How B2B Data Is Actually Collected: A Technical Breakdown of Every Method
70% of CRM data is outdated, incomplete, or inaccurate. That's not a scare stat from a vendor pitch deck - DealSignal found this when they audited real databases, and most B2B data providers deliver only 50% accuracy on average. Every "best data tools" article tells you what B2B data is. Almost none explain how it's actually collected. That matters, because the collection method determines whether the email you're about to send reaches a human or bounces into the void.
B2B data is assembled through eight core methods - scraping, email patterning, SMTP verification, contributor networks, reverse IP lookup, intent data collection, data partnerships, and first-party collection. Most providers use two or three. The quality gap between them doesn't come from which methods they use. It comes from how they verify and how often they refresh.
The one question that matters more than database size: what's the verification process and refresh cycle?
A Brief History of B2B Data Collection
Before 2003, B2B data meant business cards. Companies hired interns to sit in conference rooms and type card data into CRMs. That was the state of the art.
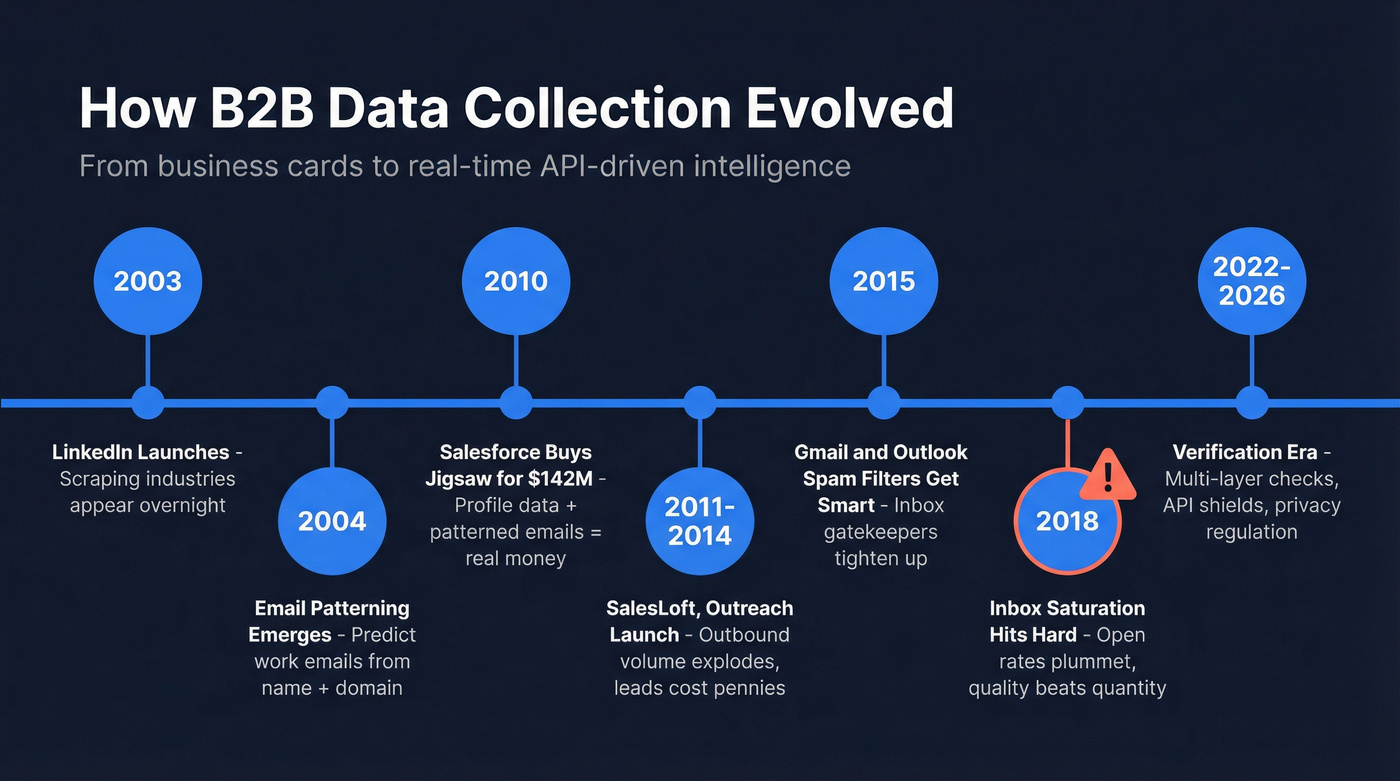
Then LinkedIn launched. Overnight, scraping industries appeared. Bots harvested names, titles, and company info from profiles at massive scale. Around 2004, email patterning emerged - using a person's name plus their company domain to predict their work email. Jigsaw pioneered commercial email patterning, and in 2010, Salesforce acquired them for $142 million. That acquisition signaled something important: paired profile data plus patterned emails was worth real money.
