Split Testing Emails: Fix Your Foundation Before You Optimize
A RevOps lead we know spent six months obsessively A/B testing subject lines, first sentences, and CTAs. Reply rate? Stuck at 1.2%. Then they stopped tweaking copy and rebuilt their targeting around buying signals. Same email, same offer - reply rate jumped to 8%. The copy was never the problem. The audience was.
That story captures why most teams get split testing emails wrong. Only 59% of companies bother with it, yet those that do see 83% higher ROI - a gap of 42:1 returns versus 23:1 for non-testers. The practice is mainstream now. But the gap isn't sophistication. It's testing the right things in the right order.
What You Need Before Testing
Before you touch a single subject line variable, nail these three things:
- Targeting and segmentation first. If your list is wrong, no amount of copy optimization will save you. (If you need a framework, start with an Ideal Customer Profile and build from there.)
- Stop trusting open rates. Apple Mail Privacy Protection killed them as a reliable metric back in 2021. Use clicks, replies, and conversions instead.
- Prioritize with RICE. Don't guess which test to run next. Score each idea by Reach, Impact, Confidence, and Effort - then run the top three.
Fix Your List Before Your Copy
Here's the thing: most teams get the hierarchy backwards. Targeting beats copy, and data quality beats both. You can write the perfect subject line, but if 15% of your list bounces, you've corrupted your sample before the test starts. Invalid addresses don't just waste sends - they skew your metrics, tank your sender reputation, and make every "winner" suspect.
Look at your target list and ask: can you explain why each person needs what you're selling right now? If you can't, your targeting is wrong, and running an email split test on copy is premature optimization. (If you're struggling to define those triggers, use a simple buying signals scorecard.)
Before running any test, clean your list. Prospeo's email verification - with catch-all handling, spam-trap removal, and honeypot filtering - delivers 98% accuracy on a 7-day refresh cycle. One customer, Meritt, saw their bounce rate drop from 35% to under 4% after switching, which tripled their pipeline. When your test data is clean, your results actually mean something. (For bounce benchmarks and what “good” looks like, see email bounce rate.)
Choosing Your A/B Testing Variables
Most teams brainstorm a dozen test ideas and run whichever one the VP of Marketing thinks is clever. That's how you waste quarters.

Instead, adapt the RICE framework from product management to your email campaign testing backlog. Score each test idea on four dimensions:
- Reach - How many recipients does this test affect? A subject line test hits everyone; a CTA test only hits openers.
- Impact - How much could this move your primary metric? Score 3/2/1/0.5/0.25.
- Confidence - How sure are you this'll produce a measurable difference? Use a percentage.
- Effort - How many hours to set up and analyze? Lower is better.
Formula: (Reach x Impact x Confidence) / Effort. A worked example: Sender name test with 10,000 recipients, high impact (3), 90% confidence, and half an hour of effort scores 54,000. That crushes most other ideas. Rank everything and run the top three.
Based on practitioner data from real-world tests, run these three tests in this order:
| Test | Typical Result | RICE Priority |
|---|---|---|
| Sender name (person vs brand) | +40% opens, +66% CTR | High - run first |
| Emoji in subject line | ~90% win rate on opens | High - run second |
| Price visibility in body | Fewer clicks, ~78% more conversions | Medium - run third |
The sender name test is your highest-leverage first move. Switching from "Acme Corp" to "Sarah at Acme" consistently lifts both opens and clicks. Subject line testing can drive up to 49% higher open rates, but sender name affects whether the email gets opened at all - test it first. (If you want a swipe file for variants, pull from these email subject line examples.)
Most teams spend months agonizing over AI-generated subject line variants when a simple sender name swap would outperform every one of them. Start boring. Get fancy later.
Every split test you run on bad data is a wasted experiment. Bounced emails corrupt your sample, skew your metrics, and make every 'winning' variant suspect. Prospeo's 5-step verification delivers 98% email accuracy with catch-all handling and spam-trap removal - refreshed every 7 days, not every 6 weeks.
Stop optimizing copy on a broken list. Fix the data first.
Why Your A/B Tests Might Be Lying
If you're still using open rates as your primary metric for an email split test, you're making decisions on fictional data.
