The Best Bland AI Alternatives in 2026 (With True Cost & Latency Tests)
Voice AI pricing is the easiest thing in the world to misunderstand. You see "$0.12/min," you do the napkin math, and then the invoice shows up looking like you accidentally doubled your volume.
And the money isn't even the worst part. The real brand damage comes from those half-second pauses that turn into talk-over, awkward silence, and a call that feels cheap even if the script is solid.
Picking bland ai alternatives isn't about "features." It's about platform type (API vs no-code vs CCaaS vs managed), then true cost-per-minute, then a latency/QA checklist that catches what demos hide. You'll walk away with a spreadsheet model, a 5-step demo script, and a production-readiness checklist.
Our picks (TL;DR)
Bland's billing mechanics - transfer-time billing when you use their numbers plus the $0.015 outbound attempt minimum - are exactly why I prioritize tools that make cost predictable and testing honest. If you can't model your minute stack, you can't manage it.

One rule: Pick this if... / Avoid if... gets you to a shortlist fast.
Retell AI - best overall for predictable cost stack + production QA
- Pick this if: you want the clearest "pricing = components" model (infra + voice + telephony + LLM), strong interruption handling, and QA tooling that makes iteration safe.
- Avoid if: you want a vendor to own outcomes end-to-end with enterprise SLAs and a services-heavy engagement (PolyAI fits that better).
Prospeo - best for verified emails/mobiles that protect your calling budget
- Pick this if: you're doing outbound and you're tired of paying voice minutes to discover your list is dead. Prospeo is the best self-serve B2B data layer for 98% email accuracy, 125M verified mobiles, a 30% pickup rate, and a 7-day refresh cycle - which directly cuts retries and failed-call waste.
- Avoid if: you never dial lists (pure inbound support). Data quality still helps routing and identity, but it won't be your biggest lever.
Synthflow - best for no-code speed when "ship this week" matters
- Pick this if: ops teams or agencies need to deploy agents fast without building orchestration from scratch.
- Avoid if: you already know you'll need deep observability, strict change control, and multi-team governance.
Vapi - best for developers who want maximum control
- Pick this if: you're building custom tool-calling and routing logic and you want to move fast.
- Avoid if: you need cost stability and ops-friendly guardrails on day one. Vapi can get there, but you'll earn it.
Look, if your average deal size is in the low five figures and you're not doing regulated workflows, you probably don't need a "guardrails-first" platform. You need predictable billing, fast QA loops, and a stack you can tune without fear.
Why teams replace Bland AI (the real cost + ops triggers)
Bland AI can be strong, but the switching triggers are consistent: bill shock, latency/voice quality, and ops friction (testing, governance, debugging).
The bill shock usually comes from two places people don't model upfront:
- Transfer-time billing (when you use Bland-provided numbers)
- Per-attempt minimums that punish short calls and failed calls
Current structure (effective Dec 5, 2026; current in 2026) breaks down like this:
- Start (Free): $0.14/min connected + $0.05/min transfer time
- Build ($299/mo): $0.12/min connected + $0.04/min transfer time
- Scale ($499/mo): $0.11/min connected + $0.03/min transfer time
And then the part that bites outbound teams:
- $0.015 per outbound call attempt minimum (Bland telephony)
- $0.015 minimum for failed calls (Bland telephony)
Transfers have a key exception that changes the math: BYOT (Bring Your Own Twilio) removes transfer fees. If you do lots of warm transfers, BYOT is the difference between "fine" and "why is this so expensive?"
What users actually complain about (and what they praise)
You don't need a thousand reviews to see the pattern - teams say the same things in Slack, in post-mortems, and in "why are we switching?" docs:
- Bland AI: people love the multi-prompt control and deterministic pathways; they hate the surprise bill math and the extra failure points once you scale beyond one agent.
- Retell AI: teams rave about natural turn-taking and interruption handling; they also learn quickly that add-ons and model choices can swing cost hard.
- Synthflow: everyone likes how fast it is to ship; everyone eventually hits a ceiling when debugging edge cases without deep traces and environments.
Latency is the obvious trigger. If your agent pauses long enough that humans start filling the silence, you get talk-over, broken barge-in, and that robotic vibe even if the words are correct. I've watched teams spend two weeks rewriting prompts while ignoring the fact that their P95 latency was the real conversion killer.
The other trigger is governance. Once you go from "one agent" to "ten agents across teams," you need RBAC, audit logs, environments, and a way to test changes without blasting real customers. A lot of voice stacks still feel like developer toys here, and yes, that gets old fast.
Bill shock callout (what usually happens):
You budget for connected minutes, then discover 30-60% of "real usage" is transfer time, retries, voicemail detection, and short-call minimums. Your effective CPM jumps, and nobody can explain it cleanly.