The formula for a basic B2B data company crystallized into three ingredients: a scraper, an email patterning engine, and SMTP email verification. SalesLoft launched in 2011, Outreach in 2014, and dozens of others emerged alongside them to manage the outbound volume this data enabled. Supply skyrocketed. You could buy B2B leads for pennies rather than dollars. Data delivery shifted from static CSV files to real-time, API-driven sales intelligence platforms - a shift that fundamentally changed how teams consumed and acted on contact data.
By 2018, inbox saturation hit hard. Open and response rates plummeted. Gmail and Outlook spam filters had grown sophisticated around 2015, and the sheer volume of cold email meant that data quality - not just data quantity - became the differentiator. The providers that survived were the ones that invested in verification infrastructure. The ones that didn't are the reason 70% of CRM data is garbage today.
The Eight Methods Behind B2B Data Collection
Web Scraping and Crawling
Web scraping is the foundation of nearly every B2B contact database. Automated programs visit public web pages and extract structured data - names, titles, company info, contact details - from professional profiles, news articles, financial filings, job postings, and corporate websites.

ZoomInfo's approach is a good case study. Their crawlers continuously scan public websites, press releases, corporate filings, and job boards. This is particularly effective for finding senior decision-makers who don't maintain active social profiles but appear in SEC filings, patent databases, and press releases. The crawlers run 24/7, building a constantly updating picture of the professional world.
The legality is murkier than most providers admit. In hiQ Labs v. LinkedIn, the court ruled that scraping publicly available data doesn't violate the Computer Fraud and Abuse Act. In Ryanair v. PR Aviation, Ryanair lost because their browsewrap terms weren't enforceable - scraping free public flight data was fair game. But Meta v. Octopus went the other direction: Meta successfully sued scraping services for violating platform terms.
The practical rule: scraping public, non-personal business data is generally legal. Scraping behind logins, bypassing access controls, or collecting personal data without a legal basis crosses the line. Microsoft's Bing famously scraped search results from Google to improve its own product. When caught, VP Harry Shum's response was telling: "Everyone does this."
Best practices that keep scrapers on the right side: respect robots.txt, throttle request rates, use official APIs where available, and avoid personal data without a valid legal basis under GDPR or CCPA.
Email Patterning and Prediction
Once you know someone's name and company domain, you can predict their email address with surprising accuracy. The most common business email pattern - first@domain - accounts for 49.9% of all business emails.

Here's how the detection works: find one confirmed employee email at a company, and you've cracked the format for the entire organization. If a press release lists sarah.martinez@acme.com as a media contact, you now know Acme uses firstname.lastname@domain. Apply that pattern to every other employee, and you've got a working email list without ever scraping an inbox.
| Pattern | Example | Approx. Frequency |
|---|---|---|
| first@domain | sarah@acme.com | ~49.9% |
| first.last@domain | sarah.martinez@acme.com | ~25% |
| flast@domain | smartinez@acme.com | ~10% |
| firstlast@domain | sarahmartinez@acme.com | ~5% |
| first_last@domain | sarah_martinez@acme.com | ~4% |
| firstl@domain | sarahm@acme.com | ~3% |
Other non-standard patterns account for the remainder.
