Pipeline Predictability in 2026: A Practical Operating System
$15,000 of "Commit" can vanish in a week without anyone lying. A close date slides, a champion goes dark, procurement shows up late, and suddenly your forecast's fan fiction. Pipeline predictability isn't about being optimistic or pessimistic - it's about being auditable.
Below is the metric set, stage template, and weekly cadence I've used to make forecasts defensible, even with messy deal cycles and reps who'd rather sell than babysit fields.
Predictability isn't a dashboard problem. It's an operating system problem.
What pipeline predictability actually means (and what it isn't)
Pipeline predictability means you can forecast amount + timing + a confidence band (Commit / Best Case / Upside) and be right often enough that Finance stops side-eyeing Sales.
It's not "having a big pipeline." It's not "updating Salesforce more." And it's definitely not "AI will fix it."
Predictability comes from inputs you can audit: stage definitions, buyer-verified next steps, clean close dates, and consistent inspection. When those inputs are tight, your forecast becomes a math problem instead of a vibes problem.
Operational definition (use this): A predictable pipeline produces a forecast that's accurate on (1) dollars, (2) the period it lands, and (3) the confidence band (Commit/Best/Upside) you assigned - based on rules, not rep optimism.
Definition box: Pipeline predictability Predictability = forecastable amount + forecastable timing + confidence band you can defend. If you can't explain why a deal is in Commit without "I feel good," you don't have predictability - you have hope.
The "auditable deal" checklist (fast test)
If a deal can't pass this in under two minutes, it's not forecastable. Full stop.
- Buyer evidence exists for the current stage (not just seller activity).
- Next step is specific, dated, and owned (name + due date).
- Close date is buyer-anchored (meeting, procurement step, signature workflow).
- Stakeholders are named (champion + economic buyer by Proposal).
- Stage age is within tolerance (or you can explain the exception in one sentence).
- Push count is within policy (or it's auto-demoted).
Hot take: if your deal size is small and your cycle is short, you don't need "enterprise forecasting." You need ruthless stage rules and a push-count policy. Most teams buy software to avoid enforcing basics.
What you need (quick version)
If you implement only three things this month, do these. They're boring. They work.
Verifiable stage exits (buyer action, not seller activity). A demo delivered isn't progress. A buyer confirming evaluation criteria and decision process is.
Day One accuracy grading + bias tracking. Lock your Day One forecast for the quarter/month and grade it later. Track whether you consistently overshoot (sandbag) or undershoot (happy ears).
Weekly scrub with push-count rules (no rep busywork). One lightweight weekly scrub beats a "CRM hygiene initiative" that dies in two weeks. Add a hard rule: deals pushed too many times lose Commit status automatically.
Why pipeline predictability breaks in the real world
I've seen this movie too many times: Salesforce is full of opps with wrong dollar values, outdated info, and close dates that magically land on the last day of the month. Leadership stops trusting the pipeline, so they start running the business off gut feel, and then everyone acts shocked when the quarter ends with a scramble.

Here's the thing: you can't fix that with "please update the CRM."
The fix has to be rules + automation + inspection, because if your solution requires reps to fill 20 extra fields per opp, it won't survive the month. And once the team learns nothing happens when they ignore the rules, your forecast categories turn into motivational labels instead of planning inputs.
Two lines I've heard in real forecast calls (and seen echoed in public threads) are painfully accurate:
- "Our pipeline is inflated by like 60%."
- "Two new deals sat untouched till Thursday."
Here's what actually breaks predictability (the repeat offenders):
- Stages are vibes. "Discovery" means five different things across the team.
- Close dates are fantasy. Reps pick end-of-month because it looks tidy.
- Commit is a motivation tool. It becomes "what I want to close," not "what will close."
- No push-count consequences. Deals slip forever and still sit in Commit.
- Handoffs leak. Work gets duplicated, deals sit untouched, and post-sale becomes a black hole.
One more cause RevOps teams ignore until it bites them: incentives. If reps get paid on pipeline creation or stage advancement, expect inflation. Pay on verified milestones (qualified meeting held, proposal accepted, closed-won) or audit hard enough that gaming the system isn't worth it.