Deployment model decision tree (API vs no-code vs CCaaS vs managed)
Most lists jump straight to tool names. That's backwards. Choose the deployment model first; then pick the vendor.
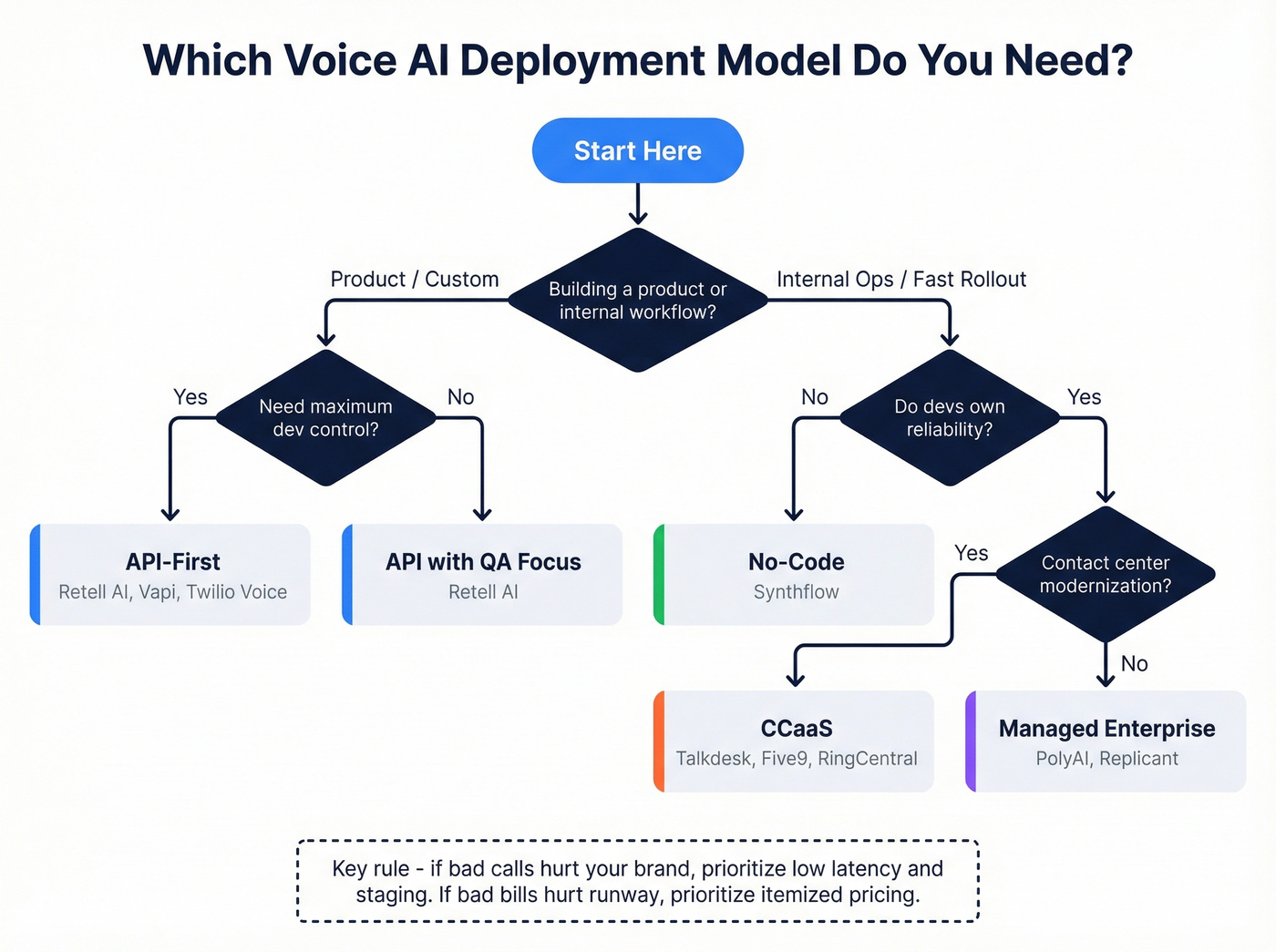
1) Are you building a product or an internal workflow?
- Product / custom experience / deep tool-calling: go API-first (Retell AI, Vapi, Twilio Voice).
- Internal ops automation / fast rollout / non-dev ownership: go no-code (Synthflow).
- Contact center modernization (routing, agent desktop, WFM): go CCaaS (Talkdesk, Five9, RingCentral, Twilio Flex).
- "We want outcomes, not a platform": go managed enterprise (PolyAI, Replicant).
2) How much do you care about deterministic control vs natural conversation?
- If you need scripted, regulated, multi-step control, Bland's style of guardrails can be a feature.
- If you need natural conversation + fast iteration, prioritize stacks with strong QA tooling and transparent billing.
