What Is Data Hygiene? The 2026 Guide (+ KPIs)
You send a campaign to 50,000 contacts and 12% bounce on the first drop. Your sender reputation tanks, sequences stall, and your ops team spends two weeks firefighting instead of selling. That's not a "data quality problem." It's a data hygiene problem - and it's been compounding since someone copy-pasted a spreadsheet into your CRM three quarters ago.
The Short Version
Data hygiene is the set of daily processes that keep databases clean, complete, and error-free - deduplication, validation, standardization, enrichment, and archiving. At least 23% of your email list degrades every year. If you haven't verified in six months, assume a quarter of your email addresses are wrong.
The two root causes are data entry (garbage in from day one) and data decay (good data going stale). Fix those and most hygiene issues shrink fast.
Data Hygiene Defined
Data hygiene refers to the continuous processes that keep databases clean, complete, and error-free. It's not a one-time cleanup project. It's the operational discipline of preventing bad data from entering your systems and catching decay before it compounds.
In practice, it covers five activities:
- Deduplication - merging or removing duplicate records
- Validation - confirming emails, phones, and addresses are real and deliverable
- Standardization - enforcing consistent formatting across fields
- Enrichment - filling in missing data points automatically
- Archiving - moving obsolete records out of active systems
Traditionally, these practices centered on postal address cleaning - NCOA processing, CASS certification, suppression lists for direct mail. In 2026, B2B hygiene is about email deliverability, CRM accuracy, and making sure your records are clean enough to feed AI models. The principles haven't changed; the fields have.
Think of it like dental hygiene. You don't wait until you need a root canal. You brush daily, floss, and get cleanings on a schedule. Database maintenance works the same way.
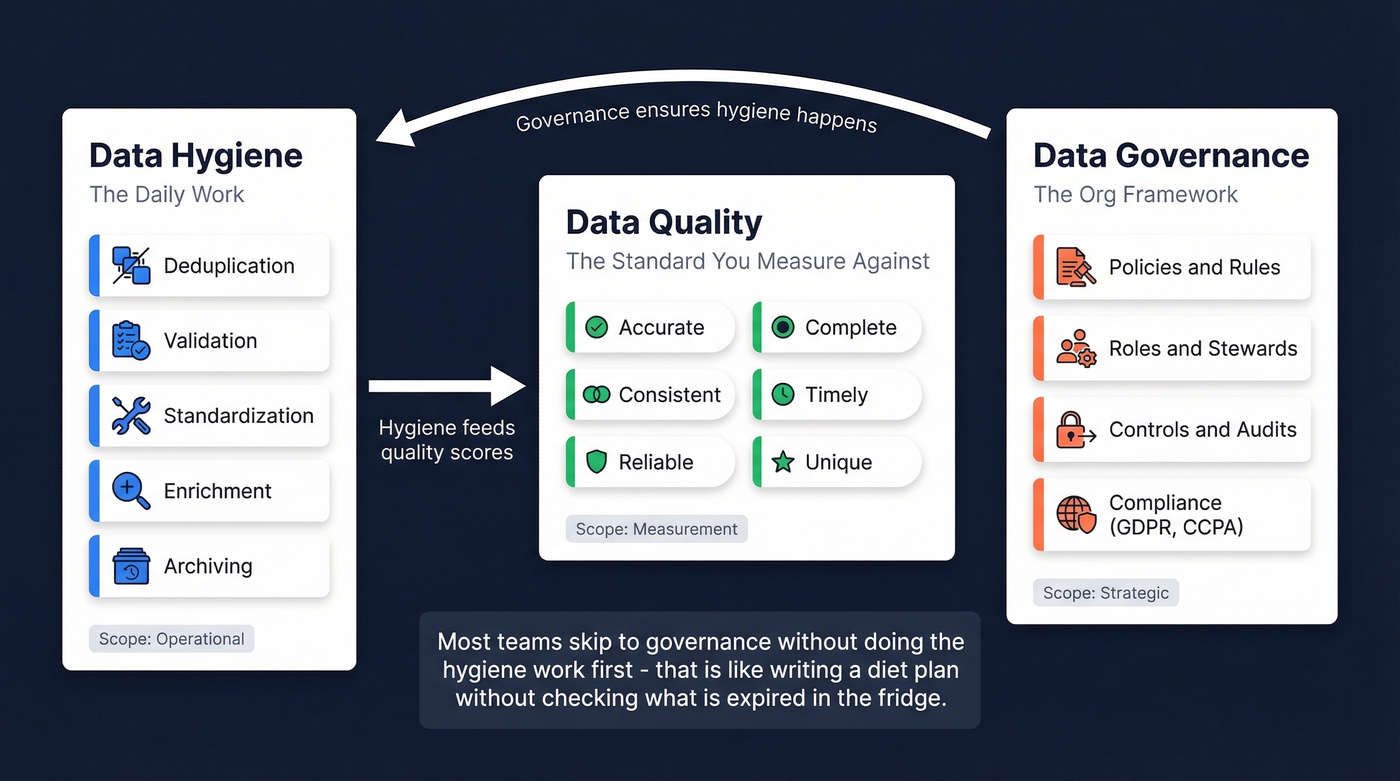
Data Quality vs Data Hygiene vs Governance
These three terms get used interchangeably, and they shouldn't.
| Concept | What It Is | Scope |
|---|---|---|
| Data Hygiene | Daily cleaning tasks | Operational |
| Data Quality | Fitness-for-use standard | Measurement |
