Why Lead Scoring Matters (And Why Yours Probably Isn't Working)
Your SDR just spent 45 minutes researching a grad student who scored 85 - she'd downloaded three whitepapers and attended a webinar. Meanwhile, a VP of Engineering at a target account sat at 32 because he visited the pricing page once and didn't open a nurture email. That's not a lead scoring problem. That's a trust problem. And once sales stops trusting the model, they stop using it.
Understanding why lead scoring is important starts here: it's supposed to stop your reps from chasing dead leads. Most implementations do the opposite.
Separate fit, engagement, and timing into distinct layers. Start simple. Feed the model clean, verified data. Everything else is decoration.
The Real Benefits of Lead Scoring
Companies using lead scoring see roughly 30% higher close rates - a benchmark cited across the industry for over a decade. But the benefits go well beyond that single metric.
Grammarly used AI-driven lead scoring and saw an 80% increase in plan upgrade conversions, with their sales cycle dropping from 60-90 days to 30. U.S. Bank's commercial banking division saw a 260% lift in lead conversion after deploying predictive scoring, with 4x more rep time spent on qualified leads. HES FinTech saw 40% more loans each week after layering AI scoring into their pipeline.
Beyond conversion, scoring aligns marketing and sales around a shared definition of "qualified." Without it, marketing celebrates MQL volume while sales complains about quality. With scoring, both teams argue about the model instead of each other - and honestly, that's progress. When you look at lead scoring ROI across these case studies, the pattern is clear: even modest implementations pay for themselves within a quarter.
Why Most Models Fail
Most scoring models look great in the planning doc and fall apart within a few months. On r/hubspot and r/b2bmarketing, lead scoring is often described as something that "feels like guesswork." They're not wrong.

Engagement doesn't equal intent. The grad student problem isn't hypothetical. High-engagement non-buyers routinely outscore real buyers who skip content and go straight to a demo request.
The second failure is subtler: single-score opacity. When everything collapses into one number, reps can't tell why a lead scored 78. Is it a great-fit company with low engagement, or a terrible-fit person who clicked everything? Reps revert to gut feel, and the model becomes decoration.
Then there's the maintenance problem. Teams build the model once and never recalibrate. Scoring logic becomes tribal knowledge nobody documents. Meanwhile, they're assigning "webinar = 20 points, whitepaper = 15 points" without distinguishing a "2026 Trends" overview from a bottom-of-funnel vendor comparison guide. Same format, completely different intent.
Here's the thing: if your MQL-to-SQL conversion rate is below 20%, you're sending unready leads to sales and burning trust. Raise the bar. And if 10% of your emails bounce and job titles are six months old, your scores are fiction regardless of how clever the model is.
If you're seeing bounce issues, start by tracking your email bounce rate and fixing the data layer first.
If 10% of your emails bounce and job titles are stale, your scoring model is grading ghosts. Prospeo's CRM enrichment returns 50+ data points per contact at a 92% match rate - with a 7-day refresh cycle so the firmographic data feeding your scores never goes stale.
Stop scoring leads that don't exist. Start with verified data.
How to Build a Model Sales Trusts
Separate Fit From Behavior
The best framework we've seen decomposes scoring into three layers: right company (firmographics), right person (title, seniority, buying role), and right time (engagement signals indicating active buying). Use a letter grade for fit (A through D) and a number for engagement (1 through 4). An A1 lead is a perfect-fit decision-maker showing strong buying signals. A D4 gets disqualified. Everything in between gets a nurture track calibrated to the gap.
If you need a starting point for fit rules, use an ideal customer profile template before you assign points.