3) Who owns reliability?
- Your engineers own it: API/CPaaS.
- Ops owns it: no-code (until you hit the ceiling).
- Vendor owns it: managed enterprise.
4) What's your failure mode?
- If "bad calls" hurt brand: choose low-latency + strong barge-in + staging.
- If "bad bills" hurt runway: choose itemized pricing + clear transfer behavior.
The true cost-per-minute model (use this to compare every vendor)
Here's the model I use in bake-offs because it forces every vendor into the same box. Retell is the best example of this framing because they spell it out: pricing is components, not vibes.
The decomposition (copy/paste this into your spreadsheet)
True cost per minute (TCPM) for voice agents:
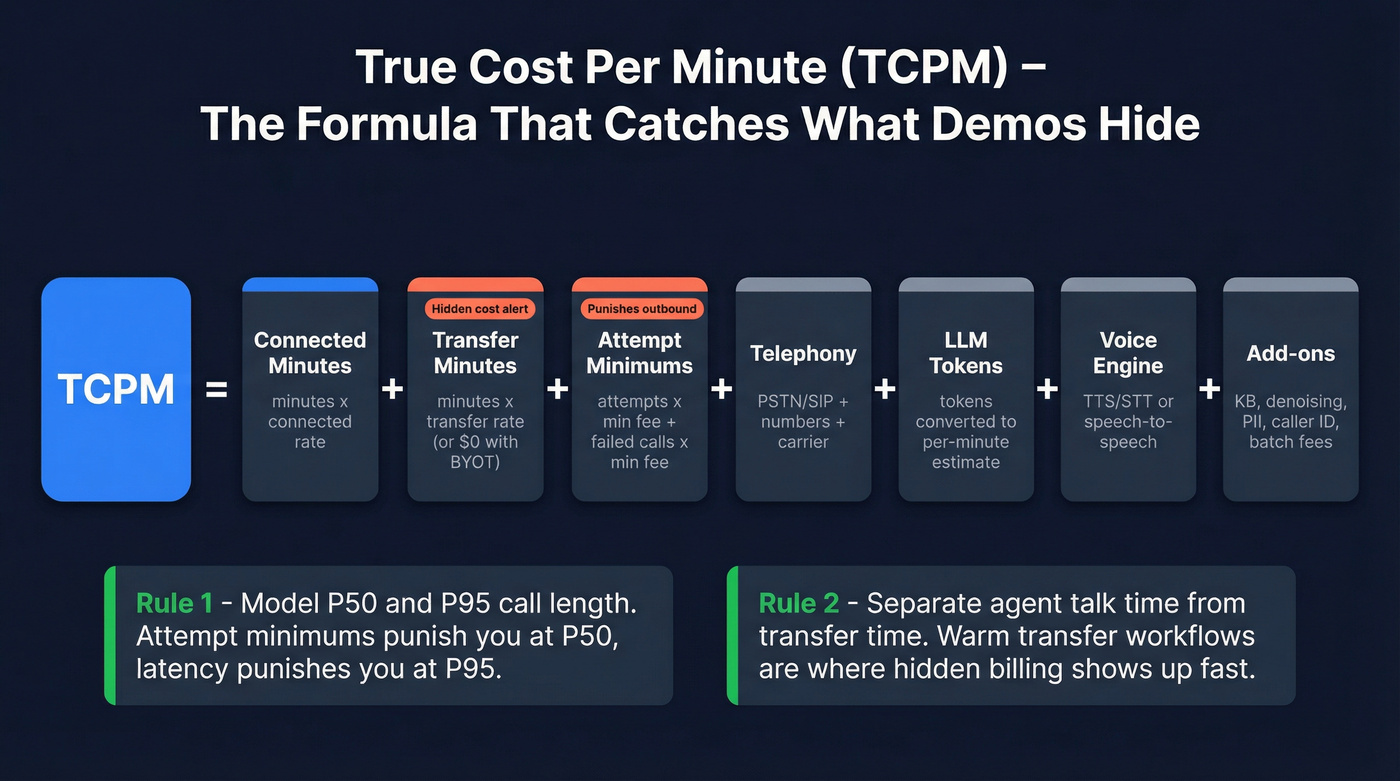
TCPM = Connected minutes + Transfer minutes + Attempt minimums + Telephony + LLM + Voice engine + Add-ons
More explicitly:
- Connected minutes cost = connected_minutes × connected_rate
- Transfer minutes cost = transfer_minutes × transfer_rate (or $0 if BYOT / no transfer billing)
- Attempt minimums = attempts × attempt_min_fee + failed_calls × failed_min_fee
- Telephony = PSTN/SIP minutes + numbers + carrier fees
- LLM = tokens → per-minute estimate (varies by model + prompt length)
- Voice engine = TTS/STT or speech-to-speech realtime
- Add-ons = KB, denoising, PII removal, branded caller ID, batch dialing fees, etc.
