Deal Scoring AI: How It Works, What It Costs, and Why Most Implementations Fail
It's Thursday afternoon. Your CRO pulls up the pipeline review, and half the "commit" deals haven't had a buyer reply in two weeks. The rep swears they're closing this quarter. The forecast says otherwise - or it would, if anyone trusted the forecast.
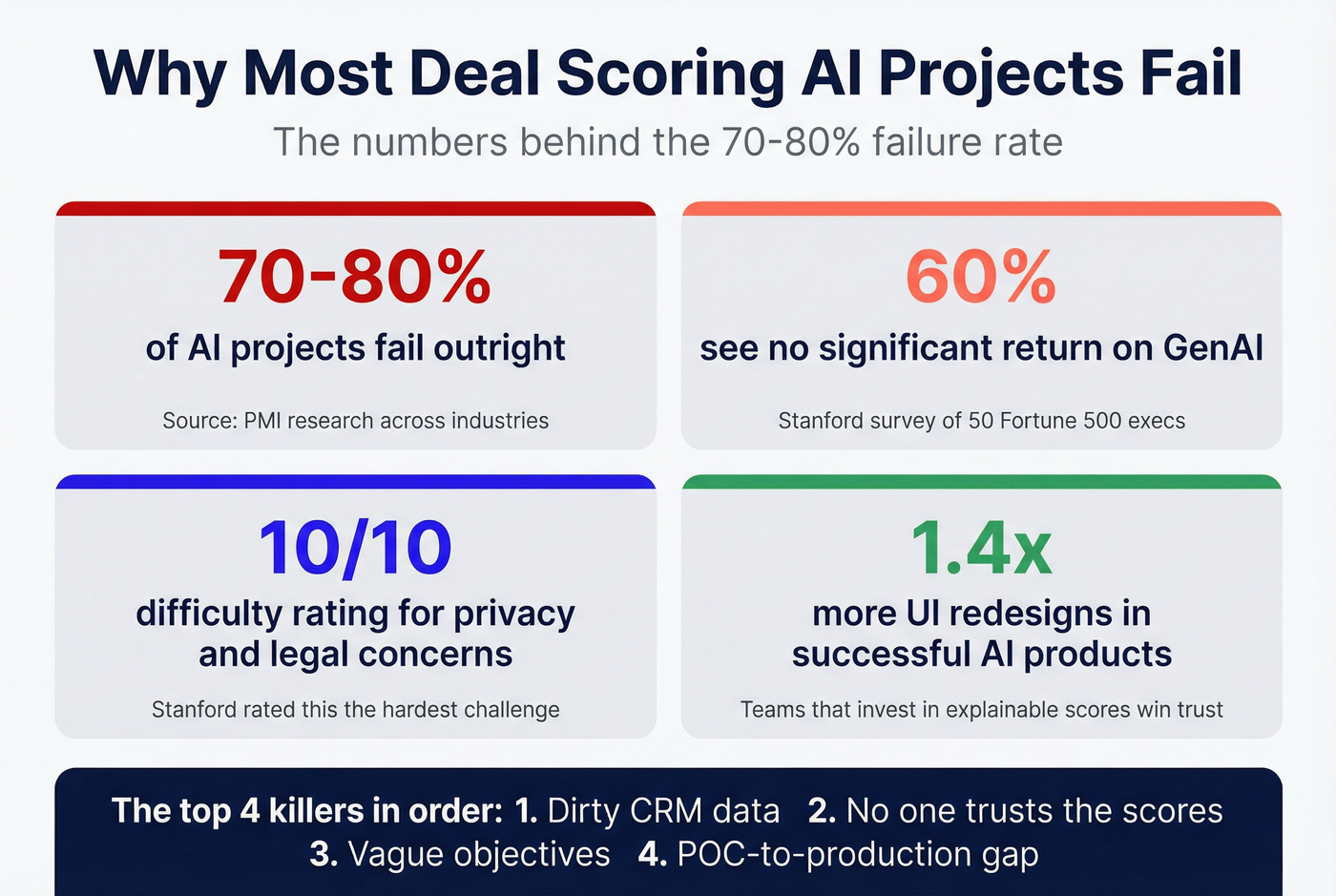
This is the exact problem deal scoring AI solves, and for some teams, it genuinely does. But 70-80% of AI projects fail, and scoring initiatives aren't immune. Companies using AI-enabled sales platforms report 30% higher win rates - but only when the implementation sticks. Teams using AI-powered forecasting stay within 3-4% of actual numbers every quarter. The gap between those outcomes and the 70% failure rate? Entirely about execution.