I've watched teams spend months rebuilding dashboards when the real issue was simpler: they never defined what "real progress" looks like.
Your forecast breaks when reps prospect from bad data. Bounced emails, wrong contacts, and ghost champions inflate pipeline and wreck predictability. Prospeo's 98% email accuracy and 7-day data refresh cycle mean every deal starts with a real buyer - not a stale record that sits untouched till Thursday.
Stop forecasting on contacts that don't exist anymore.
The standard for measuring predictability (Day One accuracy + bias)
If you don't measure predictability the same way every period, you'll argue about it forever.
A clean standard is Day One forecast grading: compare the forecast you set at the start of the period to what you actually closed by the last day. Changes mid-quarter don't rewrite history - they're signals you should inspect. This is the backbone of reliable forecasting because it forces you to grade the system, not the story, and it gives you a repeatable way to spot whether your process is improving or you're just getting lucky.
Day One grading math (use error first, then accuracy)
Most operators should start with error, because it's unambiguous.
Day One Absolute % Error = | Day One Forecast − Actual | ÷ Actual
If you want an "accuracy" number:
Day One Accuracy = 1 − (Day One Absolute % Error)
Important: if Actual is near zero, percent metrics blow up. In that case, grade in $ error (or use sMAPE below).
Grade it (and stop hand-waving)
Use these thresholds (they're strict on purpose):
- Excellent: within ±5%
- Good: within ±10%
- Terrible: worse than ±10%
Now the part most teams skip: bias.
- If you consistently undershoot (forecast < actual), you've got happy ears or weak qualification.
- If you consistently overshoot (forecast > actual), it's a sandbagging signal - reps are hiding deals or lowballing Commit to "beat the number."
Real talk: overshooting isn't "conservative." It's just inaccurate, and it wrecks hiring plans and cash planning the same way undershooting does.
Forecast accuracy scorecard (copy/paste)
| Grade | Day One error band | What it means |
|---|---|---|
| Excellent | ≤ ±5% | Finance trusts you |
| Good | ≤ ±10% | Usable for planning |
| Terrible | > ±10% | Forecast is theater |

Benchmarks for "good" in 2026 (so you stop guessing)
Most teams think they're uniquely bad at forecasting. They're not.
Gartner research summarized by Demand Gen Report puts it bluntly: only 7% of sales orgs hit ≥90% forecast accuracy, and the median sits around 70-79%. Forrester, citing SiriusDecisions research, reports that 79% of sales orgs miss their forecast by more than 10%. Gartner also found 69% of sales ops leaders say forecasting's getting harder as buying committees expand and deals pick up more steps, more stakeholders, and more ways to slip.
How to use those benchmarks:
- If you're below ~70% accuracy, don't buy more tools yet. Fix stage exits + scrub cadence first.
- If you're in the 70-79% median band, your upside is governance and bias reduction.
- If you want 90%+, you're signing up for operational discipline: tighter definitions, fewer exceptions, and better data capture.
The minimal metric set (6 leading indicators) + formulas
You don't need 40 charts. You need six leading indicators that predict whether Commit is real, plus one lagging score (Day One grading) to grade the system.

Leading indicators tell you what's likely to happen. Lagging indicators tell you what already happened. Most teams obsess over lagging - and then act surprised when the quarter ends.
Concrete enforcement example (this is what "operating system" means): if push count hits 2 and the next step is undated, the deal auto-drops from Commit to Best Case, even if the rep's "100% confident."
Minimal metric set table
| Metric | Formula | What it predicts | Action trigger |
|---|---|---|---|
| Coverage ratio | Pipeline ÷ Target | Capacity to hit # | Raise/lower target or create more pipeline |
| Weighted coverage | Σ(Deal×Prob) ÷ Target | Realistic capacity | Re-weight stages or fix stage integrity |
| Sales velocity | (Opps×ADS×Win%) ÷ Cycle days | Output speed | Fix bottleneck stage |
| Stage aging | Days in stage | Stalls/slips | Re-qualify or exit |
| Slippage % | Slipped deals ÷ Forecast | Timing risk | Tighten Commit rules |
| Push count | # close date pushes | Forecast integrity | Auto-demote Commit |
MAPE, sMAPE, and bias (for comparing periods and models)
Use Day One grading to hold the org accountable. Use these to compare performance across periods, segments, or forecasting methods.
