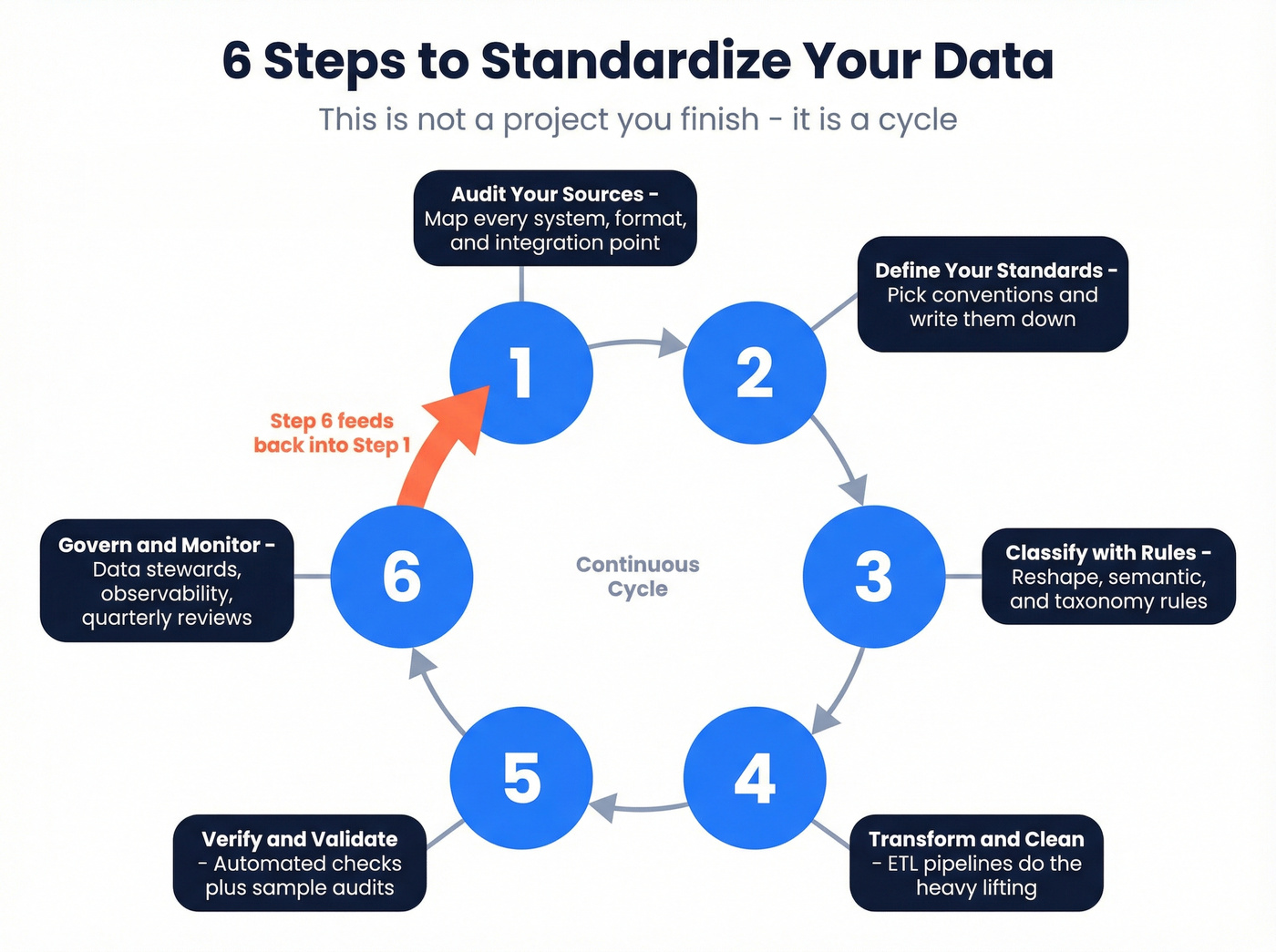
Step 1: Audit Your Sources
Map every data source, every format, every integration point. You can't standardize what you can't see. Document which systems store customer data, how they format dates, what naming conventions they use or don't. Most teams are shocked by how many shadow sources exist - spreadsheets, one-off exports, legacy systems nobody wants to touch. We've seen organizations discover 40+ undocumented data sources during their first audit, each with its own conventions and quirks.