| Data Governance | Org framework of policies | Strategic |
Hygiene is the daily work - verifying, deduplicating, standardizing. Data quality is the standard you measure against: is this data accurate, complete, timely, consistent, reliable, and unique? Data governance is the organizational framework of policies, roles, stewards, and controls that ensure hygiene actually happens.
You need all three. But most teams skip straight to governance without doing the hygiene work first. That's like writing a diet plan without opening the fridge to see what's expired.
Why It Matters in 2026
Poor data quality costs organizations an average of $12.9 million per year, according to Gartner. IBM's research sharpens the picture: 43% of chief operations officers identify data quality as their most significant data priority, and over a quarter of organizations estimate they lose more than $5 million annually to bad data.

Here's the thing about 2026 specifically: Gartner forecasts AI spending will surpass $2 trillion this year with 37% growth. But 45% of business leaders cite data accuracy as the top barrier to scaling AI. You can't feed dirty data into an AI model and expect clean outputs. Every AI initiative is a data hygiene initiative whether you planned it that way or not.
Regulatory pressure adds another layer. GDPR and CCPA increase the compliance risk of keeping inaccurate, unnecessary, or poorly controlled personal data. Storing records you can't verify or don't need creates liability for zero business value.
McKinsey found that data-driven organizations are 23 times more likely to earn new customers, six times more likely to retain them, and 19 times more profitable. Picture this: your CEO tells the board you have 15,000 customers. Finance says 11,000. The difference? Duplicates, outdated records, and test accounts that never got purged. That's a credibility problem that erodes trust in every metric downstream.
Let's be honest - most companies don't actually have a "data quality problem." They have a data entry problem and a data decay problem. Everything else - the duplicates, the bounced emails, the mismatched fields - is downstream of those two failures. Fix the inputs and the outputs fix themselves.
How Fast Does Data Decay?
Faster than most teams realize.