MAPE (Mean Absolute Percentage Error) MAPE = avg( |Forecast − Actual| ÷ Actual )
sMAPE (Symmetric MAPE) (more stable when Actual is small) sMAPE = avg( 2×|Forecast − Actual| ÷ (|Actual| + |Forecast|) )
Bias (directional error) Bias = avg( (Forecast − Actual) ÷ Actual ) Positive bias = overshooting; negative bias = undershooting.
Coverage ratio (segmented benchmarks)
Coverage ratio is the simplest "do we have enough?" check:
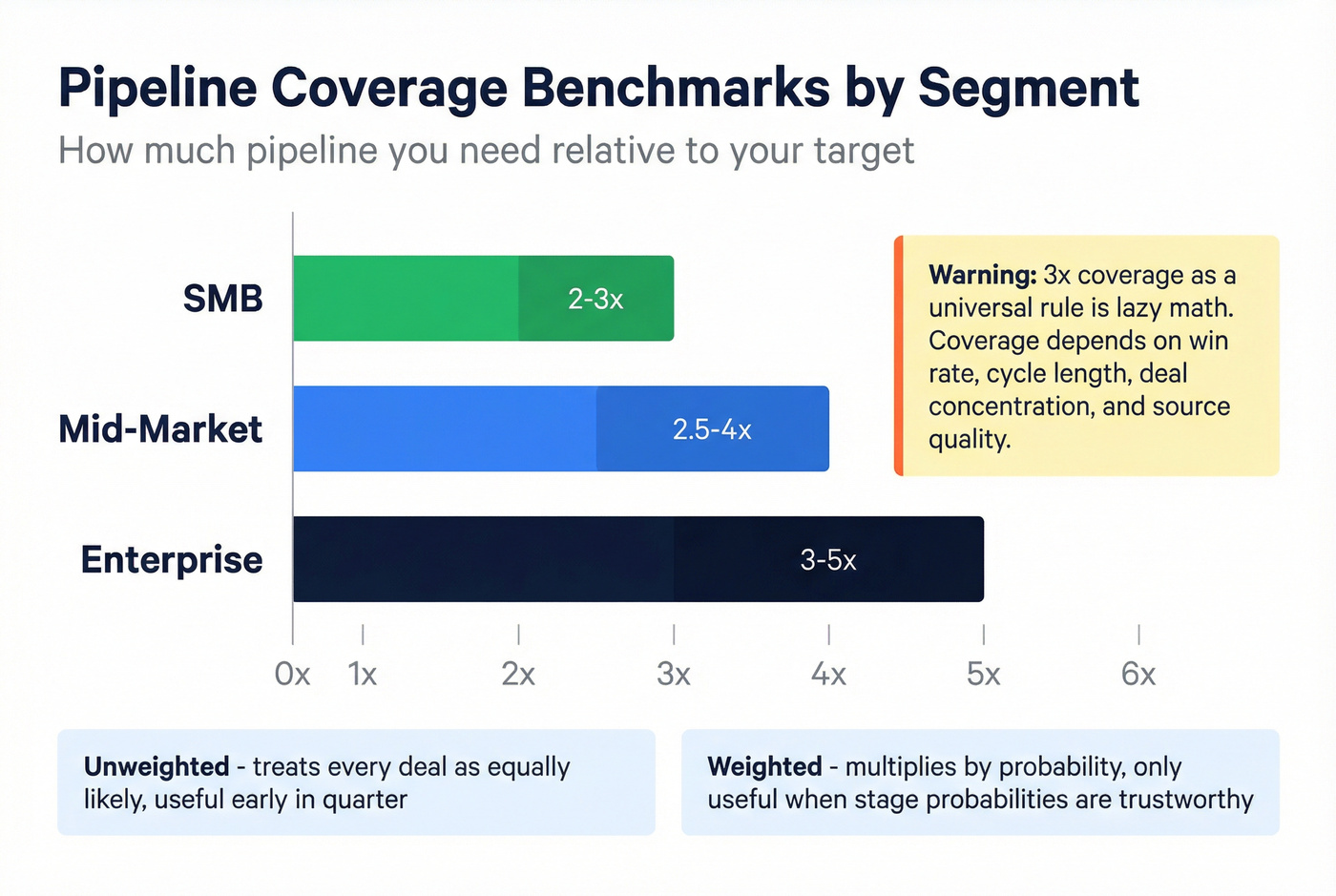
Coverage ratio = Total pipeline value ÷ Sales target value
Outreach's segmented ranges are a solid starting point:
- SMB: 2-3×
- Mid-market: 2.5-4×
- Enterprise: 3-5×
Weighted vs unweighted matters:
- Unweighted coverage treats every deal like it's equally likely. It's useful early in the quarter.