Here's the short version: if you're on HubSpot Sales Hub Pro or Enterprise, turn on native deal scoring first - it's included and genuinely good. If you need conversation intelligence layered with scoring, budget $70-95K/year for Clari or $88.5-121K/year for Gong at 50 users including Year 1 implementation. And before you buy anything, audit your CRM data. AI scoring amplifies bad data. It doesn't fix it.
What AI Deal Scoring Actually Is
AI deal scoring assigns a quantitative score to every open opportunity in your pipeline, predicting how likely it is to close. The nuance is in what kind of score you're getting, because not all deal scores work the same way.

There are three common score types. A win probability gives you a percentage - HubSpot's deal score, for example, tells you a deal has an 85% chance of closing. A percentile rank tells you how this deal compares to others in your pipeline: top 10%, bottom quartile. And a health grade flags whether a deal is on track, stalling, or at risk based on engagement patterns - closer to what Gong, Clari, and Data Parrot surface. Gong explicitly warns that its Deal Predictor score is a percentile rank, not a win probability. Most teams miss that distinction when comparing tools.
Don't confuse deal scoring with lead scoring or forecast AI. Lead scoring evaluates prospects before they enter the pipeline - should you pursue this person? Deal scoring evaluates opportunities already in motion - will this deal actually close? Forecast AI aggregates deal scores into a roll-up prediction for the quarter. They're related but distinct, and most CRMs treat them as separate models with entirely different signal inputs.
Signals the AI Evaluates