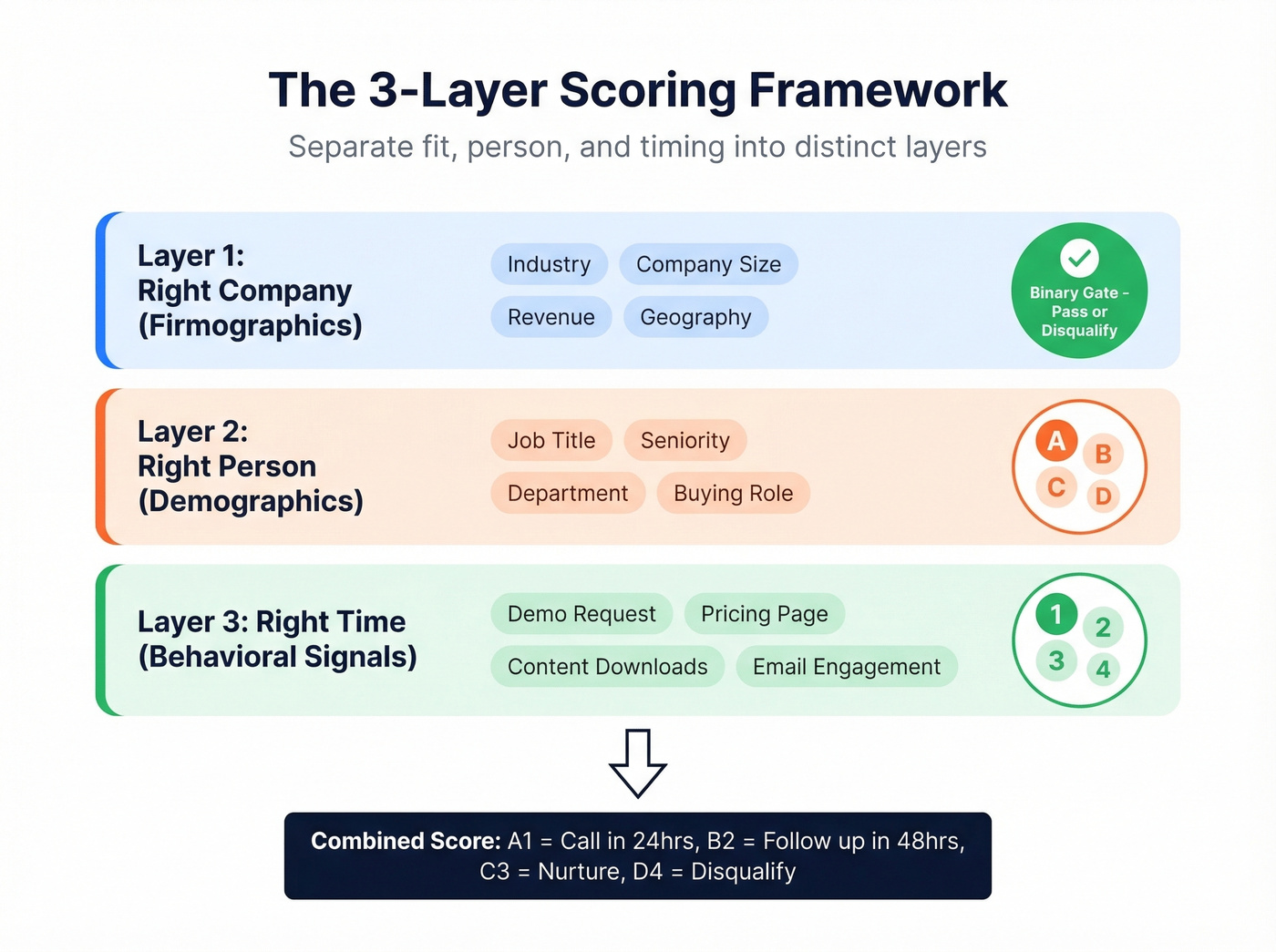
Non-negotiable fit criteria should be binary gates, not point values. Wrong industry? Out. Company too small? Out. No amount of webinar attendance overcomes a fundamental fit mismatch.
Tie SLAs to score tiers so reps know exactly when to act. A1 leads get a call within 24 hours. B2 leads get a 48-hour follow-up window. Without time-bound routing, even good scores sit in a queue and go cold.
To make those SLAs actionable, keep a set of sales follow-up templates ready for each tier.