- Weighted coverage multiplies each deal by its probability. It's useful only when stages and probabilities are actually trustworthy.
If your probabilities are made up (common), weighted coverage's just fake precision.
Why "3× coverage" is lazy math
TOPO's best point is the distinction most teams ignore:
- Pipeline coverage = all open opportunities
- Forecast coverage = the subset you're calling for the period (Commit/Best)
"3× coverage" as a universal rule is lazy because coverage depends on win rate, cycle length, deal concentration, and source quality. If you've got two $250k whales and everything else is $10k, your coverage ratio can look "healthy" while your timing accuracy's awful, because one slip turns your month into a coin flip.
Set your coverage target with cohort math (week-3 method)
Kellblog's "week-3 pipeline conversion rate" method is the best practical upgrade to the win-rate inverse myth.
Instead of "coverage = 1 / win rate," use a cohort-style conversion:
Week-3 pipeline conversion rate = New ARR closed ÷ Week-3 starting pipeline
Then:
Implied coverage target ≈ 1 ÷ (trailing avg week-3 conversion rate)
Why week-3? It's far enough into the period that the pipeline's real, but early enough that you can still change outcomes.
Sanity check mental model: win a third, lose a third, slip a third. If that's roughly true for your business, your "Commit" should be a smaller subset than your "pipeline," and your push-count rules should be strict.
Velocity + stage aging + slippage + push count (rules that force truth)
Sales velocity is your "system throughput":
Sales velocity = (Opportunities × Avg deal size × Win rate) ÷ Sales cycle length (days)
Then add the truth-forcing metrics:
Stage aging: days since Stage Entered date If a deal is 2× the typical stage duration, it's not "still in play." It's stalled.
Slippage %: Slippage % = (# deals that moved out of the period) ÷ (# deals forecast for the period) High slippage means your timing's unreliable even if dollars eventually close.
Push count: number of times close date moved This is the simplest anti-BS metric in forecasting.
Governance rule (publish it): Any deal pushed 2+ times in-quarter is removed from Commit and must be re-qualified back in.
Stages with buyer-verifiable entry + exit criteria (template you can copy)
If your stages aren't buyer-verifiable, your forecast categories can't be trusted. Period. The fix is simple and strict: define what must be true to enter a stage and what buyer evidence proves you can exit it.
Buyer evidence doesn't have to be fancy. It just has to be real:
- A calendar invite with the right attendees for a decision meeting
- A written confirmation of success criteria / evaluation plan
- A procurement ticket, security questionnaire, or legal redlines in progress
- A mutual action plan with dates the buyer agreed to
Stage-by-stage entry + exit criteria + typical durations (table)
Use 6-7 stages. Keep them consistent across segments, but allow different duration expectations.
| Stage | Entry criteria (auditable) | Buyer-verifiable exit | Typical duration |
|---|---|---|---|
| New / Triage | ICP fit + reason to talk captured; meeting requested | Qualified meeting booked | 1-3 days |
| Discovery | Meeting held; problem statement + initial stakeholders captured | Success criteria + decision process captured | 3-10 days |
| Solution Fit / Demo | Use case defined; required capabilities listed | Use-case feasibility validated (buyer confirms fit gaps/needs) | 3-14 days |
| Scoping / Proposal | Budget range + buying committee mapped; timeline hypothesis stated | Proposal shared and buyer confirms review date | 5-20 days |
| Negotiation / Biz case | Procurement/legal path identified; start date hypothesis | Terms + procurement aligned (redlines/steps in motion) | 7-30 days |
| Commit / Signature | Signature workflow identified; final approver confirmed | Signature/PO in motion; start date set | 1-7 days |
Non-negotiable rule: a deal doesn't advance stages because you sent something. It advances because the buyer did something you can point to.