There's even a low-tech trick that still works: type a guessed email into Gmail's "To" field and hover over it. If a profile card appears with a name and photo, the email is valid. It works because many work emails connect to Google accounts.
Accuracy drops significantly for startups and small companies with non-standard formats. For mid-to-large enterprises, the first.last@ pattern is correct roughly 60-70% of the time. For a 15-person startup using custom aliases? You're guessing. One sole proprietor on Reddit described manually checking Hunter.io results against company websites and finding the "A-grade" emails were often wrong - a common experience when patterning accuracy isn't backed by real verification.
That's why patterning alone is never enough.
SMTP Verification
SMTP verification is how data providers confirm that a predicted email address actually exists - without sending a single email. Here's the five-step process:

Step 1 - DNS/MX Lookup. The verifier queries DNS for the recipient domain's MX (mail exchange) records. These records point to the mail servers responsible for receiving email. No MX records? The domain can't receive mail.
Step 2 - TCP Connection. The system connects to the mail server, typically on port 25 (standard SMTP), 587 (submission), or 465 (secure SMTP).
Step 3 - SMTP Handshake. The system sends three commands: EHLO (hello, I'm a mail server), MAIL FROM (here's who I am), then RCPT TO with the target email address. That RCPT TO command is the probe - it asks the server, "Would you accept mail for this address?"
Step 4 - Response Codes. The server responds with a code. 250 means "valid, I'll accept mail for this address." 550 means "permanent rejection, this mailbox doesn't exist." 450 or 421 means "temporary issue, try again later" (often greylisting).
Step 5 - Labeling. Results get categorized: valid, invalid, temporary, catch-all (accepts everything), or unknown. The connection closes. No email was ever sent.
Why SMTP Alone Isn't Enough in 2026
Three developments have degraded SMTP-only verification:

Ghost seats. Companies suspend or deactivate accounts during layoffs without deleting the mailbox entry. SMTP returns "valid," but no human reads that inbox. This accelerated dramatically through 2024-2025 as tech layoffs cascaded.
Catch-all defense layers. More enterprises configure gateways to respond "valid" to every RCPT TO command. Security teams prefer accepting everything and filtering internally, which prevents directory harvest attacks - but also makes verification useless.
API privacy shields. Google and Microsoft have tightened public-facing endpoints. An email can "exist" in the system but never have been initialized - created but never logged into.
The result: traditional SMTP-only validation carries a 22-28% false positive rate depending on industry vertical. After implementing multi-layer activation checks - probing Autodiscover endpoints, checking OAuth session history - that false positive rate drops to 8-12%. But most providers still rely on basic SMTP alone.
Contributor Networks and Data Exchanges
This is the method that makes privacy advocates nervous - and the one you should think hardest about before relying on.
ZoomInfo's Community Edition is the textbook example: users get free or discounted platform access in exchange for sharing their professional contacts. The browser extension analyzes email signatures, captures business card information, and identifies professional relationships from the user's inbox. The scale is significant - ZoomInfo sends tens of millions of notification emails annually to people whose data has been added.
The legal basis? ZoomInfo relies on "legitimate interest" under GDPR rather than explicit consent. They hired Simon McDougall - formerly of the UK's ICO (the data protection authority) - as their first Chief Compliance Officer in early 2022. That hire tells you something about the regulatory pressure they're feeling.
Use this model if you need massive scale and accept the ethical trade-offs. Skip it if you're selling into privacy-conscious European markets where "legitimate interest" is being scrutinized more aggressively every year.
Reverse IP Lookup and Visitor Identification
96% of B2B website visitors leave without sharing contact info. Reverse IP lookup tries to recover some of that lost intent by matching visitor IP addresses to corporate networks.