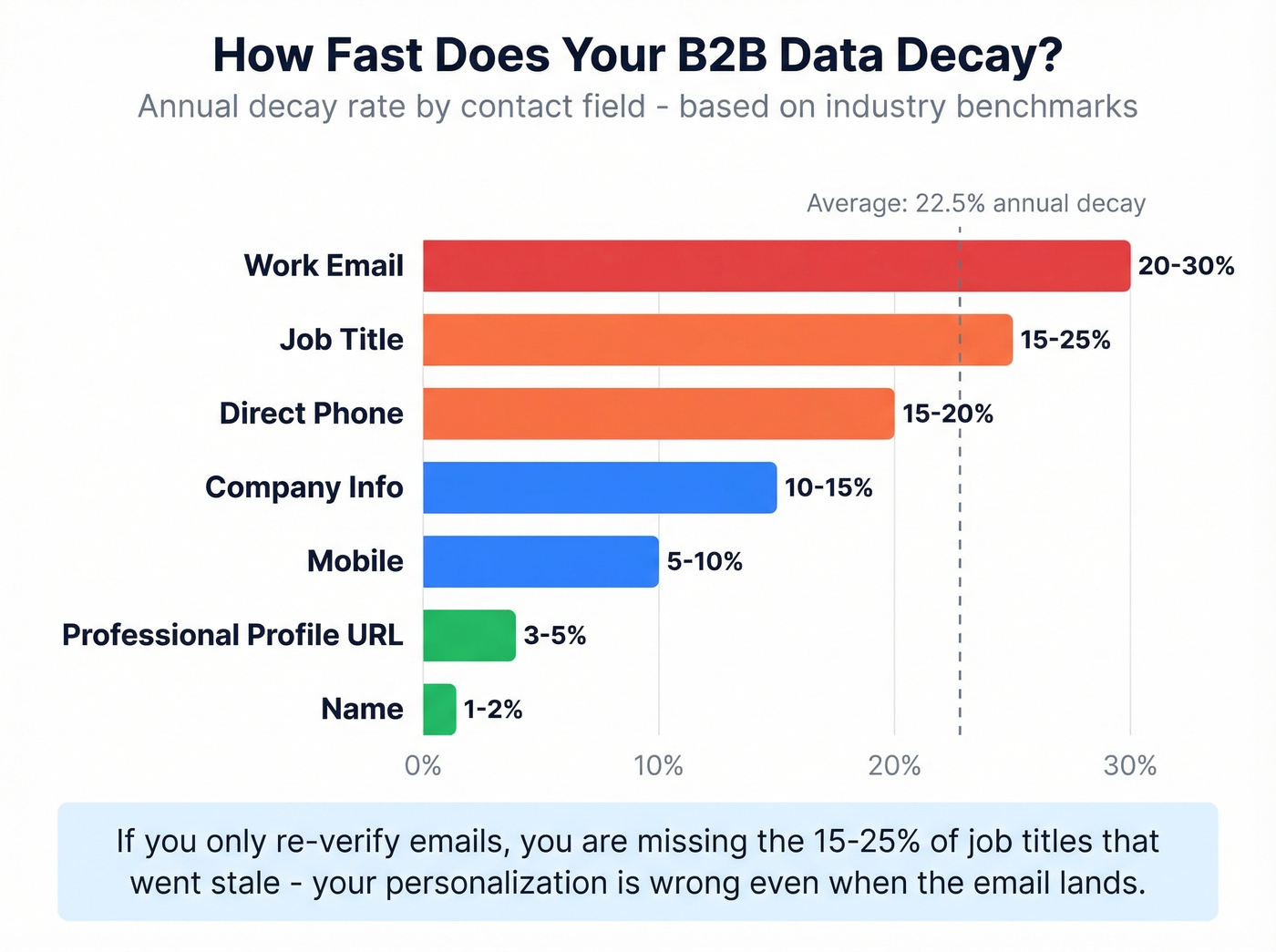
ZeroBounce's analysis found that at least 23% of an email list degrades yearly. The trend has bounced around - 22% in 2022, 25% in 2023, 28% in 2024, back to 23% in 2025 - but the baseline is clear: roughly one in four email addresses goes bad every year.