Two rules that keep you honest:
- Model P50 and P95 call length. Attempt minimums punish you at P50; latency and talk-over punish you at P95.
- Separate "agent talk time" from "transfer time." Warm transfer-heavy workflows are where transfer billing (when not BYOT) shows up fast.
The question nobody asks (and it changes everything): do you keep paying LLM/voice during transfer/hold?
Warm transfers aren't just "extra minutes." The real trap is paying the expensive parts of the stack while a human is on the line.
Ask every vendor this, bluntly, and don't accept hand-waving: when the call is on hold during a warm transfer, do you still pay LLM tokens, do you still pay voice engine minutes, and if the agent is silent but the call stays connected, what's still metered?
If a vendor can't explain metering rules in 30 seconds, expect the invoice to teach you.
Mini table: what usually dominates cost
| Use case | Biggest cost driver |
|---|---|
| Warm transfer qualification | Transfer + hold behavior |
| Receptionist/answering | Attempt minimums |
| Support deflection | LLM + voice engine |
| High-volume outbound | Pickup rate + retries |
Every failed call attempt on Bland costs you $0.015 minimum - before you even connect. Bad phone data turns your voice AI budget into a bonfire. Prospeo's 125M+ verified mobiles with a 30% pickup rate and 98% email accuracy mean your AI agents dial real people, not dead numbers. 7-day data refresh keeps it that way.
Fix your list before you fix your voice stack.
Worked "true cost" calculator (3 scenarios you can reuse)
Below is a worked example you can adapt. The point isn't perfect precision; it's forcing apples-to-apples comparisons.
Assumptions (same across vendors)
Per 1,000 outbound attempts in a day:
- Pickup rate: 25% → 250 connected calls
- Average connected time: 1.8 min
- Warm transfers: 40% of connected calls → 100 transfers
- Average transfer/hold time: 2.0 min
- Failed calls: 750 (no pickup / voicemail / invalid)
Derived minutes:
- Connected minutes = 250 × 1.8 = 450 min
- Transfer minutes = 100 × 2.0 = 200 min
Now compare three billing behaviors.
Scenario 1: Bland AI without BYOT (transfer minutes billed + attempt minimums)
Use the Build plan rates as an example:

- Connected: $0.12/min
- Transfer: $0.04/min
- Attempt minimum: $0.015/attempt (and failed-call minimum)
Cost math (usage only):
- Connected: 450 × 0.12 = $54.00
- Transfer: 200 × 0.04 = $8.00
- Attempt minimums: 1,000 × 0.015 = $15.00
Usage subtotal: $77.00 (plus your monthly plan fee and any other stack costs)
What this teaches: even before you add LLM/voice/telephony components elsewhere, the attempt minimum is a real line item, and transfer billing punishes warm-transfer workflows.
Scenario 2: Bland AI with BYOT (transfer minutes not billed, attempt minimums remain)
Same call behavior, but transfer fees drop to $0.
- Connected: 450 × 0.12 = $54.00
- Transfer: 200 × 0 = $0
- Attempt minimums: 1,000 × 0.015 = $15.00
Usage subtotal: $69.00 (plus plan fee)
What this teaches: BYOT is a direct lever if your workflow's transfer-heavy. It doesn't solve attempt minimums, but it stops the transfer bleed.
Scenario 3: Retell-style itemized stack (predictable components)
Using the example components from Retell's pricing structure:
- Voice infra: $0.055/min
- Voice engine add-on: $0.015/min
- Telephony: $0.015/min
- LLM example (lightweight): $0.006/min
All-in baseline per active minute: $0.091/min (before add-ons)
Now decide what counts as "active minute." This is where transfer/hold behavior matters:
- If the AI is active during transfer/hold, you pay on (connected + transfer) = 650 min
- If LLM/voice metering stops during hold/transfer, you pay on connected only = 450 min for the expensive parts
Case A (meter everything):
- 650 × 0.091 = $59.15
Case B (stop LLM/voice during transfer/hold):
- 450 × 0.091 = $40.95 (and you'd still pay telephony minutes depending on carrier rules)
What this teaches: "transfer minutes" isn't just a Bland problem. Every stack has a version of it. The win is clarity and control.
Bland AI vs alternatives - quick comparison tables (2026)
These tables are intentionally opinionated and based on running the same 5-step demo script (below) plus the cost model above. They're optimized for what breaks in production: forecasting, testing, and latency risk.