Required fields (the minimum viable CRM)
If you only enforce five fields, enforce these. They're the spine of predictability:
- Stage Entered date (system-captured if possible)
- Next Step (specific action) + Owner + Due date
- Close Date (with a reason code when changed)
- Forecast Category (Commit / Best / Upside)
- Stage Aging (calculated: today − Stage Entered)
Make it impossible to move stages without updating Next Step and Close Date. That one change does more than any dashboard rebuild.
If you're on Salesforce, their guidance on mapping stages to forecast categories is worth following: https://help.salesforce.com/s/articleView?id=sales.forecasts3_best_practices.htm&language=en_US&type=5
Anti-patterns to ban
These are the three I'd actually put in writing:
- Happy ears: "They loved the demo" isn't evidence. Evidence is a scheduled decision meeting with required attendees.
- Proposal-without-budget: if budget and authority aren't confirmed, "Proposal" is just a PDF you sent.
- Close-date fantasy: end-of-month close dates without a buyer-confirmed timeline get auto-demoted to Best Case.
A simple diagnostic: if X is happening, fix Y
This keeps you from "fixing everything" and fixing nothing.
- Accuracy's bad, slippage's low → qualification/stage integrity problem (Commit is polluted).
- Accuracy's bad, slippage's high → close-date governance problem (push-count policy's missing or unenforced).
- Coverage's high, accuracy's bad → deal concentration and/or stage definitions problem (big numbers hiding weak proof).
- Coverage's low, velocity's healthy → pipeline creation problem (top-of-funnel volume or reachability).
- Stage aging spikes in one stage → single bottleneck (often security/procurement or unclear decision process).
Skip this if you're still arguing about stage names. Lock the stage exits first, then diagnose.
Predictability isn't just forecasting - it's ownership and handoffs
Handoffs and ownership gaps kill predictability in a way dashboards can't see until it's too late.
I've watched a deal "look fine" in CRM while three people quietly redid the same proposal because nobody knew it was already done, and then after signature it turned into a black hole where the customer waited a week for onboarding while Sales celebrated. That isn't just messy ops - it's forecast risk, because your stage timestamps and next steps stop meaning anything when work disappears between SDR→AE, AE→SE, AE→CS.
Use simple rules:
- Every opp has a named owner. One throat to choke.
- Every opp has a dated next step. No date = not real.
- Handoffs require an explicit "accepted" moment. If CS hasn't accepted, it isn't handed off.
RACI mini-checklist (lightweight)
- R (Responsible): opp owner (usually AE)
- A (Accountable): manager for forecast category integrity
- C (Consulted): SE / Legal / Finance as needed
- I (Informed): CS post-signature, Marketing for attribution
No extra meetings required. Just clarity.
How to improve pipeline predictability week over week (scrub, forecast call, 1:1s)
Cadence is where predictability becomes real. Without cadence, your "rules" are just a doc nobody reads.
Demandbase's time allocation is the right north star:
- Selling: 60-70%
- Internal meetings: 10-15%
- Admin: 5-10%
So your cadence has to be tight. Short meetings, strict agendas, and a scrub that takes minutes - not hours.
Forrester recommends weekly forecast calls. They work when you enforce definitions and push-count rules.
For a deeper operating rhythm, see pipeline review cadence patterns that scale past one team.
One-page "Commit eligibility" checklist (print this)
A deal is Commit only if all are true:
- Buyer-verified next step exists (meeting/action) with date + owner
- Close date is buyer-anchored (procurement step, signature workflow, decision meeting)
- Economic buyer identified (name + role)
- Mutual plan exists (even a simple 5-line plan)
- Stage age within tolerance (or exception approved by manager)
- Push count within policy (see below)
- Deal amount is current (no "placeholder" numbers)
My opinion: if you let managers override this casually, you're choosing forecast theater. Don't be surprised when Finance treats your number like fiction.