The technology works in two tiers:
- Company-level identification uses reverse IP lookup to associate a visitor's IP with a corporate network - tools using multi-source data models can identify over 75% of anonymous visitors at the account level.
- Person-level identification goes further, using identity graphs and device tracking to pinpoint individuals. RB2B resolves 70-80% of U.S.-based website traffic into individual profiles.
Global match rates run 40-60%, climbing to 80% for U.S. traffic. But here's the challenge nobody talks about enough: nearly half of B2B traffic now comes from remote or non-corporate environments. Traditional IP matching struggles with residential IPs, VPNs, and shared connections. Modern tools use "IP ringfencing" and device matching to connect residential IPs to corporate domains, but accuracy drops.
Two case studies show the potential. Biscred's VP of Marketing directed the SDR team to follow up on 100 enriched website visitors and booked 11 demos in one week - an 11% conversion rate from anonymous traffic. Mixmax went further, closing a $100K deal from a single person-level identification. Both required the right follow-up infrastructure to capitalize on the data.
Intent Data Collection
Intent data tells you who's researching what - which companies are actively looking at topics related to your product. There are two fundamentally different approaches, and the quality gap between them is enormous.
First-party intent data comes from your own properties: website analytics, form fills, content downloads, email engagement, chat interactions. It's the highest-signal data you have, but it only covers people who've already found you.
Third-party intent data comes from external sources, and this is where it gets complicated:
Bidstream data is captured during programmatic ad auctions. Every time a webpage loads an ad, data about the visitor - timestamp, IP, URL, location - gets passed through the auction. Providers collect this data across billions of websites and infer buying intent from browsing patterns. The problem: there's no context. Visiting a page about "CRM software" during an ad auction doesn't mean someone's buying a CRM. They could be a journalist, a student, or a competitor.
Co-op data works differently. Bombora, the dominant player, operates a cooperative of 5,000+ B2B publisher sites. Members opt in. An exclusive tag collects 100% of content consumption data from participating sites - including those without ads. Bombora's NLP engine reads and analyzes content across 12,000+ topics, and their patented Company Surge methodology compares current consumption against historical baselines.
| Attribute | Bidstream | Co-op (Bombora) |
|---|---|---|
| Source | Ad auction data | B2B publisher network |
| Scale | Billions of sites | 5,000+ curated sites |
| Accuracy | Low (no context) | High (NLP + baselines) |
| Compliance | GDPR issues (ICO, APD) | Opt-in, consent-based |
| Cost | Lower | Premium |
The compliance gap matters. The UK's ICO and Belgian APD have both ruled that collecting and using bidstream data violates GDPR. If you're selling into Europe, this distinction isn't academic - it's a legal risk.
Data Partnerships and Public Records
No single collection method covers everything. That's why data providers form strategic partnerships with specialized data companies, business directories, and industry databases to fill gaps.
Public records are an underappreciated data source. Companies House filings in the UK, SEC filings in the US, patent databases, and job postings all contain structured business data that's freely available. Job postings are particularly valuable - they reveal tech stacks, team sizes, growth signals, and hiring priorities. A company posting for five Salesforce admins is telling you about their CRM environment. An SEC 10-K filing listing a new subsidiary tells you about expansion plans before the press release hits. Patent filings reveal R&D direction and potential technology needs.
The data marketplace is now standard - providers routinely buy, license, and exchange data with each other, which is why you'll sometimes see the same contact appear across multiple tools. The providers that win aren't the ones with the most sources. They're the ones that reconcile conflicting data points intelligently when Source A says someone's a VP and Source B says they're a Director.
First-Party Data Collection
The best B2B data you'll ever have is data people gave you voluntarily.
Forms, content downloads, event registrations, demo requests, customer interactions, support tickets - this is data with context, recency, and implicit consent built in. A practitioner on Reddit put it bluntly: "The spray-and-pray email list you bought three years ago is exactly as useful as it sounds: useless. Forget cookies, forget third-party data. Your customers fill out forms. They download things. They email you questions. That's data. Real data."