Email isn't the only field that decays. A commonly used B2B benchmark puts contact-data decay at 22.5% annually across fields:
| Field | Annual Decay Rate |
|---|---|
| Work Email | 20-30% |
| Job Title | 15-25% |
| Direct Phone | 15-20% |
| Company Info | 10-15% |
| Mobile | 5-10% |
| Professional profile URL | 3-5% |
| Name | 1-2% |
Work emails decay fastest because people change jobs. Job titles shift with promotions and reorgs. The practical takeaway: if you're only re-verifying emails, you're missing the 15-25% of job titles that went stale - which means your personalization is wrong even when the email lands. Without a cleaning strategy that covers every field, you're only solving half the problem.
You just read that 23% of email lists degrade every year. Prospeo's 7-day data refresh cycle means your contacts never sit stale for six weeks like they do with other providers. Every record runs through 5-step verification - catch-all handling, spam-trap removal, honeypot filtering - delivering 98% email accuracy at $0.01 per lead.
Stop firefighting bounces and start sending to verified contacts.
Why Most Teams Still Struggle
The data is clear: 65% of companies still rely on Excel to scrub their data. CRM duplication rates hit 20%. And 70% of teams cite duplicate and inconsistent data as their top struggle.
The core challenge isn't technical - it's behavioral. Sixty percent of data quality issues trace back to variations in business names, personal names, and addresses. People enter "IBM" and "International Business Machines" and "IBM Corp" and suddenly you've got three accounts for the same company. We've seen this firsthand in our own CRM before we locked down input fields.
The consensus on r/startups is blunt: eliminate all the spreadsheets and ban manual copy-paste. Invest in a proper data stack early because cleanup later is exponentially more painful. The HubSpot community on Reddit echoes this at scale - duplicate contacts pile up as CRMs grow, and manual merges don't scale past a team of two.
How to Implement Data Hygiene
This five-step framework comes from enterprise data cleaning methodology but works at any scale. Use it as your data hygiene checklist.
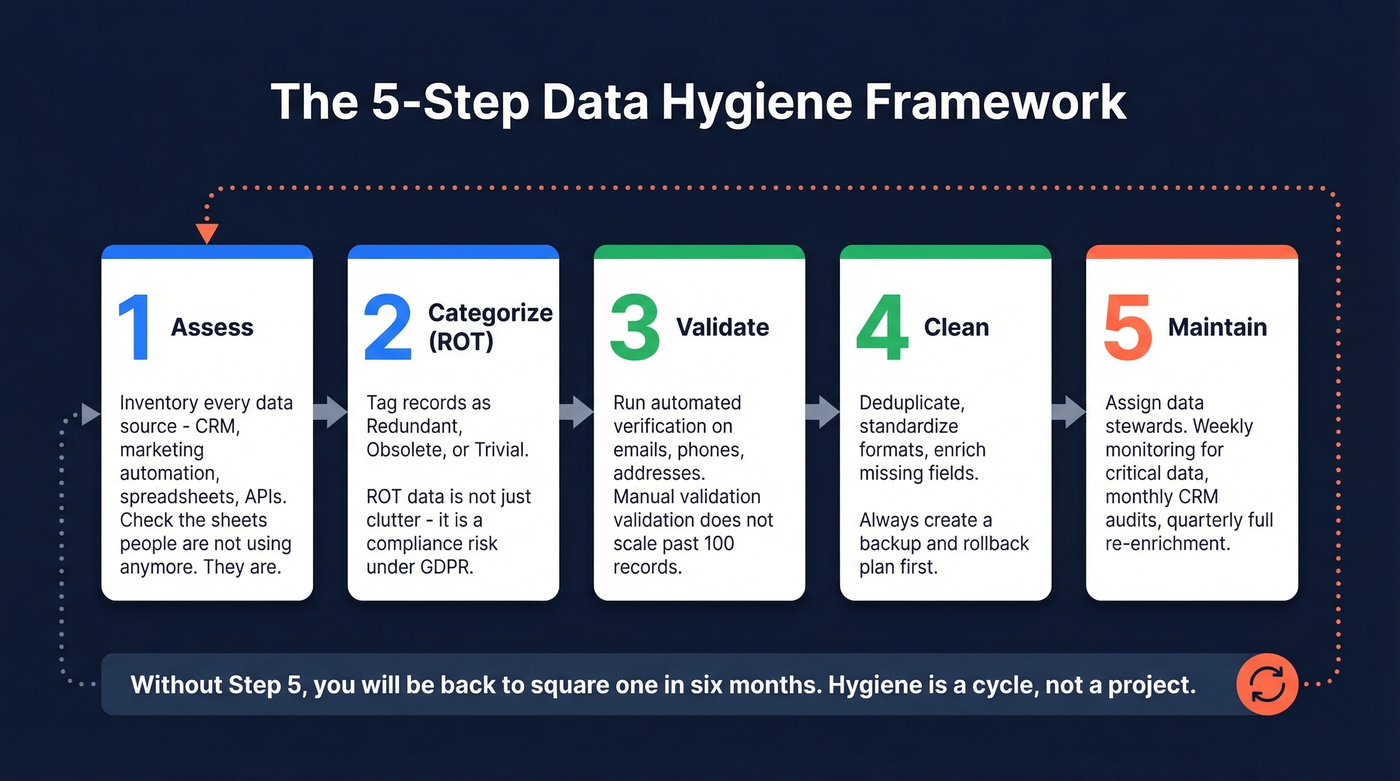
Step 1: Assess
Inventory every data source - CRM, marketing automation, spreadsheets, third-party tools, API integrations. In large organizations, this phase alone can take six months. For a 50-person company, you can do it in a week if you're honest about where data actually lives. Check the spreadsheets people "aren't using anymore." They are.
Step 2: Categorize (ROT)