The inputs vary by platform, but they generally fall into five dimensions: stakeholder engagement, business impact, financials, readiness, and risk. That framework comes from Ricavvo's deal scoring methodology, and it's a clean way to think about what the model actually weighs.
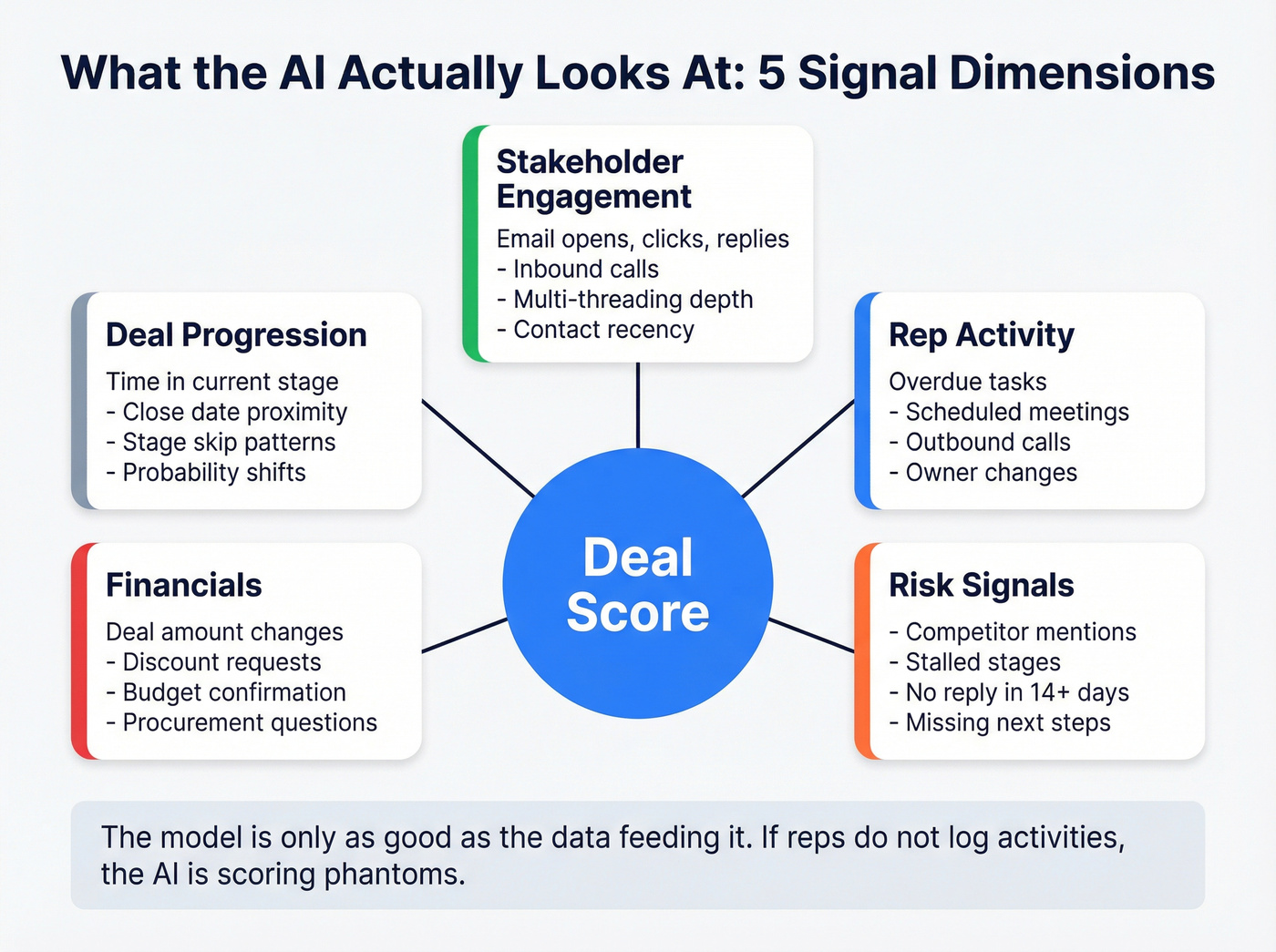
HubSpot publishes the most transparent signal list, so it's the best reference point:
- Deal properties: deal amount and changes to it, close date proximity, time since creation, time in current stage, deal probability shifts
- Rep activity: overdue tasks, scheduled meetings, outbound call activity, time without an assigned owner, owner changes
- Buyer engagement: email opens, clicks, and replies; inbound call activity; time since last contact
- Deal progression: whether the deal is stalling without engagement, time since the "next step" field was updated
The more sophisticated platforms - Gong, Clari, Data Parrot - add conversation intelligence signals on top of CRM data. They analyze call sentiment, multi-threading depth across stakeholders, competitor mentions, and whether the buyer is asking procurement-stage questions or still in discovery. Gong's model draws on 3.5B+ sales interactions, giving it pattern-matching depth that a CRM-only model can't replicate.
Here's the thing: the model is only as good as the data feeding it. If your reps don't log activities, don't update deal stages, and don't associate contacts to opportunities, the AI is scoring phantoms.
What It Actually Costs in 2026
This is where most articles get vague. Let's not. Here's what a 50-user team should expect to pay in Year 1, including implementation costs that vendors conveniently leave off the pricing page.