A Starter Scorecard
Before you assign a single point value, audit your CRM data quality. If more than 10% of your emails bounce or job titles are outdated, your scores will be wrong from day one. We've used Prospeo's CRM enrichment for this - it returns 50+ data points per contact with a 92% API match rate, so you're scoring leads that actually exist at the companies you think they work for.
If you're evaluating vendors for this step, compare data enrichment services and pick one that refreshes frequently.
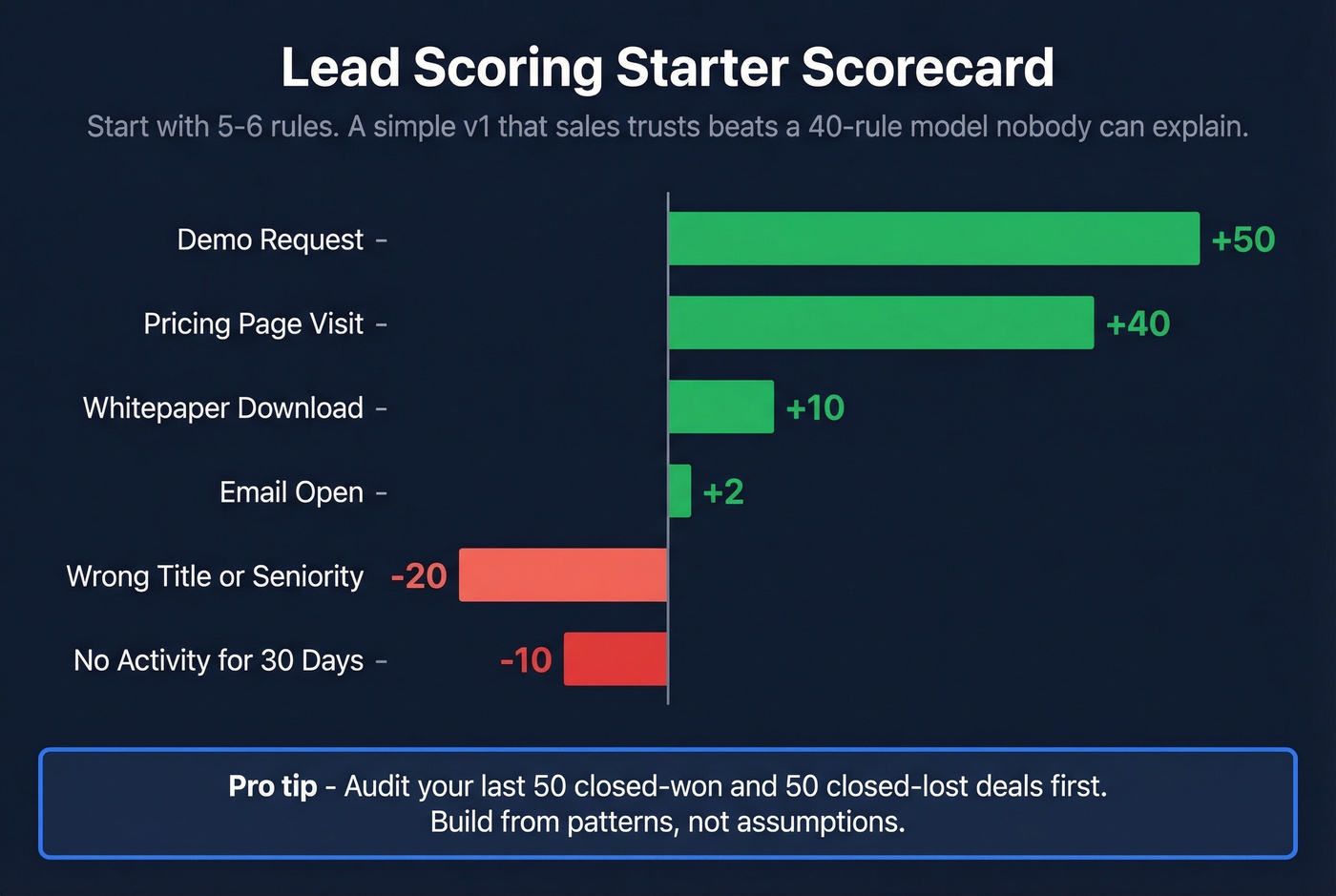
Then review your last 50 closed-won and 50 closed-lost deals. Build your v1 from those patterns, not assumptions.