Tag data as Redundant, Obsolete, or Trivial. Redundant means duplicates. Obsolete means records outdated beyond usefulness. Trivial means data you collected but never use. ROT data isn't just clutter - it's a retention and regulatory risk under GDPR.
Step 3: Validate
Run verification on emails, phones, and addresses. This is where automation pays for itself immediately. Don't try to validate manually - at any meaningful scale, it's impossible. Prospeo handles email verification at 98% accuracy on a 7-day refresh cycle, compared to the 4-6 week industry average, so data you validate today is still reliable next week.
Step 4: Clean
Deduplicate, standardize formats, and fill gaps through enrichment. Create a backup and rollback plan before you touch anything. Archive legally required records to cheaper storage rather than deleting them.
A quick note on terminology: data cleansing is this specific step - fixing what's broken - while data hygiene is the entire five-step cycle that prevents the mess from recurring. They're related but not synonyms.
Step 5: Maintain
Assign data stewards - specific people responsible for specific datasets. Set a cadence: weekly monitoring for critical datasets, monthly audits for CRM contacts, quarterly re-enrichment for the full database. Without ownership and rhythm, you'll be back to square one in six months.
Best Practices for Clean Data
Standardize at the point of entry. Validation rules, required fields, and dropdown menus prevent bad data from entering your system. If reps can free-text a "State" field, you'll get "California," "CA," "Calif," and "ca" in the same database. Lock it down.

Automate verification. Email and phone verification should run automatically on every new record and on a recurring schedule. We've tested dozens of verification workflows, and the teams that automate this step consistently outperform those running quarterly "cleanup sprints." It's not even close.
Enrich proactively. Don't wait for reps to manually research missing fields. Automated enrichment fills in job titles, direct dials, company data, and technographics before anyone has to ask. Incomplete data is dirty data.
Salesforce teams specifically need phone field normalization, email verification, and job-change alerts - automate these rather than relying on reps to update records manually. For event tracking, establish naming conventions and tracking plans so behavioral data stays as clean as your contact records.
For data engineering teams, two practices matter most: quarantine invalid records to a separate table with error metadata instead of silently dropping them, and use idempotent ingestion with stable business keys to prevent duplicates on reprocessing. Set freshness, completeness, and accuracy thresholds with alerting - don't wait for someone to notice sequences are bouncing.