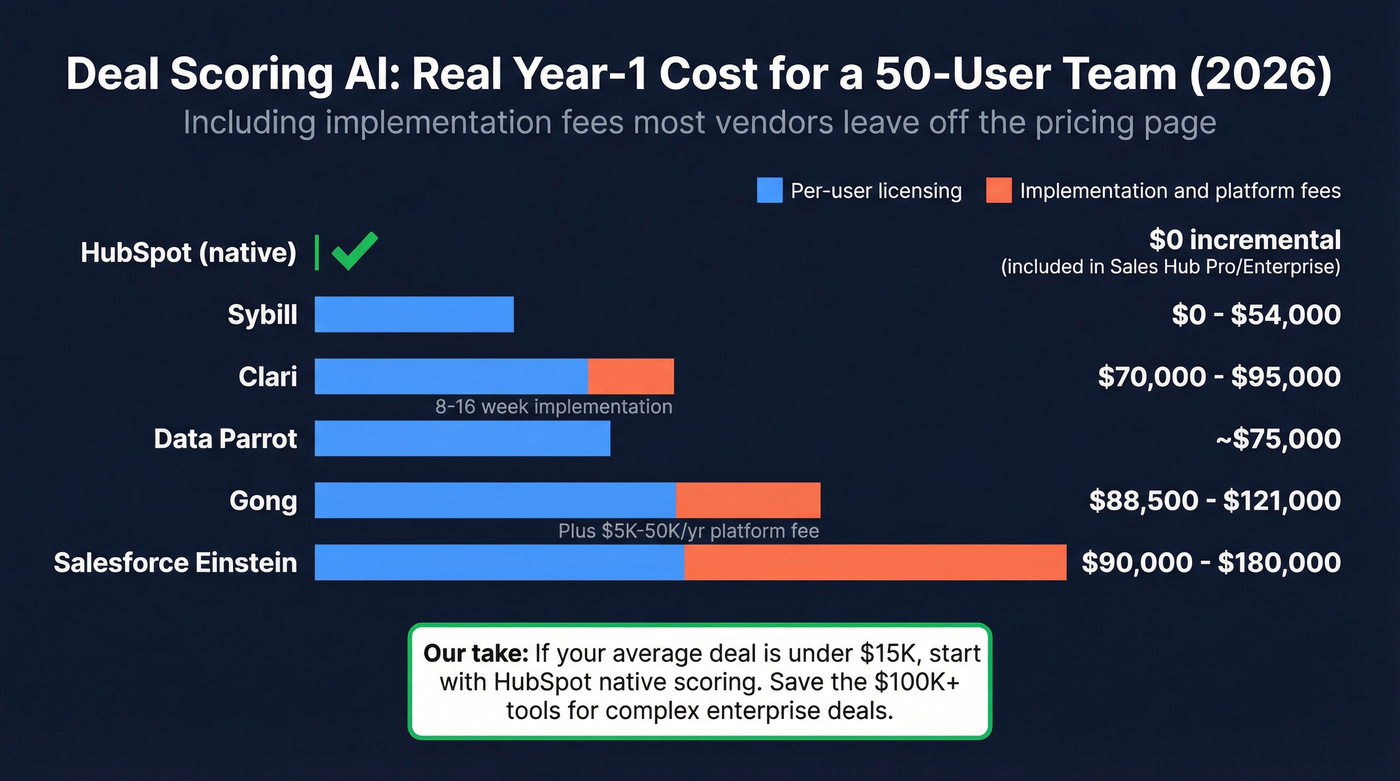
| Tool | Per-User Cost | Platform/Implementation Fees | Year-1 TCO (50 users) | Best For |
|---|---|---|---|---|
| HubSpot (native) | $100-250/seat/mo | None | Included in spend | Teams already on HubSpot |
| Sybill | $0-90/user/mo | None | $0-54,000 | Budget-conscious teams |
| Clari | $100-125/user/mo | $15K-75K implementation | $70,000-95,000 | RevOps-heavy orgs |
| Gong | $160-250/user/mo | $5K-50K/yr platform fee | $88,500-121,000 | Conversation intel |
| Salesforce Einstein | $150-300/user/mo | Often bundled as Enterprise add-on | $90,000-180,000 | SF-native orgs |
| Data Parrot | Enterprise pricing | Included | ~$75,000 | Deal health focus |
A few things jump out. HubSpot is the obvious starting point if you're already paying for Sales Hub Pro or Enterprise - deal scoring is baked in, no incremental cost. For most mid-market teams, this is the right first move. Sybill is the budget play, with a genuinely free tier and paid plans topping out at $90/user/month. AEs using Sybill report saving 4-6 hours per week on CRM data entry automation, which is where the real ROI lives for smaller teams.