| Action | Points |
|---|---|
| Demo request | +50 |
| Pricing page visit | +40 |
| Whitepaper download | +10 |
| Email open | +2 |
| Wrong title/seniority | -20 |
| No activity 30 days | -10 |
Start with five or six rules. A stupidly basic v1 that sales understands beats a 40-rule model nobody can explain. One team at Sponge.io saw their MQL-to-meeting rate jump 13% just by tightening title and seniority filters.
Keep It Alive
Scores decay. Job titles go stale in 3-6 months. Content interactions lose relevance after about 30 days. Event participation fades after about 60. Build decay rules into your model and refresh underlying data regularly - a 7-day data refresh cycle (what Prospeo runs, compared to the 6-week industry average) means the firmographic and contact data feeding your model stays current without manual re-verification.
If you want to formalize the "right time" layer, use a checklist for identifying buying signals so the model reflects real intent.
In our experience, teams that skip straight to predictive scoring without cleaning their data waste 3-6 months learning that lesson the hard way. For iteration cadence: weekly tweaks during the first month, then quarterly reviews aligned with QBRs. If you sell multiple products or serve distinct personas, build separate models for each rather than forcing one model to do everything.
Scoring at Scale: Manual vs. Predictive
Manual scoring works well when you're processing under roughly 500 leads per month. Most CRMs support it natively.
If you're building this into your stack, it helps to map scoring to your lead status definitions so routing and reporting stay consistent.
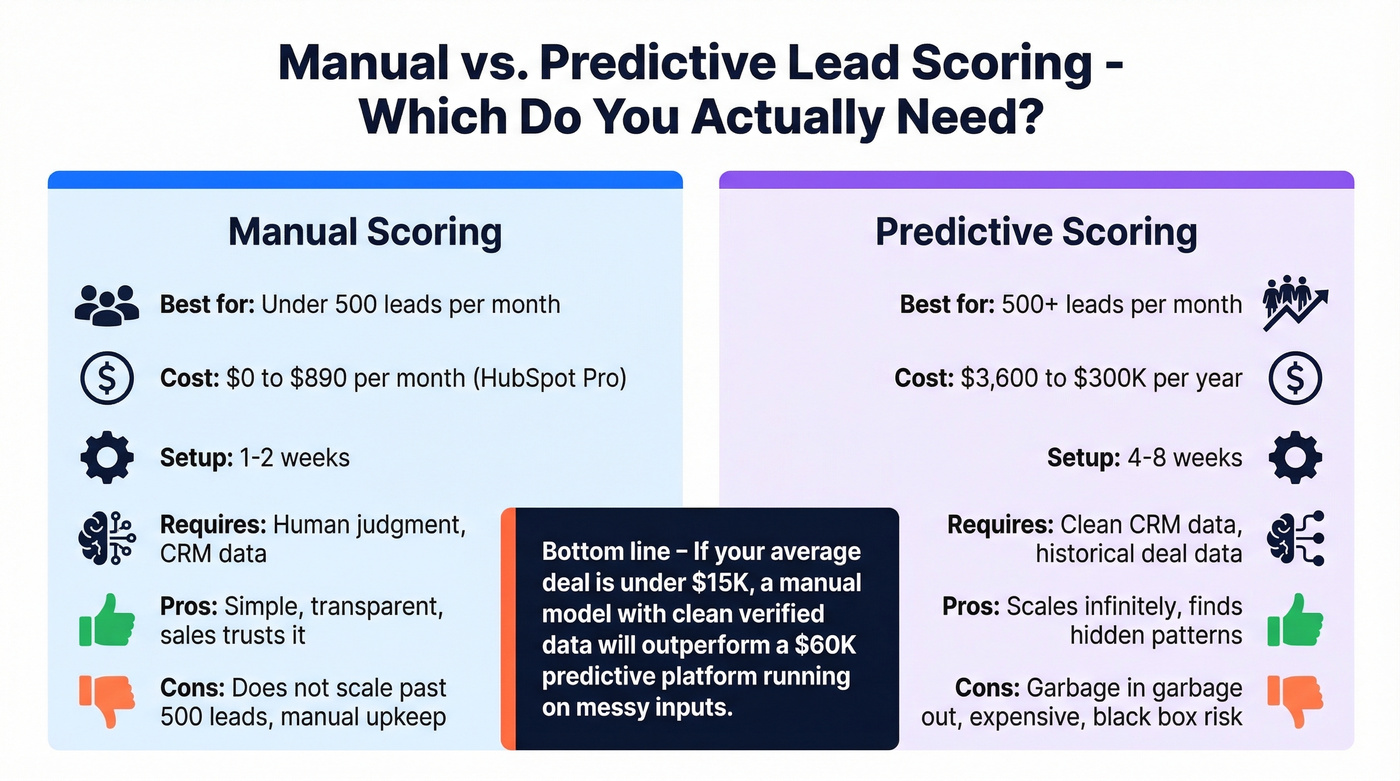
Predictive scoring becomes necessary at scale. A peer-reviewed study in Frontiers in AI tested 15 classification algorithms on real B2B CRM data and found Gradient Boosting outperformed everything else. The most predictive features? Lead source and lead status - not the behavioral signals most marketers obsess over.
| Platform | Scoring Type | Price | Best For |
|---|---|---|---|
| HubSpot Pro | Manual (predictive on Enterprise) | ~$890/mo (3 seats) | SMBs under 500 leads/mo |
| HubSpot Enterprise | Predictive | ~$3,600/mo (10 seats) | Mid-market teams wanting native AI |