Companies crushing it in 2026 are using first-party data to segment, personalize, and actually talk to people about what they care about. Third-party data supplements first-party - it fills gaps, identifies new accounts, and enriches existing records. But it should never replace the data your prospects and customers have already handed you.
The hierarchy is clear: first-party data is your foundation. Third-party data extends your reach. If you're spending more on third-party data than on capturing and maintaining first-party data, your priorities are backwards.
Most providers stop at email patterning and a single SMTP check. Prospeo runs a proprietary 5-step verification process - catch-all handling, spam-trap removal, and honeypot filtering - then refreshes every record every 7 days. The result: 98% email accuracy across 143M+ verified addresses, not the 50% industry average you just read about.
Stop sending emails into the void. Start with data that's actually verified.
Collection Methods at a Glance
| Method | What It Collects | Accuracy | Compliance Risk | Best For |
|---|---|---|---|---|
| Web Scraping | Names, titles, company info | Medium | Low-Medium | Building base records |
| Email Patterning | Email addresses | Medium | Low | Predicting work emails at scale |
| SMTP Verification | Email validity confirmation | Medium-High | Low | Confirming deliverability |
| Contributor Networks | Contacts, relationships | High | Medium-High | Massive-scale databases |
| Reverse IP Lookup | Company/person from web visits | Medium | Medium | Converting anonymous traffic |
| Intent Data | Topic research signals | Varies (co-op > bidstream) | Low (co-op) to High (bidstream) | Prioritizing in-market accounts |
| Data Partnerships | Firmographic, technographic | Medium-High | Low | Filling coverage gaps |
| First-Party Collection | Full contact + context | Highest | Lowest | Foundation of any data strategy |
How Data Providers Verify and Maintain Quality
Collection without verification is worthless. I've seen teams import 50,000 "verified" contacts from a provider, launch a sequence, and watch 15% hard-bounce in the first send. Their ESP flagged the account, pipeline stalled for weeks, and the domain reputation took months to recover.
The gap between providers comes down to verification depth. A basic provider runs a single SMTP ping and calls it verified - and as we covered, that carries a significant false positive rate. A serious provider layers multiple verification steps: DNS/MX validation, SMTP handshake, catch-all domain handling, spam-trap removal, honeypot filtering, and activation checks that confirm a human actually uses the inbox.
The business impact of getting this right is massive. High-accuracy providers (97%+) achieve 66% higher conversion rates and 25% productivity improvements compared to teams working with average-quality data.

To see what this looks like in practice: Prospeo's verification stack runs every record through DNS validation, SMTP verification, catch-all handling, spam-trap removal, and honeypot filtering - using proprietary infrastructure rather than relying on third-party email verification providers. Every record refreshes on a 7-day cycle (the industry average is six weeks), delivering 98% email accuracy across 143M+ verified addresses. That's the difference between a provider that checks a box and one that's built verification into the core architecture.
Beyond verification, waterfall enrichment has become the standard for maximizing coverage. The concept: query your primary data provider first. If gaps remain, the system automatically queries a second, then a third, continuing until the record is complete or all sources are exhausted. This works because no single provider has complete coverage across all industries and geographies. Apollo might find a contact that Lusha can't. ContactOut might have UK coverage that Datagma lacks.
The numbers are compelling. Waterfall enrichment achieves 85-95% find rates compared to 50-60% from any single source, with bounce rates below 1% versus 5-7% for non-validated datasets. Guideflow's case study illustrates this: before implementing waterfall enrichment, they had phone numbers for less than half their leads. After, they found phone numbers and emails for 85%+ of leads, and pipeline grew 37%.
Cost per enriched contact varies widely: $0.01-0.05 for basic data enrichment (email only), $0.10-0.50 for full enrichment (email + phone + firmographic), and $1-5+ for verified direct dials.