Gong and Clari are the enterprise options, and the gap between sticker price and actual cost is significant. Clari's implementation fees run $15K-75K with 8-16 week timelines. Clari self-reports 448% ROI and 15% faster deal cycles, though those numbers come from their own customer base, not independent benchmarks. Gong layers a platform fee ($5K-50K/year) on top of per-seat costs. Gong users on Gartner Peer Insights rate it 4.8/5 but flag missed call recordings and navigation complexity as friction points - issues that compound when you're relying on conversation data for deal scores.
The Clari-Salesloft merger reported in late 2025 combined roughly $450M in ARR, so expect their packaging to evolve through 2026. Gartner also published its first Magic Quadrant for Revenue Action Orchestration in late 2025, signaling that deal scoring is maturing from a feature into a category.
For context, the average B2B sales team runs 8.3 tools at $187/rep/month, and 73% report overlap waste costing $2,340/rep/year. Adding another $100+/seat tool without consolidating something else is how you end up spending $500/user annually on revenue intelligence alone. (If you're trying to rationalize spend, start with a sales tech stack audit.)
Our take: if your average contract value is under $15K, you probably don't need Gong or Clari-level scoring. HubSpot's native model plus clean CRM data will get you 80% of the value at 0% of the incremental cost. The teams that genuinely need $100K+ platforms are running complex, multi-stakeholder enterprise deals where a single missed signal costs six figures. Skip the enterprise tools if that's not you.
You just read it: AI scoring amplifies bad data - it doesn't fix it. If your CRM is full of outdated contacts and unverified emails, no $100K platform will save your forecast. Prospeo refreshes 300M+ profiles every 7 days with 98% email accuracy, so your deal scores are built on contacts that actually exist.
Clean data in, accurate scores out. Start with Prospeo's free tier.
Why Most Implementations Fail
70-80% of AI projects fail. A Stanford survey of 50 Fortune 500 executives found that over 50% of GenAI initiatives miss their operational goals, with roughly 60% seeing no significant return. Stanford rated privacy and legal concerns as 10/10 difficulty, getting the UI right as 9/10, and managing expectations as 8/10. Deal scoring AI fails for the same reasons every other AI initiative does, just with sales-specific flavors.

Dirty data kills more projects than bad tools
If 30% of your contact emails bounce, deals sit in the wrong stages for weeks, and activity logs are sparse because reps hate manual data entry, the scoring model is training on ghost data. In our experience, the teams that get the most from AI scoring are the ones that spend the first month on CRM hygiene cleanup, not tool evaluation. We've seen teams activate scoring only to discover that their "high-confidence" deals were scored based on contacts who'd left the company six months ago.
This is where upstream data quality becomes non-negotiable. Prospeo's CRM enrichment returns 50+ data points per contact at an 83% enrichment match rate, with 98% email accuracy and a 7-day refresh cycle. One customer, Snyk, had bounce rates of 35-40% before enrichment - after cleanup, bounces dropped under 5%. When the contacts feeding your scoring model have verified data, the engagement signals the model relies on actually mean something. (If you're troubleshooting bounces, see our guide to invalid emails.)
Nobody trusts the scores
This one's more insidious. A rep sees a deal scored at 40% that they "know" is going to close. The score turns out wrong once, and they never look at it again. Stanford's research found successful GenAI products redesigned their UI 1.4x more often than traditional products - scoring tools that don't invest in explainable interfaces get ignored. HubSpot shows key factors behind each score, which helps. Gong's approach of tying scores to specific conversation signals builds more trust than a black-box number.
