Lead Scoring Case Studies: Real Results, Real Failures, and What Actually Works
A founder spent three weeks building an elaborate HubSpot scoring model. Whitepaper downloads got +15 points, pricing page visits got +25, and the "perfect prospect" threshold was 100. His biggest deal that quarter - a $20K annual contract - came from a lead who scored 12 out of 100. The buyer booked a demo straight from a cold message, never opened a single email or downloaded anything.
The lead scoring 89? A grad student writing a thesis. That founder scrapped the model and went back to manual qualification: problem, budget, decision-maker. His close rate tripled.
Most lead scoring case studies floating around are vendor marketing with unverifiable claims. We dug into the ones that actually show their work - plus the failures nobody talks about.
What Successful Teams Did Differently
Only 44% of organizations use lead scoring at all. Here's what the companies that actually succeeded had in common:

- Scored fit and intent, not curiosity. Pricing page visits matter. Blog reads don't.
- Cleaned their data first. Every model trains on your CRM. Garbage in, garbage out.
- Built the workflow and routing first before touching the model. (If you’re formalizing this, start with lead routing and automated lead routing.)
- Set SLAs around scores - response time matters as much as the number itself. (Speed to lead is usually the hidden lever.)
Real-World Results with Numbers
HES FinTech - ML Scoring with GiniMachine
HES FinTech built a predictive model using three years of HubSpot lead data, feeding features like lead source, corporate vs. personal email, company age, and employee count into GiniMachine's ML engine. The model achieved a Gini index of 0.6 - commercially usable, though not spectacular. Leads scoring around 0.02 got removed from the funnel or pushed into automated nurture, yielding a 12% response rate on re-engagement campaigns.

The honest caveat from their own evaluation: unqualified leads sometimes scored 0.64. That's the kind of detail most vendor case studies conveniently leave out.
Grammarly - Salesforce Einstein
The Grammarly numbers get cited everywhere: 30% more MQLs converting, 80% more account upgrades, sales cycle cut from 60-90 days down to 30, with roughly 200 high-quality leads per month routed to sales. Worth noting that these stats come from secondary case-study roundups rather than a primary Salesforce customer story, so take the precision with a grain of salt.
Einstein Lead Scoring is sold as an add-on to Salesforce. Pricing depends heavily on your edition and packaging, but teams often end up in the low hundreds per user/month once you include the required Salesforce licensing.
HubSpot Multi-Layer Intent Framework
This is the one we'd actually steal as a blueprint. A consultancy implementation built a multi-layer system with three distinct scoring tiers. ICP fit scoring - industry, size, role, region - acts as a gatekeeper. Engagement scoring weighted pricing pages and demo requests heavily over generic blog views. But the real differentiator was the SLA layer: 7-hour initial response time, escalation alerts after 24 hours, and recycle logic for cold leads. Most teams obsess over the scoring model and completely ignore what happens after a lead hits threshold. This team didn't make that mistake.
HubSpot Professional starts around $800/month; Enterprise runs roughly $3,600/month before add-ons. Professional caps scores at 100; Enterprise caps at 500.
Every lead scoring case study above has one thing in common: the model only worked after the team fixed their data. Prospeo's 7-day refresh cycle, 98% email accuracy, and 92% API match rate give your scoring model the clean foundation it needs - at $0.01/email.
Stop scoring leads on stale CRM data. Fix the input layer first.
Why Lead Scoring Fails
Here's the thing: lead scoring doesn't fail because of bad algorithms. It fails because of bad data and bad assumptions.