Table 1: Cost & testing (mobile-friendly)
| Tool | Platform type | Pricing model | Transfer billing | Testing |
|---|---|---|---|---|
| Bland AI | Platform | Plan + per-min | Yes (BYOT=no) | Good |
| Retell AI | API/platform | Itemized per-min | Usually no | Strong |
| Synthflow | No-code | Sub + usage | Varies | Easy |
| Vapi | API/dev | Per-min + pass | Varies | Fast POC |
| PolyAI | Managed | Per-min program | Contracted | Guided |
| Replicant | Enterprise CC | Tiered program | Contracted | Structured |
| Twilio Voice | CPaaS | Usage + carrier | N/A | Dev-first |
| Twilio Flex | CCaaS | Per-seat + usage | N/A | Enterprise |
Winners (pick one):
- Cost predictability: Retell AI
- Fastest testing loop: Vapi (POCs), Synthflow (no-code)
- Best transfer economics: Bland AI with BYOT (if you're staying), otherwise Retell-style itemization
Table 2: Performance & enterprise (mobile-friendly)
| Tool | Latency risk | Ent controls | Key gotcha | Best for |
|---|---|---|---|---|
| Bland AI | Mid | Strong | Attempt mins | Guardrails |
| Retell AI | Low | Growing | Add-ons | Production API |
| Synthflow | Mid | Limited | Debug ceiling | Fast launch |
| Vapi | Mid-high | Varies | Stack sprawl | Custom logic |
| PolyAI | Low | Strong | Slow buy | SLA outcomes |
| Replicant | Low | Strong | CC focus | CC automation |
| Twilio Voice | You own | Strong | Build work | DIY stack |
| Twilio Flex | You own | Strong | Scope creep | CC foundation |
Winners (pick one):
- Lowest operational risk: PolyAI
- Best "build it right" foundation: Retell AI
- Best for strict deterministic flows: Bland AI
Scoring rubric (how we ranked options)
This is the /10 rubric I use so "opinionated" doesn't turn into "random."
Each dimension is 0-2 points (max 10):
- Cost predictability (0-2): Can you forecast without surprises?
- Latency readiness (0-2): Does it feel natural under load with strong barge-in?
- Testing & observability (0-2): Sandbox, traces, replay, environments.
- Enterprise controls (0-2): RBAC, audit logs, SSO, retention, compliance posture.
- Build effort (0-2): Time-to-production for a real workflow (not a demo).
Scorecard (top tools)
| Tool | Cost | Latency | Testing | Ent | Effort | Total |
|---|---|---|---|---|---|---|
| Retell AI | 2 | 2 | 2 | 1 | 1 | 8/10 |
| PolyAI | 1 | 2 | 1 | 2 | 2 | 8/10 |
| Replicant | 1 | 2 | 1 | 2 | 1 | 7/10 |
| Bland AI | 1 | 1 | 1 | 2 | 1 | 6/10 |
| Synthflow | 1 | 1 | 1 | 1 | 2 | 6/10 |
| Vapi | 1 | 1 | 1 | 1 | 1 | 5/10 |
How to use this:
- If you want the best balance of predictable cost + QA tooling, start with Retell AI.
- If you want the lowest "we're on the hook" risk and can afford enterprise motion, PolyAI is the cleanest bet.
- If you need deterministic guardrails and you can control transfer billing with BYOT, Bland AI stays in the conversation.
The best options (detailed reviews)
Below are the tools buyers actually evaluate when they're serious. I'm mixing platform types on purpose because the right answer depends on whether you're building an agent product, deploying internal ops automation, or running a contact center.
And yes, I'm giving a pricing signal for every tool. "Talk to sales" isn't a pricing strategy.
Retell AI (Tier 1) - the cleanest cost model in voice
Retell is the benchmark for transparent pricing and production QA. Their model forces the truth: your cost is always infra + voice + telephony + LLM, plus add-ons.
Here's the thing: this is what makes Retell feel "boring" in the best way. When something breaks, you can usually tell whether it was the model, the tool call, the carrier, or your own logic, and you can fix it without guessing which black box you're paying for.
Pricing signal (from their itemized structure):
- Voice infra $0.055/min
- Voice engine add-on $0.015/min
- Telephony $0.015/min
- LLM examples on their page range from lightweight to premium (your model choice is the swing factor)
- Add-ons (KB, denoising, PII removal, branded caller ID, batch dialing) are explicit per-minute/per-call lines
What I've seen in real evals: run the same script on two different days, at two different times, and Retell tends to hold up better on turn-taking and interruption handling than most "demo-perfect" stacks. That consistency matters once you start pushing volume and your ops team is tired of chasing ghosts.
Compared to Bland AI: Retell is better for predictable billing + iteration. Bland is better when you need deterministic, multi-step guardrails and you're willing to live inside its billing mechanics.
Prospeo (Tier 1) - The B2B data platform built for accuracy
Outbound voice automation lives or dies upstream. If your list is stale, you pay for retries, failed calls, and short-call minimums no matter which voice vendor you pick.