Step 2: Define Your Standards
This is where most teams stall, and it's the single most impactful step. Pick your conventions and write them down:
- Date format:
YYYY-MM-DD - Naming:
snake_casewith units included likerevenue_usdandduration_minutes - Country codes: ISO 3166
- Currency: ISO 4217
A standards document that nobody reads is useless - make it short, enforceable, and embedded in your tooling. Where possible, enforce standards at the point of capture. Dropdown menus, controlled picklists, and input masks prevent inconsistencies from entering your systems in the first place.
Step 3: Classify with Rules
Apply the Teradata framework of three rule types:
| Rule Type | Raw Input | Standardized Output |
|---|---|---|
| Reshape | "John A. Smith" | first: "John", middle: "A", last: "Smith" |
| Semantic | "NY", "New York", "N.Y." | state_code: "NY" |
| Taxonomy | "Running Shoes - Men's" | category: "Footwear" > subcategory: "Athletic" > gender: "M" |
Each rule type addresses a different layer of inconsistency. Reshape rules transform structure. Semantic rules interpret meaning. Taxonomy rules classify data into hierarchies.
Step 4: Transform and Clean
This is where ETL/ELT pipelines do the heavy lifting. Deduplicate records, apply your reshape and semantic rules at scale, and convert everything to your target formats. Automation is non-negotiable - manual transformation doesn't scale past a few thousand records.
Tools like dbt, Informatica, or Talend handle transformation and pipeline workflows. Orchestrators like Airflow handle scheduling. Great Expectations can validate the output, and observability platforms like Monte Carlo help you monitor drift, freshness, and anomalies over time.
Step 5: Verify and Validate
Transformation without validation is just moving garbage faster. Run automated checks against your standards: are all dates in YYYY-MM-DD? Do all currency fields use ISO codes? Are there orphaned records?
Complement automated checks with sample audits - pull 100 random records and eyeball them. I've watched teams skip this step and end up with 50,000 records where the "state" field contains ZIP codes. Standardized garbage is still garbage.
Step 6: Govern and Monitor
Assign data stewards. Set up observability for schema drift, freshness, and volume anomalies. Schedule quarterly reviews of your standards document. 71% of organizations now run formal data governance programs, which means the other 29% are flying blind.