You now know the eight methods behind B2B data collection - and why verification and refresh cycles matter more than database size. Prospeo doesn't rely on third-party email providers. Its proprietary infrastructure scrapes, patterns, verifies, and refreshes 300M+ profiles weekly at $0.01 per email. That's 90% cheaper than ZoomInfo with higher accuracy.
See what properly collected and verified B2B data actually looks like.
Build vs. Buy: Should You Collect B2B Data Yourself?
Here's my hot take: unless your entire business model depends on proprietary data, you should buy.
Building an in-house data collection operation means maintaining scrapers (which break constantly as websites change), running your own SMTP verification infrastructure, handling data cleansing and deduplication, and staying current on GDPR/CCPA compliance - all while your competitors are just buying credits from a provider and spending their engineering hours on the actual product.
| Factor | Build In-House | Buy from Provider |
|---|---|---|
| Upfront cost | $50K-200K+ (engineering) | $0-5K/month |
| Time to first data | 3-6 months | Same day |
| Maintenance burden | High (scrapers break weekly) | None |
| Coverage | Narrow (your sources only) | Broad (aggregated sources) |
| Customization | Full control | Limited to provider's filters |
| Compliance liability | Entirely yours | Shared with provider |
The exception: if you're in a niche vertical where generic providers have poor coverage (think maritime shipping or agricultural equipment), building a targeted scraper for your specific industry data can supplement what you buy. But for standard B2B contact data - names, emails, phones, firmographics - buying is faster, cheaper, and less risky. The $3.1 trillion the US loses annually to data quality issues comes largely from organizations trying to maintain data infrastructure they shouldn't be running.
How Fast B2B Data Decays
B2B data decays at 22.5% per year. That means roughly one in five contacts in your database will go stale within twelve months - and that's the average. In high-turnover industries, it's far worse.
The drivers are relentless. 15-20% of professionals change jobs annually. Average tenure has dropped to 4.1 years across all industries; in tech, it's 2-3 years. A single job change invalidates most fields in a contact record - email, title, phone, company. Even without a job change, 10-15% of email addresses change annually due to system migrations, domain changes, and promotions. On top of that, 5-10% of companies undergo major changes annually through acquisitions, mergers, rebrands, or closures.

Decay by Industry
| Industry | Annual Decay Rate |
|---|---|
| Startups / VC-backed | 30-40% |
| Technology | 25-35% |
| Professional Services | 20-25% |
| Financial Services | 15-20% |
| Manufacturing | 10-15% |
| Government | 8-12% |
Decay by Field Type
| Field | Annual Decay Rate |
|---|---|
| Work email | 20-30% |
| Job title | 15-25% |
| Direct phone | 15-20% |
| Company | 10-15% |
| Mobile phone | 5-10% |
| Name | 1-2% |
The engagement impact is brutal. Contacts aged 0-3 months deliver a 25% open rate and 3% reply rate. By 12-24 months, that drops to 12% open and 1% reply. At 24+ months, you're looking at 8% open and 0.5% reply.
You're emailing into the void.
The financial cost is staggering: poor data quality costs organizations an average of $12.9 million annually. Sales reps lose 500 hours per year - 62 working days - just validating and correcting contact information. That's nearly 25% of their selling capacity spent on data hygiene instead of revenue-generating activity.
What Privacy Laws Mean for B2B Data Collection
B2B data isn't exempt from privacy laws. That's the misconception that gets companies in trouble. GDPR applies to any data that identifies a person - including business email addresses. CCPA expanded "personal information" to include employment-related data. Understanding the compliance obligations tied to each collection method is essential before you scale any outbound program.
| Attribute | GDPR | CCPA/CPRA |
|---|---|---|
| Consent model | Opt-in required | Opt-out rights |
| Legal basis needed | Yes (6 options) | No (for processing) |
| B2B applicability | Full - business emails included | Full - employment data included |
| Max penalties | EUR 20M or 4% global revenue | $100-$750 per violation |
| Enforcement trend | Tightening | Expanding |
The legitimate interest loophole that most B2B data providers rely on is narrowing. Marketing teams typically rely on consent; sales teams lean on legitimate interest for outbound prospecting. But legitimate interest requires a documented balancing test, and regulators are scrutinizing these more aggressively.