The most common failure is arbitrary point systems. As one practitioner on r/digital_marketing put it, most tools "track events, not stories." Assigning +5 for an email open tells you someone clicked something, not that they're ready to buy.
Data problems run deeper than most teams realize. Bots account for 40%+ of all internet traffic, inflating engagement scores with phantom activity. Email opens are unreliable because image preloading triggers false positives. And for ML models, CRMs store latest-state data, not historical snapshots - when you train on a lead's current record, you're leaking future information into the training set. This is why predictive scoring can look great in backtesting and then degrade in production.
If you want a deeper breakdown of what “behavior” signals actually work (and which ones are vanity), see behavior scoring.
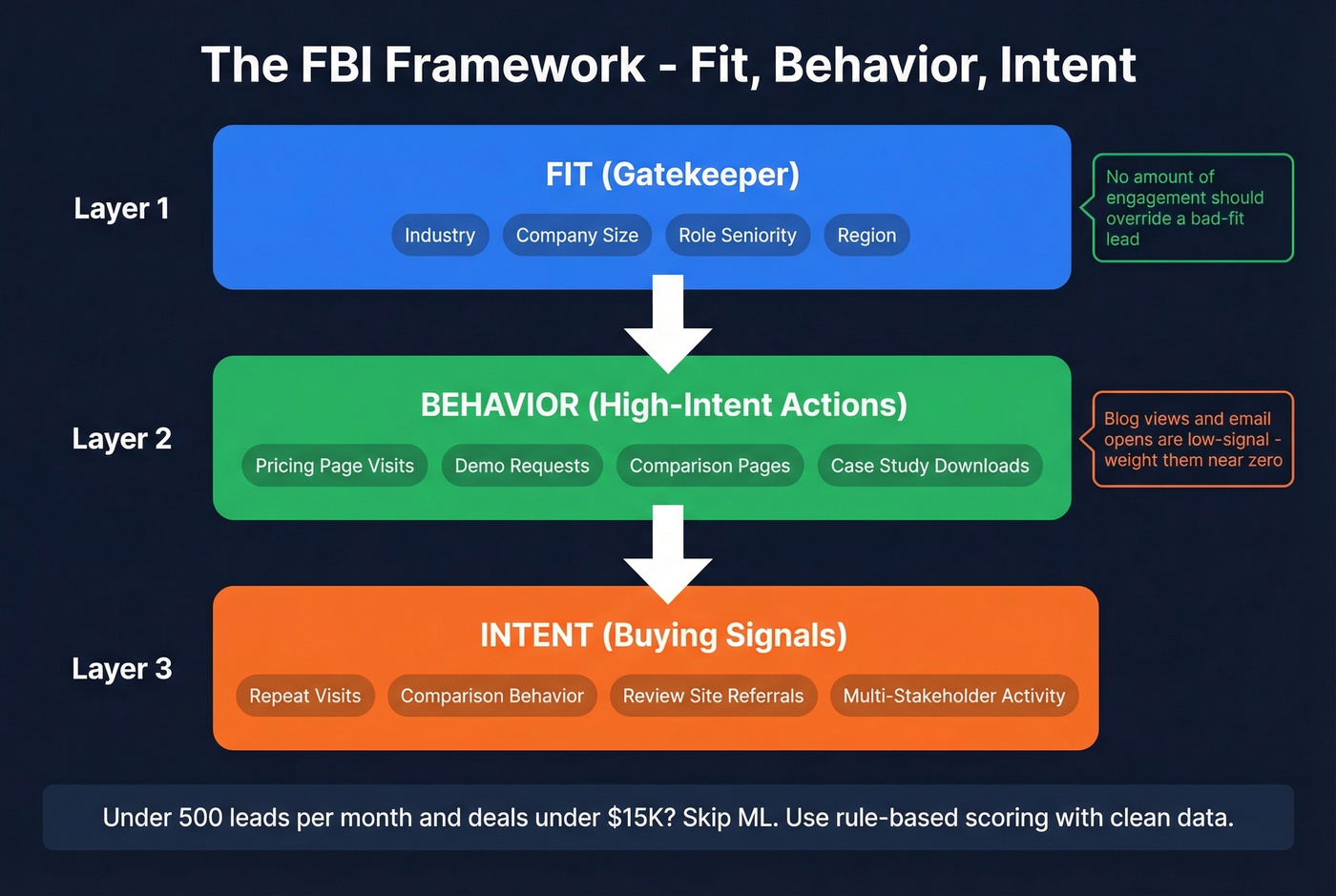
The FBI Framework: Fit, Behavior, Intent
The practitioners who've fixed their scoring converge on three separate buckets. One founder reported that weighting fit and intent over raw activity made pipeline conversations "way more efficient."
| Approach | Best For | Biggest Risk | Setup Time |
|---|---|---|---|
| Rule-based (HubSpot) | Early-stage, small pipeline | Arbitrary weights, curiosity ≠ intent | Days |
| Predictive ML (Einstein, GiniMachine) | Large datasets, complex ICP | Data leakage, stale CRM data | 3-6 months |
| Hybrid FBI (Fit + Behavior + Intent) | Mid-market, scaling teams | Requires clean data | 2-4 weeks |
Fit is firmographics: industry, company size, role seniority. Behavior is high-intent page visits - pricing, demo, comparison pages. Intent is repeat visits, comparison behavior, and signals like review-site referrals.
The fit bucket acts as a gatekeeper. No amount of engagement should override a bad-fit lead.
Let's be direct: if your deal size is under $15K and your pipeline has fewer than 500 leads per month, skip predictive ML entirely. A well-built rule-based model with clean data will outperform a fancy algorithm trained on a thin dataset every single time. We've watched teams spend six months building ML scoring when a two-day HubSpot setup would have gotten them 80% of the way there. (If you’re deciding between approaches, AI lead scoring vs traditional lead scoring covers the tradeoffs.)
Clean Data First, Score Later
Every scoring model - rule-based or ML - trains on your CRM data. If that data is stale, the model learns noise. If emails are invalid, engagement signals are meaningless. If job titles haven't been updated in six months, your fit scoring is fiction.
In our experience, the fastest scoring fix isn't algorithmic. It's data quality. Before you score a single lead, verify your contact data. Prospeo runs a 7-day refresh cycle on 300M+ profiles with 98% email accuracy and a 92% API match rate, returning 50+ enriched data points per contact at roughly $0.01/email. That's the data layer your scoring model needs before it can produce numbers your reps will trust. (Related: lead data enrichment and B2B lead enrichment.)
Skip this step if you're confident your CRM data is already clean and current - but honestly, we've never met a team that didn't find at least 15-20% of their records were stale or invalid once they actually checked. If you’re seeing bounces, start with why emails bounce.

The FBI framework needs verified firmographics to gate fit, and real engagement signals to measure behavior. Prospeo returns 50+ enriched data points per contact across 300M+ profiles - so your fit scores reflect reality, not six-month-old job titles.
Your scoring model deserves data that's less than a week old.
FAQ
Does AI lead scoring outperform rule-based scoring?
AI lead scoring shows 25-215% conversion improvements in reported case studies, but only when trained on clean, time-aligned data with 1,000+ historical conversions. Rule-based scoring works fine for early-stage teams with small pipelines and deal sizes under $20K.
How long does implementation take?
Rule-based scoring in HubSpot takes days. ML models typically require 3-6 months for data collection, training, and validation. The hybrid FBI framework sits between those at 2-4 weeks with proper CRM hygiene.
What's the fastest way to improve scoring accuracy?
Fix your data before touching the model. Enrich CRM contacts with verified emails and current firmographics - that foundation is what scoring models need to produce numbers your sales team will actually act on.
Can small teams benefit from lead scoring?
Yes, but with a caveat. Teams with 200+ inbound leads per month see the most immediate ROI from even basic rule-based scoring. Below that volume, manual qualification with a simple ICP checklist often outperforms automated scoring because you don't have enough data to calibrate point values accurately.