This is where most organizations fail - they do Steps 1-5 once and declare victory. Six months later, a new team onboards a new tool with different conventions, and the cycle of chaos restarts. Governance is the habit that makes standardization stick.
Data Standardization for ML
For ML practitioners, standardization has a precise mathematical definition. You're transforming features to have a mean of 0 and a standard deviation of 1 using the z-score formula:
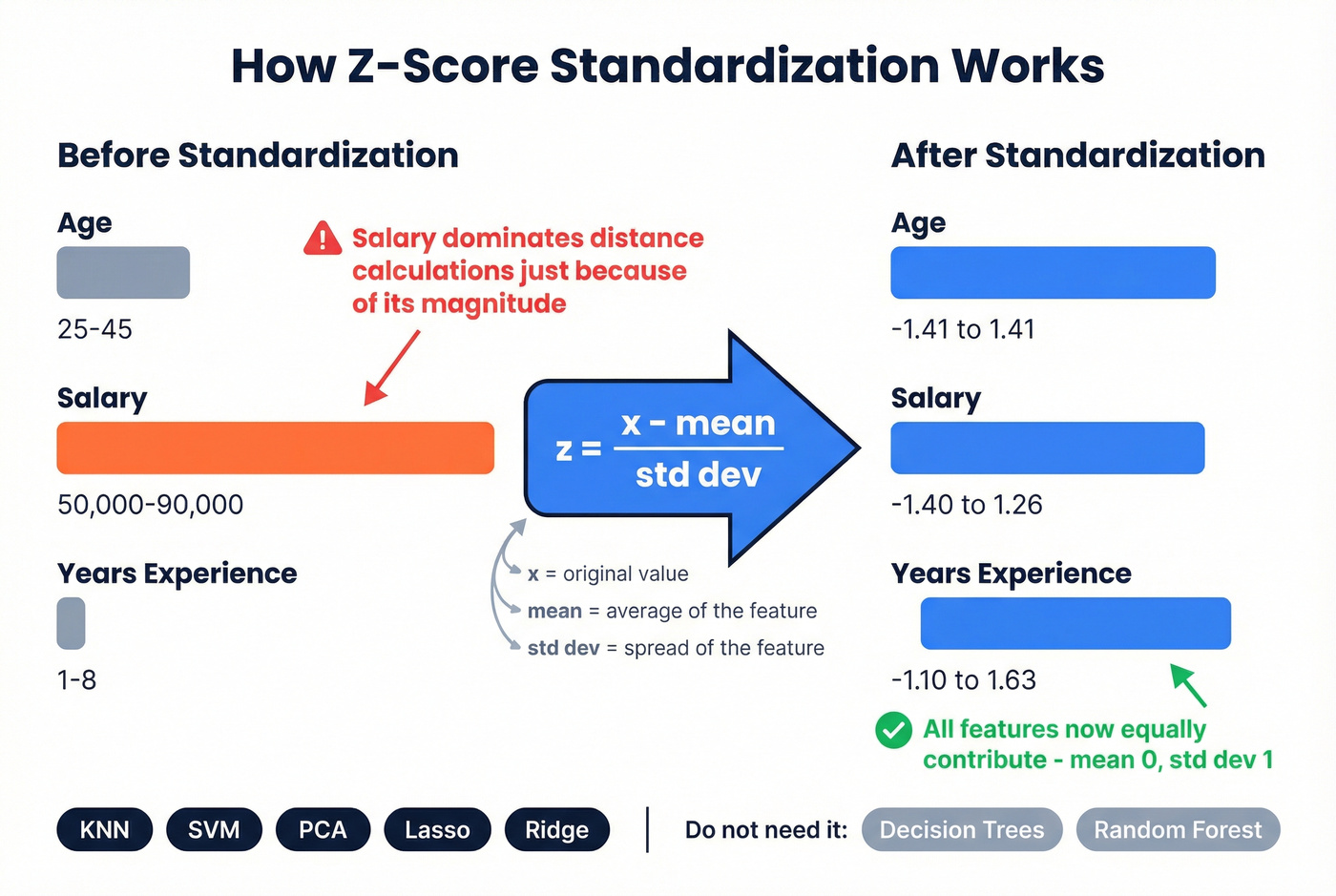
z = (x - μ) / σ
This matters because algorithms like KNN, SVM, PCA, and penalized regression (Lasso, Ridge) are sensitive to feature scale. If one feature ranges from 0-1 and another from 0-1,000,000, the larger feature dominates distance calculations and gradient updates regardless of its actual predictive value.
A correct implementation using scikit-learn's StandardScaler:
from sklearn.preprocessing import StandardScaler
# Sample data: 5 observations, 3 features
X = np.array([
[25, 50000, 3],
[30, 60000, 5],
[35, 75000, 2],
[40, 80000, 8],
[45, 90000, 1]
])
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("Means (should be ~0):", X_scaled.mean(axis=0).round(4))
print("Stds (should be ~1):", X_scaled.std(axis=0).round(4))
print("\nScaled data:\n", X_scaled.round(4))
A word of caution: some popular tutorials compute standard deviation incorrectly in their manual examples, using population SD where sample SD is needed or vice versa. Always use scikit-learn's StandardScaler to avoid subtle bugs.
When you don't need it: tree-based models like random forests, gradient boosting, and XGBoost don't require feature scaling because they split on thresholds, not distances. Standardizing before feeding data into a random forest won't hurt, but it won't help either. Skip the preprocessing step for algorithms that don't need it.
Common Mistakes
Cryptic naming conventions. rev_1, cust_dt, amt_f - these mean something to the person who created them and nobody else. Use descriptive, business-friendly names with units: revenue_usd, customer_created_date, amount_final_eur. Future you will be grateful.
Inconsistent metadata across platforms. Your CRM calls it "Company Size," your data warehouse calls it "employee_count," and your marketing platform calls it "org_headcount." Same concept, three names, zero interoperability. Centralize your metadata schema and enforce it through automated validation.
Skipping governance entirely. You standardize everything in Q1. By Q3, three new integrations have introduced four new date formats. Without stewards, policies, and monitoring, standardization decays. It's entropy - it always wins unless you actively fight it.