Here's a scenario I've watched play out: a team launches an outbound voice agent, sees "bad performance," and starts tweaking prompts for two weeks. The real problem? Half the numbers were wrong, a chunk of the "right" numbers never picked up, and the agent spent its life chewing through attempt minimums and voicemail detection. Fix the data first, and suddenly the same agent looks "smarter" without changing a word.
Prospeo is the best self-serve data layer for keeping outbound efficient because it's built around accuracy and freshness:
- 300M+ professional profiles, 143M+ verified emails, 125M+ verified mobiles
- Used by 15,000+ companies and 40,000+ Chrome extension users
- 98% email accuracy, 30% mobile pickup rate, and a 7-day refresh cycle
- Enrichment returns 50+ data points per contact with a 92% API match rate and 83% enrichment match rate
- 30+ filters plus 15,000 intent topics
It fits into real workflows: native integrations with Salesforce, HubSpot, Smartlead, Instantly, Lemlist, Clay, Zapier, and Make, so you can verify/enrich and push clean contacts straight into your calling motion.
Pricing: credit-based and self-serve. Expect ~$0.01 per verified email, 10 credits per mobile, plus a free tier with 75 emails + 100 Chrome extension credits/month. Details: https://prospeo.io/pricing and integrations: https://prospeo.io/integrations.
Synthflow (Tier 1) - no-code speed, with a real ceiling
Synthflow is what you pick when you need something live fast and you don't want to build an orchestration layer. For common workflows - receptionist, FAQ routing, basic qualification - it gets you from zero to working in days.
Then reality shows up.
When it breaks (and it will): edge cases. The moment you're debugging barge-in failures, tool-call timeouts, or weird ASR behavior, you'll want deeper traces, environments, and change control than most no-code builders provide.
Pricing signal: Starter $29/month (50 minutes), Pro $450/month (2,000 minutes), Growth $900/month (4,000 minutes), Agency $1,400/month (6,000 minutes). Overage minutes cost $0.12-0.13/min, and extra concurrent call capacity is $7.
Compared to Bland AI: Synthflow wins on speed and non-dev ownership. Bland wins when you need strict multi-step control and deterministic pathways.
Vapi (Tier 1) - maximum flexibility, maximum responsibility
Vapi is for dev teams who want to wire up custom tools, prompts, routing logic, and experiments that no builder will handle cleanly.
It also offers free telephony for POCs via Vapi-managed numbers (U.S. area codes only, up to 10 numbers per wallet), which is genuinely useful for fast testing.
In the wild (what happens to teams):
- Week 1: "This is awesome, we can do anything."
- Week 3: "Why's our cost per minute drifting?"
- Week 6: "We need real observability and guardrails."
That's not a knock. It's the trade.
Pricing signal: budget $0.03-0.08/min for orchestration plus pass-through for LLM + voice + telephony. For most teams, an all-in budget of $0.17-0.50/min is realistic until you tune aggressively.
Compared to Bland AI: Vapi gives you more freedom; Bland gives you more guardrails. If your team can't own reliability, Bland (or managed enterprise) is safer.
PolyAI (Tier 1) - managed enterprise, polished experience
PolyAI is the grown-up option when you want a vendor to own outcomes, not just sell you a platform. It's built for reliability, ongoing tuning, and operational support, with a 99.9% uptime SLA for phone lines.
Implementation reality: you're buying an enterprise program. Expect security reviews, procurement, and a heavier rollout. The payoff is that you're not assembling a stack from five vendors and hoping it behaves.
Pricing signal: per-minute, contract-based. For enterprise voice automation, a realistic all-in range is $0.20-0.60/min depending on volume, channels, and support scope.
Compared to Bland AI: PolyAI is less DIY and more "we'll run this with you." Bland is better when you want strict scripted control and you're willing to operate the platform yourself.
Tier 2 alternatives (standalone blurbs)
Replicant (Tier 2) - contact-center automation with enterprise guardrails
Replicant is built for contact-center automation where concurrency, compliance, and integrations matter more than flashy demos.
Packaging details that matter:
- Quick Start includes 10 concurrent calls
- Higher tiers move to Unlimited concurrency
- PCI/HIPAA appear at Enterprise
- 35+ languages at Enterprise
- A 100% risk-free guarantee (refund of implementation and platform fees if expectations aren't met)
Pricing signal: enterprise CC automation is usually sold as a program (platform + implementation). Expect mid-to-high five figures per year for serious deployments, scaling with concurrency and channels.
AssemblyAI (Tier 2) - speech models, not a full agent platform
AssemblyAI is a strong option when you're building your own stack and you want ASR/speech capabilities as components.
Best for: teams already committed to DIY (Twilio + orchestration + your app) who want to control the speech layer.
Pricing signal: their base ASR products price out to about $0.0025-0.0045/min (depending on product), and you still need orchestration, telephony, and the rest of the stack.