Push-count policy (with escalation)
This is the policy that stops "forever deals" from poisoning your forecast.
- Push #1: require a reason code + updated buyer evidence (what changed?)
- Push #2 (in-quarter): auto-demote from Commit → Best Case; manager must re-qualify to return to Commit
- Push #3: remove from in-period forecast entirely and either re-stage (earlier stage) or close-lost with a clear reason
Yes, it feels harsh. It also fixes your timing accuracy faster than any training.
Weekly pipeline scrub checklist (10-minute per deal rules)
This is the "no busywork" version. It's fast because it's binary.
For each in-period deal (Commit + Best Case):
- Next step exists, has an owner, has a date. If not, it's not forecastable.
- Close date has buyer evidence. Meeting date, procurement timeline, signature workflow - something.
- Stage aging within tolerance. If it's 2× typical duration, re-qualify or exit.
- Push count check.
- 0-1 pushes: normal
- 2+ pushes in-quarter: remove from Commit and re-qualify
- Stakeholders named. If there's no economic buyer identified by Proposal, it's Upside at best.
Timebox it: if you can't defend the deal in 10 minutes, it isn't Commit.
Forecast call agenda (Commit/Best/Upside) + "last-call" rules
Run one weekly forecast call (30-60 minutes depending on team size):
- Commit: only deals with buyer-verified next step + no push-count violations
- Best Case: real deals with one missing element (stakeholder, timeline, procurement)
- Upside: everything else that's plausible but not defensible
"Last-call" rule (simple and effective): 48 hours before period end, no new deals enter Commit. They can close, but they don't count as forecastable.
1:1 forecast agenda + cadence by segment
A good 1:1 forces three questions:
- What deals are forecast?
- What deals could close this cycle but aren't forecast?
- What deals likely close next cycle - and can we pull them in?
Baseline: 30 minutes.
Cadence by segment:
- High-velocity / SMB: weekly
- Mid-market: weekly or bi-weekly
- Enterprise: bi-weekly or monthly (but keep weekly scrub rules for in-period whales)
Tooling & data inputs (make your pipeline auditable and AI-ready)
Tools don't create predictability. They enforce it - if your operating system's already defined.
Clari Labs surveyed 400 enterprise revenue leaders and found the core problem: 55% deal with conflicting pipeline signals, 48% say revenue data isn't AI-ready, and 42% lack governance. Gong's angle is signals: it uses 300+ signals and improves precision versus CRM-only approaches by capturing what actually happened in conversations and activity, not just what got typed into fields.
Clari's commissioned Forrester TEI report cites 96% forecast accuracy and 398% ROI for a composite org. Treat that as directional evidence, not a promise you'll get the same outcome.
How the stack fits together (the diagram in words)
Think in layers, with governance running across all of them:
- Data quality (contacts + enrichment): prevents dead outreach and fake activity at the top of funnel.
- Engagement/activity capture: logs touches and sequences so "next step" isn't a blank field.
- Conversation intelligence: captures real buyer intent, risks, and timeline changes without rep essays.
- Forecasting / revenue intelligence: standardizes categories, flags risk, and forces inspection.
Governance (stage definitions, entry/exit criteria, push-count policy) is the spine. Without it, every layer becomes an expensive way to be wrong.
When to buy tools (a decision rule that saves money)
- Buy nothing if your stage definitions are loose and your push-count policy doesn't exist. You'll automate chaos.
- Buy conversation intelligence when managers spend forecast calls arguing about "what happened" instead of "what to do next."
- Buy revenue intelligence when you have multiple teams/regions and your forecast categories drift, or when you need consistent rollups for Finance.
- Invest in data quality when outbound's a real pipeline source and bounce/connect rates are killing activity quality.
Predictability stack: category → what it fixes → typical pricing (2026)
| Category | What it fixes | Typical pricing |
|---|---|---|
| Revenue intel | Forecast + risk | $30k-$150k+/yr |
| Sales engagement | Activity + touches | $100-$200/u/mo |
| CRM add-ons | Basic forecasting | $75-$200/u/mo |
Pricing above is typical market range; "/u/mo" means per user per month.