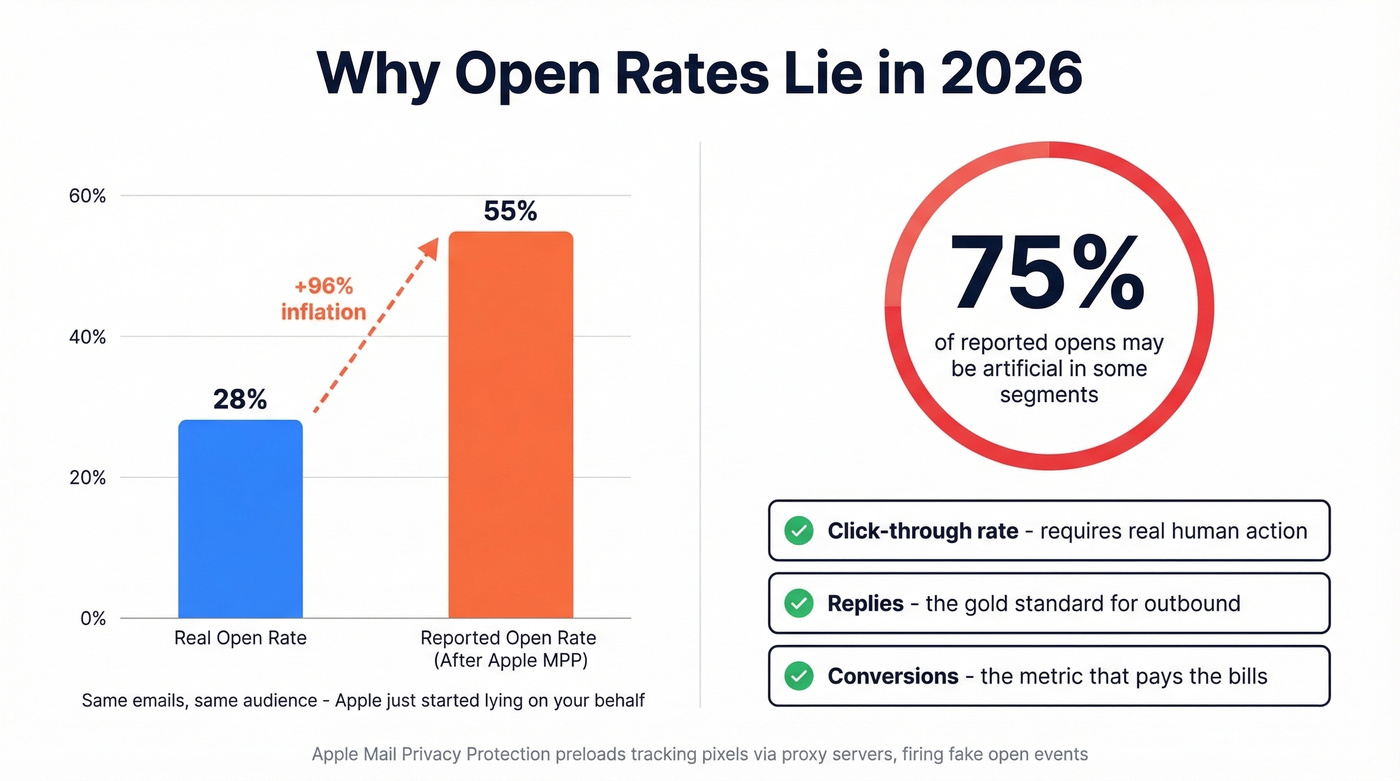
Apple Mail Privacy Protection, rolled out in 2021, preloads tracking pixels via proxy servers. This fires an "open" event even when nobody reads your email. One marketer saw open rates spike from 28% to 55% overnight - not because their emails improved, but because Apple started lying on their behalf. In some segments, up to 75% of reported opens are artificial.
This isn't a minor distortion. It's a fundamental breakdown of the metric, and it applies to anyone using the Apple Mail app regardless of their email provider - a Gmail user reading in Apple Mail triggers the same phantom open.
The Reddit consensus backs this up. One marketer sending millions of emails monthly stopped A/B testing entirely because bots and MPP made opens and clicks too noisy to trust. That's an overreaction, but the frustration is legitimate.
Metrics That Actually Work
Shift to signals that require intentional human action:
- Click-through rate - still the most reliable engagement signal (use a consistent click rate formula so tests stay comparable)
- Replies - especially critical for outbound
- Conversions and purchases - the metric that pays the bills
- Referral activity - forwards and shares
Never trigger automations based on opens alone. An "opened but didn't click" segment is mostly Apple bots in 2026. Segment into high-confidence openers (open + click) and low-confidence openers (open with no further action), and treat the second group as unreliable.