Voximplant (Tier 2) - developer voice infrastructure beyond Twilio
Voximplant is another CPaaS-style option for teams that want programmable voice infrastructure.
Best for: developers who want flexibility and are comfortable owning routing, monitoring, and integrations.
Pricing signal: usage-based telephony and features; budget $0.01-0.05/min for telephony plus numbers and feature add-ons, then layer your AI costs on top.
Tier 3 (good to know, but validate hard)
These can be right depending on your environment, but don't buy them on a demo alone. Run the QA script and force the billing answers.
- Talkdesk: enterprise CCaaS. Pricing signal: many deployments land $85-165/agent/month plus AI add-ons and implementation.
- RingCentral: UCaaS/CCaaS consolidation play. Pricing signal: $20-35/user/month core; contact-center and AI add-ons push higher.
- Five9: enterprise contact center with strong routing/WFM. Pricing signal: per-seat, commonly $100-250/agent/month plus implementation and AI modules.
- Twilio Flex: CCaaS foundation. Pricing signal: $150-250/agent/month plus usage and any AI you add.
- CloudTalk: SMB phone system. Pricing signal: $19-49/user/month plus add-ons/usage.
- Aircall: sales/support phone system. Pricing signal: $30-50/user/month plus AI add-ons.
- Dialpad: UCaaS with AI features. Pricing signal: $15-25/user/month core; AI upgrades increase total.
- Lindy: workflow automation that can be voice-adjacent depending on your stack. Pricing signal: Free up to 40 tasks/month; $49.99/month and $199.99/month tiers.
- Ringly: more e-commerce oriented than general voice orchestration. Pricing signal: $349/month (Grow, 1,000 minutes); Scale includes a $4,000 setup fee plus $1,099/month.
- Nurix / Insighto: niche tools. Pricing signal: SMB entry plans often $50-500/month plus usage; validate what counts as a "minute" and how transfers/holds are billed.
Latency and voice QA (the part most alternatives lists ignore)
Most "alternatives" articles obsess over features and ignore the thing users actually feel: latency, barge-in, and dead air. That's why voice agents fail in production even when transcripts look fine.
Hamming (a voice testing vendor) reports that 42% of production issues are voice-specific failures - latency, ASR errors, interruption handling, audio glitches. That matches what we've tested: your logs can look "successful" while the call experience is painful.
Production targets (benchmarks that keep you honest)
Use these as targets in vendor evaluation and internal SLOs:
- Latency: P95 end-to-end <800ms (stretch goal <500ms; elite stacks chase <200ms in controlled setups)
- Uptime: 99.9% for most businesses; 99.99% if voice is revenue-critical or safety-critical
- Containment: 60-75% Tier-1 containment is a solid benchmark for mature deployments (define Tier-1 clearly: "resolved without human")
Targets that keep you out of trouble:
- P95 latency > 800ms → users get frustrated
- ~1.2s → talk-over starts
- 2+ seconds → abandonment spikes
Demo test script (steal this)
Run this exact script in every vendor demo and record it. This is also the method behind the "latency risk" notes in the tables.
Barge-in test: Interrupt mid-sentence with a new intent.
- Pass = agent stops cleanly and pivots.
- Fail = it keeps talking or loses the thread.
Dead-air test: Stay silent for 3-5 seconds.
- Pass = agent prompts naturally or confirms you're there.
- Fail = awkward looping or long silence.
Tool-call failure test: Force a tool to fail (calendar API error, CRM timeout).
- Pass = graceful fallback + confirmation.
- Fail = hallucinated success.
Transfer test: Warm transfer with context.
- Pass = clean handoff, no double introductions, no long hold.
- Fail = transfer "works" but customer experience is garbage.
Noise test: Add background noise and a second speaker.
- Pass = stable ASR and turn-taking.
- Fail = constant "sorry, can you repeat that?"
QA checklist (what to demand)
- Latency metrics: P50/P95 end-to-end, not just "model latency"
- Interruption handling: barge-in that doesn't break mid-flow
- Fallback routing: to human, voicemail, SMS, or ticket creation
- Monitoring: live call view, error taxonomy, replay with audio + events
- Regression testing: simulator/staging to test prompts and tools safely
Who should not switch away from Bland AI
A lot of teams switch because they're mad at the bill or the pauses. That's fair. But Bland is legitimately strong in one specific scenario: when you need strict, multi-step conversational control and you've got engineering support to implement it well.
People consistently point to multi-prompt control and deterministic pathways as the differentiator. If your workflow's closer to "guided transaction" than "open-ended conversation" (regulated scripts, eligibility checks, identity verification, tightly controlled escalation), Bland's guardrails are a real advantage.