Ignoring time zones, locales, and units. A timestamp without a time zone is a lie. A revenue figure without a currency code is a guess. A distance without a unit is useless. Always store the context alongside the value.
Standardizing without validating. Running transformation scripts without checking the output is how you end up with corrupted fields at scale. Validate after every transformation step, not just at the end.
Industry Examples
Healthcare
US healthcare spending hit $4.9T in 2023 - $14,570 per person, 17.6% of GDP. With that much money flowing through fragmented systems, uniform data formats aren't optional. HL7 FHIR has become a key interoperability standard, enabling structured data exchange across EHRs, labs, and payers. One regional health system built a readmission risk product on standardized data and reduced readmissions 19% in six months, saving $2.8M.
Supply Chain
Supply chains run on standards most people never think about. GS1's GTIN and GLN give every product and every location a unique, universal identifier. EDI document normalization ensures purchase orders, invoices, and shipping notices can be processed consistently across trading partners. Without these standards, global commerce would grind to a halt.
B2B Sales and Outbound
CRM data is a standardization nightmare. Contacts flow in from web forms, trade shows, purchased lists, and manual entry - each with different formats, completeness levels, and accuracy. The result: duplicate records, bounced emails, and reps calling disconnected numbers.
Financial Services
ISO 20022 is a global standard for financial messaging. It enforces structured, machine-readable transaction data - standardizing everything from payment instructions to securities settlement. If your org touches cross-border payments, this isn't a nice-to-have.
Best Practices and Tools
Frameworks and Standards
DAMA-DMBOK provides the vendor-neutral reference framework, covering 11 knowledge areas with governance at the center. The current 2.0 edition is widely adopted, with 3.0 in development.
ISO/IEC 5259-5:2025 provides a governance framework specifically for data quality in analytics and ML contexts. Industry-specific standards include GS1 for supply chain, HL7/FHIR for healthcare, ISO 20022 for financial services, and ISO 8000 for master data quality.
Tools by Category
| Category | Representative Tools | Price Range |
|---|---|---|
| Data quality | Informatica | $50K-$250K+/yr |
| B2B contact data | Prospeo | Free tier, ~$0.01/email |
| Data governance | Collibra | $100K-$500K+/yr |
| Open-source | Great Expectations, dbt | Free to ~$100/mo |
| Data quality (mid-market) | Talend | Open-source available; enterprise $12K-$150K+/yr |
| Observability | Monte Carlo | $50K-$150K+/yr |
For enterprise data platforms, budget $100K-$500K/year in tooling plus 1-3 dedicated FTEs. Payback typically lands within 6-18 months through reduced analyst time, fewer data incidents, and faster reporting cycles. For teams where the standardization bottleneck is specifically contact and prospect data, skip the six-figure platform and start with a tool like Prospeo that handles verification and formatting before records ever hit your CRM.
Your analytics team shouldn't spend 30% of their time fixing inconsistent records. Prospeo enriches CRM and CSV data with 50+ standardized data points per contact at a 92% match rate - uniform formats, verified emails, and direct dials ready for every downstream system.
Enrich your database with data that doesn't need fixing.
FAQ
What's the difference between data standardization and normalization?
In enterprise contexts, standardization converts data to uniform formats (dates, naming, units), while normalization eliminates redundancy in database schemas through first to third normal form. In ML, standardization is z-score scaling (mean=0, SD=1) and normalization is min-max scaling (0-1 range). Applying the wrong technique to the wrong problem is a common and costly mistake.
How long does a standardization project take?
Foundation work takes 3-6 months for most mid-size organizations; enterprise-wide rollout runs 18-36 months. Treat it as an ongoing operational discipline - like code review or security patching - not a one-time migration. Teams that declare victory after the first pass regress within 12-18 months.
What is z-score standardization?
Z-score scaling rescales features to have mean 0 and standard deviation 1 using the formula z = (x - μ) / σ. It's required for distance-based and gradient-sensitive algorithms - KNN, SVM, PCA, Lasso, and Ridge regression. Tree-based models like XGBoost and random forests don't need it.
How much does poor data quality cost?
Over 25% of organizations lose more than $5M annually, with the average cost of bad data running $12.9M per year. The average data breach costs $4.44M worldwide. For B2B teams specifically, stale contact records are one of the most common quality gaps - they inflate bounce rates and tank sender reputation fast.