How to Know If Your Result Is Real
Statistical significance isn't optional - it's the difference between a real insight and a coin flip you're treating as strategy.

You need 95% confidence and 80% power. In practice, that often means thousands of recipients per variant, and Litmus recommends 10,000 as a rule of thumb. If your list is small, run a 50/50 split instead of carving off a tiny test segment - you'll need every recipient to reach significance.
One variable at a time is table stakes. If you change the subject line and the CTA and the send time, you've learned nothing about any of them. Isolating variables is the only way to draw causal conclusions from your results. (If you want a dedicated playbook for this specific lever, use email preview text A/B testing as your next test after sender name.)
Best Tools for Email A/B Testing
The tool matters less than the process, but here's what's available:
| Tool | Max Variants | Starting Price | Best For |
|---|---|---|---|
| Prospeo | N/A (verification) | Free / ~$0.01/email | Pre-test list cleaning |
| ActiveCampaign | 5 | $29/mo | Multi-variant testing |
| Mailchimp | 3 | $6.50/mo | Budget-friendly start |
| GetResponse | 5 | ~$14/mo | Mid-range flexibility |
| Benchmark | Multivariate | $13/mo | Low-cost multivariate |
| Brevo | 2 | $25/mo | Subject line tests |
ActiveCampaign is a strong pick for true multi-variant testing - up to five variations with solid automation. For teams watching budget, Mailchimp at $6.50/mo gets you started with three variants, which is plenty for most early-stage testing programs. GetResponse splits the difference at ~$14/mo. Skip Brevo if you need more than two variants; its A/B testing only kicks in at the Business plan and caps at two. (If deliverability is shaky, fix that before tool-shopping with an email deliverability guide.)
Common Mistakes That Kill Tests
Testing too many variables at once. One variable per test, always. If you change three things, you can't attribute the result to any of them.

Calling a winner too early. A 2% lift after 200 sends isn't a result - it's noise. Wait for statistical significance. We've watched teams roll out "winning" subject lines based on 150-send tests, then wonder why performance didn't hold at scale.
Running tests without a hypothesis. "Let's see what happens" isn't a test - it's a guess. Write down what you expect and why before you hit send.
Ignoring bot and MPP pollution. If you're declaring winners based on open rates in 2026, you're letting Apple's proxy servers make your marketing decisions.
Not documenting findings. We've seen teams re-run the same subject line test three quarters in a row because nobody wrote down what happened. Keep a shared log - even a simple spreadsheet with date, variable, sample size, result, and confidence level saves you from repeating yourself.
Let's be honest: split testing emails is one of the highest-ROI habits a marketing or sales team can build. But only when the foundation is solid. Clean data, the right metrics, and disciplined prioritization will outperform clever copy tricks every single time. (If you want to systematize the “what to do next” part, build a lightweight lead generation workflow that feeds testing with consistent segments.)
You just learned that targeting beats copy and data quality beats both. Prospeo gives you 30+ filters - buyer intent, technographics, job changes, headcount growth - so every recipient on your split test actually needs what you're selling right now. Meritt tripled their pipeline after switching. Same team, clean data.
Build test audiences that make your results real for $0.01 per email.
FAQ
What's the difference between A/B and multivariate testing?
A/B testing compares two versions with one variable changed - for example, two subject lines. Multivariate testing changes multiple variables simultaneously and measures all combinations. Stick with A/B unless you're sending to 50,000+ recipients, since multivariate tests require far larger sample sizes to reach significance.
How long should I run an email split test?
Run until you hit 95% statistical significance - often thousands of recipients per variant, with 10,000 as a solid benchmark. Plan your sample size before you send. You can't add recipients after the fact without invalidating the test.
Can I run split tests with a small list?
Yes, but use a 50/50 split instead of a small test segment. You'll only detect large differences, so focus on high-impact variables like sender name that produce bigger swings - typically 40%+ lifts - rather than subtle copy tweaks.
Are open rates still reliable for A/B testing?
No. Apple Mail Privacy Protection inflates opens by up to 75% in some segments. Use click-through rate, replies, or conversions as your primary metric. Any decision based on open rates alone in 2026 is essentially random.
How do I make sure my test data is accurate?
Verify your email list before testing. Bounced emails, spam traps, and dead addresses corrupt your sample and skew results. Prospeo's verification handles catch-all domains and removes honeypots at 98% accuracy - its free tier covers 75 emails per month, enough to validate a test segment before committing budget.