How to Measure Data Hygiene
If you can't put a number on it, you can't improve it. This KPI framework, adapted from Alation's data quality dimensions, gives you concrete targets:
| Dimension | Example Metric | Target (P0 Datasets) |
|---|---|---|
| Completeness | % required fields populated | ≥95% |
| Accuracy | % matching authoritative source | ≥98% |
| Consistency | % conflicting values across systems | <2% |
| Uniqueness | Duplicate record rate | <1% |
| Timeliness | % records updated within SLA | ≥90% |
| Validity | % conforming to format/rules | ≥99% |
These targets are for your most critical datasets - active pipeline, ICP accounts, outbound sequences. Long-tail datasets can run looser thresholds.
Start by measuring completeness and uniqueness. They're the easiest to calculate and usually the most embarrassing. If your duplicate rate is above 5%, no amount of enrichment will fix it until you deduplicate first.
Tools That Help
You don't need a ten-tool stack. You need coverage across four categories.
Email and contact verification. Prospeo gives you 98% email accuracy with a 7-day refresh cycle. The free tier covers 75 emails per month, and paid plans run roughly $0.01 per email with no contracts. For teams that need verified direct dials alongside emails, it's the strongest cost-to-accuracy ratio we've found - and yes, we're biased, but the numbers hold up against independent testing.
CRM-native deduplication. HubSpot Operations Hub (around $800+/mo depending on tier and seats) and Salesforce's built-in duplicate management handle the basics. They won't catch fuzzy matches well, but they prevent the most obvious duplicates from piling up.
Data enrichment. For enterprise-scale enrichment with credit bureau and firmographic data, Experian offers custom-priced solutions. For B2B contact enrichment specifically, look for tools returning 50+ data points per contact with match rates above 80%. If you're comparing vendors, start with a shortlist of data enrichment services and validate match rates on your own sample.
Data pipeline observability. For data engineering teams, dbt (free/open-source, Cloud plans from a few hundred dollars per month) and Great Expectations (open-source) handle contract validation. Monte Carlo (typically $1,000+/mo) adds full observability with anomaly detection and lineage.
Skip this category entirely if you're a team under 20 people - CRM-native tools and a good verification provider will cover you. Pipeline observability only makes sense once you're managing multiple data sources and automated workflows.
If you're still using Excel to clean your CRM, you've already lost. The 65% of companies doing this aren't saving money - they're spending more on manual labor than any tool would cost.
Enrichment is one of the five pillars of data hygiene - and the hardest to do at scale. Prospeo's CRM and CSV enrichment returns 50+ data points per contact with a 92% match rate. Job titles, direct dials, verified emails - every field that decays gets refreshed automatically so your personalization stays accurate.
Fill every gap in your CRM before your next campaign ships.
FAQ
How often should you clean your data?
Weekly for critical datasets like active pipeline, monthly for CRM contacts, and quarterly for full re-enrichment. B2B contact data decays at roughly 22.5% per year, so waiting longer than 90 days between verification passes means you're already sending to stale records.
What's the difference between data hygiene and data cleansing?
Data cleansing is a one-time fix - removing duplicates, correcting typos, updating outdated records. Data hygiene is the ongoing system that includes prevention, validation, enrichment, and monitoring so you never need a massive cleansing project again.
What tools help automate data hygiene?
It depends on your stack size. For email verification and CRM enrichment, Prospeo covers both with 98% accuracy and a 7-day refresh. For deduplication, HubSpot Operations Hub or Salesforce's native tools handle the basics. For pipeline observability, dbt, Great Expectations, or Monte Carlo add automated alerting - but only invest here once you're managing multiple data sources.
Do I need a formal data hygiene checklist?
Yes. Even a simple five-step checklist - source inventory, ROT categorization, validation, cleaning, and ongoing maintenance - keeps your team accountable. Without documented ownership and cadence, hygiene tasks get deprioritized until bounce rates spike or a campaign fails. I've watched it happen at three different companies before we finally built the process right.