Signals beyond CRM fields (activity + conversation intelligence)
If you're relying on CRM fields alone, you're missing the stuff that predicts reality:
- Next steps actually agreed to (not "sent follow-up")
- Stakeholders and roles (economic buyer vs champion)
- Risks (security, legal, procurement)
- Competitive mentions and pricing pressure
Conversation intelligence is valuable because it captures these signals without asking reps to type novels. That's how you reduce busywork while improving auditability.
If you want a good mental model for what "pipeline data" should include beyond fields, Gong's overview is solid: https://www.gong.io/blog/pipeline-data
Revenue intelligence / forecasting layer (enterprise)
If you're a larger org with multiple teams and long cycles, a revenue intelligence layer earns its keep by:
- Standardizing forecast categories across teams
- Flagging risk based on behavior (slippage, missing stakeholders, no next step)
- Reconciling conflicting systems (CRM vs engagement vs support)
Pricing reality: expect $30k-$150k+/year depending on size, modules, and procurement.
Data quality layer (contacts + enrichment) - where Prospeo fits
Predictability starts earlier than most teams admit: pipeline creation. When reps can't reach buyers, they manufacture activity, keep zombie deals alive, and "advance" stages to justify time spent. Upstream discipline is a major lever for forecast reliability because it reduces the number of "looks real in CRM" opportunities that never had a reachable buyer in the first place.
In our experience, teams get a fast win by tightening reachability before they tighten forecasting, because it cuts the volume of junk opps that managers then waste time "inspecting" later.
Prospeo ("The B2B data platform built for accuracy") fits here: 300M+ professional profiles, 143M+ verified emails with 98% accuracy, and 125M+ verified mobile numbers with a 30% pickup rate, all refreshed every 7 days. If you're building outbound lists or enriching inbound leads, that weekly refresh and real-time verification keeps your early-stage pipeline anchored to people you can actually contact, which makes every downstream metric (coverage, velocity, slippage) less noisy.
Workflow's simple: verify → enrich → push to your CRM or sequencer via https://prospeo.io/integrations.

FAQ
What's a "good" forecast accuracy for pipeline predictability?
A good standard is Day One absolute % error within ±10% of actuals, and excellent is ±5%. Anything worse than ±10% means your forecast categories and close dates aren't governed tightly enough for hiring, spend, or quota planning. If actuals are near zero, grade in $ error or use sMAPE.
What pipeline coverage ratio do I need (SMB vs mid-market vs enterprise)?
Use segmented targets: SMB 2-3×, mid-market 2.5-4×, enterprise 3-5× pipeline coverage. Then refine with cohort math: if your week-3 pipeline conversion rate is 25%, you'll need roughly 4× coverage to hit plan without heroics.
How do I stop sandbagging and "happy ears" from wrecking Commit?
Make Commit rules auditable: buyer-verified next step, named stakeholders, and push-count limits. Track forecast bias: repeated overshoot signals sandbagging; repeated undershoot signals happy ears. Enforce a rule that any deal pushed 2+ times in-quarter is removed from Commit and re-qualified.
What's the fastest weekly cadence to improve pipeline predictability without rep busywork?
Run a weekly 30-60 minute forecast call plus a lightweight scrub where each in-period deal must pass a 10-minute audit: dated next step, buyer-evidenced close date, stage aging within tolerance, and push-count compliance. Keep admin to 5-10% of rep time by auto-capturing activity where possible - this improves reliability without turning it into a CRM cleanup project.
What tools help clean pipeline inputs (verified contacts) before forecasting?
Final recommendation (tie the system together)
Pipeline predictability isn't a dashboard problem - it's an operating system problem.
Start with fewer metrics and stricter definitions: Day One grading, bias tracking, verifiable stage entry/exit criteria, and a weekly scrub with push-count consequences. Add tools only when they reduce rep busywork and increase auditability.
Auditable pipeline beats big pipeline. Every time.
Auditable deals need real stakeholders. If your champion left six weeks ago and your data provider hasn't caught up, your Commit is fiction. Prospeo tracks job changes in real time and refreshes every 7 days - so your forecast reflects who's actually in the seat, not who was there last quarter.
Real-time job change alerts keep your forecast honest.