Stay with Bland if:
- You need strict branching logic with guardrails and loop conditions
- You're doing high-stakes calls where "creative" AI is a liability
- You're already on BYOT and transfer fees aren't hurting you
- You've got a team that can own testing, monitoring, and iteration
Switch if:
- Your main pain is cost predictability (transfer minutes + attempt minimums)
- Your main pain is latency/talk-over and you can't tune it out
- You need faster iteration cycles with cleaner sandboxes and pricing transparency
Bland isn't bad. It's just optimized for controlled conversations, and most teams aren't actually running that kind of program.
Production readiness checklist (before you sign anything)
POCs are easy. Production is where vendors start saying "that's not supported" or "you'll need enterprise for that." This checklist keeps you out of science-project territory.
POC vs production gates (non-negotiables)
- Testing without friction: if you need billing details just to place test calls, your iteration speed dies.
- Staging/simulator: a safe environment to test prompts, tools, and routing without calling real people.
- Observability: call traces with timestamps (ASR → LLM → tool → TTS), not just transcripts.
- Concurrency limits: know your caps and what it costs to raise them.
- Enterprise controls: RBAC, audit logs, SSO, retention controls.
- Compliance: SOC 2 baseline; HIPAA/PCI if you touch sensitive data.
- SLA: uptime and support response times in writing.
- Failover: what happens when the agent can't complete the task?
The "cost stack" questions procurement should ask
- What's billed per connected minute vs per transfer minute?
- Are there per-attempt minimums? Failed-call minimums?
- Do LLM/voice charges continue during hold/transfer?
- What's included vs add-on (KB, denoising, PII removal, branded caller ID)?
- Can we export raw logs for our own monitoring?
Data quality check (don't skip this)
If you're doing outbound, verify emails and mobiles before you dial. Bad data doesn't just hurt deliverability - it burns voice minutes on retries, failed calls, and low pickup rates. Clean the list, enrich missing fields, then push only verified contacts into your dialer/agent workflow. For dialing benchmarks and KPIs, use this B2B cold calling guide.
You just modeled true cost-per-minute for every voice AI vendor. Now model the cost of retries, voicemails, and disconnected numbers feeding those minutes. Prospeo cuts that waste at the source - verified contacts at $0.01/email, 125M+ mobiles, refreshed every 7 days. No contracts, no sales calls.
Your cheapest voice minute is the one you never waste on a bad number.
FAQ
Does Bland AI charge for warm transfers, and how does BYOT change it?
Yes. When you use Bland-provided numbers, Bland bills transfer duration separately at $0.03-0.05/min depending on plan, on top of connected minutes. With BYOT (Bring Your Own Twilio), transfer fees are $0, so warm-transfer-heavy workflows get dramatically cheaper.
What's the simplest way to estimate "true cost per minute" for voice agents?
Use a stacked model: connected minutes + transfer minutes + attempt minimums + telephony + LLM + voice engine + add-ons. Run two scenarios - short calls (receptionist) and transfer-heavy calls (qualification) - and if either one blows past budget by 20%+, the headline CPM is hiding real charges.
Is Vapi's free telephony enough for production, or just POCs?
It's for POCs. Vapi's free telephony is limited to U.S. area codes and up to 10 numbers per wallet, which is perfect for testing but isn't a production telephony strategy. For production, plan for orchestration plus pass-through costs and validate monitoring, support, and reliability under load.
What latency should a voice agent hit to feel natural in real calls?
Aim for P95 under 800ms end-to-end to avoid frustration, and treat 1.2 seconds as the talk-over danger zone. Once you hit 2+ seconds at P95, abandonment spikes and your agent sounds broken even if the transcript looks fine. Test barge-in and dead-air handling, not just response accuracy.
What should I demand about billing during transfers or holds?
Get a written answer on whether LLM tokens and voice engine minutes keep running when the call's on hold or bridged to a human. If they can't describe metering rules in 2-3 bullet points, require a capped pilot (for example, 5,000 minutes) before scaling.
Summary: how to choose among bland ai alternatives in 2026
If you're comparing bland ai alternatives, don't start with feature checklists. Start with (1) deployment model, (2) a true cost-per-minute spreadsheet that includes transfers and attempt minimums, and (3) a latency QA script that forces barge-in and dead-air failures to show up in the demo.
If you want the cleanest forecasting and production QA, Retell's the obvious starting point. If you're doing outbound, Prospeo is the fastest way to stop wasting minutes on dead lists by verifying emails and mobiles upfront - start with an email verifier website and a B2B phone number workflow. And if you need strict deterministic flows, Bland can still be the right call - just don't ignore the billing mechanics.
If you’re building a broader outbound motion around calling, pair this with an outbound calling strategy, track your answer rate, and keep an eye on B2B contact data decay. For bigger systems, map it into your B2B sales stack and enforce data quality checks so your agents (and reps) aren’t burning minutes on bad inputs.