Vague objectives doom the rollout
"We need AI for our pipeline" isn't a goal. "We want to reduce forecast variance from +/-15% to +/-5% within two quarters" is. Without a measurable target, you can't tell if the tool is working, and you definitely can't justify the renewal. RevOps communities on Reddit consistently cite vague objectives as the second-biggest blocker for AI scoring adoption, right behind CRM hygiene.
The POC-to-production gap
A pilot with 10 reps and clean demo data looks great. Rolling it out to 200 reps with inconsistent CRM hygiene across five regions is a different animal entirely. Clari's 8-16 week implementation timeline exists for a reason. Teams that skip change management - training reps on what the scores mean, when to override them, and how to feed the model better data - end up with expensive shelfware.
How to Roll It Out Without Wasting $85K
Step 1: Audit and clean your CRM data. Before you activate any scoring model, run an enrichment pass on your contacts and accounts. This single step prevents the number-one failure mode. If 20% of your contact records have stale emails or missing job titles, the scoring model starts with a handicap it can never overcome. (If you need a process, start with a CRM verify workflow.)

Step 2: Start with what you have. If you're on HubSpot Sales Hub Pro or Enterprise, turn on native deal scoring. It generates initial scores within 36-48 hours of deal creation and updates within 6 hours when scores shift +/-3%. One limitation worth knowing: reopened deals don't receive scores - you'll need to create a new deal instead.
Step 3: Set a minimum data threshold. Most platforms need 100-200 closed deals, both won and lost, before the model produces reliable scores. Gong requires sufficient won/lost deal volume before its Deal Predictor even activates. If you don't have that history, start logging rigorously now and revisit scoring in a quarter.
Step 4: Train your team on what scores mean - and what they don't. A deal score isn't a mandate. It's a signal. Reps should know how to interpret scores, when to challenge them, and what actions to take when a score drops. The teams that get value from deal scoring AI are the ones where managers use scores in coaching conversations, not as gotcha metrics. (If you're building the manager motion, use a sales coaching cadence.)
Step 5: Calibrate continuously. Review scoring accuracy quarterly. Compare predicted outcomes to actual close rates. If the model consistently overscores deals in a specific segment or region, flag it. AI models drift - especially when your market, product, or sales motion changes. The best dynamic scoring systems recalibrate as new closed-won and closed-lost data flows in, but even they benefit from a human review cadence. (This is also where deal forecast accuracy work pays off.)
Before you spend $70-121K on Clari or Gong, fix the input layer. Deal scoring models weigh buyer engagement, stakeholder depth, and rep activity - all of which depend on having real, verified contacts associated to every opportunity. Prospeo enriches your CRM with 50+ data points per contact at 92% match rate for $0.01/email.
Stop scoring phantom deals. Enrich your pipeline with contacts that pick up.
Common Questions About Deal Scoring AI
How is deal scoring different from lead scoring?
Lead scoring evaluates prospects before they enter the pipeline - it answers "is this person worth pursuing?" Deal scoring evaluates opportunities already in motion - it answers "will this deal close?" Most CRMs run them as separate models with different signal inputs, so don't assume one replaces the other.
How much historical data does AI deal scoring need?
Most platforms require 100-200 closed deals, won and lost, before producing reliable scores. HubSpot generates initial scores within 36-48 hours, but accuracy improves with more historical outcomes. Gong requires sufficient won/lost volume before its Deal Predictor activates at all.
Can deal scoring AI work with bad CRM data?
It'll generate scores, but they'll be unreliable - potentially worse than no scores at all because they create false confidence. Cleaning your CRM data before activating scoring is the single highest-ROI step you can take.
What makes dynamic scoring different from static scoring?
Static scoring assigns a number when a deal enters a stage and doesn't update until the rep manually moves it. Dynamic scoring continuously recalculates based on real-time signals - new emails, call sentiment shifts, stakeholder changes, stalled engagement. A deal that looked strong last week can drop today if the champion goes silent, giving managers early warning they'd otherwise miss entirely.