| Salesforce Einstein | Predictive | ~$165 + $50/user/mo | Teams already on Salesforce |
| 6sense | Predictive + intent | $60K-$300K/yr | Enterprise with ABM programs |
Let's be honest: most SMBs don't need AI scoring. They need a clean, simple model and clean data. Predictive scoring on top of a messy CRM just gives you confidently wrong answers faster. If your average deal size is under roughly $15k, a manual model with verified data will outperform a $60K predictive platform running on garbage inputs every single time. Skip the enterprise tools until your basic model is already working and you've outgrown it.
If you're considering predictive approaches, it's worth understanding B2B predictive analytics before you buy a platform.
The article above makes it clear: clean data beats clever models every time. Prospeo gives you 98% email accuracy, verified job titles, and contacts refreshed every 7 days - not every 6 weeks. That means your A1 leads are actually A1 leads.
Fix your data layer and watch your scoring model finally work.
FAQ
What's a good MQL-to-SQL conversion rate?
Below 20% means your threshold is too low - you're flooding sales with unqualified leads. Aim for 25-40%, then optimize based on sales capacity and rep feedback. Track this metric monthly and adjust scoring thresholds accordingly.
How often should you recalibrate your scoring model?
Weekly during the first month of deployment, then quarterly aligned with QBRs. At each review, compare predicted scores against actual closed-won and closed-lost outcomes. Models that go six months without recalibration typically see a 15-20% drop in accuracy.
Can you do lead scoring without expensive software?
Yes. HubSpot Professional and Salesforce both support manual scoring out of the box. Start with five or six criteria, verify your contact data with a tool like Prospeo (75 free credits/month), and upgrade to predictive only after the basic model proves itself.
Why does lead scoring matter more for small teams?
Small teams feel the cost of wasted outreach more acutely than enterprise orgs. When you only have two or three reps, every hour spent on a bad-fit lead is an hour not spent closing revenue. A lightweight scoring model ensures those limited hours go toward the highest-potential opportunities first.