GTM expert Andy Mowat captured the tension perfectly: "If you read the rule book on GDPR, you basically can't do anything, but it's all gray... literally you can't outbound prospect if you read GDPR fully."
Here's a cautionary tale. A Series B SaaS firm purchased 8,000 CFO contacts and received an ICO complaint within two weeks. Resolution: $35,000 in legal and audit costs, full campaign suppression, and months of lost momentum. After rebuilding with compliant methods, their cost per qualified lead actually dropped 40%.
KPMG found that 75% of consumers won't buy from a brand they don't trust with their data. Compliance isn't just about avoiding fines - it's about not torching your brand.
How to Evaluate a Data Provider's Collection Methods
Not all providers are transparent about how they build their databases. Here's the checklist I use when evaluating a new data tool:
Questions to ask:
- What are your primary data sources? (If they can't answer specifically, that's a red flag.)
- How often do you refresh records? (Anything longer than monthly should give you pause. The best providers refresh weekly.)
- What's your verification process beyond basic SMTP? (If the answer is "we verify emails," push harder. How?)
- Do you use bidstream data for intent signals? (This matters for GDPR compliance.)
- What's your catch-all domain handling? (This separates serious verification from checkbox verification.)
Red flags:
- No transparency on collection methods
- No disclosed refresh cycle
- Single-source reliance (no waterfall approach)
- "95% accuracy" claims without methodology explanation
- No option to test before committing to an annual contract
Look, two providers can both claim "95% email accuracy" and deliver wildly different results. One might be measuring accuracy at the point of collection. The other measures it at the point of delivery, after catch-all handling and activation checks. The claim is identical. The quality is not. Always ask: accuracy measured how, and when?
We've run bake-offs where the provider with the biggest database and the boldest accuracy claims delivered the worst bounce rates in production. Database size is a vanity metric. Verification depth and refresh frequency are the numbers that actually predict whether your sequences will land.
FAQ
Is it legal to collect B2B data through web scraping?
Scraping public, non-personal business data is generally legal. Courts in hiQ v. LinkedIn ruled that public data doesn't fall under the Computer Fraud and Abuse Act. Scraping behind logins or violating enforceable terms of service crosses the line. Always respect robots.txt and throttle request rates.
How often should B2B contact data be refreshed?
Weekly is the gold standard - B2B data decays at 22.5% per year, meaning roughly 2% of your database goes stale every month. The industry average sits around six weeks. Monthly is acceptable, but anything longer invites bounce-rate problems.
What's the difference between bidstream and co-op intent data?
Bidstream data is captured during programmatic ad auctions - broad but lacking context, and facing active GDPR enforcement from the ICO and Belgian APD. Co-op data comes from curated B2B publisher networks (like Bombora's 5,000+ sites) where members opt in and content consumption is analyzed with NLP. Co-op is more accurate and more compliant.
Why do B2B data providers claim high accuracy but still deliver bounces?
Most rely on basic SMTP verification, which carries a 22-28% false positive rate due to ghost seats and catch-all servers. A "valid" SMTP response doesn't mean a human reads that inbox. Multi-layer verification - including catch-all handling, spam-trap removal, and activation checks - drops false positives to 8-12%.
What is waterfall enrichment and how does it improve data quality?
Waterfall enrichment queries multiple data providers in sequence - if the first source can't find a contact, the system automatically tries the next. This achieves 85-95% find rates compared to 50-60% from any single source, with bounce rates below 1% versus 5-7% for single-provider datasets.